一个新的转移指数OTCE在跨域串联环境中的应用
三个要点
✔️ 提出了不同领域任务之间转移学习中监督分类任务的可转移性新措施。
✔️ 在使用Domain Net和Office31(由多个不同领域组成的数据集)的实验中,与之前的研究相比,所提出的指标与准确性之间的相关性平均提高了21%。
✔️ 与以前的研究中的指数相比,证实了所提出的指数对源模型选择的有用性。
OTCE: A Transferability Metric for Cross-Domain Cross-Task Representations
written by Yang Tan, Yang Li, Shao-Lun Huang
(Submitted on 25 Mar 2021)
Comments: CVPR2021.
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的 。
简介
一般来说,为了在机器学习中做出准确的预测,需要使用大量的数据进行训练。然而,并不总是能够收集到足够数量的数据。这就是为什么有很多人对转移学习是一种技术,它通过重复使用预先训练好的模型并使用模型学到的特征提取能力来减少所需的学习量。
在迁移学习中,众所周知,当预训练的模型所学习的领域/任务与新模型试图学习的领域/任务相同时,学习是高效的。另一方面,与领域和任务相同的转移学习相比,不同领域和不同任务之间的转移学习是一个更加普遍和困难的问题。
在本文中,我们提出了一个称为基于最优传输的条件熵(Optimal Transport based ConditionalEntropy,OTCE)的可转移性措施,以预测这种跨领域、跨任务转移学习中监督分类任务的可转移性。
OTCE将可转移性描述为领域和任务差异的组合,在一个统一的框架内从数据中明确地评估这些差异。
具体来说,它使用最佳传输来估计领域差异,并估计源和目标分布之间的最佳耦合,我们得出目标任务的条件熵(任务差异)。
运输优化问题
在进入所提出的方法的描述之前,我们将解释运输优化问题。
什么是运输优化问题?1781年1781年,法国数学家和工程师加斯帕德-蒙日提出了以下问题:"我们想把一堆沙子移到一个相同体积的洞里。如果移动沙子的成本取决于它的移动距离,那么什么是最好的移动方式?
下面是一个一般运输优化问题的表达式。成本函数$c(x,y)$表示将产品从其当前位置运输到目的地的成本。耦合矩阵表示从某一点到目的地的运输量。
在本文中,我们解决了$Pi(\alpha,\beta)$的运输优化问题,以找到一个在本文中,我们解决了$Pi(\alpha,\beta)$的运输优化问题,以找到最佳耦合矩阵,使从一个概率分布到另一个概率分布的运输成本最小。

建议的方法
在提出的方法中,我们把可转移性分为跨领域和跨任务的转移学习中的领域差异和任务差异。首先,我们解释域差$W_D$的部分。
最初,我们通过解决如下所示的传输优化问题,获得源域$D_s$和目标域$D_t$的最佳耦合矩阵$pi(x,y)$。
其中$x^i_s$和$x^j_t$分别指源图像和目标图像,$\theta$指特征提取周期,加入熵正则化项,用Sinkhorn算法解决传输优化问题。

使用通过解决运输优化问题得到的最佳耦合矩阵,使用以下公式得到域差
由于迁移学习通常使用在源模型上训练的特征提取器,如果目标图像与源图像相似,$||\theta(x^i_s)-||\theta(x^j_t)||^2_2$的值会更小,而域差如果目标图像与源图像相似,$W_D$将变小;如果目标图像与源图像不相似,域差$W_D$将变大。

接下来,我们将解释任务差异的部分$W_T$。
首先,我们通过使用最优耦合矩阵$pi(x,y)$,得到同时存在的概率${\hat P}(y_s,y_t)$和${\hat P}(y_s)$的估计。

这里有一个公式,可以利用这样得到的同时概率${\hat P}(y_s,y_t)$和${hat P}(y_s)$的估计值找到任务差$W_T$。
任务差异$W_T$是通过使用条件熵$H(Y_t|Y_s)$得到的,它可以通过使用同时存在的概率${\hat P}(y_s,y_t)$和${\hat P}(y_s)$表示。这里,$Y_s$和$Y_t$分别指整个源标签和目标标签的集合$y_s$和$y_t$。
熵是平均信息量的术语,是衡量一个来源产生多少信息的标准。信息越是出乎意料,就越有价值,熵也就越高。
这里使用的条件熵$H(Y_t|Y_s)$是指当$Y_s$已知时从$Y_t$获得的平均信息量,这个值越小,说明两个来源越相似。
另外,$H(Y_t|Y_s)$可以通过使用同时存在的概率${\hat P}(y_s,y_t)$和${\hat P}(y_s)$来表示。

域差$W_D$和任务差$W_T$与相应的权重$\lambda_1$和$\lambda_2$相加,再加上一个偏置项$b$,得到OTCE,OTCE的值越高意味着可转移性越高。

使用的数据集,实验设置
本文使用的两个数据集如下所示。

为了考虑在不同领域和任务之间的设置中使用这两个数据集的分类任务的可转移性估计的问题,我们用基于以下实验设置我们用以下实验装置进行了实验
以一个域为源域,另一个域为目标域的迁移学习
・随机获得域网中44个类别和Office31中15个类别的分类任务作为源任务
・每个源任务用8个源模型训练:Domain Net中的5个域和Office31中的3个域
・优化方法:SGD,损失函数:Cross熵
实验结果与以往研究中的可转移性指数LEEP、NCE和H-score的比较
・研究可转移性指数与准确性之间的相关性的实验(在目标数据上训练源模型100次后的测试准确性)。
1.基本设置
2.多源应用
实验结果
在开始时,我们介绍了实验装置1的实验结果。下表显示了下表显示了可转移性指数和测试时的准确性之间的相关系数。比较每个指数的平均精确度,我们发现OTCE:92.6%,LEEP:88.3%,以及NCE: 84.9%,以及H-score:73.0 %,表明OTCE显然比其他指标更准确。
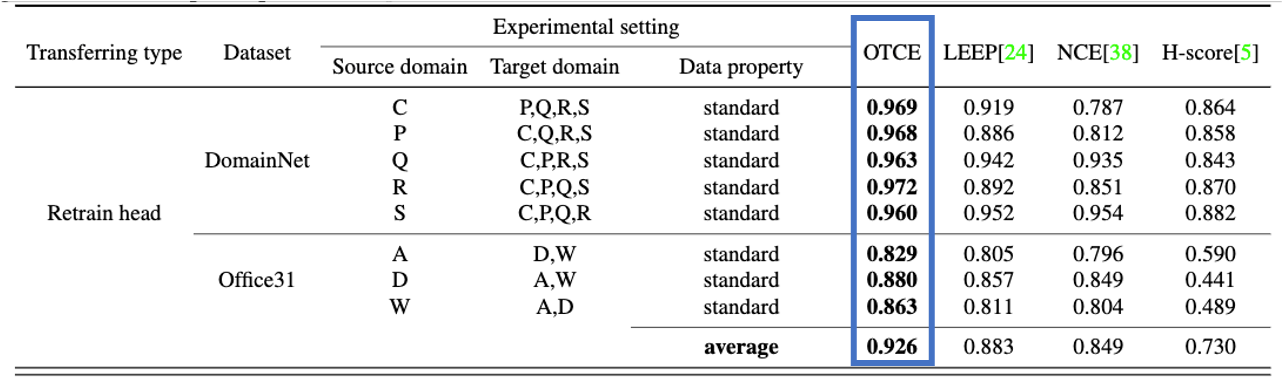
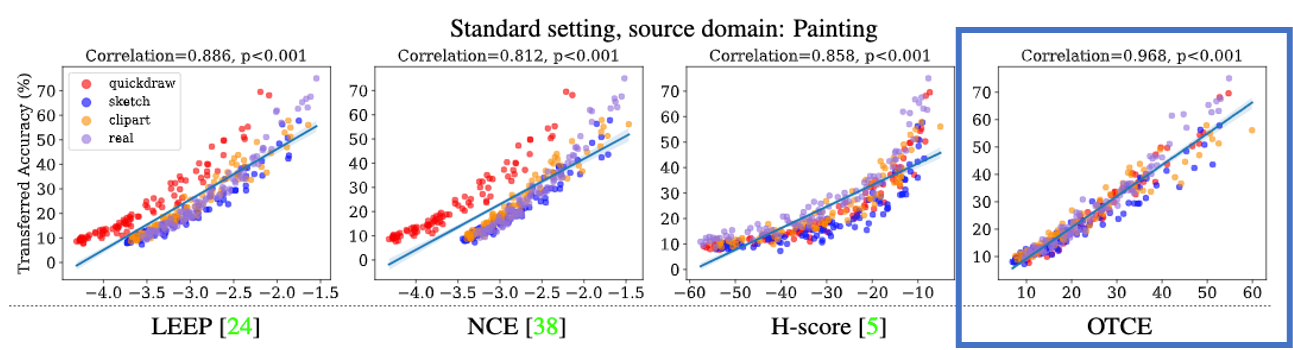
上表中的数值也被绘制在下图中。在这个图中,横轴代表可转移性指数,纵轴代表测试时的准确性。对于每一个指数,绘制时的相关值进行了比较LEEP: 0.886和NCE: 0.812和H-score: 0.858, 和OTCE: 0.968和图中显示图中显示,OTCE该图显示,OTCE的准确性高于转移指数与准确性之间的强相关性在偏移性和准确性之间。
下一节介绍了实验装置2的实验结果。在这个实验中对于一个给定的目标领域,随机选择100个目标任务,并且对于每个目标任务,我们准备四个以前在其他领域训练过的源模型。
在这个实验中,使用具有最佳偏移指数的源模型为每个我们使用具有最佳可转移性指数的源模型,为每个下表中的数值是预测成功率(即具有最佳转移指数的源模型在多大程度上超过了其他源模型)。下表中的数值显示了预测成功率(具有最佳转移指数的源模型比其他源模型更准确的次数/总试验数)。

在这里,在这个实验中,H-score并没有给出任何有意义的结果,所以我们比较了OTCE、LEEP和NCE的预测准确性。我们比较了OTCE、LEEP和NCE的预测准确性。
对于每个指标对比一下LEEP: 52.2和NCE:67.5,和训练营:86.4和可以确认的是,OTCE比其他指标更有用。可以确认的是,OTCE对于源模型的选择比
摘要
在本文中,我们考虑了在跨领域交叉任务转移学习的一般背景下估计可转移性的问题。
所提出的OTCE在领域和任务差异的基础上描述了可转移性,并且与其他转移性措施(LEEP、NCE、H-score)相比人们发现它更适合于在跨领域、跨任务的环境下捕捉可转移性。
OTCE也被证明对选择源模型是有用的,我们认为这是一个在未来可以有多种应用的指标。



与本文相关的类别




