自己教師あり対照学習が成功するために必要なデータセットの条件とは?
3つの要点
✔️ 4つの大規模画像データセットで自己教師あり対照学習について分析
✔️ データ量、データドメイン、データの質、タスク粒度の観点からデータセットの影響を調査
✔️ 自己教師あり学習が成功するための好ましいデータセット条件についての知見を示す
When Does Contrastive Visual Representation Learning Work?
written by Elijah Cole, Xuan Yang, Kimberly Wilber, Oisin Mac Aodha, Serge Belongie
(Submitted on 12 May 2021 (v1), last revised 4 Apr 2022 (this version, v2))
Comments: CVPR 2022
Subjects: Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
ImageNetによって事前学習を行う自己教師あり対照学習は、多くの下流タスクで有効な視覚表現の生成に成功しています。
では、こうした自己教師あり対照学習の成功は、ImageNet以外の他のデータセットにおいても再現することができるでしょうか? また、どのような条件を満たすデータセットならば、自己教師あり対照学習は成功するでしょうか?
本記事で紹介する論文では、4つの大規模データセットにおける自己教師あり対照学習について研究することで、この問いに答えました。
より具体的には、事前学習時のデータ量、データセットのドメイン、データの質、タスクの粒度などが自己教師あり対照学習にもたらす影響について調査しました。
実験設定
まず、自己教師あり対照学習におけるデータセットの影響を調べるための実験設定について説明します。
データセット
実験では、次に述べる4つの大規模データセットを利用します。
- ImageNet:1kのクラスからなる1.3Mの画像データセット(ImageNet-21kデータセットのILSVRC2012サブセットを使用)
- iNat21:10kのクラスからなる2.7Mの動植物画像データセット
- Places365:365のクラスからなる1.8Mの画像データセット(全画像が256x256にリサイズされた「Places365-Standard(small images)」を使用)
- GLC20):16のクラスからなる1Mのリモートセンシング画像データセット
固定サイズのサブセットについて
実験では、サンプルサイズの影響を調べるため、各データセットのうち1M、500k、250k、125k、50k枚の画像を選択したサブセットも利用します。
このサブセットのサンプリングは一度のみ行われ、画像の選択は一様・ランダムに行われます。各サブセットは入れ子になっており、例えばImageNet(500k)にはImageNet(125k)の全画像が含まれています。また、使用したトレーニングサブセットに関係なく、テストセットは同一となります。
学習の詳細
論文では主にSimCLRで実験を行います。バックボーンとしてResNet-50を利用しており、標準的なプロトコル(自己教師あり学習の後、線形分類器またはエンドツーエンドのFine-tuningを行う)に従っています。
実験結果
実験では、データ量、データセットのドメイン、データの質、タスクの粒度が対照学習に与える影響の調査を行いました。
データ量
はじめに、自己教師あり対照学習におけるデータ量について考えます。
ここで、データ量には以下に述べる二つの重要な概念が存在します。
- 事前学習時に用いるラベルなし画像の数
- 分類器の学習に用いるラベル付き画像の数
これら二つのうち、ラベル付き画像は効果であり、可能な限り少ない数でも汎化できる表現を学習することが望ましいです。また、ラベルなし画像は安価に入手できるものの、事前学習に要するコストと比例関係にあります。
これら二つのデータ量と性能の関係を調べるため、様々な数のラベルなし画像でSimCLRを学習させ、様々な数のラベル付き画像で評価を行った場合の結果を評価します。結果は以下の通りです。
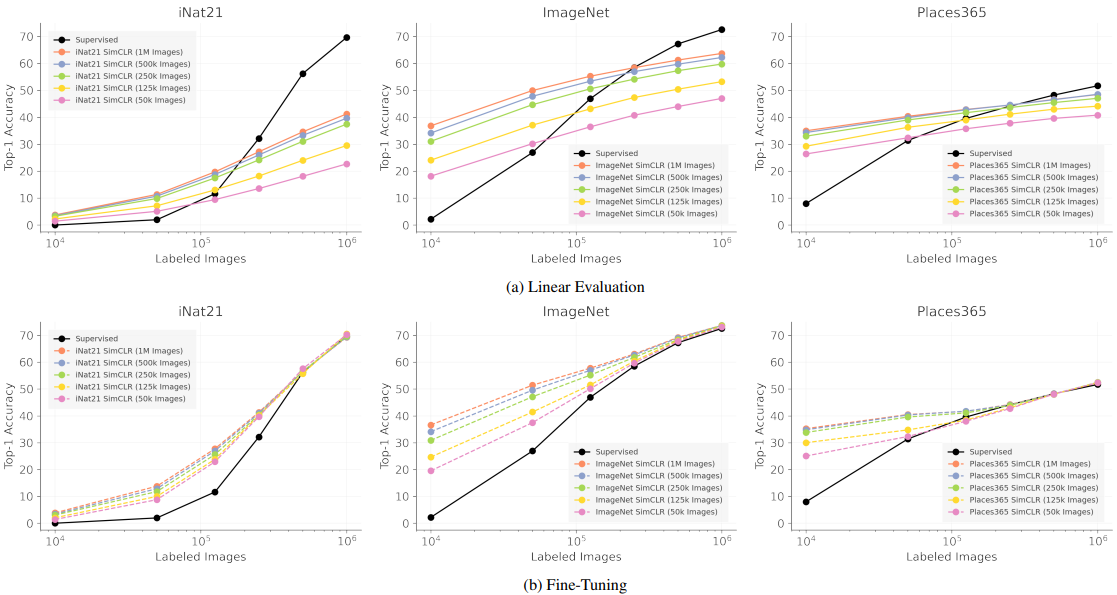
Supervisedはゼロから学習した場合の結果に対応しています。
この結果から示唆されることは以下の通りです。
- 事前学習時に500kを超える画像を使用しても効果は希薄です:500kまたは1Mの画像を事前学習に使用した場合、Top-1精度の低下は1~3%程度に抑えられており、わずかな精度低下と引き換えに事前学習時間を大きく削減することが可能です。
- 自己教師あり学習(SSL)は教師あり画像が限られている場合に良い初期化となります:ラベル付き画像の枚数が10kまたは50k程度の場合、SimCLR表現のFine-Tuningは非常に優れた結果を示しています。
- 自己教師あり表現が完全な教師あり表現と近い性能を発揮するには、大量のラベル付き画像が必要となります:自己教師あり学習の最終的な目標は、少ないラベル付きデータのみで教師あり学習と匹敵する性能を発揮することだと言えますが、完全な教師あり学習(黒い曲線の右端)の性能とラベル付き画像が少ない場合の性能差は非常に大きいままとなっています。
- iNat21はSSLベンチマークとして貴重です:iNat21ベンチマークでは、自己教師あり学習と教師あり学習とで非常に大きな性能差が存在しており、今後の研究にとって重要なベンチマークであると考えられます。
データドメイン
次に、どのようなドメインに属する画像を事前学習に用いるべきかについて調査します。
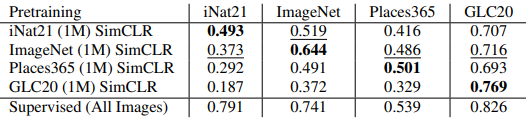
ここで、iNat21(1M)、ImageNet(1M)、Places365(1M)、GLC20(1M)でSimCLRを学習させた場合の線形分類器fine-tuning評価は以下の通りです。
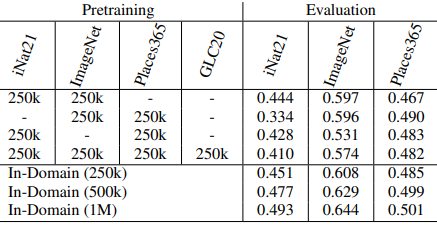
また、これらのデータセットを組み合わせた場合の結果は以下の通りです。
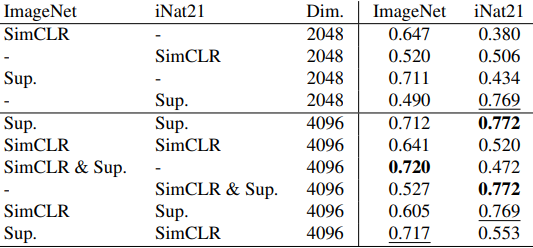
さらに、それぞれの表現出力を連結することで得られた融合表現を利用した場合の結果は以下の通りです。
これらの結果から、データドメインに関して以下の知見が得られました。
- 事前学習データドメインは重要です:事前学習時とドメインが同一な場合(1つ目の表の対角線上)は、クロスドメインの場合より一貫して優れた結果が得られます。また、ImageNet上で学習させたSimCLRはクロスドメイン性能が最も高くなっており、事前学習時・下流タスクのデータドメインが類似している場合に優れた結果が得られることが示唆されます。
- クロスドメインな事前学習データを追加することは、必ずしも一般的な表現には繋がりません:2つ目の表では、異なるデータセットを融合した場合の結果が示されています。しかし、単一の事前学習データセットを使用した場合(In-Domain)と比べ、異なるデータセットを融合した場合の結果は一貫して悪化しています。この結果は、異なるドメインがデータセットに含まれる場合、事前学習時の対照学習タスクが容易になることによると考えることができます。
- 自己教師あり表現は大部分が冗長な可能性があります:3つ目の表では、ImageNetとiNat21で学習したモデルの表現を融合した場合の結果が示されています。その結果、ImageNet SimCLRとiNat21 SimCLRの組み合わせによる性能変化(-0.6%または+1.4%)は、それぞれの表現性能の差(12%以上)と比較すると小さく、これらの表現が冗長であることを示唆しています。また、教師あり表現と自己教師あり表現を組み合わせた場合、より性能変化が大きくなります(+4.7%または-4.2%)。
データの質
次に、事前学習データの品質が性能にもたらす影響について調査します。具体的には、事前学習データのみを人為的に劣化させた場合の結果について実験します。結果は以下の通りです。
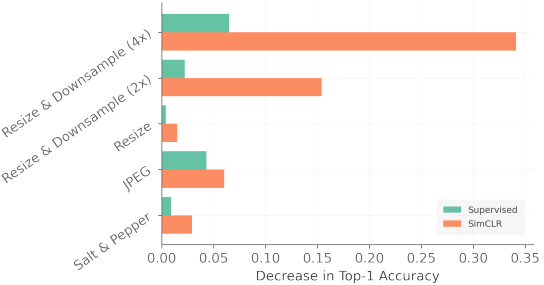
この結果から得られる知見は以下の通りです。
- SSLでは画像の解像度が重要です:ダウンサンプリング(2倍または4倍)により画像を劣化させた場合、SimCLRは最も性能が低下します(それぞれ約15%、34%)。この性能低下は教師あり学習と比べて著しく大きく、SimCLRの特徴表現に欠陥があることを示しています。
- SSLは高周波ノイズに対しては比較的ロバストです:JPEGとSalt&Pepperは画像に高周波ノイズを付与しますが、これらの影響はダウンサンプリングと比べて小さく抑えられています。これは、CNNにとって重要なテクスチャ情報が、ダウンサンプリングにより破損されることによると考えられます。
タスク粒度
最後に、自己教師あり学習表現が特に適している、あるいは適していない下流タスクがあるのかについて調査します。論文ではこの疑問について、分類性能はタスクの粒度(ラベルの細かさ・粗さ)に依存していると結論付けています。
ここで、ImageNet、iNat21、Places365で利用可能なラベルヒエラルキーを利用し、性能がラベルの粒度にどれだけ依存するかについて実験します。このとき、ラベル階層のうち根に近いほどラベルは荒く、根から遠いほどラベルは細かいとみなします。結果は以下の通りです。 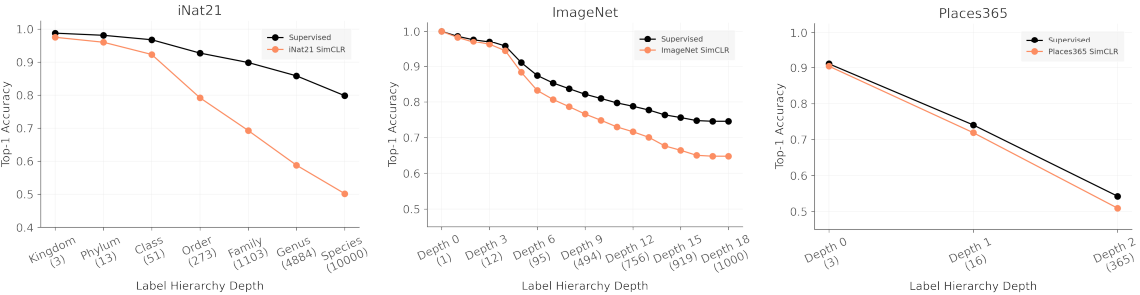
この結果から得られる知見は以下の通りです。
- タスクの粒度が細かくなるにつれて、SSLと教師あり学習の性能差は大きくなります:タスクの粒度が細かくなると、SimCLRと教師あり学習はどちらも性能が低下しますが、SimCLRはより急速に劣化しています。また、SimCLRの劣化が最も激しいのはiNat21であり、SSLにとってiNat21が困難なベンチマークであることをまたもや示唆しています。
- データ増強(Augmentation)は破壊的であるかもしれません:対照学習手法はImageNet用に設計されているため、デフォルトの増強手法は他のデータセットに対して十分に調整されていない可能性があり、これが性能低下をもたらしている可能性があります。例えば、SimCLRにおける「color jitter」は、クラス分類に色が重要となる場合は重要な情報を破壊してしまうかもしれません。(ただし、ImageNetでもSSLの性能は粒度に伴い低下しているため、この仮説は実験結果を完全には説明できていません。)
- 対照学習はcoarse-grainedバイアスを持っているかもしれません:論文では、対照学習損失は全体的な視覚的類似性に基づいて画像をクラスタリングする傾向があると仮定しています。この仮説に基づくなら、対照学習によって区別できるクラスタは粗く、細かいクラス間の違いを区別できないと考えられます。そのため、クラスが粗い場合はこの効果が見落とされる一方、タスクの粒度が細かい場合はクラスタリングの粗さによる影響が明らかになっているのかもしれません。
総じて、SSLにおけるタスク粒度のギャップの理解にはさらなる分析が必要であり、これは今後の課題となります。
まとめ
4つの大規模画像データセットを利用した包括的な実験により、自己教師あり学習(SimCLR)において重要な性質を分析しました。
その結果、事前学習に必要なデータ量、データドメインと性能との関係、画像解像度などの劣化が性能にもたらす影響、タスクのラベルの細かさとモデル性能の関係など、様々な重要な知見が明らかとなりました。
ただし、実験に用いたデータセットサイズはImageNetと同程度のスケールであること、一連の実験はSimCLRに焦点を当てられていることなどの制限事項があるため、今後より詳しい調査が必要であると言えます。





この記事に関するカテゴリー






