
大規模データ生成ライブラリKubricの紹介
3つの要点
✔️ 機械学習モデルの質は、データの質である。
✔️ データ合成は、詳細なアノテーション付与、サンプリングバイアスの除去、法的に安全なデータ収集等の問題を回避できる。
✔️ Kubricは、多くのタスクに有用なデータ生成を行うことができるPythonライブラリである。
Kubric: A scalable dataset generator
written by Klaus Greff,Francois Belletti,Lucas Beyer,Carl Doersch,Yilun Du,Daniel Duckworth,David J. Fleet,Dan Gnanapragasam,Florian Golemo,Charles Herrmann,Thomas Kipf,Abhijit Kundu,Dmitry Lagun,Issam Laradji,Hsueh-Ti(Derek)Liu,Henning Meyer,Yishu Miao,Derek Nowrouzezahrai,Cengiz Oztireli,Etienne Pot,Noha Radwan,Daniel Rebain,Sara Sabour,Mehdi S. M. Sajjadi,Matan Sela,Vincent Sitzmann,Austin Stone,Deqing Sun,Suhani Vora,Ziyu Wang,Tianhao Wu,Kwang Moo Yi,Fangcheng Zhong,Andrea Tagliasacchi
(Submitted on 7 Mar 2022)
Comments: 21 pages, CVPR2022
Subjects: Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR); Machine Learning (cs.LG)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
概要
近年「データ・ドリブン」という言葉を耳にしませんか?これは「データ駆動型の」「データ主導・牽引型の」という意味で「機械学習手法よりもデータの質が結果を左右する」ことを示しています。機械学習が爆発的な流行を見せ、大学や企業で様々な研究・開発が行われた結果、データの質がモデル精度に重要であることが分かってきました。
しかし質の高いデータ、つまりアノテーションが詳細・正確で、バイアスがなく、よく整理され、法的にも安全なデータを収集・保管することは困難です。
これに対してデータの合成は、上記の問題点を解消しうる手法です。その一方で、データ合成に関するツールは、機械学習モデルの訓練や設計のツールと比較すると未成熟です。
そこで本論文では、Kubricと呼ばれるPythonフレームワークを提案します。Kubricは、PyBulletやBlenderと連携してフォトリアリスティックな画像を生成し、詳細なアノテーションを付与することが可能です。加えて、数千台のマシンで分散処理することも可能であり、大規模なデータ生成を展開することができます。
本論文では、主要なタスクにあわせて13種類のデータを生成し、Kubricの有効性を検証しています。
はじめに
深層学習には、大規模で高品質なデータが不可欠です。データの量・質は、モデル設計や訓練方法と同等かそれ以上に重要です。しかし単純な画像系タスクでさえ、質の高い十分なデータを収集し、管理することは困難な課題です。
データ合成は、アノテーション(真偽判定)が容易で、画像の複雑さも制御しやすいため、ベンチマーク評価に利用されてきました。またモデル設計上想定していないデータを合成することでも、モデルの仮定にそぐわないデータを系統的に評価することも可能です。同様にモデルの訓練にも使用されており、合成データは驚くほど効果的であることが示されてきました。
しかしデータ生成のためのツールはあまり成熟していません。本稿ではデータ生成のためのワークフレームであるKubricを提案します。Kubricはビジョンタスクのために様々な形式(下図参照)のデータセットを生成でき、詳細なアノテーションを付与することができます。さらにKubricは数千台のマシンで大規模なデータ生成ジョブを実行することも可能です。本論文では、13種類のデータセットを生成し、それらを各種ベンチマークで検証します。
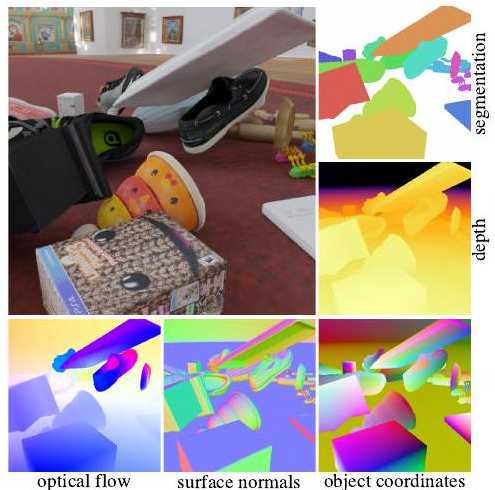
上図は、Kubricで作成されたシーンです(註:論文では当然静止画ですが、GitHub上だと動画で見ることができます)。物体の衝突等のシミュレーションはPyBulletで行われており、レンダリングはBlenderで行われています。エクスポートされた画像(上図)には、セグメンテーション、深度マップ、オプティカルフロー、法線ベクトルなどの豊富なアノテーションが含まれています。
関連研究
合成データは、多くの画像タスクに高品質なラベルを提供します。CLEVR, ScanNet, SceneNet RGB-D, NYUv2, SYNTHIA, virtural KITTI, flying things 3Dなどがデータ合成ツールとして報告されていますが、これらは特定のタスクを想定しています。また多くの場合、カメラの設定、照明条件などのデータは残されていません。
BlenderやUnityを使ったデータ合成パイプラインもありますが、これらも特定タスクを想定していることが多いです。さらに言えば、レンダリングエンジンへの深い知識がなければ、データに新しい属性を付与することは困難です。
Kubricのような汎用データ合成エンジンとしてThreeDWorldが知られています。
ThreeDWorldは、柔軟なPython APIとUnity3Dベースのエンジン、NVIDIA Flex物理シミュレータ、PyImpactによるサウンド生成まで包括的なエクスポートが可能です。また、Kubricに最も近いのはBlenderProcですが、BlenderProcとKubricの違いは、Kubricが数千台のマシンでのジョブを可能とし、TensorFlowとの連携に重きを置いている点です。
データセットと課題
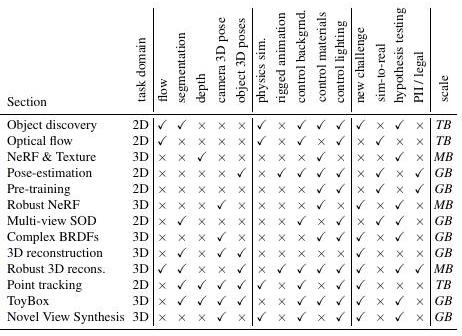
Kubricの性能と汎用性を示すために、Kubricで生成したデータを用いた一連のチャレンジを説明します(一覧は以下のテーブル)。
動画上でのオブジェクト発見(object discovery)
オブジェクト発見とは、動画からオブジェクトのセグメンテーションマスクを発見することを意味します。データセットはMOViと呼ばれる動画で、難易度でAからEに分けられています。比較対象は、現状SOTAであるSAViとSIMONeです。

上図がMOViのデータセットです。DとEでは、抽出できていないオブジェクト(手前側の靴など)があることが分かります。
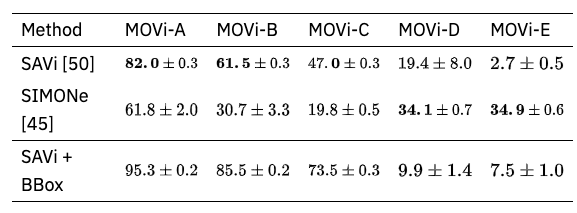
上記の結果から、視覚的・動的複雑さが増すとオブジェクトの発見が難しいことがわかります。この実験からKubricで生成されたデータが既存のアーキテクチャ評価に有用であることがわかります。
オプティカルフロー
オプティカルフローとは、動画上の特定のフレームからその次のフレームへの画素の動きのことです。オプティカルフローは、人間がアノテーションしても質の高いデータにならないことが知られています。

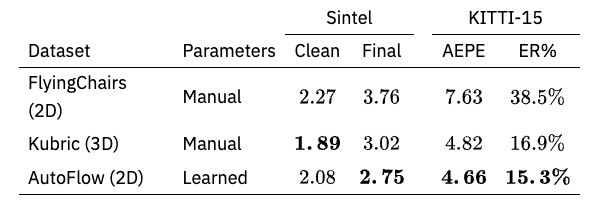
上図のFlyingChairsは、文字通り椅子が浮かんでいるデータセットで、optical flowのデータセットに利用されています。しかし現実的なデータとは言えません。AutoFlowはポリゴンで作成したオブジェクトが移動していますが、ランダム生成なポリゴンであり現実的に意味のあるオブジェクトではありません。Kubricではこれらの問題を解決しています。
オプティカルフローのモデルとして知られているPWC-net, RAFT, VCNのうち、RAFTを使ってKubricでの学習を行いました。その結果、FlyingChairsよりも大幅な性能向上が確認されました。
AutoFlowとの比較はやや複雑で、AutoFlowではモデルSintelに対してハイパーパラメータの最適化が行われており、AutoFlowとKubricを単純に比較することができません。それでも以下の表に示すとおり、同等の性能を発揮しています。このさき、ハイパーパラメータの設定次第ではAutoFlowより高い性能向上が期待されています。
NeRFでのテクスチャ構成
NeRF(neural radiance fields)は本質的には体積表現法ですが、一般的には物体の表面をモデル化するために使用されています。実体の表面とNeRFによって再構成された表面を比較し、NeRFの性能をベンチマークすることはまだ未開拓の分野です。

本論文ではNeRFベンチマークのために、上図のような平面からなる物体を合成しました。物体の表面性状(テクスチャ)は、ブルーノイズ(アジュールノイズ)から手続き的に生成されています。そしてピクセルごとにカットオフ周波数を設定し、これをアノテーションデータとします。その後、周波数と深度分散の相関を解析(これがタスクになります)して、実際に設定した値との誤差を測定します。

結果、周波数が低くなるほど色予測の精度(PSNR)が上がり、表面性状の精度(深度分散)は低下していることがわかりました。
ポーズ推定
ポーズ推定によるインタラクティブな体験(例えばKinect)は人間のポーズを特徴量としますが、写真をデータセットとすると見栄えのするポーズには明らかにサンプリングバイアスが生じています。そのため写真ではなく、画像生成によってあまり見栄えのしないポーズを補完することができます。

ポーズ推定に使用される画像は上図のようなものです。
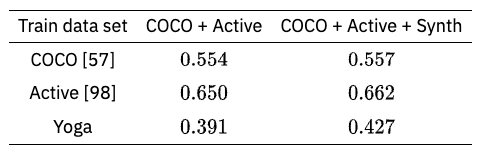
既存のデータセット(COCO)にはない人体モデルの生成画像を追加することで、平均精度(mAP)が改善されました。
その他のタスク
前述してきたタスク以外にも、事前学習用視覚表現(pre-training visual representations)、Robust NeRF、周辺物体検出(Salient Object Detection, SOD)、複合BRDFs(bidirectional reflectance distribution functions; 双方向反射率分布関数)、単視点再構成、動画ベース再構成、点トラッキング、セマンティックセグメンテーション、上限つき新規視点合成のタスクに対してもKubricで生成したデータを利用することができます。
まとめ
Kubricは、豊富なアノテーションに対応可能で、学習パイプラインに直接データを加えるためのエクスポートフォーマットを備えたPythonライブラリです。
本論文では、11個のケーススタディでKubricの有効性を検証しました。その結果、Kubricは必要なデータの生成に対する労力を大幅に削減し、再利用やコラボレーションを促進することができました。
筆者らは、Kubricによってデータ生成の障壁を下げ、データの断片化を防ぐことを希望しています。またKubricには課題があり、BlenderやPyBulletの機能を完全にサポートしているわけではありません。今後は、霧や炎の表現、被写界深度・モーションブラー等のカメラエフェクトにも対応する予定です。






この記事に関するカテゴリー






