
YesBut:VLMに皮肉や風刺画を理解させるデータセットの登場!
3つの要点
✔️ 皮肉理解を評価するためのマルチモーダルデータセット「YesBut」を提案
✔️ 風刺画の検出、理解、完成品の作成の3つのタスクでVision-Languageモデルを評価
✔️ 最先端モデルでも皮肉の理解に限界があり、性能改善の余地を確認
YesBut: A High-Quality Annotated Multimodal Dataset for evaluating Satire Comprehension capability of Vision-Language Models
written by Abhilash Nandy, Yash Agarwal, Ashish Patwa, Millon Madhur Das, Aman Bansal, Ankit Raj, Pawan Goyal, Niloy Ganguly
(Submitted on 20 Sep 2024)
Comments: EMNLP 2024 Main (Long), 18 pages, 14 figures, 12 tables
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
概要
サタイアは皮肉や誇張を通じて人や社会、政治を批判する一種のユーモアであり、問題提起や批判的な視点を促す強力なツールです。特にソーシャルメディアでは、対照的なシナリオを提示して皮肉やユーモアを表現する風刺画像が頻繁に投稿されます。しかし、これらの矛盾したシナリオを理解するためには、画像内のオブジェクトの相互作用や、場合によってはテキスト、さらに一般常識や推論能力が必要です。
従来の研究では、テキストや画像、あるいはその組み合わせでユーモアや皮肉を検出する手法が提案されてきましたが、皮肉を「検出」「理解」「完成品の作成」といった複数のタスクにまたがる包括的な評価は行われていませんでした。
この論文では、風刺の理解力を評価するために、次の3つのタスクを設定しています:
1. 風刺画検出:与えられた画像が風刺であるかを判定するタスクです。このタスクはバイナリ分類問題として扱われます。
2. 風刺画像の理解:風刺画像の内容や皮肉のポイントを自然言語で説明するタスクです。モデルは、サブ画像ごとの描写と、なぜそれが面白い・皮肉的であるかを説明する必要があります。
3.風刺画の完成品の作成:画像の一部が与えられたときに、風刺画として完結するもう一方の画像を2つの選択肢から選ぶ。
研究では、1,084枚の風刺画像と1,463枚の非風刺画像を含む「YesBut」データセットを作成し、各画像には異なる芸術スタイルの2つのサブ画像が含まれています。風刺画像は、左側のサブ画像が通常のシナリオを示し、右側のサブ画像がそれに反する皮肉な状況を描写することで、ユーモアや皮肉を生み出します。
結果として、最先端のVision-Languageモデルは、これらの風刺タスクで期待したほどのパフォーマンスを発揮できていません。特に「風刺画像検出」では、最良のモデルでも精度が60%未満であり、風刺やユーモアの理解にはまだ大きな改善の余地があることが示されています。
この研究は、風刺理解力を評価するための新たなデータセットとタスクを提供するだけでなく、今後のVision-Languageモデルのさらなる改善が必要であることを強調しています。
図表の解説
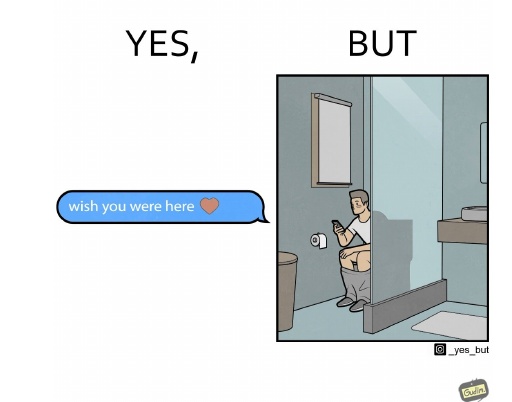
この図は「YES, BUT」という形式でユーモアや皮肉を表現しています。左側には、メッセージアプリの吹き出しがあり、「wish you were here」(あなたがここにいてくれたらいいのに)というメッセージが書かれています。これは一般的に感動的で温かい感情を伝えるフレーズです。
しかし、右側の画像を見てみると、そのメッセージを送っている人物がトイレに座っていることがわかります。この対比が皮肉を生み、面白さを引き立たせています。トイレという個人的かつ少しおかしな状況での行動と、感動的なメッセージのギャップがユーモアの源となっています。
このような形式は、現代のコミュニケーション手段や個人のプライバシーに関する文化的なテーマを風刺的に見せています。
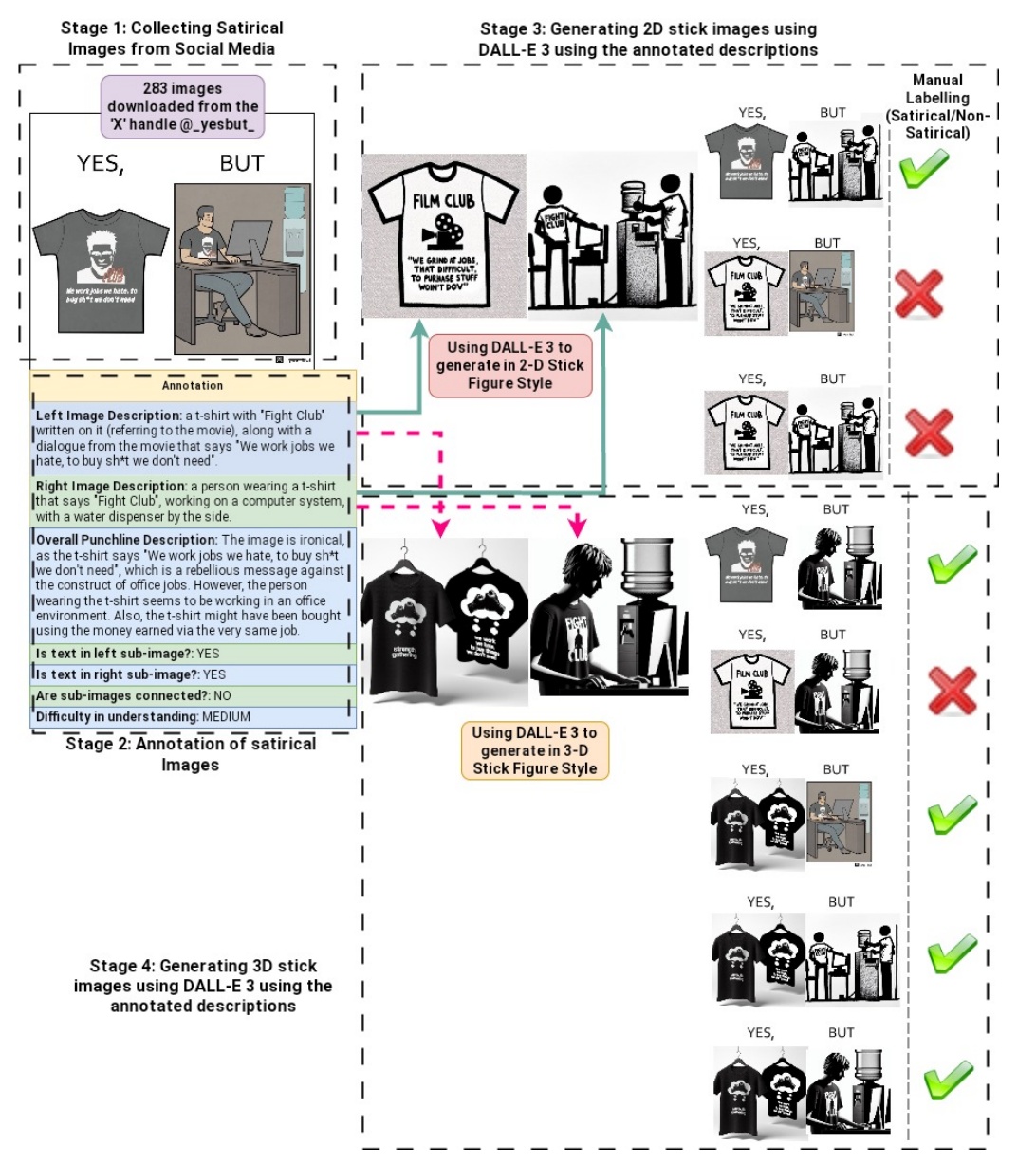
この図は、風刺画像の収集と生成プロセスを4つのステージで説明しています。
ステージ1: ソーシャルメディアからの収集
- ソーシャルメディアから283枚の画像が収集されます。この段階では、「YES, BUT」というテーマの画像が取り上げられています。
ステージ2: 風刺画像の注釈
- 収集された画像に詳細な注釈が付けられます。
- 左の画像説明では、「Fight Club」と記載されたTシャツと、その映画の台詞が含まれています。
- 右の画像説明では、「Fight Club」と記載のTシャツを着た人が水のディスペンサーのそばでコンピュータを操作している様子が示されています。
- 全体の風刺的表現の説明は、この図の皮肉さを強調します。画像は、「私たちは嫌いな仕事をして、必要のないものを買う」というメッセージを伝えています。
ステージ3: 描写を利用した2Dスティック画像の生成
- DALL-E 3を使って、注釈をもとに2Dスティック図のスタイルでイメージが生成されます。
- 生成された画像は手動で分類され、風刺的か否かがラベル付けされます。正しいラベルの画像には緑色のチェックが付けられます。
ステージ4: 3Dスティック画像の生成
- 同様にDALL-E 3を用いて、3Dスティック図スタイルでイメージが生成されます。
- 成果物は、2Dと同様に手動で分類され、適切にラベル付けされます。
この過程において、多様なスタイルとアプローチで画像が生成され、風刺の要素がどのように表現されるかが示されています。
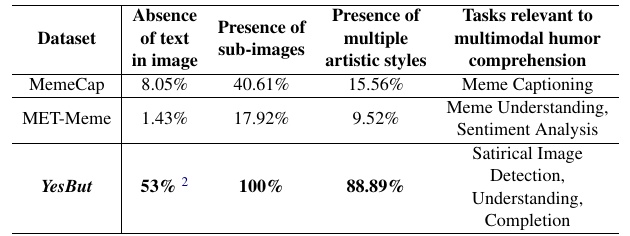
この図表は、異なるデータセットの特徴とその用途を比較しています。「MemeCap」、「MET-Meme」、そして「YesBut」という三つのデータセットについて、次の四つの観点で解説しています。
1. 画像内のテキストの有無:
- 「MemeCap」では8.05%、「MET-Meme」では1.43%の画像にテキストがありません。
- 「YesBut」は53%の画像にテキストがないことを示しています。
- テキストがない画像は、画像だけで意味やユーモアを伝える必要があります。
2. サブイメージの有無:
- 「MemeCap」では40.61%、「MET-Meme」では17.92%の画像がサブイメージを持っています。
- 「YesBut」ではすべての画像がサブイメージを含んでいます。
3. 様々なアーティスティックスタイルの存在:
- 「MemeCap」では15.56%、「MET-Meme」では9.52%の画像が複数のアーティスティックスタイルを持っています。
- 「YesBut」では、88.89%の画像がこの特徴を持っています。この特徴はユーモアや風刺の表現を豊かにする要素として注目されます。
4. マルチモーダルなユーモア理解に関連するタスク:
- 「MemeCap」は主に「Memeのキャプション生成」に使われます。
- 「MET-Meme」は「Memeの理解」や「感情分析」に焦点を当てています。
- 「YesBut」は「風刺的な画像の検出」、「理解」、「補完」といったタスクに使用されます。
この表から、「YesBut」データセットはユーモアや風刺を多角的に評価するために設計されていることが分かります。
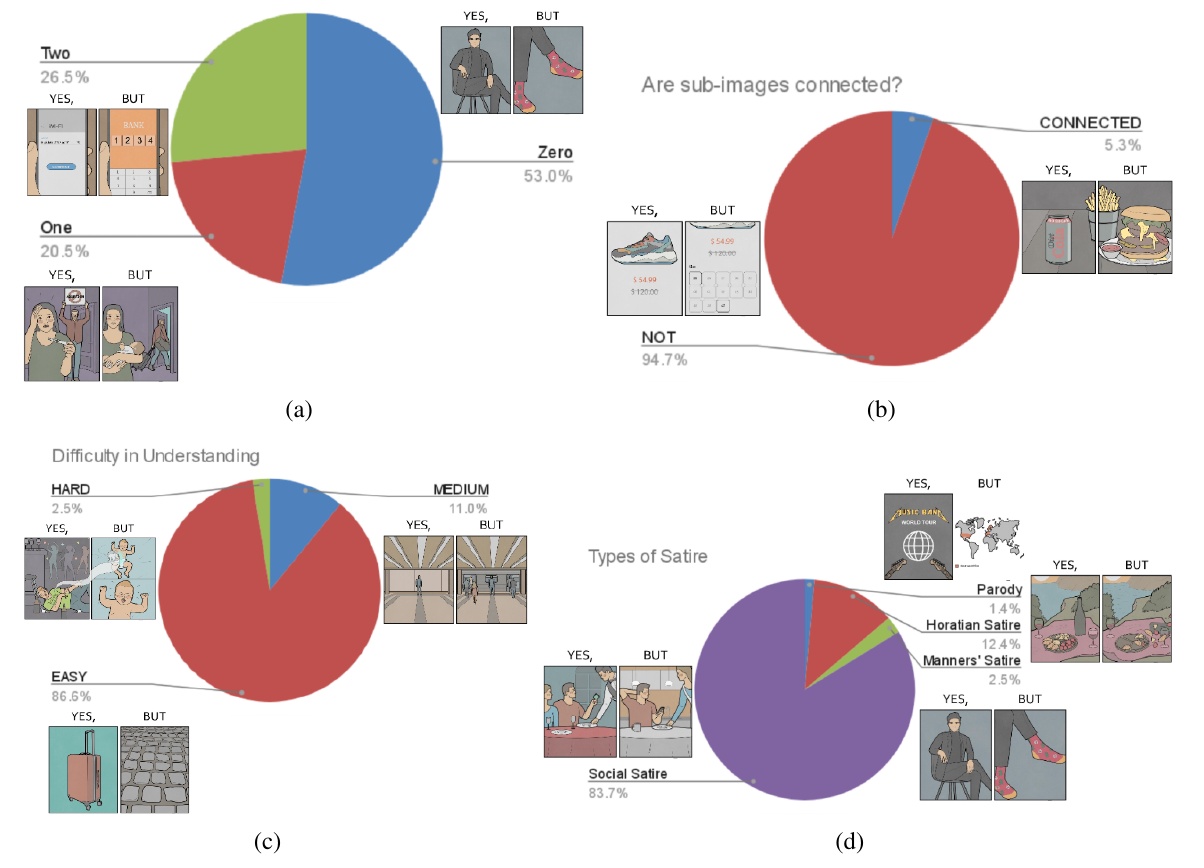
この図表は、4つの異なる側面から風刺画像の特性を分析しています。
(a) 一つ目の円グラフは、サブ画像の数を示しています。「Zero」が53.0%で、これは風刺に使われている典型的なパターンで、二つのサブ画像が描かれていますが、それには関連がないように見えます。他に「One」と「Two」といったカテゴリーもありますが、数が少ないことがわかります。
(b) 次に、サブ画像の接続性についての円グラフです。「NOT」が94.7%を占めており、大部分の画像はサブ画像同士が直接的には接続されていないことを示しています。それに対して、「CONNECTED」はわずかな割合です。
(c) サブ画像の理解の難易度を示すグラフです。「EASY」が86.5%で、多くの画像が比較的理解しやすいことがわかります。「MEDIUM」や「HARD」といった難易度が高い画像は少数です。
(d) 最後に、風刺の種類を示すグラフです。「Social Satire」が83.7%で、社会的な風刺が主流であることを示しています。「Parody」と「Horatian Satire」はそれぞれ14%と12.4%で、「Manners' Satire」は非常に少数です。
これらの統計は、異なる風刺のスタイルとそれに含まれる要素の多様性を視覚的に表現しています。
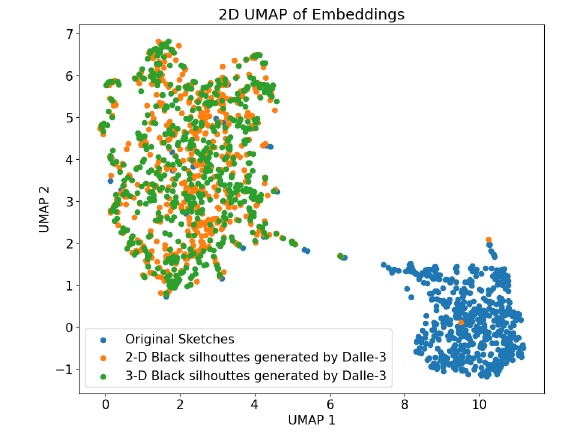
この図はUMAPという手法を使ってデータの分布を2次元で視覚化したものです。UMAP(Uniform Manifold Approximation and Projection)は、高次元のデータを低次元に圧縮する手法の一つです。
図中の異なる色の点は、異なる種類の画像を示しています。
- 青の点は「Original Sketches(元のスケッチ)」を表しています。これらは元の画像で、学習に使用されるベースとなるものです。
- オレンジの点は「2-D Black silhouettes generated by Dalle-3(Dalle-3によって生成された2Dの黒いシルエット)」を示しています。これは人工知能モデルDalle-3が生成した2Dシルエットです。
- 緑の点は「3-D Black silhouettes generated by Dalle-3(Dalle-3によって生成された3Dの黒いシルエット)」を示しています。こちらも同じくDalle-3が生成した3Dシルエットです。
この図からは、元のスケッチとAIで生成された画像がどのように異なり、どれだけの多様性を持っているかがわかります。特に、元のスケッチは他のデータ群とは異なるクラスターを形成しており、違った特徴を持っていることが示唆されています。これはモデルが異なるスタイルの画像をどれだけ区別することができるかを評価するための基礎となっています。
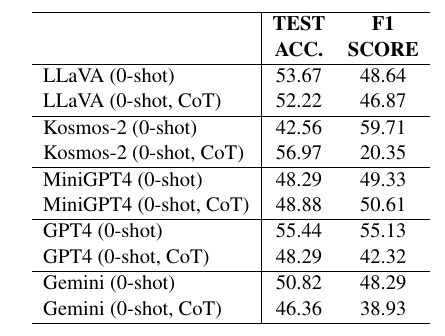
この図は、複数のビジョン・ラングエージモデル(VLモデル)が「風刺画像の検出」タスクにおける性能を示した表です。このタスクは、与えられた画像が風刺的かそうでないかを識別するものです。
- LLaVA: これは「ゼロショット」と「ゼロショットChain-of-Thought(CoT)」の両方の設定で実行されました。ゼロショットは、モデルが追加の学習やコンテキストを得ることなく即座にタスクを処理する設定のことです。「テスト精度(TEST ACC.)」が53.67%、F1スコアが48.64という値で、CoTの設定では若干の低下が見られます。
- Kosmos-2: ゼロショットCoT設定でのテスト精度が56.97%であり、最も良い結果を示しています。これは、連携された推論が効果を発揮していることを示唆しています。
- MiniGPT-4: このモデルは両方の設定で48%台の精度を持っており、F1スコアは少し変動していますが、劇的な改善は見られません。
- GPT-4: 精度とF1スコアが約55%で、他のモデルと比較して中庸なパフォーマンスを示しています。CoTの設定では精度が低下しています。
- Gemini: このモデルは、他のモデルよりも若干低めの性能を示しています。CoTの設定でさらに精度が低下しています。
全体として、絵の風刺性を理解するというタスクへの対応が各モデルで異なり、特にCoTの推論が必ずしもすべてのケースでパフォーマンスを向上させるわけではないことがわかります。モデルによってパフォーマンスに違いが見られますが、全体的にまだまだ改善の余地があることが示唆されています。
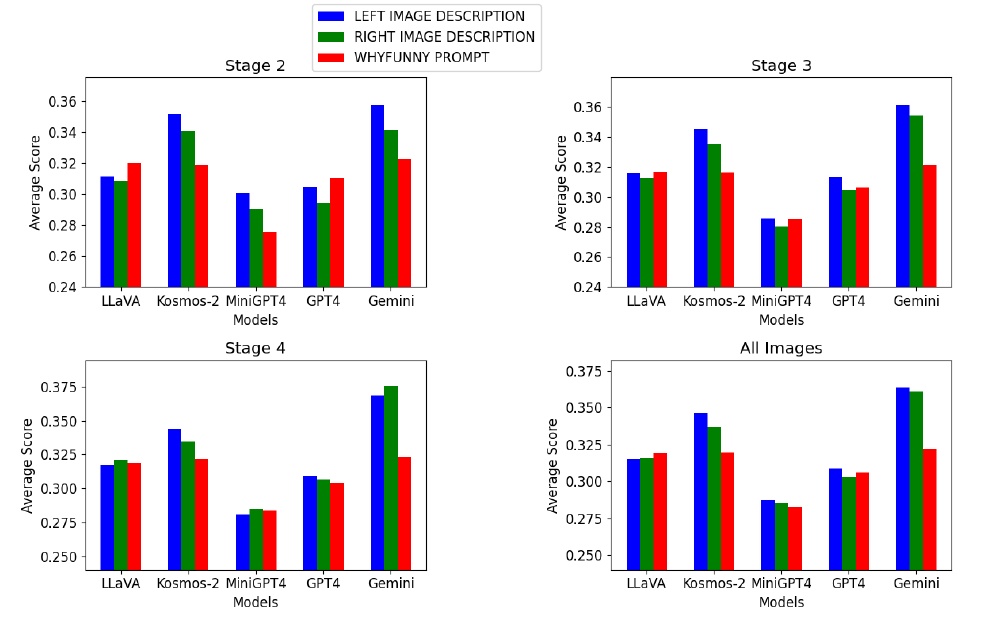
この図は、さまざまなモデルが「YesBut」データセット内の異なるステージでどの程度効果的に風刺的な画像を理解できるかを示しています。評価は、左側の画像説明、右側の画像説明、そして「WHYFUNNY」プロンプトでの評価を通じて行われています。
- 上部の2つのグラフは、Stage 2とStage 3での評価結果です。ここでは、LLaVA、Kosmos-2、MiniGPT4、GPT4、Geminiの5つのモデルを比較しています。各モデルごとに、3つの評価基準の平均スコアが示されています。
- 下部の2つのグラフは、Stage 4と全ての画像を用いた場合の結果を示しています。これにより、各モデルが様々なステージでどのように性能が変化するかを視覚的に比較できます。
一目でわかることとして、Geminiモデルは全てのステージにおいて他のモデルよりも高い評価を受けていることがわかります。特に、Stage 3とStage 4でのスコアが高く、画像の風刺を理解する能力が優れていることを示しています。
逆に、MiniGPT4は相対的に他のモデルよりも低いスコアを示しており、特定のステージでの風刺理解に課題があると考えられます。
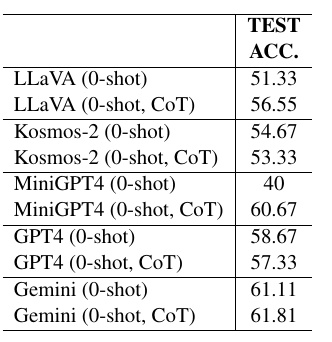
この図表は、さまざまなビジョン・ランゲージ(VL)モデルの「Satirical Image Completion」というタスクにおける性能を示しています。具体的には、各モデルの「ゼロショット」および「ゼロショットCoT(Chain-of-Thought)」設定でのテスト精度(精度)を比較しています。
1. モデルの概要:
- LLaVA: このモデルは、ゼロショットでの精度が51.33%、ゼロショットCoTでは56.55%です。
- Kosmos-2: ゼロショットでは54.67%、ゼロショットCoTでは53.33%の精度を示しています。
- MiniGPT4: このモデルは、ゼロショットでの精度が40%ですが、ゼロショットCoTでは60.67%と大幅に向上しています。
- GPT4: こちらは、ゼロショットで58.67%、ゼロショットCoTで57.33%の精度があります。
- Gemini: 最も高い精度を示しており、ゼロショットで61.11%、ゼロショットCoTでは61.81%です。
2. 結果の傾向:
- 多くのモデルでゼロショットCoTによる精度の向上が見られます。ただし、Kosmos-2では例外的にゼロショットCoTで若干の精度低下があります。
- 全体として、Geminiが最も高い精度を示しています。このことは、複雑なタスクにおけるGeminiの優れたパフォーマンスを示唆しています。
3. 応用性:高い精度を持つモデルは、特定の文脈での画像理解や共通のパターンを見つける能力があることを示しており、視覚と言語の統合された処理が可能です。

この画像は、ユーモアや皮肉を表現している一例です。「YES」と「BUT」の2つの部分に分かれています。
左の「YES」部分では、消火器が表示されています。この消火器には「FOAM」と書かれたラベルが貼ってあり、油火災や可燃性液体の火災用で、電気火災には使用できないことが示されています。背景には水辺の風景が見え、状況は平和そのものです。
右の「BUT」部分になると、引き戸のような格子が消火器の前に置かれ、実際に使おうとしたときにはアクセスが制限されていることを示唆しています。この格子によって、消火器が素早く取り出せない状況が皮肉的に表現されています。
この2つの画像のコントラストによって、消火器が視覚的には利用しやすい場所に置かれているが、実際には使いにくい状況がユーモラスに描かれています。社会的なシステムや、表面的にはうまく機能しているように見えても、実際にはそうではない状況を風刺しているとも解釈できます。
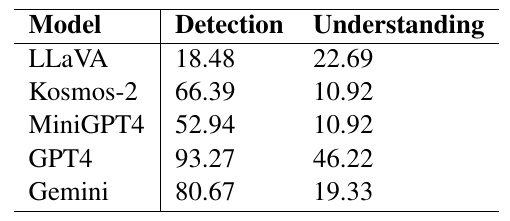
この図は、複数のモデルのパフォーマンスを示した表です。各モデルが、特定の二つのタスクにどの程度の精度(パーセンテージ)で取り組めたかが示されています。
- 「Detection(検出)」は、おそらく画像やデータの中から特定の要素を見つけ出すタスクを指しており、モデルがどれくらいそれをうまく実行できたかの評価です。
- 「Understanding(理解)」は、与えられた情報をどれだけ深く理解し、意味をつかめるかを表しています。
各モデルの結果を見ますと、GPT4は検出で93.27%、理解で46.22%と非常に高いスコアを示しています。次に優れているのがGeminiで、検出で80.67%、理解で19.33%です。
他のモデルは、特に理解において10%台と低いスコアを示しており、データの深層的な理解にはまだ改善の余地がありそうです。Kosmos-2とMiniGPT4は、検出において中程度のパフォーマンスを示していますが、理解では同様に10%ほどのスコアにとどまっています。
この表から分かることは、各モデルが異なるタスクに対して得意な領域と改善が必要な領域を持っているということです。特に、GPT4は両方のタスクで優れていますが、他のモデルは検出と理解でばらつきが見られます。

この画像は、左側に「YES」と右側に「BUT」と書かれている2つのパネルで構成されています。
- 左のパネルには、手がティッシュペーパーを1枚引っ張り出している様子が描かれています。これは、通常の動作を示しています。
- 右のパネルには、多くのティッシュペーパーが一度に引き出されてしまっている様子が描かれています。こちらは、予期しない結果を表しています。
これにより皮肉やユーモアを生み出しているのです。この画像は、単純な行動がしばしば期待外れの結果をもたらす状況を象徴的に表現しています。
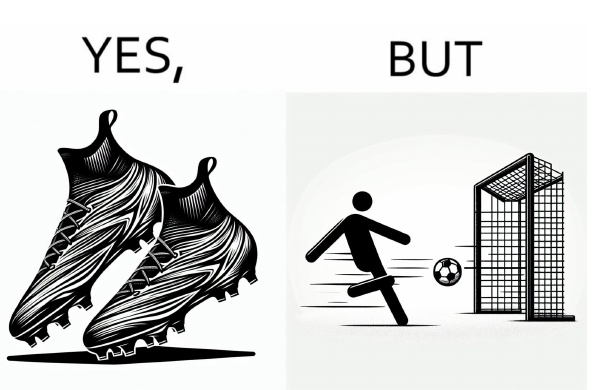
この画像は、サッカーに関する冗談を視覚的に表現しています。左側にはサッカーシューズが描かれ、「YES」と書かれています。これは、サッカーをする準備が整っていることを示しています。一方、右側にはゴールを蹴るスティックフィギュアが描かれ、「BUT」と書かれています。これは、プレーが意図した通りにならなかった、または期待された結果に反する出来事を示唆しています。
このように、期待と現実のギャップをユーモラスに表現することで、見る人に笑いや軽い驚きを提供しています。このような図表は識字に役立つだけでなく、社会的な状況を風刺的に捉える際にも用いられます。

この図では、2つの異なるシナリオが描かれています。それぞれのセットに対して「YES, BUT」という形式が使われており、その間に対立するアイデアが示されています。
左側の図では、(A)と(B)が提示されています。(A)には大きな疑問符が描かれており、(B)には壁に取り付けられたテレビの画面に暖炉の炎が映し出されています。この組み合わせは、実際の暖炉とは異なり、テレビ画面を通しての疑似暖炉を面白く見せています。
右側の図でも、(A)と(B)が示されています。(A)は信号機のライトが赤の状態で、周囲にたくさんの人々が立っている状況です。(B)には疑問符が置かれています。これらの対比は、信号が変わらない矛盾を示している可能性があります。
このように「YES, BUT」の形式を用いて、視覚的に対立や皮肉を引き立たせるような工夫がされています。

この図は、ユーモアや風刺を表現するための画像です。左上に「YES,」と書かれており、右上に「BUT」という言葉が見えます。
左下の画像(A)は、火を囲む暖炉のシンプルな図案化されたイラストです。人々が暖を取る典型的な暖炉のシーンを表現しています。
右下の画像(B)は、豪華な暖炉の写真で、薪が美しく積まれた状態です。しかし、この暖炉は現実の炎ではなく、テレビ画面に映し出された映像です。
この図全体が示す風刺的な要素は、現実の暖かさと見かけだけの暖かさに対する皮肉です。本物の暖炉が持つ暖かさと、単なる装飾としての電子的暖炉の対比が、ユーモラスに強調されています。
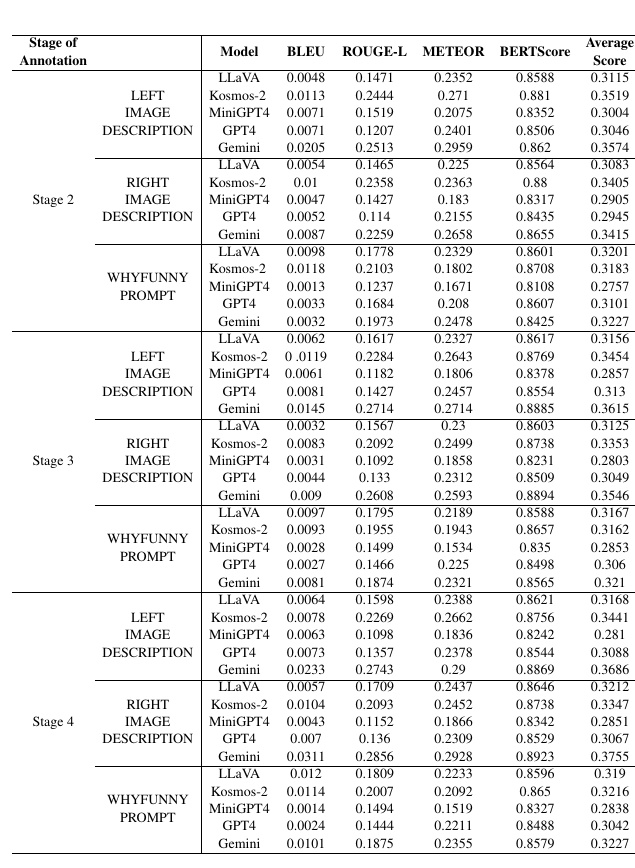
この図は、異なるモデルがYesButデータセットにおいて、風刺的な画像の理解力を評価するために使用されたメトリクスの結果を示しています。以下の内容について解説します。
1. 評価ステージ:データセットは3つの異なるステージに分かれています。それぞれのステージで、モデルが提供された画像のサブ画像の説明や風刺の理解を試みます。
2. モデル:図には複数のモデルが含まれています。LLaVA、Kosmos-2、MiniGPT4、GPT4、Geminiが挙げられます。
3. 評価メトリクス:
- BLEU、ROUGE-L、METEOR、BERTScoreといった自動評価メトリクスを用いて、モデルが生成した文章の質を評価しています。
- それぞれのメトリクスは、モデルが生成したテキストと参考となるテキストとの類似度を測るものです。
4. 結果の概要:
- 各ステージでの「LEFT IMAGE DESCRIPTION」、「RIGHT IMAGE DESCRIPTION」、「WHYFUNNY PROMPT」といったタスクがあります。
- 各メトリクスのスコアが示されており、これらのスコアはモデルの性能を数値化しています。
5. 平均スコア:最後に、「Average Score」として各タスク全体の平均スコアが示されています。これは、モデルの総合的なパフォーマンスを評価する指標です。
この図表を通じて、異なるモデルがどの程度風刺を理解し説明できるかを比較し、評価しています。モデルによって結果が異なり、どのモデルがより効果的に風刺を理解できるかがわかります。
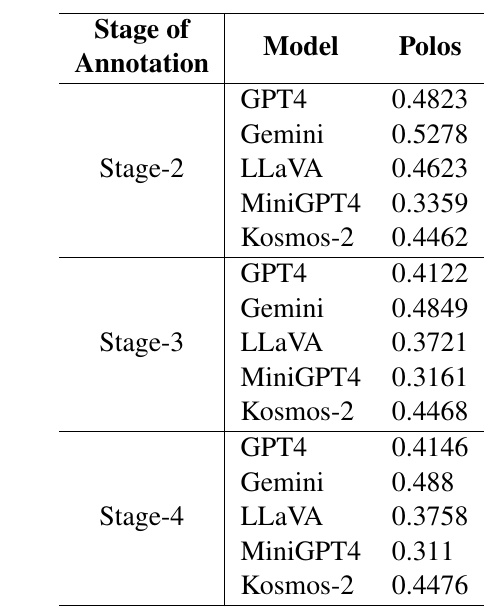
この表では、異なるフェーズでのさまざまなモデルの性能を評価しています。評価指標「Polos」は、モデルの特定のタスクにおけるパフォーマンスを数値で表しています。
Stage-2:
- GPT4のスコアは0.4823で、性能は他のモデルと比較して平均的です。
- Geminiは0.5278で最も高いスコアを示しています。
- LLaVAは0.4623で、他のモデルと比べるとやや低めです。
- MiniGPT4は0.3359で最も低いスコアです。
- Kosmos-2は0.4462で、中位のスコアを獲得しています。
Stage-3:
- GPT4のスコアは0.4122に下がっています。
- Geminiは0.4849と依然として高いスコアを保っています。
- LLaVAは0.3721と低めの性能です。
- MiniGPT4は引き続き低く、0.3161です。
- Kosmos-2は0.4468で、Stage-2のスコアとほぼ変わりません。
Stage-4:
- GPT4のスコアは0.4146とわずかに上がっています。
- Geminiは再び0.488と高い性能を示しています。
- LLaVAは0.3758で、安定した結果を出しています。
- MiniGPT4は0.311と、依然として低いスコアです。
- Kosmos-2はコンサistentして0.4476を記録しています。
全体として、Geminiがどのステージでも一貫して高い性能を示しています。MiniGPT4はすべてのステージで最も低いスコアを示しており、他のモデルとの差が見られます。これらの数値は、特定のタスクの進行ステージにおけるモデルの理解力やパフォーマンスの違いを示しています。
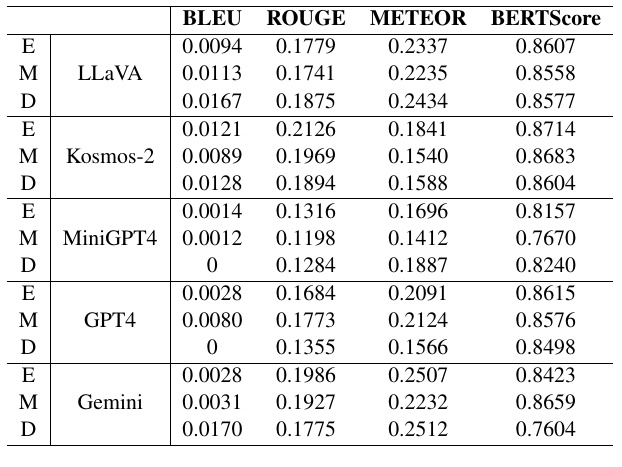
この表は、複数のモデルがテキスト生成タスクにおいてどの程度の性能を発揮するかを示しています。各モデルの性能は、異なる難易度のデータセット(EASY、MEDIUM、DIFFICULT)に対して評価されています。指標に使用されているのは、BLEU、ROUGE、METEOR、BERTScoreの4つです。これらはそれぞれ、生成されたテキストがどれだけ元のテキストに近いか、または意味的に類似しているかを評価するための指標です。
- BLEUは、生成されたテキストと参照テキストのn-gramの一致度を計測します。この値が高いほど、元のテキストと一致していることが示されます。
- ROUGEは、特に要約タスクでよく使われる指標で、生成されたテキストと参照テキストの一致度を評価する際に用いられます。
- METEORは、語形変化や同義語の考慮を含む、一致度の指標です。
- BERTScoreは、BERTという事前学習モデルを用いて、意味的な類似度を確認するためのスコアです。
表の中で、各モデルがそれぞれの難易度(E/M/D)でどのようなスコアを出しているかが示されています。たとえば、LLaVAモデルは、EASYデータセットに対してBLEUスコアが0.0094であり、DIFFICULTデータセットでは0.0167となっています。これは、難易度が上がるにつれて、このモデルの生成精度に変化が生じていることを示しています。
他のモデル、Kosmos-2やMiniGPT4、GPT4、Geminiも同様に評価され、それぞれの指標に基づいた性能が示されています。このような評価を通じて、どのモデルが選択したタスクやデータセット条件において最も優れた性能を示すかを比較することができます。

この画像は、二つの場面を比較することで風刺を表現しています。左の画像には、通常の椅子が描かれています。一見して普通の場面を示しています。右の画像では、人物がトイレに座りながら鏡で自撮りをしている様子が描かれています。この二つの瞬間を並置することで、普通の椅子に座らずに面白い状況にいることを強調し、皮肉やユーモアを生み出しています。このように、二つのシーンの対比により、現代社会の自己表現や生活様式の風刺を巧みに描写しています。
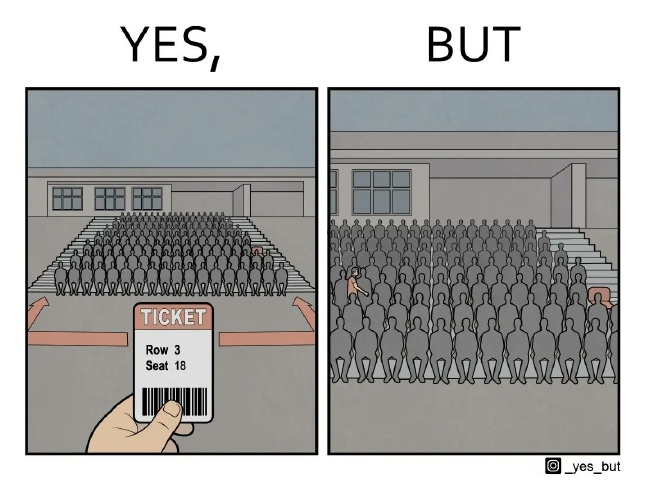
この図は、チケットを持っている人と、その結果起こる状況を示しています。左側の画像では、手に持ったチケットが示されています。そこには「Row 3, Seat 18」と書かれており、観客席の中で指定された席が描かれています。観客席はほぼ満席で、座る場所への行き方を示す矢印も見えます。
一方、右側の画像では、同じ観客席の風景が描かれています。列の途中まで進もうとしている人物が見え、席が埋まっているために皆の前を通り過ぎなければならない様子が伺えます。この配置は、人が満席の中を通らなければならない面倒さを皮肉的に示しているのです。
このように、チケットの提示により問題なく席にたどり着けるはずの状況が、実際には多くの人をかき分けながら進む必要があるという矛盾を、ユーモラスに描写しています。

この画像は、「YES」と「BUT」の対比を用いた風刺です。左側の人物は多くの科学的分野(天文学、数学、物理学)の専門知識を持っています。しかし、TikTokに関する知識はありません。一方、右側の人物はTikTokの専門知識が非常に高いですが、他の科学分野の専門知識は無いようです。
この比較は、現代社会における専門知識の評価の仕方を風刺的に表現しています。特にソーシャルメディアの影響力が専門家として評価される場合があることを暗示しています。このように異なる基準で評価される状況が、画像のユーモアと風刺の要素を生み出しています。
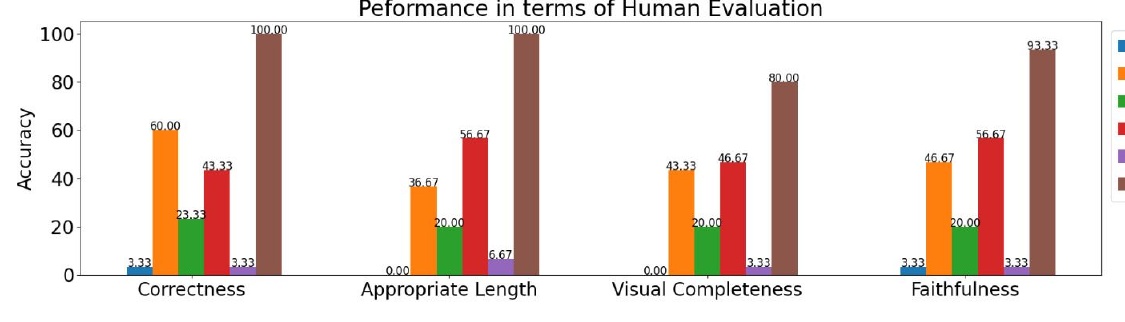
この図は、人間による評価を基にしたパフォーマンスの比較を示しています。評価基準としては、「正確さ」「適切な長さ」「視覚的な完全性」「忠実さ」の4つが挙げられています。
1. 正確さについては、図の上で示されたバーを見ると、あるモデルまたは手法が60%の正確さを達成しています。その一方で、他の方法はそれに比べてかなり低い正確さを示しています。
2. 適切な長さに関しては、最高の手法が100%に達していますが、一定の長さを欠いている手法もあり、それが一部の評価に影響しています。
3. 視覚的な完全性の項目では、最も優れた手法が80%に達しており、他の手法はそれよりも低く、一部では極端に低い数値が観察されます。
4. 忠実さについては、最高の手法が93.33%を示していますが、他の手法はこの数字に届いていません。しかし、中には50%以上の数値を示すものもあり、ある程度の信頼性が確保されています。
図全体として、評価基準ごとに明確な差異があることがわかります。この結果は、ある特定のモデルまたは手法が様々な基準でどの程度の性能を発揮しているのかを直感的に理解するためのものです。

この表は、ある画像に対する人間と異なるモデルの解釈を比較しています。
1. 人間の記述:TikTokの専門性が高い人が、他の分野での専門性が高い人よりも重要視されていることを示しています。ここで、マイクの数がその人物の重要性を示しています。
2. LLaVA:紫色のモヒカンと眼鏡をかけた男がマイクに囲まれており、「専門家、天文学」というフレーズが上に表示されています。この配置が滑稽で皮肉な状況を作り出しており、人々の外見やステレオタイプに基づくラベルや仮定の不条理さを表していると述べています。
3. Kosmos-2:年配の男性がマイクの前で若いマスクを着けた男に質問している描写をしています。年配の男性の知識が皮肉的な方法で扱われていると述べています。
4. GPT4:異なる分野における二人の専門性の差を大げさに示しており、それによっておかしな状況を引き起こしていると述べています。
5. MiniGPT4:記述が不完全で詳細が記されていません。
6. Gemini:専門知識のある人が難解な専門用語を使って話し、あまり知識のない人が一般的で親しみやすい方法で話すことの対比を示していると述べています。
この比較は、モデル間で画像の解釈に大きな違いがあることを示唆しています。



この記事に関するカテゴリー





