Unconditional-GANのモデル圧縮
3つの要点
✔️ Unconditional-GANのモデル圧縮技術
✔️ 画像内の重要なコンテンツの保持を重視したプルーニング・知識蒸留の提案
✔️ 既存の圧縮技術・オリジナルモデルと比べ同等以上の性能を発揮
Content-Aware GAN Compression
written by Yuchen Liu, Zhixin Shu, Yijun Li, Zhe Lin, Federico Perazzi, S.Y. Kung
(Submitted on 6 Apr 2021)
Comments: CVPR2021.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
Generative Adversarial Network(GAN)は、画像生成・画像編集などのタスクで優れた結果を示しています。
しかし、StyleGAN2をはじめとした最先端のGANは、計算量・メモリコスト等の面で課題を抱えており、エッジデバイスへの展開などが困難です。
大きなモデルの容量を削減するための手法として、pruningやknowledge distillationなどがありますが、これらの手法をそのままStyleGANのようなUnconditional-GANに適用することはできません。本記事で紹介する論文ではこの問題に対処するため、Unconditional-GANに特化したモデル圧縮手法を提案しました。以下に見ていきましょう。
提案手法
提案手法の目標は、ランダムなノイズから画像を生成するUnconditional-GANである$G$について、より容量が小さく効率的なモデル$G'$を得ることです。
より具体的には、以下の二つを実現することが目標となります。
- 同一の潜在変数$z \in \mathcal{Z}$について、生成される画像$G(z),G'(z)$の視覚的品質が類似している
- 現実世界の画像$I \in \mathcal{I}$について、対応する潜在変数$Proj(G,I),Proj(G',I)$が類似している
この目標を達成するよう、以下に示すChannel PruningとKnowledge Distillationを行います。
Content-Awareなモデル圧縮
Channel PruningとKnowledge Distillationに関する詳細な解説の前に、例えば、人間の顔画像を生成するGANの圧縮を行いたい場合について考えてみましょう。このとき、生成される画像のうち、最も重要なのは人間の顔にあたる領域となります(その他の背景領域は重視されません)。
そのため元論文では、GANが生成する画像の中でも重要なコンテンツに対応する領域(人間の顔など)を特定するネットワーク(content-parsing neural network)を用います。それにより、Channel Pruningの際には「画像内の重要なコンテンツの生成に各チャンネルがどれだけ貢献しているか」を測定する指標($CA-l1-out$)を利用します。またKnowledge Distillationの際には、「画像内の重要なコンテンツの生成のための知識」を継承するように定義された損失を利用します。
このような"Content-Aware"なモデル圧縮により、オリジナルのGANと同等の質を持つ軽量なモデルの獲得を目指しています。
Content-AwareなChannel Pruningについて
提案手法のプルーニングでは、以下のパイプラインに基づき、チャンネルの重要度を測定します。
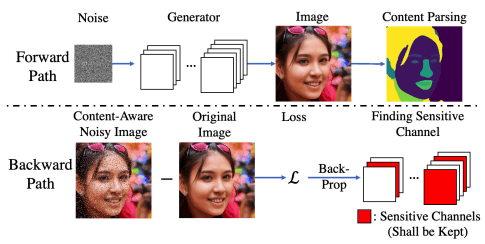
パイプラインはForward path/Backward pathの二つの経路から成り立っています。
まずForward pathでは、潜在変数$z \in \mathcal{Z}$から生成画像$G(z) \in R^{H×W×3}$を求めます。
次に、画像内のコンテンツマスク$m \in R^{H×W}, m_{h,w} \in {0,1}$を予測するネットワーク(content-parsing neural network)である$Net_p$に生成画像を通し、画像内の注目すべきコンテンツマップ$COI={(h,w)|m_{h,w}=1}$を取得します。
人間の顔画像の生成では、人間の顔領域がこれに対応します。
次にBackward pathでは、生成画像$G(z)$の重要な領域であるCOI上にのみランダムなノイズを加えた画像$G_N(z)$を用意します。これは上図のContent-Aware Noisy Imageにあたり、例えば顔画像生成では、生成画像のうち人間の顔領域にのみノイズが付加された画像となります。
そして、元画像との間で求められる微分可能な損失$L_{CA}(G(z),G_N(z))$のback-propagationを行い、勾配$\nabla g \in R^{n_{in}×n_{out}×h×w}$を求めます。
これをランダムな複数のノイズサンプル$z$について行うことで、勾配の期待値$E[\nabla g]$を求めます。このとき、各チャンネル$C_i$の重要度の指標$CA-l1-out$は、各チャンネルの勾配出力のL1ノルムとして定義されます。
$CA-l1-out(C_i)=||E[\nabla g]_i||_1, E[\nabla g]_i \in R^{n_{out}×h×w}$
プルーニング処理の際には、この$CA-l1-out$が大きいチャンネルを保持し、小さいチャンネルは削除します。
Knowledge Distillationについて
提案手法のKnowledge Distillationでは、いくつかの損失を組み合わせた損失を利用します。それぞれ順番に見ていきましょう。
・ピクセルレベルのDistillation
最もシンプルな例として、生成画像$G(z),G'(z)$の出力または中間層間のノルムを小さくするように定義された損失が考えられます。
これは、出力・中間層について、それぞれ以下の式で表されます。
$L^{norm}_{KD}=E_{z \in \mathcal{Z}}[||G(z),G'(z)||1]$(出力のみ)
$L^{norm}_{KD}=\sum^T_{t=1}E_{z \in \mathcal{Z}}[||G_t(z),f_t(G'_t(z))||1]$(中間層)
ここで、$G_t(z),G'_t(z)$は中間層($t$層目)のactivationを、$f_t$は深さ次元を一致させるための線形変換となります。
・画像レベルのDistillation
出力画像間のピクセルレベルのノルムとは別に、人間の類似性の判断により近い評価指標を用いることもできます。
提案手法ではLPIPSにより、出力画像間の知覚的な距離を利用します。
$L^{per}_{KD}=E_{z \in \mathcal{Z}[LPIPS(G(z),G'(z))]}$
・Content-Aware Distillation
提案手法ではプルーニングの場合と同様、画像内の重要なコンテンツを重視した蒸留損失を利用します。これは以下の図の通りです。
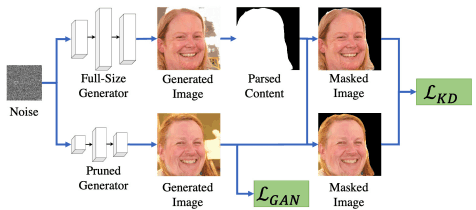
端的に言えば、画像内の重要なコンテンツ以外の領域(顔画像生成における背景領域など)のマスキングを行った後の画像について、先述したピクセルレベル・画像レベルのDistillation損失を求めます。
このようなContent-Awareな(生成画像のうち重要なコンテンツを重視した)蒸留損失を利用することで、オリジナルGANの生成画像のうち、重要なコンテンツをより詳細に継承することができます。これらの蒸留損失と、通常のGANの学習損失$L_{GAN}$を組み合わせることで、最終的な学習目標は以下のようになります。
$L=L_{GAN}+\lambda L^{norm}_{KD} + \gamma L^{per}_{KD}$
生徒モデルの学習の際には、まず教師GANのGenerator$G$のプルーニングを行うことで生徒Generator$G'$を導出し、生徒Discriminator$D'$は教師Discriminatorをそのまま利用します。その後、$G',D'$の両方について、標準的なminmax最適化によるファインチューニングを行います。
実験結果
実験では、CIFAR-10上で学習されたSN-GAN、FFHQ上で学習されたStyleGAN2のモデル圧縮を行いました。出力画像の解像度は、SN-GANが32px、StyleGAN2が256,1024px四方となっています。
評価指標について
生成画像の性能を評価するため、以下の5つの定量的指標を利用します。
- Inception Score(IS):生成された画像の分類品質を測定する指標。
- Frechet Inception Distance(FID):生成された画像と実画像間の類似性を測定する指標。
- Perceptual Path Length(PPL):GANの潜在空間の滑らかさを測定する指標。
- PSNR・LPIPS:実画像と、その画像をGAN Inversionにより潜在ベクトルに変換し、その潜在ベクトルから生成した画像間の類似度を測定する。
最後のPSNR・LPIPSに関する評価指標は以下の図で示されます。

GANを用いた画像編集手法(例えばこの研究など)では、実画像に対応する潜在ベクトルを得て、そこから元画像を復元できるかが重要となるため、このような指標が導入されています。
また、こうした画像編集手法等では、画像内の重要なコンテンツが保持されているかが重視されるため、画像内の重要なコンテンツ以外の領域をマスクした画像間での類似度(上図のCAxPSNR/CA-LPIPS)も測定します。
提案手法(channel pruning)について
はじめに、提案手法のプルーニングと様々なベースラインとの比較結果は以下の通りです。
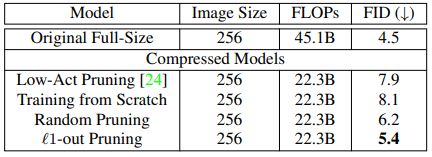
既存のプルーニング手法であるLow-Act pruningは、GANのモデル圧縮ではほぼ失敗しており、ランダムなプルーニングよりも性能が低く、ゼロから学習されたモデルとほぼ同等の結果を示しています。
一方、提案されたプルーニング手法では、FLOPsをオリジナルの半分程度に抑えながら、FIDスコアの低下は0.9のみとなりました。
提案手法(knowledge distillation)について
知識蒸留における先述した学習目標$L=L_{GAN}+\lambda L^{norm}_{KD} + \gamma L^{per}_{KD}$について、ハイパーパラメータである$\lambda,\gamma$などを様々に設定して実験を行った結果は以下のようになります(学習されたモデルは、提案されたプルーニング手法によりオリジナルモデルのチャンネルの80%を削除しています)。
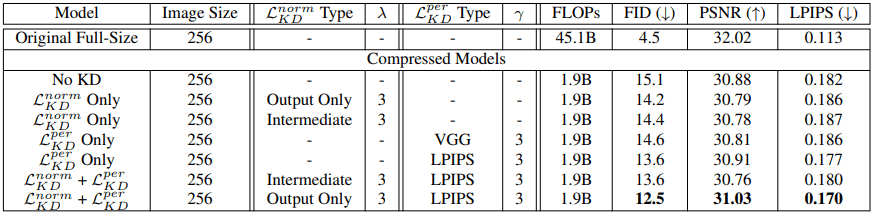
総じて、出力のみの$L^{norm}_{KD}$と、LPIPSによる$L^{per}_{KD}$により学習を行った場合が最も優れた結果を示しました。
最先端のGAN圧縮手法との比較
さらに、最先端のGAN圧縮手法であるGAN Slimming(GS)と提案手法との比較実験を行います。結果は以下の通りです。
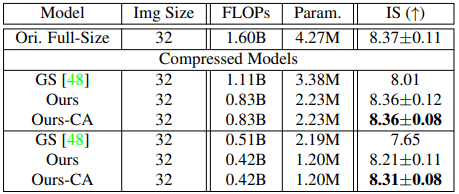
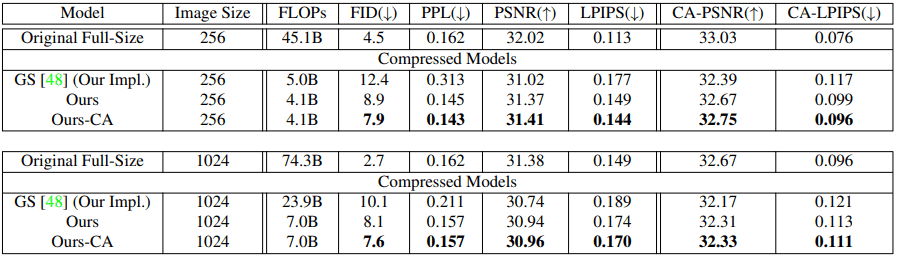
総じて、CIFAR-10/FFHQどちらについても、提案手法(特にContent-Aware設定の場合)がより優れた結果を示しました。
画像編集について
提案手法により圧縮されたモデルが、スタイル融合やモーフィング、GANSpaceの編集タスクなどに利用できるかについて検証した結果は以下の通りです。

この図ではスタイル融合・モーフィングの結果が示されており、総じてアーティファクトが少なく良質な画像の生成に成功しています。
また、GANSpaceにより画像編集の例は以下のようになります。

この図では、GANSpaceにおける$u_0$方向の画像編集(性別を変更できる)の検証がされており、提案手法により圧縮されたモデルでは、元画像($\sigma=0$)の性別が男性または女性方向にうまく変更されており、フルサイズモデルと比べてもアーティファクトが少なく、年齢の変化なども起きておらず、画像編集における提案手法の圧縮モデルの有効性を示しています。
アブレーション実験
提案手法のプルーニング・知識蒸留の有効性を検証するため、アブレーション研究を行います。
はじめに、提案手法のプルーニングをファインチューニング無しで行った場合の結果は以下の通りです。

提案手法である$CA-l1-out$は、その他と比べて出力される画像を保持しており、情報量の多いチャンネルの判別が適切に行われていることがわかります。
また、知識蒸留における、Content-Aware設定の有無による生成結果の変化事例は以下のようになります。

Content-Aware設定を持たないAS-KDと比べ、提案手法(CA-KD)は、画像内の重要なコンテンツをより適切に保持していることがわかりました。
まとめ
提案手法は、Unconditional GANのモデル圧縮において、既存の圧縮手法と比べて生成される画像の質・潜在空間の滑らかさなどの点で優れた結果を示し、画像編集等への応用についてもオリジナルモデルと同等以上の結果を発揮しうることが示されました。
こうした優れた圧縮技術は、エッジデバイスでの最先端モデルの利用などのために重要であり、今後のさらなる発展が待ち望まれる所です。



この記事に関するカテゴリー






