
RELIC:大活躍中の対照学習を因果論で解釈してみた
3つの要点
✔️ 対比学習を因果論の視点から解釈したみた論文
✔️ 画像のスタイルがタスクに影響しないような制限をかけたRELIC Lossを提案
✔️ 学習した表現はロバスト性と汎化性に優れていることをImageNet-CとImageNet-Rで検証した
Representation Learning via Invariant Causal Mechanisms
written by Jovana Mitrovic, Brian McWilliams, Jacob Walker, Lars Buesing, Charles Blundell
(Submitted on 15 Oct 2020)
Comments: Published on arxiv.
Subjects: Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (stat.ML)
code:
本記事で使用している画像は論文中のもの、またはそれを参考に作成したものを使用しております。
はじめに
SimCLR(解説記事)とBYOL(解説記事)をはじめ、対照学習(Contrastive Learning)は現在大きく活躍しています。自己教師あり学習でラベルデータを必要としないため、BERTのように膨大なデータで事前学習して下流タスクに応用でき、注目を集めています。
一方で、対比学習の原理に関する理論解釈がいまだに完成していません。一時期に画像とその表現との相互情報量最大化が重要という説は有力でしたが、On Mutual Information Maximization for Representation(解説記事)の論文で相互情報量理論だけでは対照学習を解釈できないことがわかりました。
空前の大盛況な対照学習の発展に理論が追いついていないのが現状です。本日はDeepMindが発表した因果論の思想を取り入れた対照学習の理論解釈を行う論文を紹介します。
2. 提案手法:REpresentation learning via Invariant Causal mechanisms(RELIC)
著者たちはa. 対照学習の先行研究を因果論で解釈した上で、b. RELIC損失関数を提案しました。順に説明していきます。
2.a 対照学習の先行研究を因果論で解釈
著者たちが描いた因果グラフはデータ生成(Data generation)の部分と表現学習(Reprensentation Learning)の部分から成り立っています。
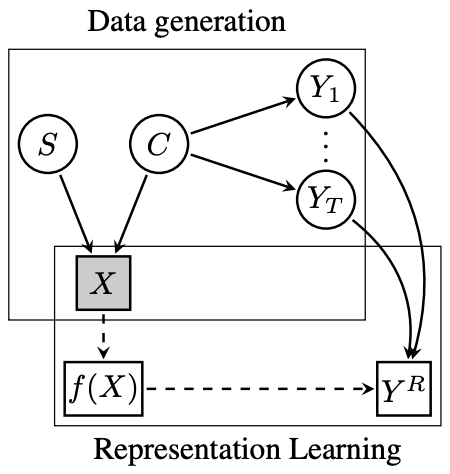
データ生成(Data generation)には次の3つの仮説が含まれています。
- 画像(X)はコンテンツ(C)とスタイル(S)から生成される
- コンテンツ(C)のみが下流タスク(Y_1...Y_T)に影響を与える
- コンテンツ(C)とスタイル(S)はお互いに独立している
表現学習(Representation Learning)では、画像(X)からf(X)表現を学習して代理タスク(Y^R)を解いています。ここでの代理タスク(Y^R)は下流タスク(Y_1...Y_T)から影響を受けるものと考えています。つまり下流タスク(Y_1...Y_T)を解くのに必要十分な情報を代理タスク(Y^R)で学習できることが必要と仮定しています。
ここで、既存の対照学習(Contrastive Learning)で行われているインスタンス分類タスク(Instance classification)が代理タスクに該当します。下流タスクであるクラス分類タスクに対して、インスタンス分類タスクは画像そのものを他の画像と区別するタスクであるためより難しいです。従って、このより難しい代理タスクを解ける表現f(X)を学習すれば下流タスクは理論上解けます。これは既存の対照学習がうまくいく原因と考えられます。
2.b RELIC損失関数を提案
これで因果グラフを用いて対照学習の先行研究を解釈できました(数式は後ほど示す)。本研究の著者たちは、画像(X)の要素の一つであるスタイル(S)は下流タスクに影響を与えることがないと仮定するため、代理タスクを解く際にスタイル(S)を変化させても結果が変わらないように式(2)の制限をかけます。
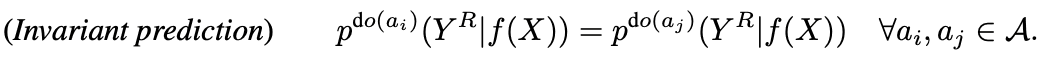
つまり、データ拡張の集合Aから2種類の拡張を画像に適応しても代理タスク(Y^R)における結果が不変であるようにします。損失関数として書き直すと次のようになります。
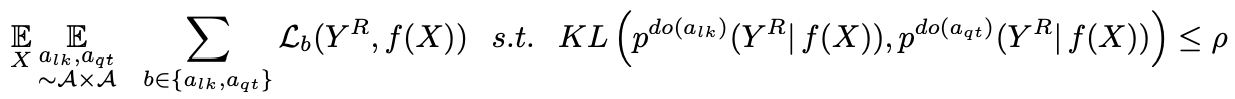
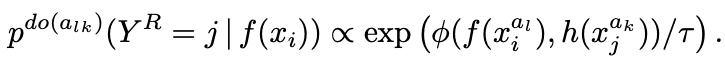
この損失関数と従来の対照学習で使われている損失関数と組み合わせると式(3)になります。
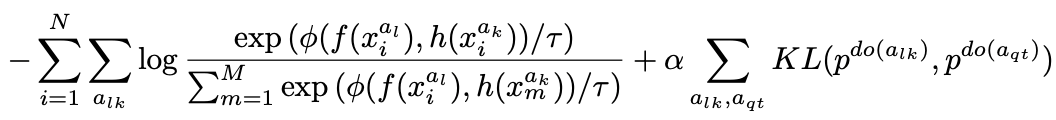
ここで従来の対照学習で使われている損失関数は式(3)の1つ目の項目で表せることを、次の表を参考にするとわかります。
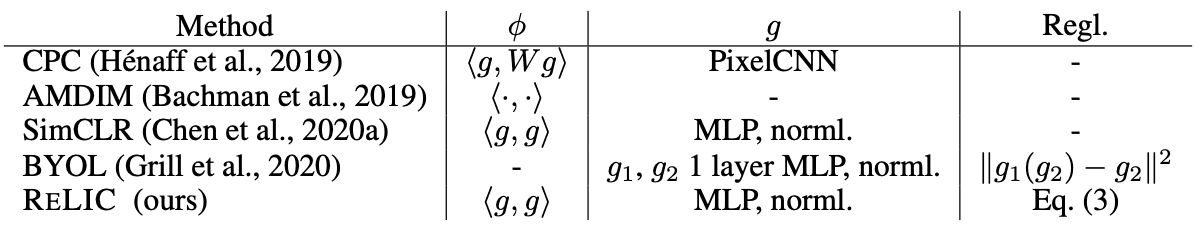
式3と表における関数の表記を説明します。f()はデータから表現を学習する関数で、h()はf()と同じアーキテクチャを持つ関数になります。ただし、h()自体のパラメータを更新せずに、f()のパラメータの移動平均を使う際は、target networkアーキテクチャと呼ばれます。また、f()やh()で得られた表現をより小さい潜在変数にマッピングする際にg()を使います。g()によってマッピングした潜在変数間の距離を測るのは、Φ()になります。
従って、提案するRELICの損失関数(式3)は従来の損失関数とスタイル(S)が代理タスクに影響しないようにした制限と組み合わせたものになります。
次の図は提案したRELIC損失関数を説明したものになります。入力に対して2種類の変換を行なって得られた2つ表現による、他の表現との類似度確率分布はKL距離で近づけていると解釈できます。
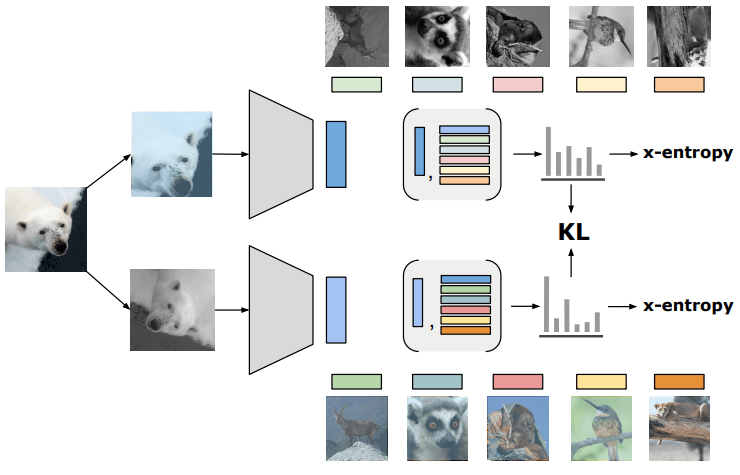
提案手法の紹介は以上になりますが、本研究のハイライトはこういった因果論的な制限と解釈を理論的に証明されたことであるので、Appendix Bの証明を参考にするといいかもしれません。
実験
実験の部分では、a. 学習した表現の良さを線形評価します。b. スタイル(S)の影響を取り除いた表現が提案手法で得られるので、そのロバスト性と汎化性を評価します。
3.a 線形分類で表現の良さを評価
・Fischer's linear discriminant ratio.
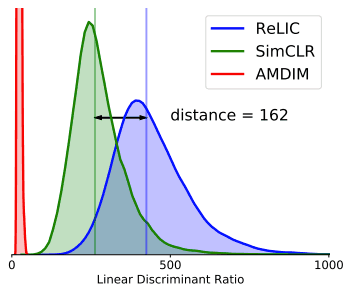 まず、線形分類のしやすさを指標として、学習した表現の良さを評価します。ここで用いたのは、Fischer's linear discriminant ratioという指標で、次の式で計算されます。
まず、線形分類のしやすさを指標として、学習した表現の良さを評価します。ここで用いたのは、Fischer's linear discriminant ratioという指標で、次の式で計算されます。
![]()
ただし、![]() である。
である。
この値は大きければ大きい程よい表現となるので、BaselineのSimCLRと比較しても良い表現であることがわかります。
・ImageNet
次にImageNetを使った線形評価を行います。
対照学習の問題設定はImageNetを使って教師ラベルなしで表現学習します。得られた表現に線形分類器を新たにくっつけて分類精度を測定します。シンプルな線形分類器を使うので、表現の良さが直接分類精度に寄与すると考えられて、スタンダードな評価方法となっています。
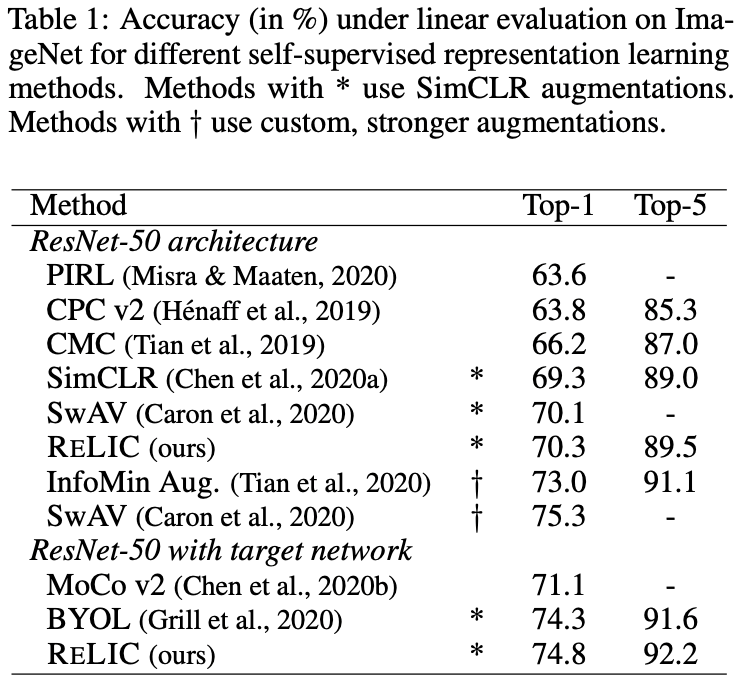
提案手法RELICはSimCLRベースと(Target Networkを持つ)BYOLベースの2種類があります。上記の図にそれぞれの結果を載せており、先行研究と同等程度の結果が得られています。ただし、Target Networkを持たないSimCLRベースのRELICはInfoMin Aug.とSwAVといった手法に及ばないことに対しては、著者たちは比較手法の方ではより強力なデータ拡張を用いたことに起因していると考察されていました。この結果からデータ拡張が対照学習において重要な役割を担っていることがわかります。
3.b 異なるデータセットでRELICのロバスト性と汎化性を評価
・ImageNetの拡張データセットでロバスト性を評価
ImageNetを用いた線形評価では目立った結果が得られていないが、提案手法RELICはスタイル(S)による影響を取り除いたコンテンツ(C)の情報のみを学習した表現と考えられるため、ロバスト性に関する評価を行いました。
まずImageNet-Rデータセット(Figure 7.)を用いて、事前学習時と異なるデータセットで分類精度を測定します。

分類のエラー率を指標として、教師あり学習とSimCLRとBYOLと比較した結果をTable 2.に載せました。教師あり学習より精度が悪いが、比較手法より優れていることがわかります。

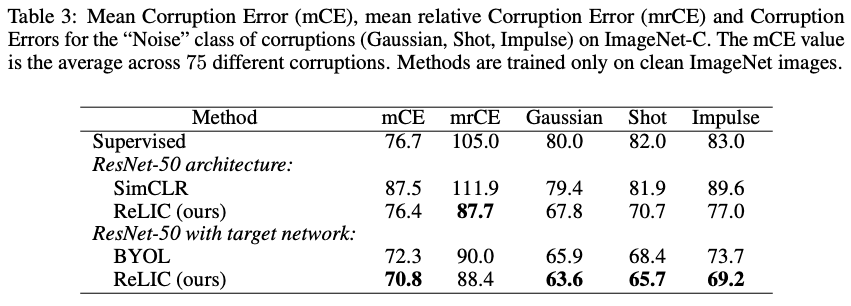
さらに、ImageNetの画像に15種類のノイズ(Fig 5.)とそれぞれ異なる程度(Fig 6.)で75種類の干渉を行ったデータセットImageNet-Cでロバスト性を評価しました。


複数のエラー率を指標として比較した結果(Table 3.)、提案手法RELICは確かにロバスト性が高いことが言えます。これでスタイルに対する不変性を意図した提案手法RELICの損失関数の有効性が示されています。
・強化学習の57 Atari Gamesで汎化性を評価
表現学習の魅力は、学習した良い表現は下流タスクに応用できることが挙げられます。本研究では、提案手法RELICで得られた表現は強化学習のベンチマーク 57 Atari Gamesで評価実験しました。R2D2というRNNと強化学習のDQNを組み合わせた手法をベースとして、CURLやBYOLと比較しています。
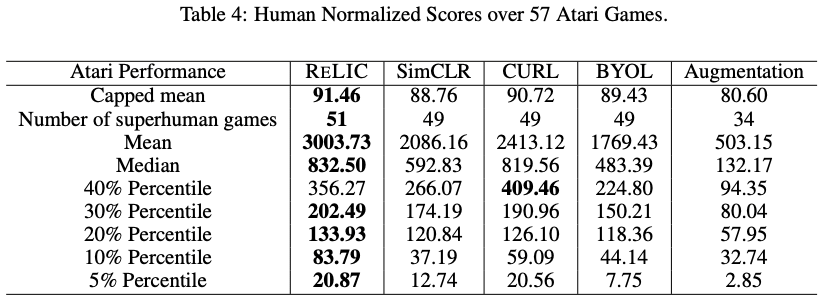
Table 4.に示された結果を見ると、提案手法はSimCLRやBYOLより汎化性が良いことがわかります。また、CURLという強化学習の研究で提案された研究とも比較しています。表現学習は強化学習のベンチマークで実験することは滅多にないと思うので、DeepMindらしい面白い実験だと感じました。
まとめ
本記事では、対照学習の研究を統合的に解釈する論文を紹介しました。記事では書ききれないほど厳密な定理証明がなされており、因果論ならではの理論的なアプローチでした。詳細について知りたい方、また数学に自信がある方は是非一度論文を開いて読んでみることをお勧めします。
一言でまとめると、スタイル(S)がタスクに影響を与えないことを仮定しで、定義したRELIC損失関数を用いて実装した研究でした。
一方で、対照学習のデータ拡張にフォーカスして、スタイル(S)とコンテンツ(S)を分離すべきであると因果論ベースで主張する類似研究として、2021年6月のSelf-Supervised Learning with Data Augmentations Provably Isolates Content from Styleが挙げられます。
このように関連研究が今も多く発表されており、大変興味深い分野で今後も注目していきたいと思います。



この記事に関するカテゴリー






