テキスト編集から話してる人のスピーチ合成が可能に!テキストベースのトーキングヘッド編集
論文: Text-based Editing of Talking-head Video
話者の顔と上半身に焦点を合わせるように設計されたトーキングヘッドビデオは、映画、テレビ番組、コマーシャル、YouTube、オンライン講義などいたるところで見られます。このような録画済みビデオを編集するのは大変そうです。

本稿では、テキストの編集のみに基づいて、話している人の音声と口の動きを変更させたり、発話の途中などの難しいカットポイントを自然につなぎ合わせたりなど、シームレスな動画合成に取り組んでいます。
アプリケーションは、新しいスクリプトを基にさまざまなビデオ作品からスピーチの動きを抽出し、機械学習を使用してそれらを自然に見えるビデオに変換します。
俳優やパフォーマーが言葉をまぎらわしたり、話し間違えたりした場合、ユーザーがスクリプトを編集するだけで、アルゴリズムはビデオのどこか別の場所で話されたさまざまな単語や単語の一部から正しい単語を組み立てることができます。まるで、ライターがスペルミスや不適切な単語をリタイプするのと同じように、ビデオをリライトするような感じです。

アプリケーションは主に3種類の編集操作に対応しています。
•新しい単語を追加
1つ以上の連続した単語を追加し編集する(例えば、俳優が単語をスキップした時にフレーズを挿入するなど)
•既存の単語を並べ替える
ビデオ内に存在する連続した単語を移動させることが可能
•既存の単語を削除する
ビデオから1つ以上の連続した単語が削除できる(たとえば、文言の簡略化や「um」や「uh」などのフィラーの削除)
現在、ユーザーごとに既存のオーディオやビデオコンテンツをカスタマイズするのは莫大な費用と労力がかかってしまいます。このツールを使えば、例えば、教育ビデオを異なる言語や文化的背景に合わせて微調整したりし、異なる年齢に合わせてビデオの内容を調整するなど、パーソナライズされたビデオ作成が簡単に行えるようになりそうです。
5段階のアプローチ
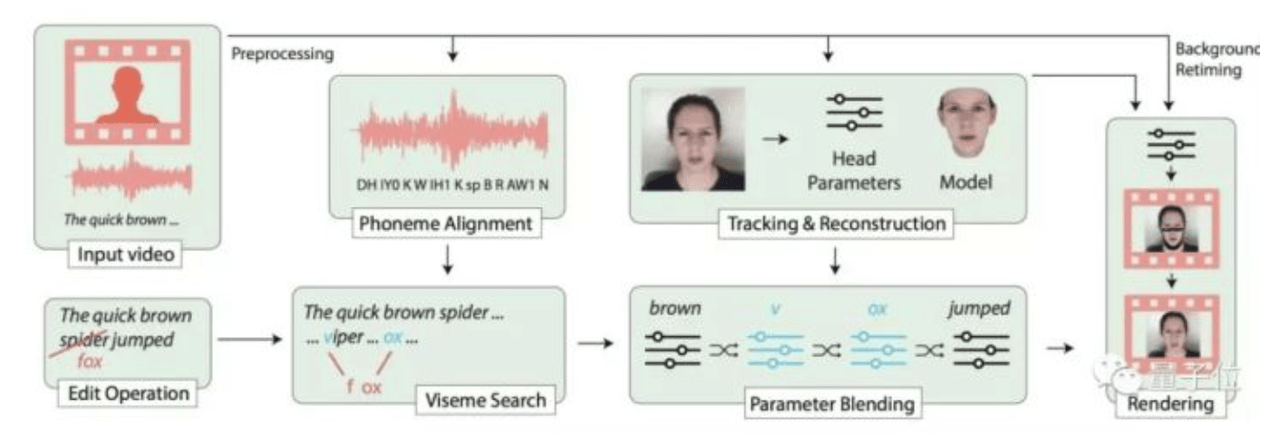
入力としてスクリプトで指定された任意の編集操作とトーキングヘッドのビデオ記録を取ります。
システムはこれらの入力を以下の五つの主要な段階(上図)で処理します。
1、最初のステップ:ビデオとテキストを揃える
音素は、母音と子音に分けられた意味論を区別する言語における音の最小単位です。各音素はそれ自身の対応する口形を持つため、まずはビデオとテキストの間の正確な位置合わせを行うことが必要です。
整列ツール、P2FAを使用し、さまざまな音素を区別することに加えて、各サウンドレベルの開始時刻と終了時刻をマークします。
ステップ2:3Dパラメトリックヘッドモデルをビデオに登録する
新しいシーケンスは、あるフレームの表情や他のフレームの頭の姿勢/向きと組み合わせたりなど複数のフレームをブレンドすることで合成できます。
ここでは、事前に入力のトーキングヘッドビデオの各フレームに3Dパラメトリック顔モデルを登録し、頭部姿勢や、反射率や表情、光線など、ビデオの1フレームごとに257パラメータのベクトルを取得しておきます。
(ここまでは、入力ビデオごとに1回実行される前処理ステップです)
ステップ3:リップサーチ
次に、与えられた編集操作(クモをキツネに変えるなど)に対して、新しい単語と似た形をした入力ビデオのセグメントを見つけます。
マッチング手順では、視覚的に互いに似ているように見える聴覚的に異なる音素のグループを、良い可能性のあるマッチングとして考えます。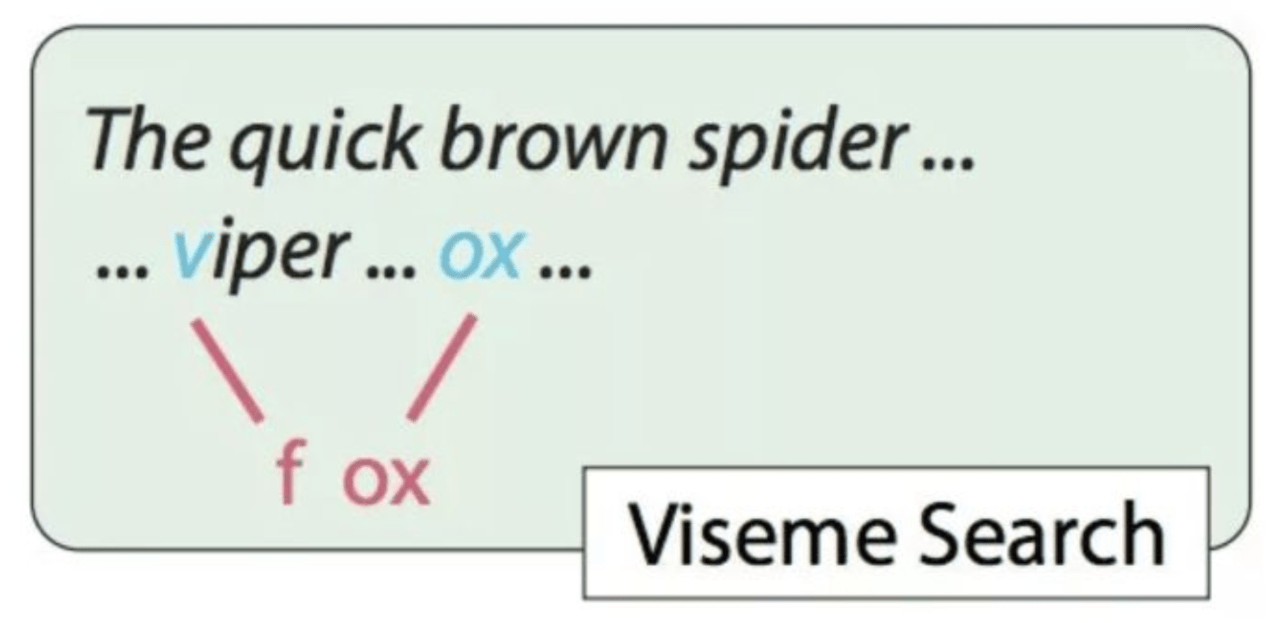
例えば、クモ(スインダー)をキツネ(Fox)にするには、本来は“f”唇と“ox”唇が必要です。
ただし,“v”と“f”では,視覚的に大きな差はありません。もし、動画に毒蛇(Viper)が登場したなら、“v”の唇形を取り出して、“ox”の唇形と組み合わせれば、“fox”の動作をさせることができます。
ステップ4 パラメータのリタイミングとブレンド
このプロセスでは、各セグメントの長さをリセットします。
抽出したサブシーケンスは同一性においてフレームの一部には対応しますが、長さにおいては対応せず、組み合わされると不自然なビデオを生成し、連続するシーケンス間の遷移は不自然に見える可能性が高いからです。
ここでは、2で事前に登録した3Dフェイスパラメータモデルを使用し、異なる入力フレームからの異なる特性(ポーズ、表情など)を混合し、それらをパラメータ空間で混合します。
操作によって生じる長さの変化を考慮してタイミングを調整し、シーケンスがリタイミングされます。
リタイミングされたシーケンスは、現実的なピクセルでビデオの残りの部分に自然に溶け込むポーズパラメータを生成します。
ステップ5、フェイスレンダリング
4の処理ステップの出力は、新しい所望の顔の動きに対応するリタイミングされた背景のビデオクリップを記述するパラメータシーケンスです。
修正されたパラメータシーケンスにマッチする写実的なトーキングヘッドビデオをGANを用いて合成します。
首の一部を含む口元の領域をマスクアウトし、上に目的の表情を持つ新しい口元をレンダリングします。

結果
主なアプリケーションは、トーキングヘッドビデオをテキストで編集することです。フレーズの移動と削除、新しい単語を追加するというような操作ができますが、他にも様々な現実的な用途に使えます。
1翻訳
例えば、ソースとなるビデオがターゲット言語に類似した口形素を含む限り、このアプローチはビデオ翻訳にも使用できます。口形素探索パイプラインは言語に依存しないため、新しい言語をサポートするために必要なのは、単語を個々の音素に変換する方法だけです。
2合成音声を用いた全文合成
Alexa、Siri、Google Assistantなどの音声アシスタントの登場により、ユーザーは音声ベースのインタラクションに慣れてきました。音声に対応するビデオを配信するためにこのアプローチを使うことができます。例えば、なりたい顔の俳優のビデオが与えられれば、このツールを使って、任意の言葉で俳優を喋らせることもできてしまいます。
3比較
こアプローチを他のトーキングヘッドビデオ合成技術と比較しています。
Deep Video Portraits(DVP)方式で出力された文字のレンダリングイメージと比較したものです。(DVP)では歯がズレて見えるのに対し本手法では自然に合成できています。


フレームを削除するタスクにおけるMorphCutと比較してたものです。MorphCutはフレーム2、3、4のシーン削除タスクに失敗していますが、本手法では正常に削除できています。
詳しい結果はこちらで確認できます




この記事に関するカテゴリー






