
新的半监督分割法:对比一致的学习。
三个要点
✔️ 开发了第一个同时考虑像素的一致性属性和对比性属性的半监督分割框架。
✔️ 将现有的图像级对比学习扩展到像素级。特别是,使用了一种新的阴性抽样技术来降低计算成本和假阴性率。
✔️ 在现有基准实验中记录的SOTA。
Pixel Contrastive-Consistent Semi-Supervised Semantic Segmentation
written by Yuanyi Zhong, Bodi Yuan, Hong Wu, Zhiqiang Yuan, Jian Peng, Yu-Xiong Wang
(Submitted on 20 Aug 2021)
Comments: ICCV 2021
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
今天使用深度学习的语义分割需要大量的标签数据,当标签数据减少时,性能会明显下降。然而,生成大量标签数据的成本很高,而半监督学习,在少量标签数据的情况下保持性能,已经引起了人们的关注。因此,本文提出了一个半监督学习模型,需要满足两个属性:一个叫标签空间的一致性属性,表示物体颜色等发生变化时,分割结果不发生变化。另一个被称为特征空间的对比性,表明模型的特征有能力将相似的像素放在同一组,而将不相似的像素放在不同的组。传统的半监督学习SOTA模型考虑了上述的一致性属性,但对比性属性却没有被考虑很多。本文提出了一种像素对比一致的半监督分割方法(${rm PC^2Seg}$),将两者都考虑在内。
技术
该方法的示意图如下所示。
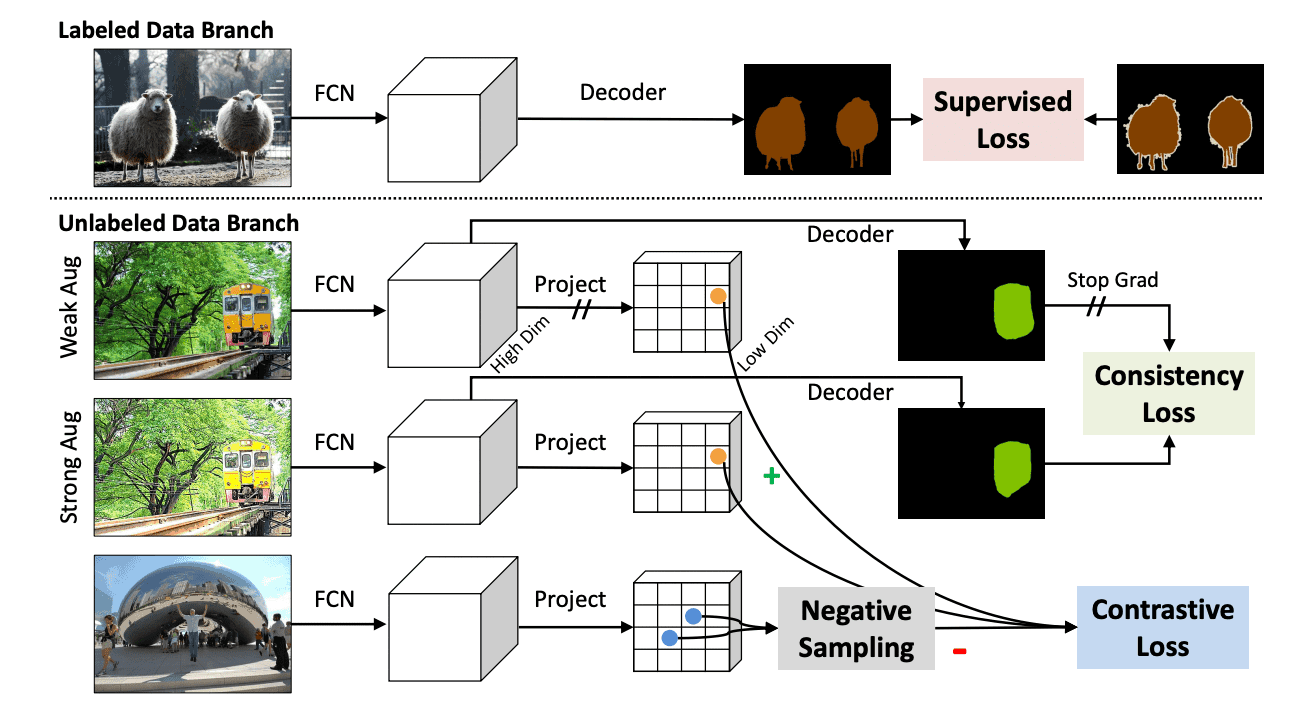
${rm PC^2Seg}$的损失函数是有标签数据和无标签数据的损失函数之和,表示如下。
$${\cal L}={\cal L}^{label}(x,y)+{\cal L}^{unlabel}(x)$$
然而,$x$是图像,$y$是掩膜图像。标记数据的损失函数使用了通常的交叉熵。无标签数据的损失函数是在一个连体网络架构中使用数据乘以强和弱的增量来计算的。最后,利用一致性损失$l^{cy}$和对比性损失$l^{ce}$,可表示为:。
$${\cal L}^{unlabel}=\sum_{i}\lambda_1 l^{ce}(z_i,z_i^+, \{z_{in}^-\}_{n=1}^N)+\lambda_2 l^{cy}({\hat {\bf y}}_i, {\hat {\bf y}_i^+})$$
其中$i$是像素的索引,$z_i$是弱增强图像的锚点像素,$z_i^+$是强增强图像的正像素,$z_{in}^-$是负像素,${\hat {\bf y}}_i, {\hat {\bf y}_i^+}$分别是模型的预测概率。另外,$\lambda$是平衡参数。
Consistency loss
一致性损失$l_i^{cy}$ 被定义为
$$l_i^{cy}=1-\cos({hat {\bf y}_i}, {hat {\bf y}_i^+})$$
其中$cos({bf u}, {bf v})=\frac{{bf u}^T{bf v}}{||{bf u}||_2||{bf v}||_2}$ 是余弦相似度。此外,对于弱增强的图像引入了梯度停止,对于强增强的图像引入了反向传播。
Contrastive loss
对比性损失$l_i^{ce}$定义为
$$l_i^{ce}=-\log{\frac{e^{\cos({\bf z}_i, {\bf z}_i^+)/\tau}}{e^{\cos({\bf z}_i,{\bf z}_i^+)/\tau}+\sum_{n=1}^Ne^{\cos({\bf z}_i,{\bf z}_{in}^-)/\tau}}}$$
然而,${\bf z}_i\in {\mathbb R}^D$是$D$维的特征向量, $\tau$是温度参数。
然而,在优化上述方程时存在一些问题。首先,特征向量是高维的,因此计算成本高。因此,加入了一个线性映射层,将维度降低到一个较低的维度。另外,负样本的数量是巨大的,因为它是逐个像素看的,对错误的负样本的噪声影响也很大。因此,我们采用了一种新的抽样方法。
Negative Sampling手法
假设对于每一个$i$的锚点像素,$N$的负像素$z^-_{in}$遵循以下离散概率分布。
$$z_{in}^-\sim Discrete(\{z_j\}_{j=1}^M;\{p_{ij}\}_{j=1}^M)$$
对于$\{p_{ij}\}$,我们考虑了以下四种方法。
Uniform
只需从小型批处理中的所有非锚定像素$M$中取样。然而,由于同一图像中的许多像素属于同一类别,因此会出现许多假阴性。
$$p_{ij}=\frac{1}{M}$$
Different Image
为了减少假阴性,从与锚点不同的图像中取样。让$I_i, I_j$为负面样本的候选图像的锚和ID。
$$p_{ij}=\frac{{\bf 1}\{I_i\neq I_j\}}{\sum_{k=1}^M{\bf 1}\{I_i\neq I_k\}}$$
Different Image + Pseudo-Label Debiased
让${\hat y}_i, {hat y}_j$分别为像素$i, j$的预测标签。从预测为与锚点不同类别的像素中抽取这些假标签。
$$p_{ij}=\frac{P({\hat y}_i\neq{\hat y}_j)}{\sum_{k=1}^MP({\hat y}_i\neq{\hat y}_k)}=\frac{1-{\vec{\bf y}_i^T}{\vec{\bf y}_j}}{\sum_{k=1}^M1-{\vec{\bf y}_i^T}{\vec{\bf y}_k}}$$
不同的形象 + 伪标签的贬低
上述两种方法的结合可以进一步减少假阴性。
$$p_{ij}=\frac{{\bf 1}\{I_i\neq I_j\}\cdot (1-\vec{{\bf y}}_i^T\vec{{\bf y}}_j)}{\sum_{k=1}^M{\bf 1}\{I_i\neq I_k\}\cdot(1-{\vec{{\bf y}}_i^T}{\vec{{\bf y}}_j})}$$
本文中使用了这种方法。
结果
对照公共数据集VOC 2012、Cityscapes和COCO,对性能进行了评估。结果分别如下表所示。
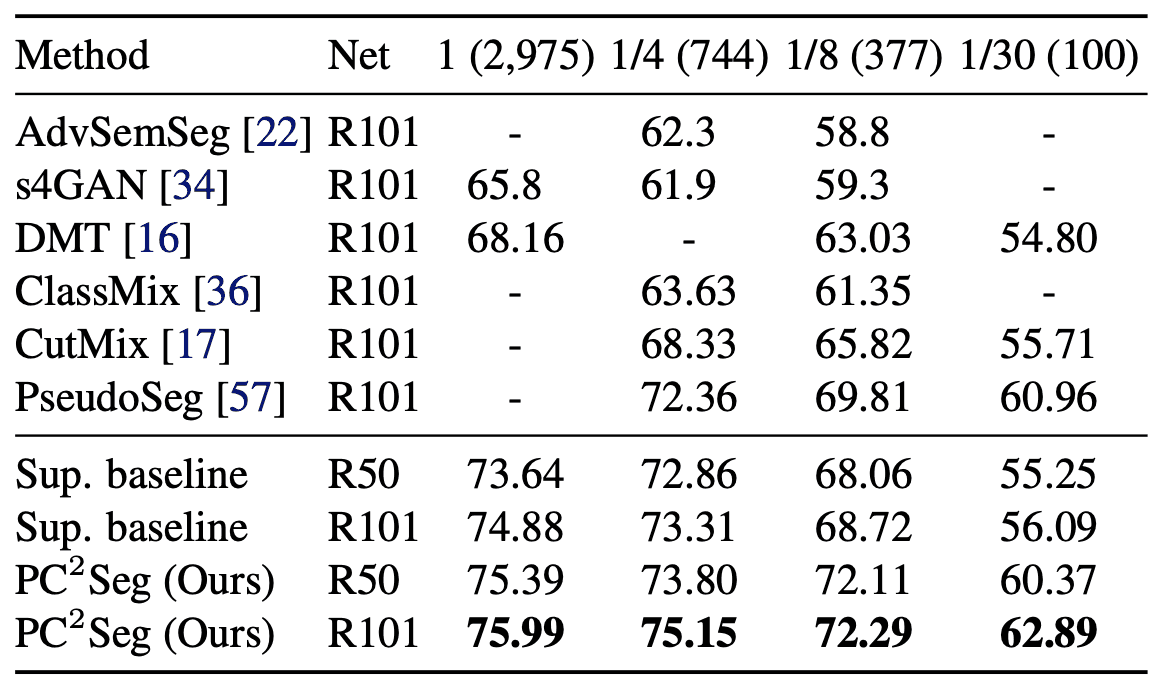

在这里,1/N$一栏只使用了总标示数据中的1/N$。该表显示,这种方法($PC^2Seg$)记录了所有数据集的SOTA。特别是,对于城市景观,使用全部数据和使用1/4的数据之间只有0.84%的差异。ResNet50也显示出与ResNet101相当的性能,这表明在少量数据的情况下,架构不需要那么深。
摘要
本文提出了一种新颖的半监督性分割方法,称为像素对比一致学习。还使用了一种新的负采样方法来有效地学习共生损失。该方法在现有的基准上记录了SOTA,并被发现是一种有希望改善半监督分割的方法。



与本文相关的类别


