深層強化学習アルゴリズムの評価は正確か?
3つの要点
✔️ 深層強化学習の評価基準のバイアス・不確実性について検証
✔️ 既存のアルゴリズム評価について再検討
✔️ 実行回数が少ない条件下でより有効な評価基準の提案
Deep Reinforcement Learning at the Edge of the Statistical Precipice
written by Rishabh Agarwal, Max Schwarzer, Pablo Samuel Castro, Aaron Courville, Marc G. Bellemare
(Submitted on 30 Aug 2021 (v1), last revised 13 Oct 2021 (this version, v3))
Comments: NeurIPS 2021.
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Methodology (stat.ME); Machine Learning (stat.ML)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
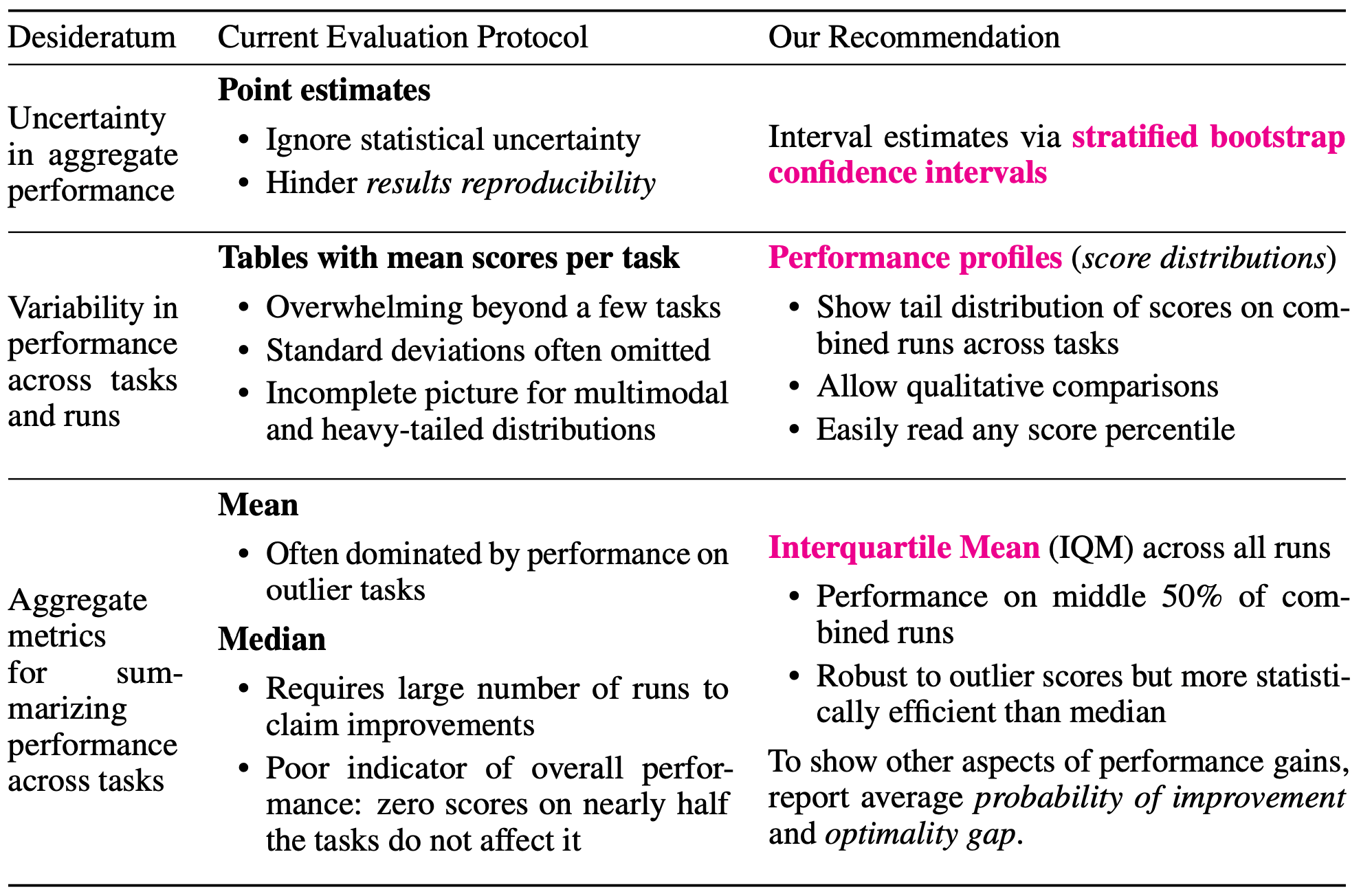
深層強化学習(RL)アルゴリズムの既存の評価は、タスク性能の平均値・中央値などの点推定値の比較に頼っており、統計的な不確実性が無視されている傾向にあります。
この傾向は、ベンチマークの計算負荷が大きく、性能評価のための実行回数を増やすことが困難になるにつれ、より深刻化しています。
本記事で紹介する論文では、点推定値に頼る既存の評価方式の問題を示し、より厳密な評価方式を提案しました。以下に見ていきましょう。
強化学習アルゴリズムの性能指標について
強化学習アルゴリズムについて、$m$個のタスクを$N$回行い、その性能の評価に用いるとします。
ここで、それぞれの正規化されたスコアを$x_{m,n}$($m=1,...,M, n=1,...,N$)とし、これらの集合を$x_{1:M,1:N}$、$m$個目のタスクの正規化スコアの確率変数を$X_m$と表記します。
強化学習アルゴリズムの性能指標によく用いられているのは、正規化スコアの標本平均値または標本中央値です。
これは、タスク$m$の平均スコアを$\bar{x}_m=\frac{1}{N}\sum^N_{n=1}x_{m,n}$とすると、$Mean(\bar{x}_{1:M})$または$Median(\bar{x}_{1:M})$で表されます。
これらの値は、$Mean(\bar{X}_{1:M})$と$Median(\bar{X}_{1:M})$の点推定値にあたります。
Atari 100k ベンチマークにおける点推定について
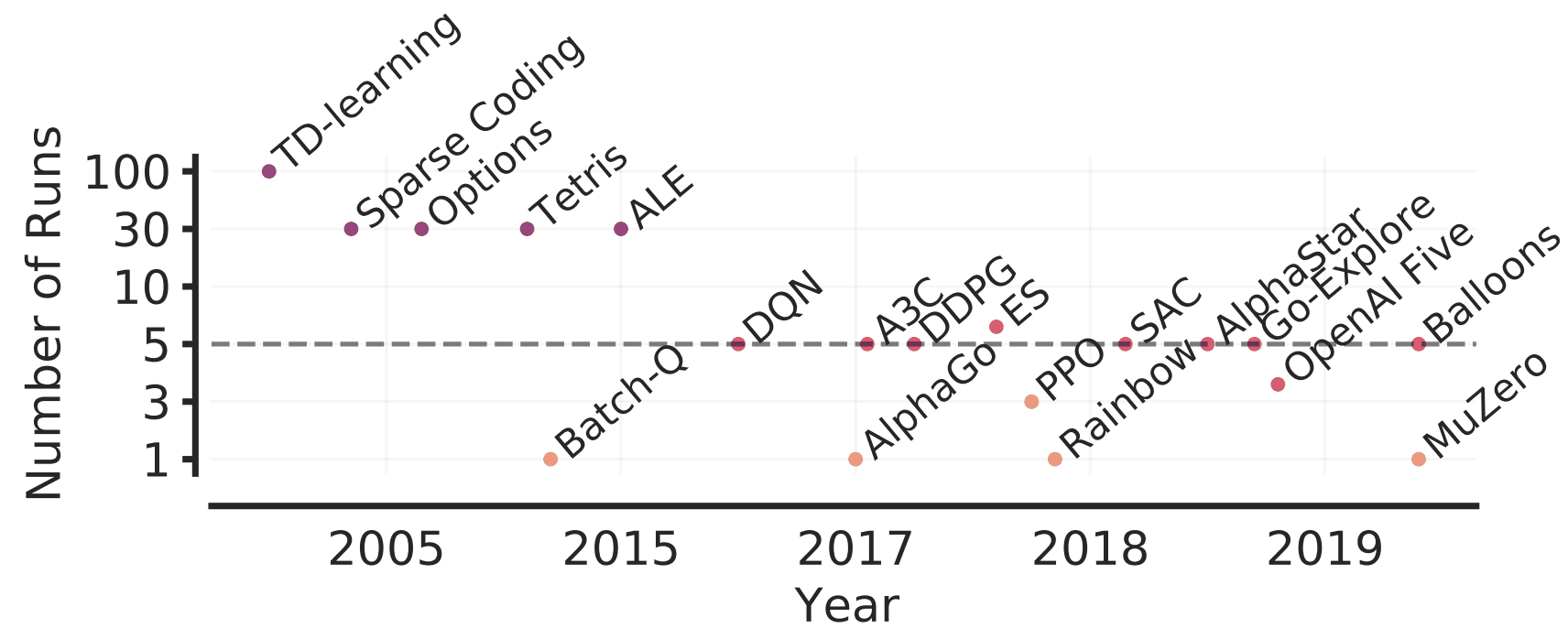
Atari 100kベンチマークでは、26種類のゲームについて、それぞれ100kステップのみでアルゴリズムを評価します。このベンチマークを利用した過去の事例では、3、5、10、20回の実行により性能が評価されており、その多くは3、5回のみの実行でした。また、評価指標には主に標本中央値が利用されています。
ここでは実行回数が少ない条件下で点推定値を評価に用いる具体的な事例として、最近の5つの深層RLアルゴリズムの性能比較を行います。
実験では、DER、OTR、DRQ、CURL、SPRの5つのアルゴリズムについて、それぞれ100回実行し、その実行結果のうち一部をサブサンプリングし、その中央値を測定します。
これを用いて、実行回数が少ない場合の中央値について調査を行います。
点推定値のばらつきの大きさ
サブサンプリングの際には、論文での実行回数と同じ数だけ結果を収集します。DER、OTR、DRQは5回、CURLは20回、SPRは10回分について、それぞれ中央値を求めます。
実験の結果は以下の通りです。
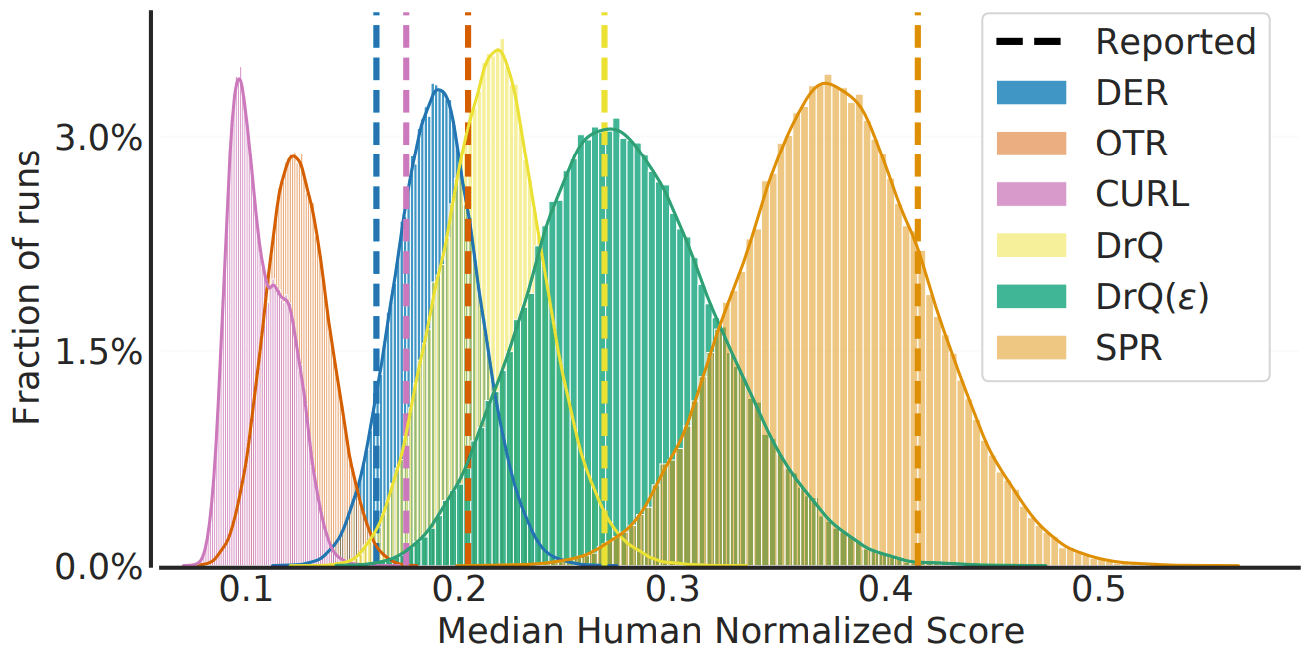
この図では、得られた中央値の分布と、論文にて報告された数値が示されています。総じて、少数のサンプルから得られた標本中央値には大きなばらつきがあり、点推定値をもとに比較を行うことは誤った結論に繋がる可能性があることがわかります。
また、評価プロトコルの変化もアルゴリズムの比較に大きな影響をもたらします。
強化学習アルゴリズムの評価には、最終訓練エピソードのスコアを用いることが典型的ですが、訓練中の最高スコアや、複数回の実行によるスコアが報告されることもあります。実際に、DERの評価プロトコルを、CURL・SUNRISEのものに変更した場合、以下の図のように結果が大きく変化します。

このように、実行回数が少ない条件下での点推定値のばらつきに加え、評価プロトコルの変化も、強化学習アルゴリズムの評価の正確さに大きな影響をもたらしています。
信頼性の高い評価のための推奨事項とツール
先述の問題を解決するために実行回数を大きくすることは、ベンチマークの計算負荷の大きさにより非現実的ではありません。
元論文ではこの解決のため、実行回数が少ない場合における信頼性の高い指標について、三つのツールを提案しています。
層別ブートストラップ信頼区間
1つ目は、層別サンプリングによるブートストラップ法で信頼区間を求めることです。
単一タスクの平均スコアについてブートストラップ法を用いることは、$N$が小さい場合には有用ではないため、$m$個のタスクそれぞれについて$N$個の実行結果の中からサンプリングを行い、これを元に信頼区間を求めます。
performance profile
2つ目は、最適化ソフトウェアのベンチマークに用いられるperformance profileを用いることです。
より具体的には、ある正規化スコア以上の実行の割合を示すスコア分布(またはrun-score分布)を用いることが提案されています。これは以下の式で与えられます。
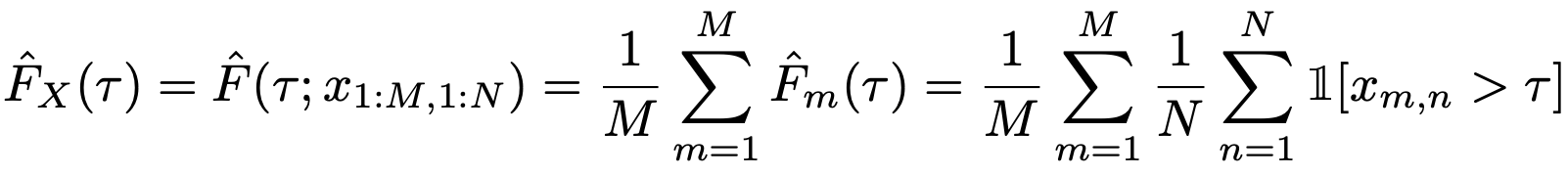
また、実際の比較結果は以下の通りです。
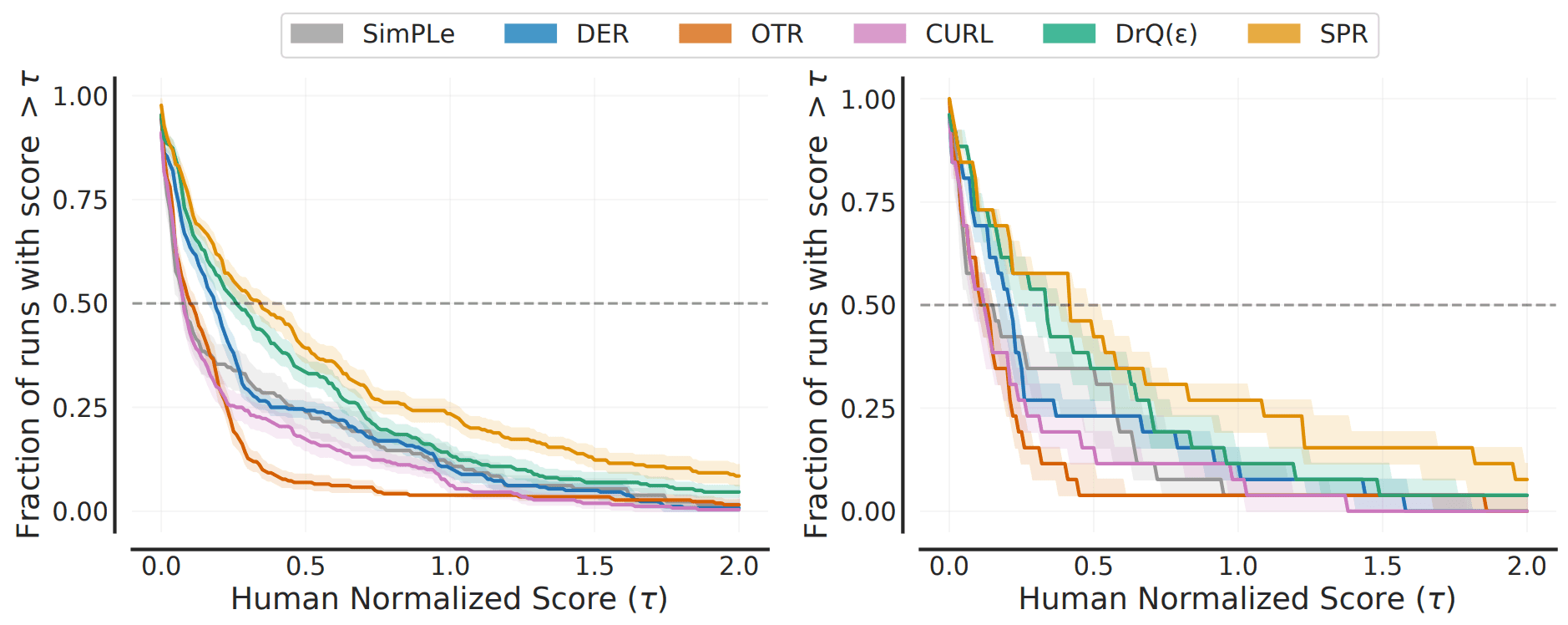
この図について、左はスコア分布を、右は平均スコア分布(ある正規化スコア以上の性能を示すタスクの割合)を示しており、スコア分布のほうが分散が小さくよりロバストな指標だといえます。
InterQuartile Mean (IQM)
スコア分布のような指標では、二つの曲線が複数の点で交差するなどの場合、どちらが優位かの判別が難しくなります。
そこで、中央値の代わりに用いることのできる集約的な指標として、InterQuartile Mean (IQM)を利用することが提案されています。これは、下位25%と上位25%を除いた残りの50%についての平均値によって計算されます。
IQMは外れ値に強く、またタスク間の順序に強く依存している中央値と比べ、全体的なパフォーマンスの指標となるため、よりロバストです。実際に、先述した5つの強化学習アルゴリズムについて、平均値とIQMの95%信頼区間は以下のようになります。
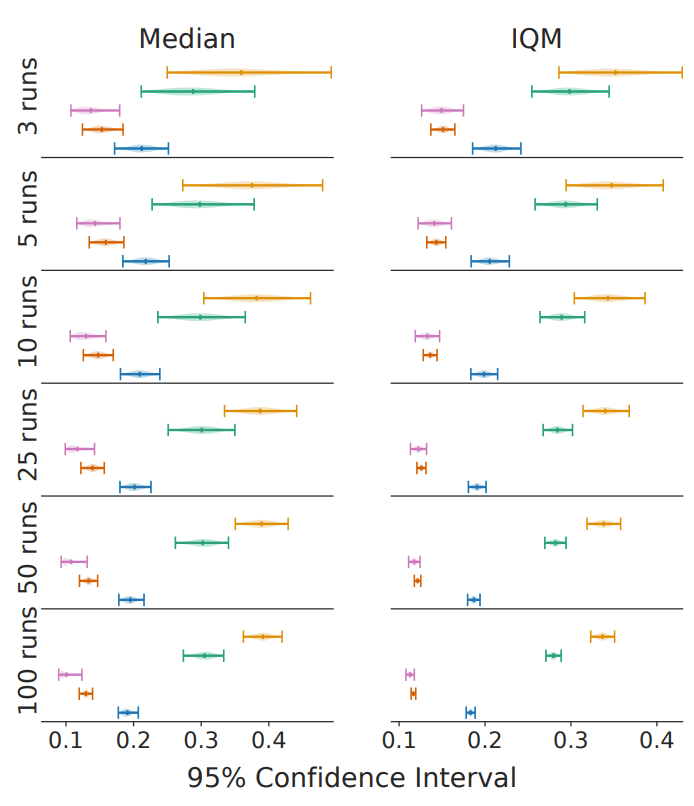
図の通り、試行が少ない場合でも不確かさが小さく抑えられていることがわかります。
深層強化学習ベンチマークでの評価について
最後に、既存のいくつかの深層強化学習ベンチマークの評価について検討を行います。
・Arcade Learning Environment(ALE)
ALEにて200Mフレームの間学習を行うベンチマークは広く認知されています。このベンチマークについて、既存のアルゴリズムの性能を様々な指標で測定した結果は以下の通りです。
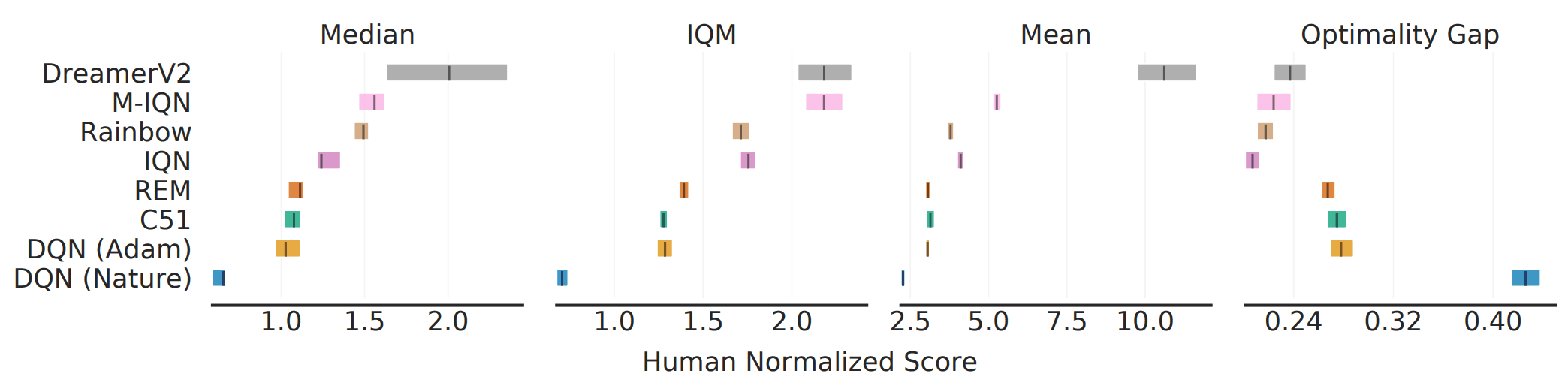
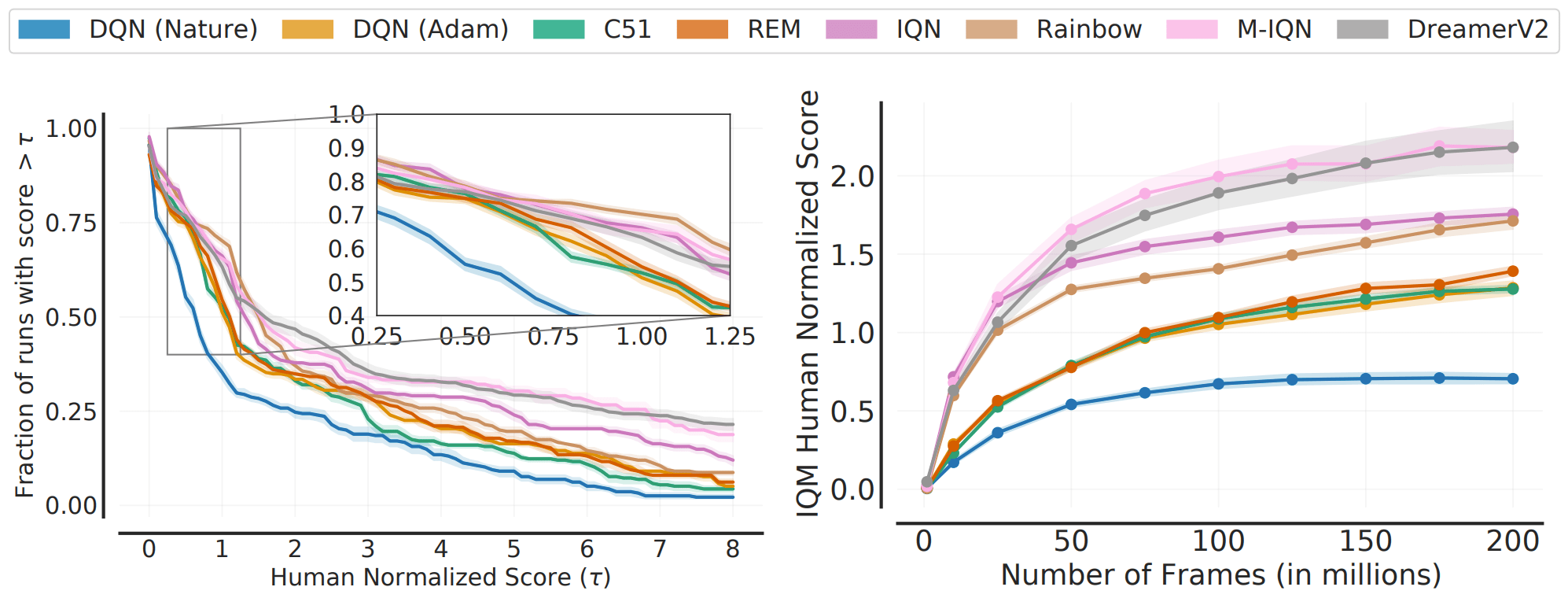
図の通り、指標の選択によってアルゴリズム間の順位が変わる場合が存在しています(中央値とIQMなど)。これは、集約的な指標がタスク・実行全体の性能の全てを捉えているわけではないことを示しています。
・DeepMind Control Suite
次に、連続制御タスクであるDM Controlについての結果は以下の通りです。
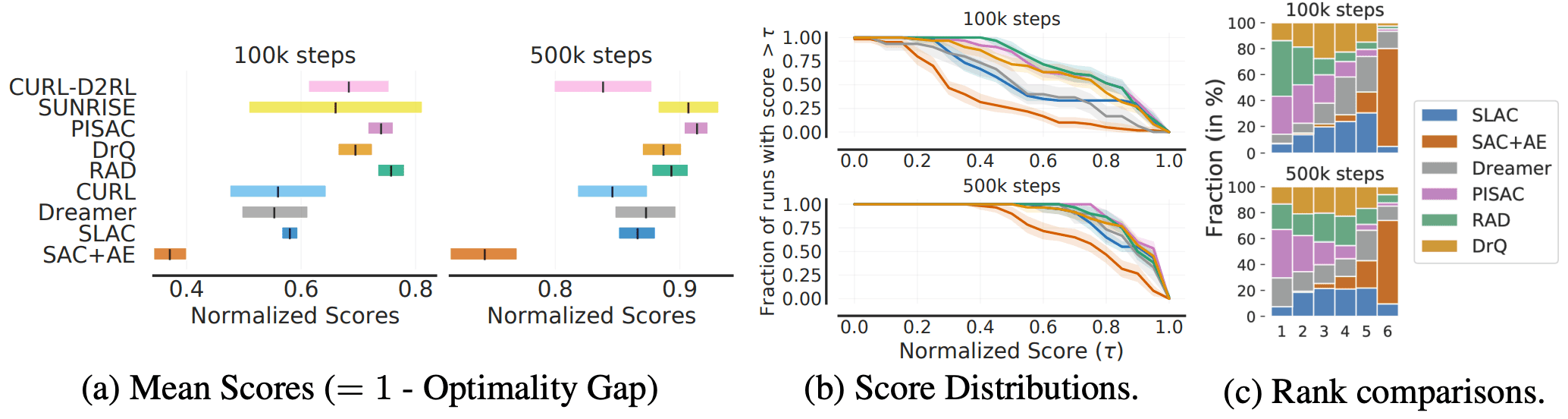
図のアルゴリズムは論文で主張された相対的な性能順で並んでいますが、実際には不確かさによるばらつきが大きく、実際の優劣と報告された性能には差異があるかもしれません。
まとめ
深層強化学習アルゴリズムについて、その報告された性能がバイアスや不確実性の影響を多く受けていることが示唆されました。論文では、バイアスや不確実性を抑えるための指標や、それを抑えるための提言が述べられています。
また、強化学習のより正確な評価・分析のためのライブラリが公開されています。元論文と合わせてぜひご覧ください。
宣伝
cvpaper.challenge主催でComputer Visionの分野動向調査,国際発展に関して議論を行うシンポジウム(CCCW2021)を開催します.世界で活躍している研究者の講演や天才に勝つためのチームづくりについて議論を行う貴重な機会が無料なので,是非ご参加ください!!




この記事に関するカテゴリー






