激活功能摘要
三个要点
✔️ 关于激活函数的调查文件
✔️ 通过分类引入各种激活函数
✔️ 介绍在图像分类、语言翻译和语音识别中比较激活函数的实验结果
A Comprehensive Survey and Performance Analysis of Activation Functions in Deep Learning
written by Shiv Ram Dubey, Satish Kumar Singh, Bidyut Baran Chaudhuri
(Submitted on 29 Sep 2021)
Comments: Submitted to Springer.
Subjects: Machine Learning (cs.LG); Neural and Evolutionary Computing (cs.NE)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的 。
简介
各种激活函数已被提出用于深度学习,包括sigmoid、tanh和ReLU。
在这篇文章中,我们介绍了调查论文,详细介绍了迄今为止提出的激活函数的分类、特性和性能比较等重要信息。我们希望这些信息对选择深度学习的激活函数和设计新的激活函数有帮助。
关于激活函数
一开始,激活函数可以根据它们的特点和属性分类如下
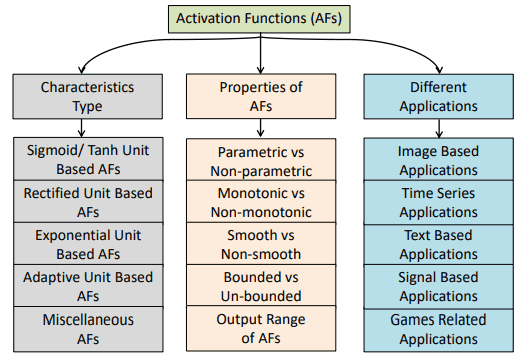
图中的特征类型表示每个激活函数所依据的函数。具体来说,它们被分为基于Sigmoid/Tanh的、基于ReLU的、基于指数单元的、学习和适应性的以及其他。
在这些类别中,主要激活函数的特点是
AFs的属性描述了每个激活函数的定义特征。特别是,它们可以根据以下属性进行分类:参数化与否,单调与否,平滑与否,有界与否,输出范围。
不同的应用显示了每个激活函数可以用于哪些任务。
下面的章节描述了基于特征类型分类的不同激活函数。
基于Sigmoid/Tanh的激活函数
在神经网络的早期,主要使用(Logistic)Sigmoid和Tanh作为激活函数。这些由以下数字(紫色和绿色线条)和公式表示。
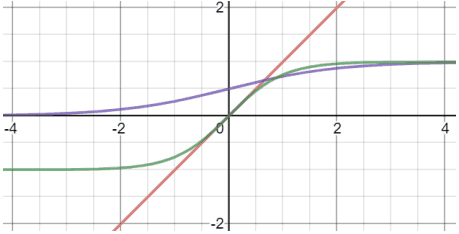
$Sigmoid(x)=1/(1+e^{-x})$
$Tanh(x)=(e^x-e^{-x})/(e^x+e^{-x})$
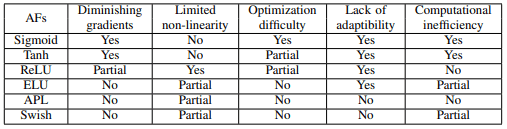
Sigmoid和Tanh函数都有自己的挑战,如梯度消失和计算复杂性。基于这些函数的激活函数可以在下表中总结。
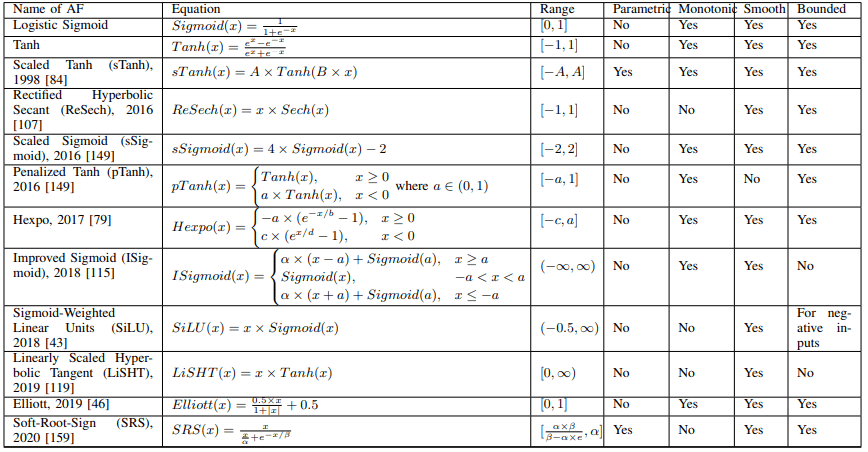
例如,在Scaled Sigmoid(sSigmoid)中,Sigmoid的性能通过适当的缩放得到改善。
此外,Penalized Tanh(pTanh)通过惩罚Tanh的负区域来消除原点周围的均匀斜率,并被证明在自然语言处理任务中表现良好。
作为一个没有在表中显示的例子,还建议使用噪声来应对梯度消失()。
一般来说,我们的目标是缓解梯度消失的问题,并通过增加参数的比例和改变梯度的属性来提高性能。
基于ReLU的激活函数
ReLU函数是一个非常简单的激活函数,表示为$Relu(x)=max(0,x)$。与Sigmoid和Tanh相比,这个函数在深度学习中非常流行,因为它的计算简单,而且不存在梯度消失的问题。
改进后的基于ReLU的激活函数解决了ReLU的一些特性,如不使用负值,非线性受到限制,输出无界等。基于ReLU的激活函数列于下表。
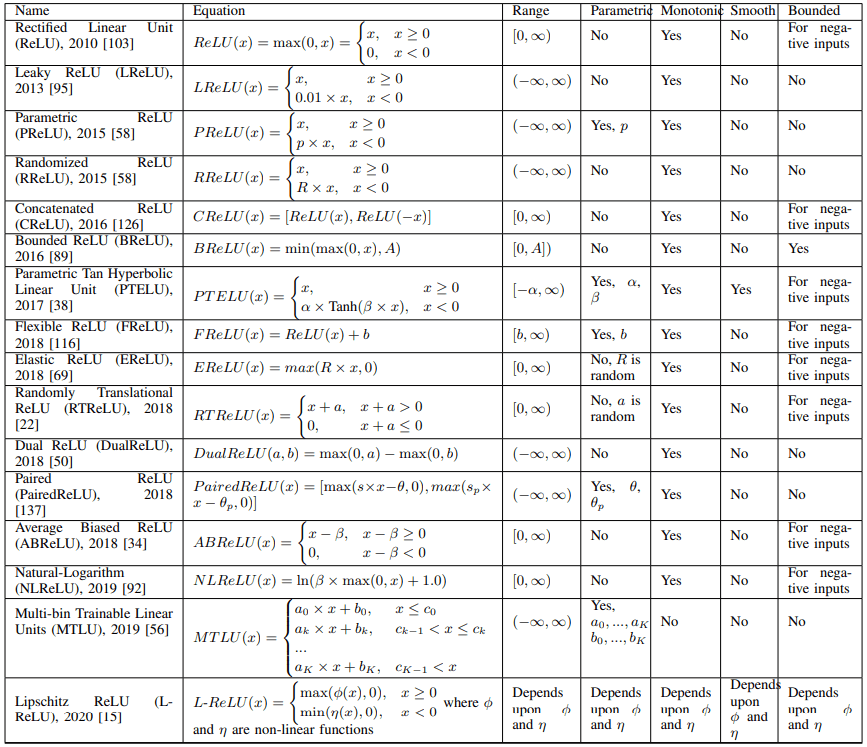
关于ReLU中不使用负值的问题
首先,介绍了一个例子,它涉及到ReLU不使用负值的事实。
一个典型的例子是Leaky ReLU(LReLU),它将ReLU扩展到负区,作为一个斜率很小的线性函数(例如$LReLU(x)=0.01x$,对于$x<0$)。LReLU在许多情况下都被使用,并显示出优异的性能,但很难找到LReLU的斜率应该如何设置。
因此,也有人提出了参数化ReLU(PReLU)和随机化ReLU(RReLU)等衍生物,其中负区的斜率是一个可学习的参数,斜率是从一个均匀分布中随机抽样。
还建议在参数化Tanh双曲线性单元(PTELU)中使用带有可学习参数的Tanh,用于消极区域。
在另一个方向上,并联ReLU(CReLU)通过合并两个输出ReLU(x)和ReLU(-x)来利用负值信息。
在柔性ReLU(FReLU)、随机平移ReLU(RTReLU)和平均偏向ReLU(ABReLU)中,ReLU是基于可学习参数或随机数或特征的平均值,ReLU在x或y方向平移通过在X或Y轴方向平移ReLU来利用负值。
论ReLU的有限非线性
接下来,我们介绍一个在扩展ReLU的非线性方向的改进实例。
在S型ReLU(SReLU)中,使用了三个线性函数和四个可训练参数来增加ReLU的非线性。同样地,多仓可训练线性单元(MTLU)结合了大量的线性函数。
此外,弹性ReLU(EReLU)通过随机设置正区域的斜率来控制非线性。
在其他方向上,也有ReLU与其他函数相结合的情况,如将ReLU与Tanh相结合的Rectified Linear Tanh(RelTanh),或将ReLU与对数函数相结合的Natural-Logarithm ReLU(NLReLU)。
关于ReLU的非约束性输出
由于输出是无界的,ReLU及其变种函数的学习可能是不稳定的。
为了应对这种情况,Bounded ReLU(BReLU)对输出设置了一个上限,这提高了学习的稳定性。
基于指数单位的激活函数
提出了使用指数函数的激活函数来处理Sigmoid、Tanh和ReLU所面临的问题。ELU是这一类别中典型的激活函数,由以下公式定义。
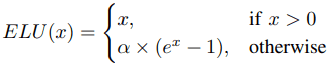
与Leaky ReLU和Parametric ReLU相比,ELU结合了ReLU的优点,对负区的噪声具有更强的鲁棒性。
基于这种ELU的激活函数已被提出,如缩放ELU(SELU),连续微分ELU(CELU),即使在$alpha\neq 1$时也是连续微分的,以及参数化可变形ELU(PDELU),它将激活图的平均值降为零。和参数化可变形ELU(PDELU),它将激活图的平均值减少到零。
与ReLU的情况一样,对于正的输入,也有修改函数的情况,使其有界。
学习和适应性激活函数
接下来,我们引入具有可学习参数的激活函数。典型的例子是Swish,这些例子在下面的表格中进行了总结。

例如,在Swish中,激活函数的形状在线性函数和ReLU之间进行调整,这取决于可学习参数$beta$(如果$beta小,则为线性,如果$beta大,则更接近ReLU)。
Swish扩展的例子包括ESwish、flatten-T Swish和Adaptive Richard's Curve weighted Activation(ARiA)。
还有一些例子,如本研究和自适应自动调节(AAF),它结合了PReLU和PELU,其中多个激活函数由可学习的参数组合。
一般来说,目标是通过可学习的参数来控制非线性函数的形状,或结合几个激活函数来实现对数据集或网络的适当激活函数。
其他激活函数
最后,我们将介绍一些上面没有列出的激活函数。
Softplus激活函数
Softplus是一个由$log(e^x+1)$定义的函数。
基于此的激活函数,例如Softplus Linear Unit,结合了Softplus和ReLU($x\geq 0的α×x,x<0的β×log(e^x+1))。
Softplus功能也被用于其他应用,如Rectigied Softplus(ReSP)和Rand Softplus。
还有一些建议,例如定义为$Mish(x)=x×Tanh(Softplus(x))$的Mish激活函数,它被用于YOLOv4模型的物体检测。
随机激活函数
存在概率性激活函数,如RReLU、EReLU、RTReLU和GELU。
例如,高斯误差线性单元(GELU)是由$x\Phi(x)$定义的函数(其中$Phi(x)=P(X≤x), X ~ N (0, 1)$)(可以近似为$xSigmoid(1.702x)$)。
其他提议的GELU的扩展包括对称高斯误差线性单元(SGELU)、双截高斯分布和概率自动调节(Probabilistic AF)。还有一项建议是使用概率性自动调节(ProbAct)。
多项式激活函数
基于多项式的激活函数包括平滑自适应AF(SAAF)、整流动力单元(RePU)($x\geq 0 for x^s where s is a hyperparameter)$、Pade激活单元(PAU)和理性AF(RAF),等等。
按子网络激活功能
Variable AF(VAF)使用一个小型子神经网络,以ReLU作为激活函数本身。
存在类似的方法,如动态ReLU(DY-ReLU)、宽隐式扩展(WHE)和AF单元(AFU)。
核心激活函数
有一些基于核的非参数自动调节(KAFs)及其扩展的例子,即多核自动调节(multi-KAFs),其中激活函数由核函数扩展。
关于SOTA的激活函数
SOTA对各种数据集和模型的激活函数如下表所示。
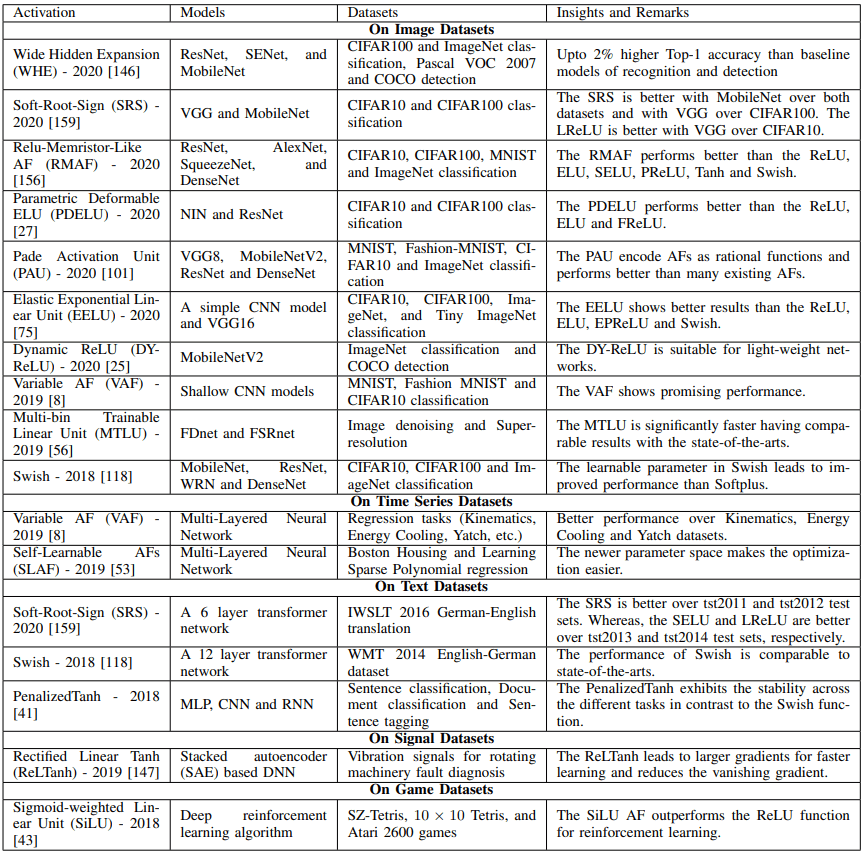
上表将帮助你了解哪些激活函数对哪些数据集和模型显示出最佳结果。此外,下面给出了关于现有激活函数的调查论文清单。
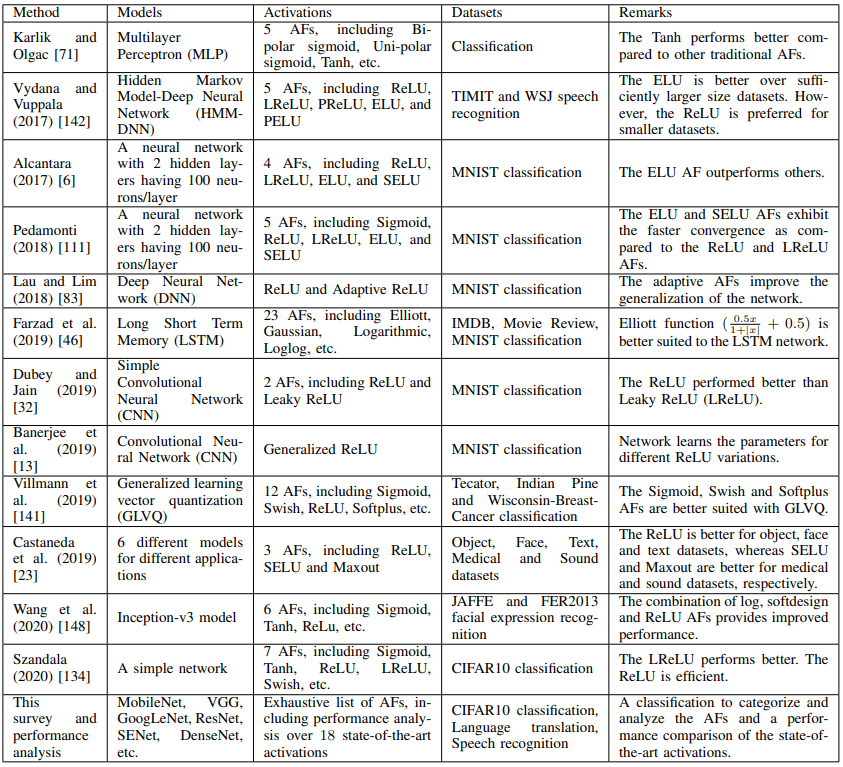
实验结果
在最初的论文中,我们为三个任务实验了18个不同的激活函数:图像分类(CIFAR10/100)、语言翻译(德语到英语)和语音识别(LibriSpeech)。实验中使用的激活函数如下
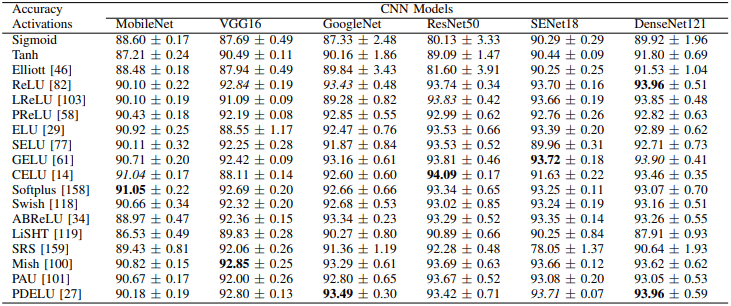
首先,CIFAR10的实验结果如下
其次,CIFAR100的实验结果如下
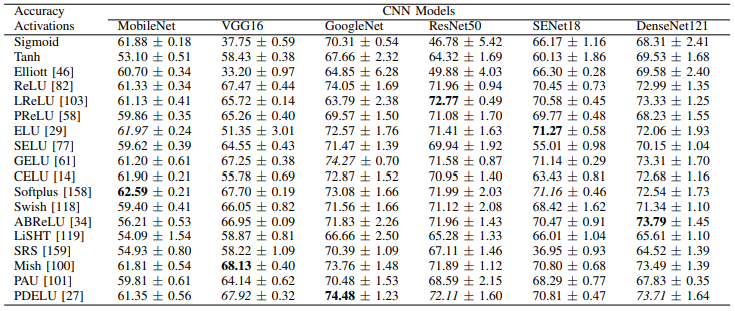
一般来说,可以看出每个模型的最佳损失函数是不同的(例如,Softplus、ELU和CELU在MobileNet上表现出色)。此外,CIFAR100中每个激活函数的学习时间(100个epochs)如下
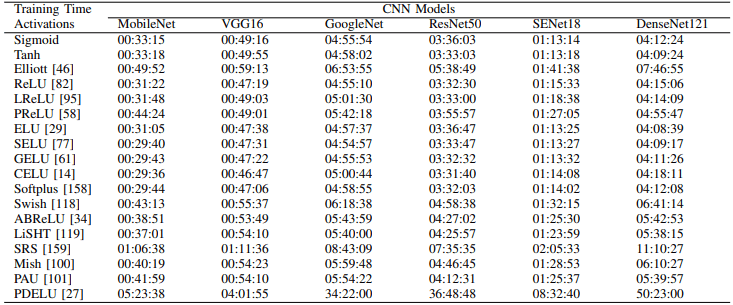
可以看出,PDELU、SRS和Elliott特别耗费时间。此外,CIFAR100中每个模型的学习曲线如下
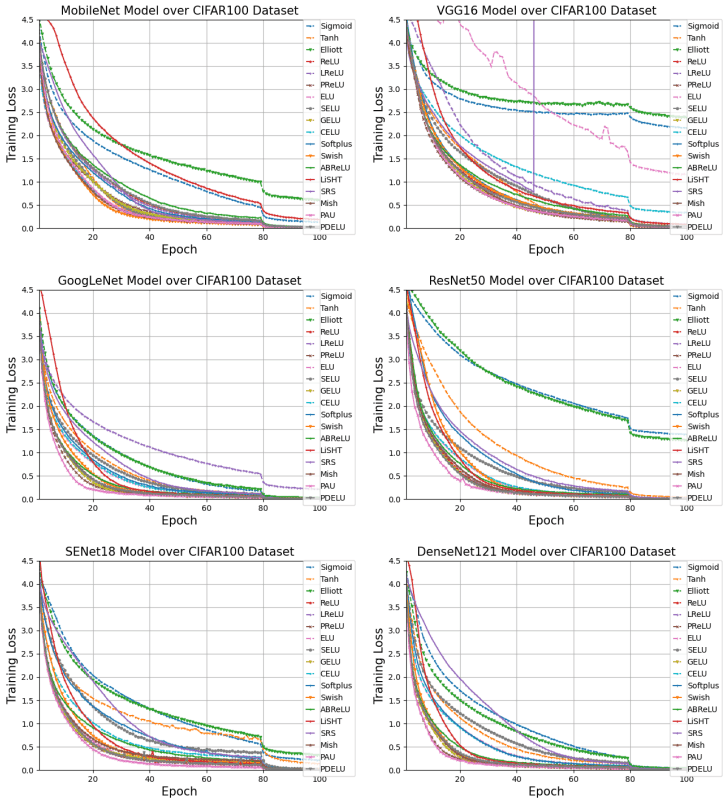
PAU、PReLU、GELU和PDELU收敛得特别快。最后,翻译和语音识别任务的结果如下
Tanh、SELU、PReLU、LiSHT、SRS和PAU在语言翻译方面表现出优异的成绩,而PReLU、GELU、Swish、Mish和PAU在语音识别方面表现出优异成绩。
摘要
在这篇文章中,我们提出了一份调查报告,总结了关于各种激活函数的分类、特性和性能比较的重要信息。
它包含了大量的信息,包括比较不同数据集和模型的激活函数的实验,如果你想了解更多关于激活函数的信息,这是一篇非常有用的论文,所以我们建议你看一看原始论文。



与本文相关的类别





