【開発者必見】活性化関数の最新包括的レビュー!
3つの要点
✔️ 活性化関数は、5種類(シグモイド系、ReLU系、ELU系、学習系、その他)に分類され、それぞれの課題を抱えている。
✔️ 「最高の活性化関数」などは存在せず、データやモデルごとに最適な活性化関数がある。
✔️ まずはReLUで良いが、Swish, Mish, PAUも試す価値がある。
A Comprehensive Survey and Performance Analysis of Activation Functions in Deep Learning
written by Shiv Ram Dubey, Satish Kumar Singh, Bidyut Baran Chaudhuri
(Submitted on 29 Sep 2021 (v1), last revised 15 Feb 2022 (this version, v2))
Comments: Submitted to Springer.
Subjects: Machine Learning (cs.LG); Neural and Evolutionary Computing (cs.NE)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
こちらの記事は2021年11月24日の「活性化関数まとめ」の更新になります。
ニューラルネットワーク(neural network, NN)の目的は、非線形に分離可能な入力データを学習によってより線形的に分離可能な特徴量に変換することです。この変換に活性化関数が重要な役目を果たします。活性化関数の具備すべき特徴は以下のとおりです。
- 非線形性を持ち込むことでネットワークの最適化を手助けする。
- 計算コストを過剰に増やさない。
- 勾配の流れ(gradient flow)を阻害しない。
- データの分布を保つ。
活性化関数の進化
線形関数 $ y = cx $ は、単純な活性化関数です($c$は定数で$c=1$のとき恒等関数と呼ばれます)。
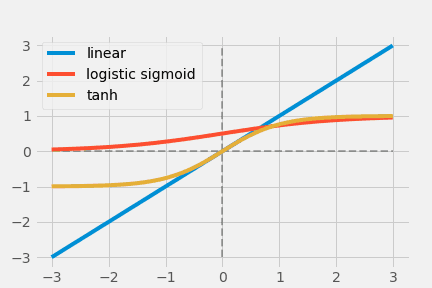
上記の赤色のグラフが線形関数です。あわせて、ロジスティックシグモイド関数(青色)とハイパボリックタンジェント(緑色)が描かれています。重要なのは、線形関数ではネットワークに非線形性を持ち込めない点です。
ロジスティックシグモイド・ハイパボリックタンジェント系列
$$\text { Logistic Sigmoid }(x)=\frac{1}{1+e^{-x}}$$
$$ \operatorname{Tanh}(x)=\frac{e^{x}-e^{-x}}{e^{x}+e^{-x}} $$
上記2つの関数は、初期によく使われていた非線形の活性化関数です。生物学的な意味でのニューロンにヒントを得ています(註:生物学的ニューロンは全か無かの法則にしたがうため、出力は0か1のみで、その間はありません)。Logistic Sigmoidは出力を$ [0,1] $に制限しますが、入力の大小に対して出力の大小があまり変わらない(saturated output)ため、勾配消失を引き起こします。また出力が0中心(zero centric)でない点も最適化に不向きです。
これに対して、$ \operatorname{Tanh}(x) $は0中心であり、出力が$[-1,1]$となっています。しかしながら勾配消失問題は依然として解決していません。
ReLU系列
Rectified Linear Unit(ReLU)は、その単純さと性能向上から活性化関数のstate of the art(最高品質、最高性能、SOTA)となりました。
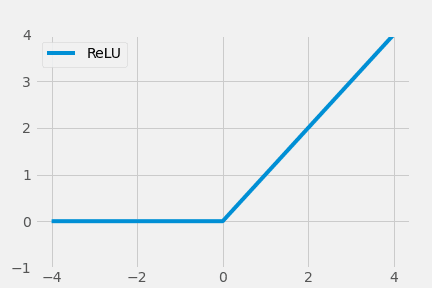
$$ \operatorname{ReLU}(x)=\max (0, x)= \begin{cases}x, & \text { if } x \geq 0 \\ 0, & \text { otherwise }\end{cases} $$
しかしReLUは、負の値の入力を活用できていない(under-utilization)問題がありました。
Exponential Unit系列
Logistic SigmoidとTanhの問題は、無限小から無限大までの入力の幅広さに対する出力の狭さ($[0,1]$)という出力の飽和(saturated output)でした。加えてReLUでは負の入力をうまく活用できていません。そこで見出されたのがExponential Linear Unit(ELU)です。
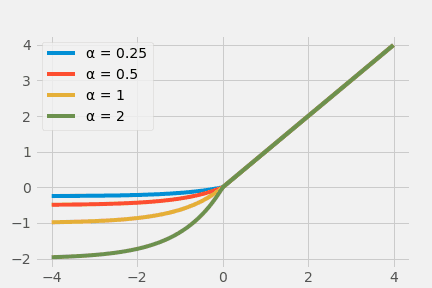
$$ \operatorname{ELU}(x)= \begin{cases}x, & x>0 \\ \alpha \times\left(e^{x}-1\right), & x \leq 0\end{cases} $$
学習・適応系
これまで挙げたSigmoid, Tanh, ReLU, ELU系の活性化関数は、いわば手作業的に設計されたものであり、データの複雑性を十分に抽出できていないかもしれません。
$$ \operatorname{APL}(x)=\max (0, x)+\sum_{s=1}^{S} a_{i}^{s} \max \left(0,-x+b_{i}^{s}\right) $$
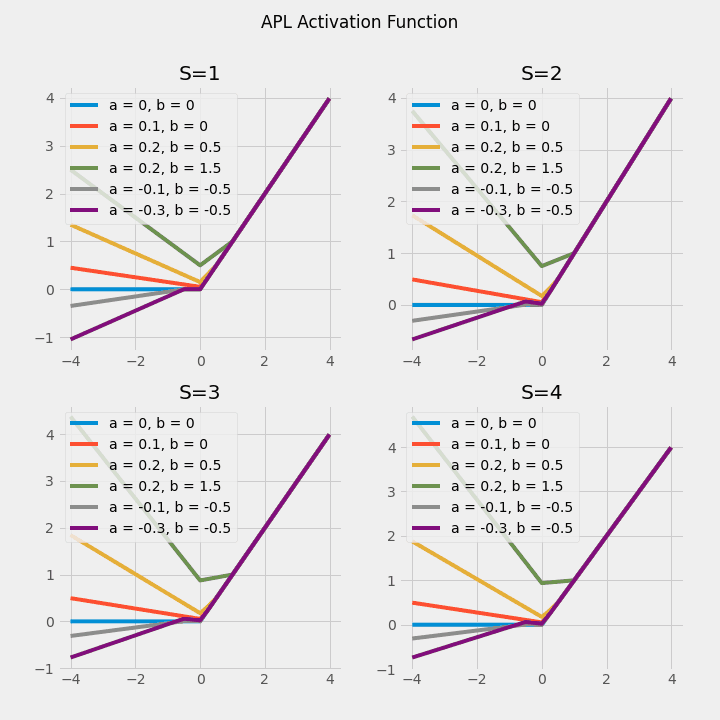
APLでは$ a_i $と$ b_i $が学習パラメータであり、活性化関数自体が変化します(註: S=3とS=4のグラフが同じに見えますが、よく見ると異なっています)。
その他
現在、他にも多くの活性化関数が提案されています。ここにはSoftplus関数、確率的関数、多項関数、カーネル関数等が含まれます。
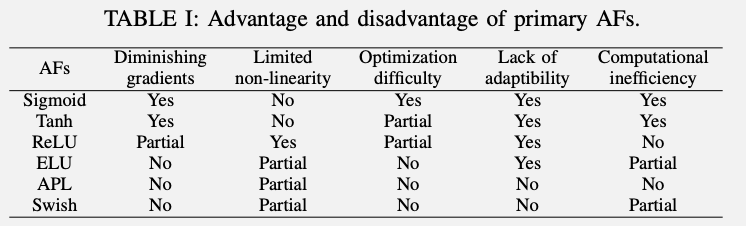
利点と欠点をまとめたのが上記の表です。左から勾配消失、非線形性、最適化の難しさ、適応性の欠如、計算コストの項目が並んでいます。
Logistic Sigmoid/Tanhベースの活性化関数
$ \operatorname{Tanh}(x) $ の出力範囲の狭さと勾配消失問題に対して、scaled hyperbolic tangent(sTanh)が提案されました。
$$ \operatorname{sTanh}(x)=A \times \operatorname{Tanh}(B \times x) $$
parametric sigmoid functionは、微分可能で連続な有界関数として提案されています。
$$ \operatorname{PSF}(x) = (\frac{1}{1+\exp(-x)})^m $$
同様にshifted log-sigmoidやrectified hyperbolic secantも提案されていますが、saturated outputと勾配消失問題は依然として残っていました。それはlogistic sigmoidやTanhの原点付近における形状が原因だったためです。そこでscaled sigmoidやpenalized Tanhが提案されてましたが、勾配消失は避けられませんでした。
その後、noisy活性化関数と呼ばれる、gradient flowを向上させるために活性化関数に乱数を与えた方法が提案され、saturated output問題にうまく対処できるようになりました。またHexpo関数は勾配消失問題の大部分を解決することになりました。
$$ \operatorname{Hexpo}(x)= \begin{cases}-a \times\left(e^{-x / b}-1\right), & x \geq 0 \\ c \times\left(e^{x / d}-1\right), & x<0\end{cases} $$
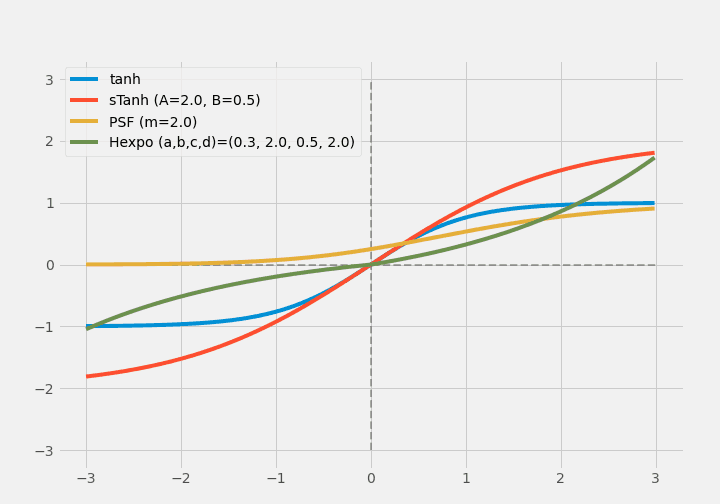
sigmoid-weighted linear unit(SiLU)やimproved logistic sigmoid(ISigmoid)は同時期に提案され、saturated outputと勾配消失問題を解決しています。またlinearly scaled hyperbolic tangent(LiSHT)、Elliott、Soft-Root-Sign(SRS)も同様です。
Sigmoid/Tanh系の活性化関数の多くは勾配消失問題の克服に挑戦してきましたが、多くの場合完全に解決するには至っていません。
Rectified Activation Functions
rectified linear unit(ReLU)は単純な関数で、正の入力に関しては恒等関数、負の入力に関しては0を出力します(入力が0のときは出力も0)。
$$ \operatorname{ReLU}(x)= \begin{cases}x, & \text { if } x \geq 0 \\ 0, & \text { otherwise }\end{cases} $$
そのため、微分値は1(入力が正)か0(入力が負)しかありません。そこでLeaky ReLU(LReLU)は、負の入力に対して0ではなく、小さな値を返すように変更しています。
$$\operatorname{LReLU}(x)= \begin{cases}x, & x \geq 0 \\ 0.01 \times x, & x<0\end{cases}$$
ところがLReLUの問題は、0.01が正しい係数かわからない点です。これをParametric ReLU(PReLU)では、係数を学習させることで回避しています。
$$ \operatorname{PReLU}(x)= \begin{cases}x, & x \geq 0 \\ p \times x, & x<0\end{cases} $$
しかしPReLUには過学習しやすい欠点がありました。
$$ \operatorname{RReLU}(x)= \begin{cases}x, & x \geq 0 \\ R \times x, & x<0\end{cases} $$
Randomized ReLU(RReLU)は係数をランダムに選択する手法です。
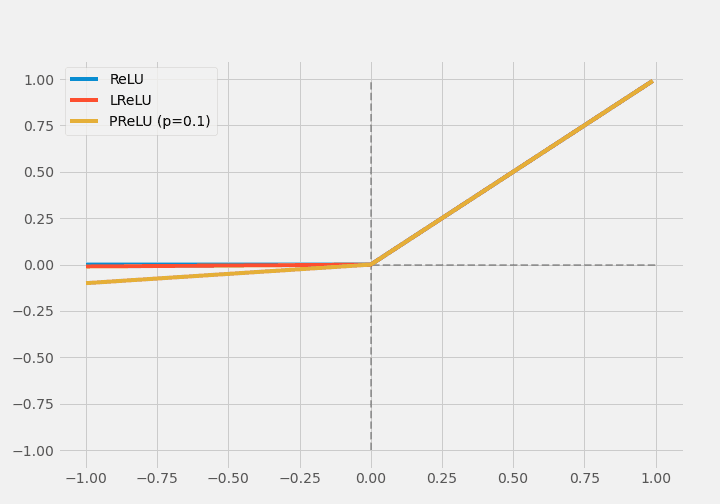
(註:係数が小さいのでほとんど重なってしまいます)
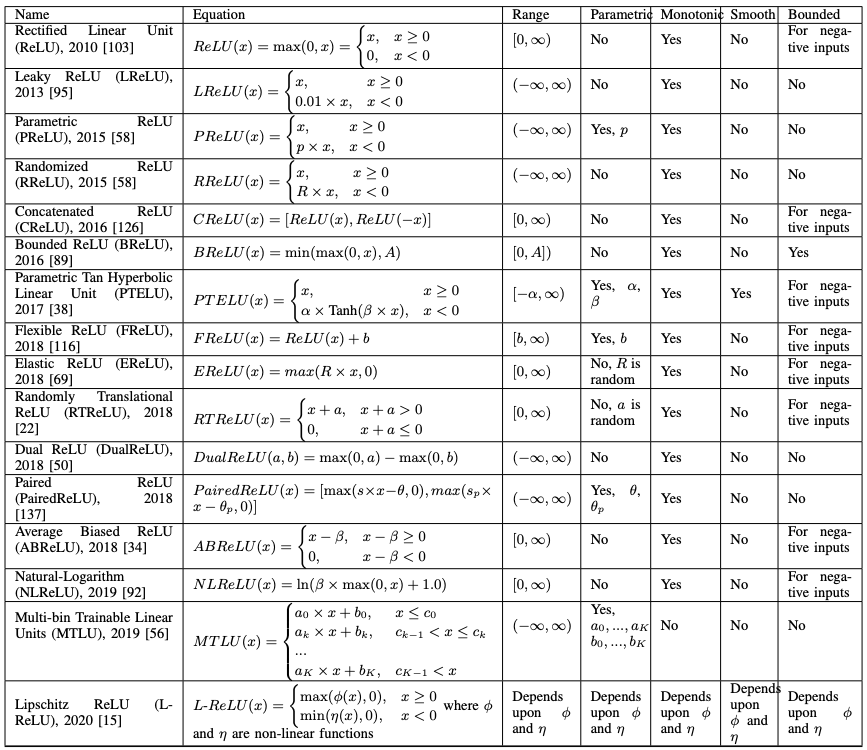
他にも様々なReLUの亜種が提案されています。
Exponential Activation Functions
Exponential系の活性化関数は、ReLUにおける勾配消失問題に取り組んだものです。
$$\operatorname{ELU(}x)= \begin{cases}x, & \text { if } x>0 \\ \alpha \times\left(e^{x}-1\right), & \text { otherwise }\end{cases}$$
ELUは、微分可能で大きな負の入力に対して飽和しており、このことがLeaky ReLUやParametric ReLUと比較してノイズに対し堅牢な性質となっています。
$$ \operatorname{SELU}(x)=\lambda \times \begin{cases}x, & x>0 \\ \alpha \times\left(e^{x}-1\right), & x \leq 0\end{cases} $$
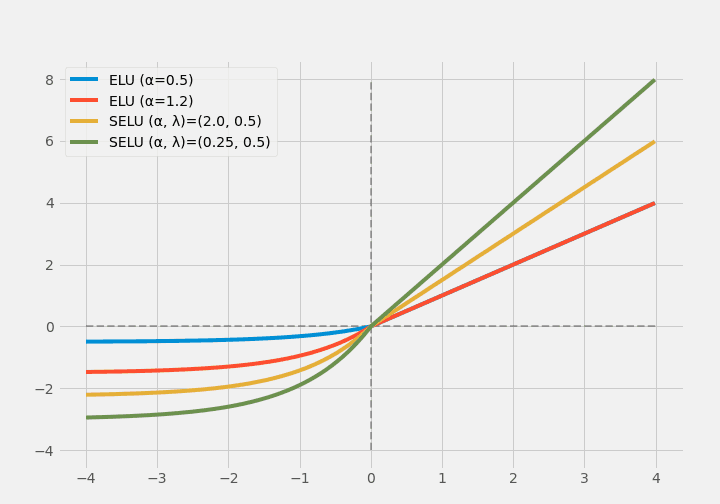
(註: x > 0の領域では、青色と赤色が重なっています。)
Scaled ELU(SELU)は、スケーリングのためのハイパーパラメータを使用しており、巨大な正の入力に対しても飽和しないようにしています。
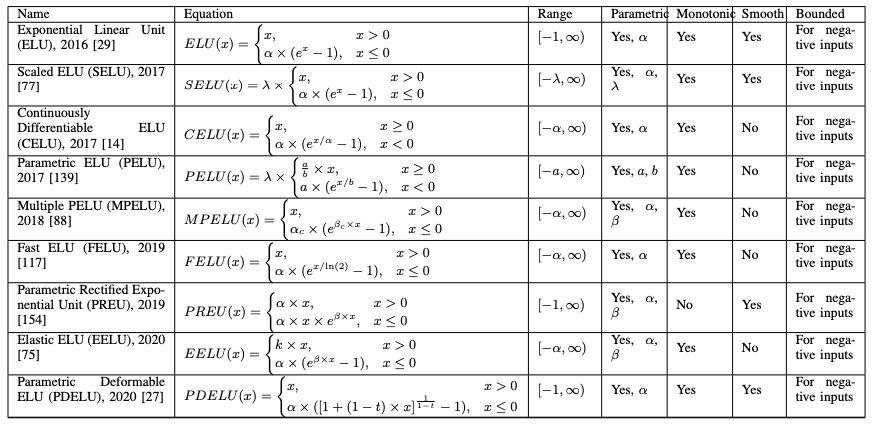
上記にELUの亜種をまとめます。どのELUでも大きな値に対する飽和、計算コストに対する対処が考慮されています。
学習/適応型活性化関数
前述した活性化の多くは適応型ではありませんでした。
$$\operatorname{APL}(x)=\max (0, x)+\sum_{s=1}^{S} a_{s} \times \max \left(0, b_{s}-x\right)$$
Adaptive Piecewise Linear(ALP)は、hinge-shape(ヒンジ型の、折れ線グラフ型の)活性化関数です。aとbは学習可能なパラメータであり、Sはヒンジ数を表すハイパーパラメータです。つまりニューロンごとにaとbの値が異なっており、それぞれのニューロンがそれぞれ独自の活性化関数を持っていることになります。
SwishはRamachandranらが提案したもので、自動探索によって見出しました。
$$ \operatorname{Swish}(x)=x \times \sigma(\beta \times x) $$
$\sigma$は、シグモイド型の関数です。SwishはReLUの形に似せて作られています。
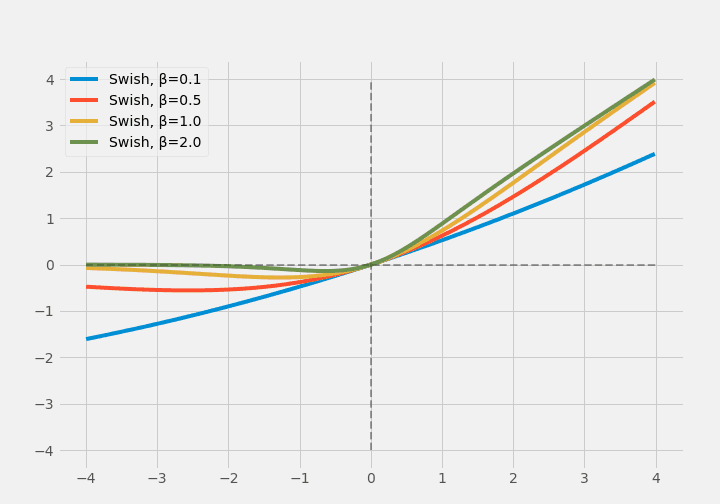
のちにSwishはESwishに拡張されました。
$$ \operatorname{ESwish}(x)=\beta \times x \times \sigma(x) $$
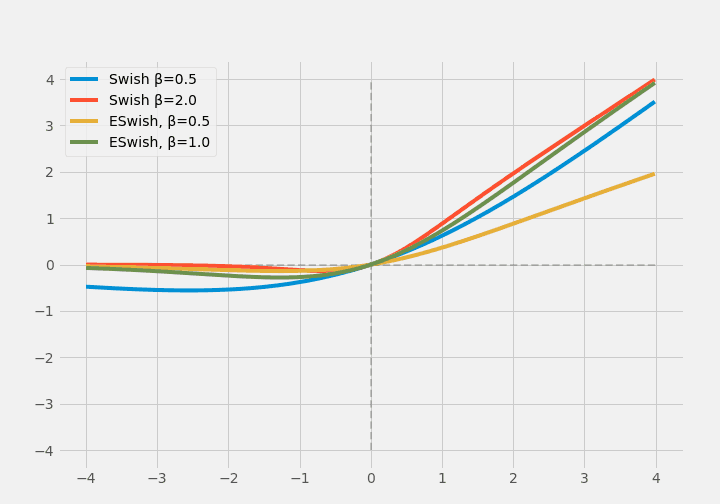
(註:$\beta=1.0$でSwishとESwishは一致するので、それぞれ$\beta$の値をバラバラにしています。それでもよく似た形になっています)
学習・適応型の活性化関数は、基礎となる活性化関数があり、そこに学習可能な変数を追加することで定義されます。例えば、前述したParametric ReLUとParametric ELUを使った適応型活性化関数には、$\sigma(w \times x) \times \operatorname{PReLU(x)} + (1-\sigma(w \times x)) \times \operatorname{PELU}(x)$と定義されているものがあります($\sigma$はS字型の関数で、$w$が学習可能な変数です)。
あるいは、それぞれのニューロンで異なる活性化関数を利用することもあります。これは学習可能な変数の値が異なった結果、それぞれのニューロンで異なる活性化関数を利用しているという意味ではなく、文字通り異なる活性化関数を利用します。ある研究では、ニューロンごとにReLUとTanhのいずれかを選び、その選択自体を学習するというものもあります。
学習可能なハイパーパラメータを利用しない活性化関数(nonparametrically learning AFs)として、上記のような1つの数式で書けるような活性化関数ではなく、活性化関数自体をごく浅いニューラルネットワークにするものも報告されています。これをハイパー活性化関数(hyperactivations)といい、そのネットワークをハイパーネットワーク(hypernetwork)といいます。
学習・適応型の活性化関数は、近年のトレンドです。より複雑で非線形なデータに対応すべく研究されていますが、当然計算コストが増加しています。以下に学習・適応型の活性化関数をまとめた表を示します。

その他の活性化関数
A. Softplus活性化関数
Softplus関数は2001年に提案され、統計学によく利用されていました。
$$ \operatorname{softplus}(x)=\log{(e^x+1)}$$
その後、ディープラーニングの大流行によってSoftmax関数がよく利用されることになります。Softmax関数は、分類タスクにおいてクラスごとに確率値を出力できる点が大きな魅力です。
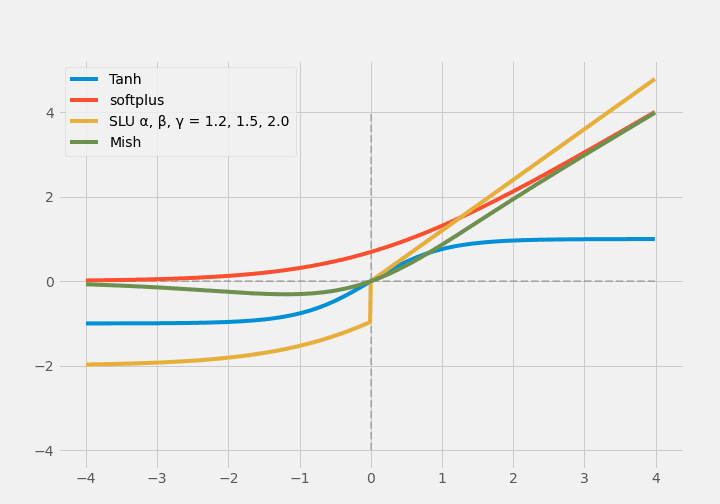
Softplusは滑らかで微分可能であるため、これをReLUに似せたものがSoftplus Linear Unit(SLU)です。
$$ \operatorname{SLU}(x)=\begin{cases} \alpha \times x, & x>0 \\ \beta \times \log{(e^x+1)} - \gamma, & x \leq 0\end{cases} $$
$\alpha, \beta, \gamma$は学習可能なパラメータです。
Mishと呼ばれる活性化関数は非単調写像(non-monotonic)な活性化関数で、ここにもSoftplusが使われています。MishはさらにTanhをも利用しています。
$$ \operatorname{Tanh}(x)=\frac{e^{x}-e^{-x}}{e^{x}+e^{-x}} $$
$$\operatorname{Mish}(x)=x \times \operatorname{Tanh(\operatorname{Softplus(x)})}$$
Mishは滑らかで、non-monotonicです。近年、YOLOv4に採用されています。ただし計算上複雑ですので、計算コストが大きい欠点もあります。
B. 確率的活性化関数
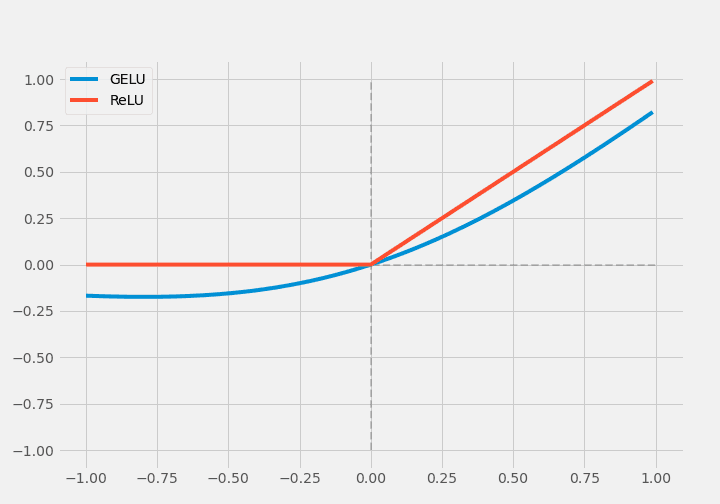
これまで確率的活性化関数は、その手間からあまり研究されてきませんでした。RReLU, EReLU, RTReLU, GELUは、このカテゴリに含まれる数少ない活性化関数です。GELU(Gaussian Error Linear Unit)は確率的正則化により非線形性が考慮されています。
$$\operatorname{GELU}(x)=x P(X \leq x)=x \Phi(x)$$
Φは$\Phi(x) \times I x+(1-\Phi(x)) \times 0 x=x \Phi(x)$と定義され、これが確率的正則化と呼ばれています。原著では$0.5 x\left(1+\tanh \left[\sqrt{2 / \pi}\left(x+0.044715 x^{3}\right)\right]\right)$と近似されています。
C. 多項活性化関数
Smooth Adaptive活性化関数(SAAF)は区分的な多項式活性化関数として開発されました。ReLUの線形部分に対称な2つのべき乗関数を組み合わせており、ReLUの性能を向上させました。
$$ \operatorname{SAFF}(x)=\sum_{j=0}^{c-1} v_{j} \mathrm{p}^{j}(x)+\sum_{k=1}^{n} w_{k} \mathrm{~b}_{k}^{c}(x) $$
where
$$ \begin{aligned} \mathrm{p}^{j}(x) &=\frac{x^{j}}{j !}, \quad \mathrm{b}_{k}^{0}(x)=\mathbb{1}\left(a_{k} \leq x<a_{k+1}\right) \\ \mathrm{b}_{k}^{c}(x) &=\underbrace{\iint \ldots \int_{0}^{x}}_{c \text { times }} \mathrm{b}_{k}^{0}(\alpha) \mathrm{d}^{c} \alpha \end{aligned}$$
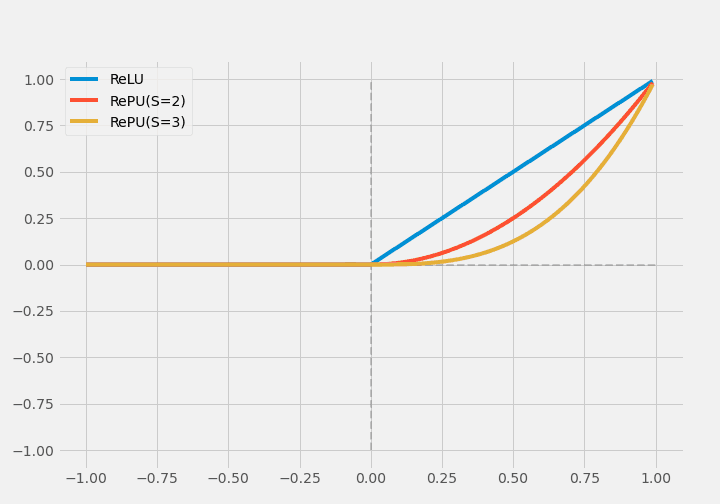
またReLUは、Rectified Power Unit(RePU)に拡張され、$ x>0 $部分では、$y=X^S$になっています($S$はハイパーパラメータ)。RePUはReLUと比べると、$x=0$付近でより滑らかです。しかし勾配消失のしやすさ、非拘束性(unbounded)、非対称性がRePUの欠点でもあります。
近年、Padé近似法が使われてたPadé Activation Unit(PAU)が開発されています。
$$ \operatorname{PAU}(x) = P(x) / Q(x) $$
PAUは上記のように定義されており、$P(x)$と$Q(x)$はそれぞれ$m$次、$n$次の多項式で、基本的に手作業(hand-designed)で定義されます。
$$F(x)=\frac{P(x)}{Q(x)}=\frac{\sum_{j=0}^{m} a_{j} x^{j}}{1+\sum_{k=1}^{n} b_{k} x^{k}}=\frac{a_{0}+a_{1} x+a_{2} x^{2}+\cdots+a_{m} x^{m}}{1+b_{1} x+b_{2} x^{2}+\cdots+b_{n} x^{n}}$$
原著では上記のように定義されています。
各活性化関数のパフォーマンス比較
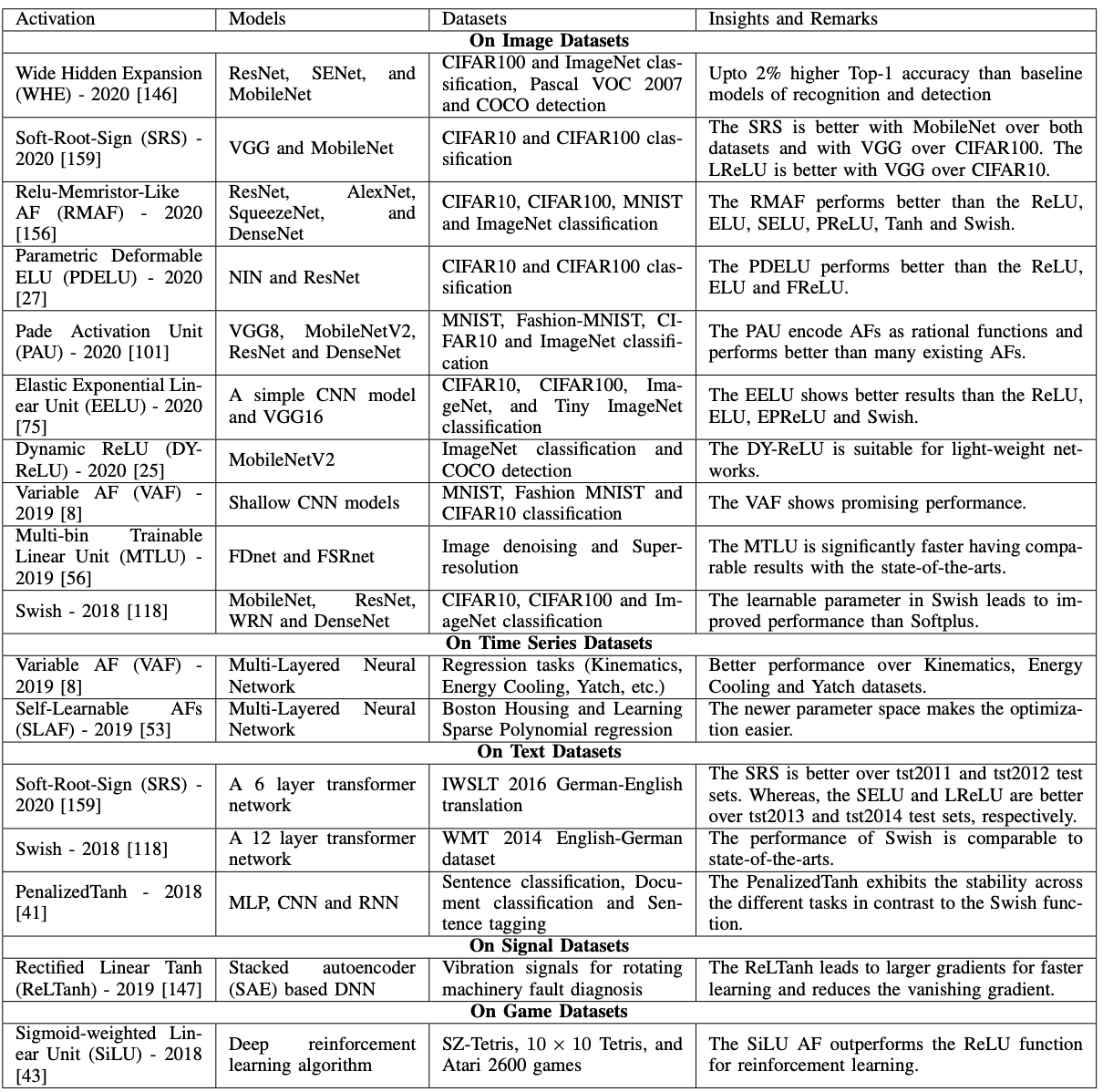
上の表がすでに報告されているSOTAを達成した活性化関数の一覧です。これまで説明したもののうち、Padé Activation Unit(VGG8でMNIST)、Swish(MobileNet,ResNetでCIFAR10,CIFAR100)があります。データセットは画像、時系列、テキスト等様々ですが、Swishを除き、データセットが変わるとSOTAを達成した同一の活性化関数がないことがわかります。
CNNでの実験
論文ではなく、実際にモデルを実装して比較しました。データセットはCIFAR10です。
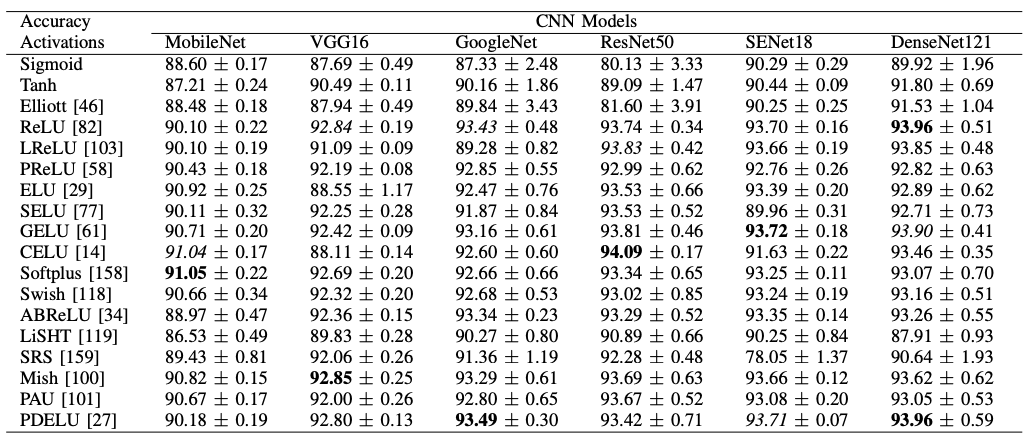
データセットは共通ですが、モデルが変わるとそれに適した活性化関数も変化していることがわかります。
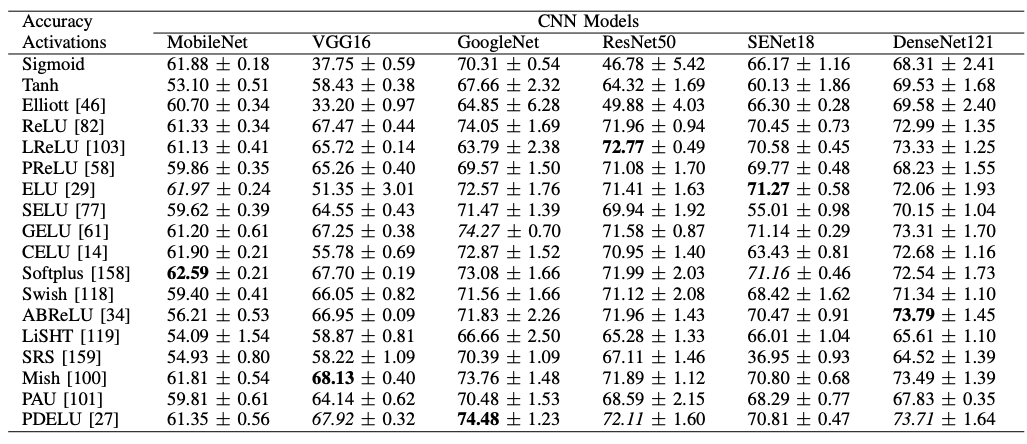
上記はデータセットをCIFAR100に変更した結果です。MobileNet, VGG16, GoogleNetでは、最高性能の活性化関数がCIFAR10と同じですが、ResNet50, SENet18, DenseNet121では結果が変わってしまいました(ただし、CIFAR10で最高性能だった活性化関数は相変わらず性能は良いです)。
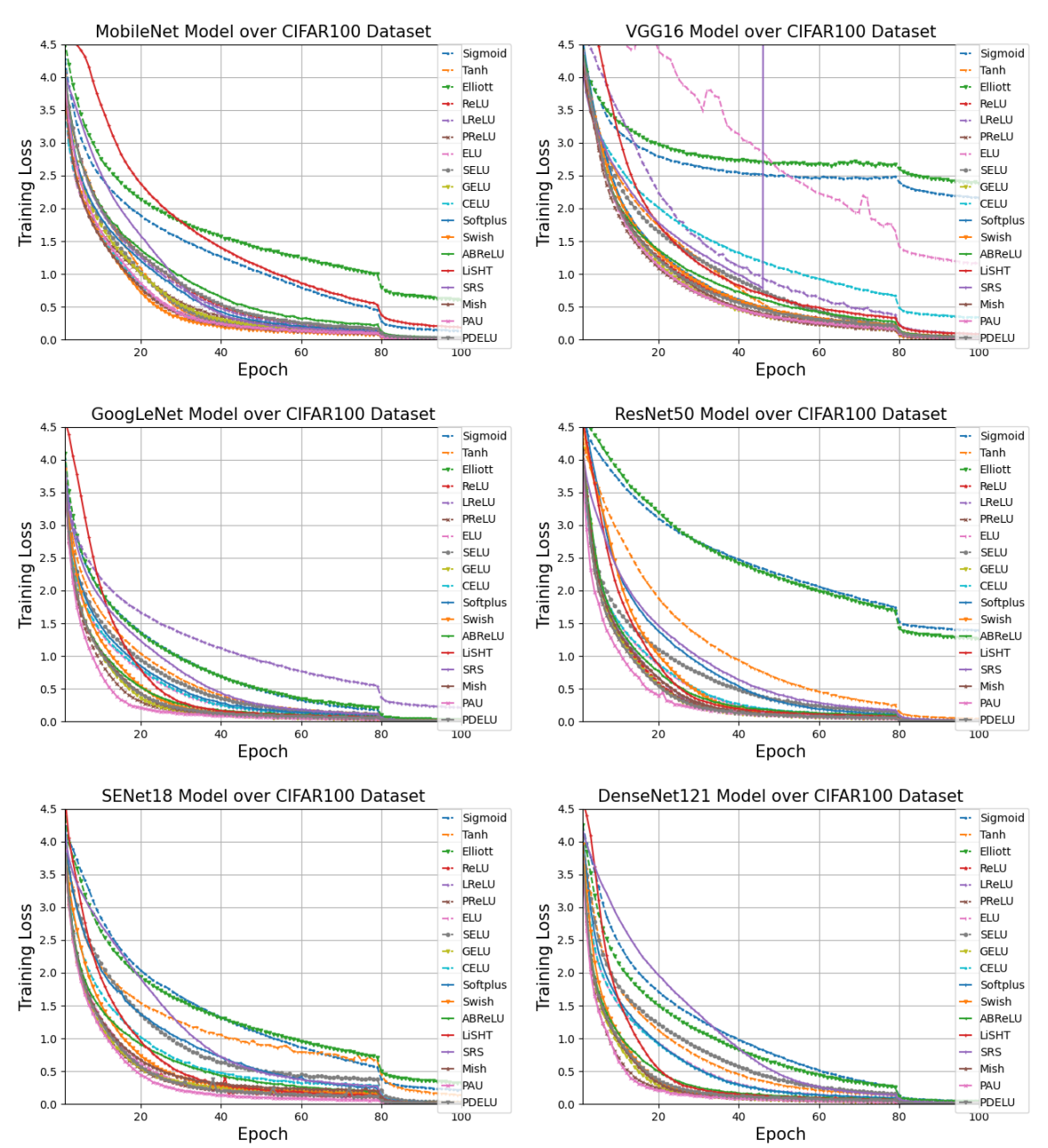
各モデルの損失を示したグラフです。活性化関数が色で区別されています。グラフの凡例で、ReLU以下の活性化関数であれば、時間をかけて損失をゼロに近づけられそうです。そこで100エポックにかかる時間を比べてみましょう。
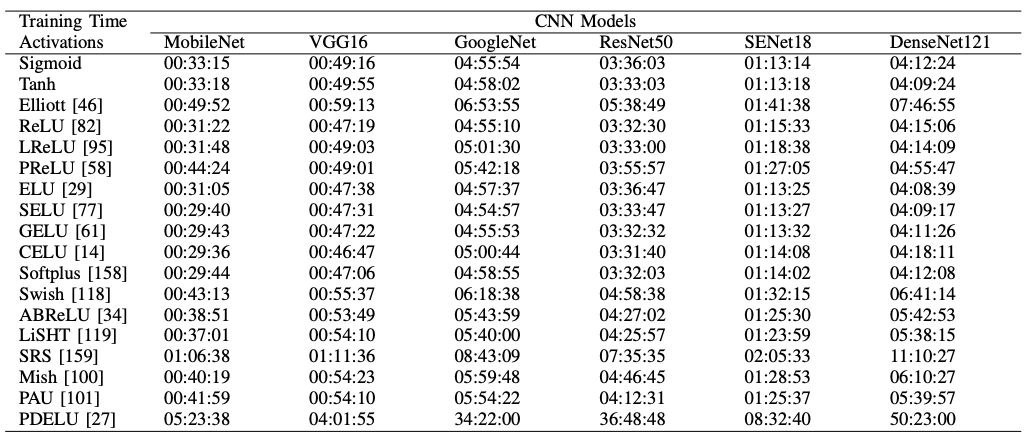
PDELUだけが群を抜いて時間がかかっていますね。
$$\operatorname{PDELU}(x)= \begin{cases}x, & x>0 \\ \alpha \times\left([1+(1-t) \times x]^{\frac{1}{1-t}}-1\right), & x \leq 0\end{cases}$$
(註: PDELUに関しては、原著がオープンアクセスではなく、変数$t$の意味が未確認です。申し訳ございません。)
結論
本論文では、活性化関数に関する広範な調査と実験を行いました。異なるタイプの活性化関数が報告されてきましたが、本論文では特に深層学習における性能について述べました。本論の結論を以下にまとめます。
- ロジスティックシグモイド・ハイパボリックタンジェント系列の活性化関数は、非ゼロ平均と勾配消失に対して進歩してきた。しかしその進歩は計算コストを増加させた。
- ReLU系列は、負のインプットの活用不足、制限のある非線形性、上限のないアウトプットに対して進歩してきた。しかしほとんどの場合、ReLUがベターであり、今でも研究者の第一選択はReLU(もしくはLeaky ReLU, Parametric ReLU)である。
- Exponential系列は、負のインプットを活用することが焦点である。ただほとんどの場合、滑らかでないのが問題である。
- 学習・適応系列は、近年のトレンドであるが、当然というべきか、基礎となる関数の設定、パラメータ数の設定が問題である。
そして以下が著者らの提言です。
- 学習時間を短くしたければ、出力の平均が0で、正と負ののインプットを活用する活性化関数を用いると良い。
- 重要なのはデータの複雑さに見合ったモデルを選択することである。活性化関数は、データの複雑さとモデルの表現力の橋渡しに過ぎず、2つのギャップが大きすぎれば破綻(過剰適応か学習不足)に陥る。
- ロジスティックシグモイド・ハイパボリックタンジェント系列は、CNNに使うべきではない。この種の活性化関数はRNNに有効である。
- ReLUは良い選択である。しかしSwish, Mish, PAUも試すべきだろう。
- ReLU, Mish, PDELUはVGG16とGoogleNetに使うべし。
- ReLU, LReLU, ELU, GELU, CELU, PDELUは、残差結合(residual connection)をもったモデルの画像分類タスクに使うべし。
- 一般的にパラメトリックな活性化関数は、より早くデータに適合できる。特にPAU, PReLU, PDELUはおすすめだ。
- PDELU, SRSは、学習時間を長くする。
- ReLU, SELU, GELU, Softplusは、学習時間が短いと精度が下がる。断言できる。
- Exponential系列は負のインプットを活用しやすい。
- Tanh, SELUは自然言語処理に適している。PReLU, LiSHT, SRS, PAUも良い。
- PReLU, GELU, Swish, Mish, PAUは音声認識に良いとされている。
以上です。
長くなりましたが、具体的な指標が見えて開発に役立ちそうですね。






この記事に関するカテゴリー





