
【PiCIE】教師なしセマンティックセグメンテーションのためのピクセルレベルのクラスタリング
3つの要点
✔️ ピクセルレベルのクラスタリングを元にした教師なしセマンティックセグメンテーション手法の提案
✔️ 二つの帰納的バイアス(Invariance・Equivariance)を導入した損失関数の利用
✔️ COCO・Cityscapesにおいて優れた性能を発揮
PiCIE: Unsupervised Semantic Segmentation using Invariance and Equivariance in Clustering
written by Jang Hyun Cho, Utkarsh Mall, Kavita Bala, Bharath Hariharan
(Submitted on 30 Mar 2021)
Comments: CVPR 2021.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
セマンティックセグメンテーションのためには、ピクセルレベルのアノテーションが行われたデータセットが重要となります。
しかし現実には、画像のアノテーションには大きなコストがかかるため、必ずしもそのようなデータセットが得られるとは限りません。
本記事で紹介する論文では以下の図のように、ラベルなしデータセットから教師なしセマンティックセグメンテーションを行う手法を提案しています。

このような教師なしセマンティックセグメンテーションが実現できれば、アノテーションのコスト削減、人間が発見していないクラスの発見などの様々な利点があります。
提案手法であるPiCIE(Pixel-level feature Clustering using Invariance and Equivariance)では、ピクセルレベルのクラスタリングをもとにこの問題に対処し、既存手法と比べ優れた成果を示しました。以下に見ていきましょう。
提案手法(PiCIE)
はじめに、教師なしセマンティックセグメンテーションタスクのタスク設定について考えます。
このタスクは、あるドメイン$D$から得られたラベルなし画像データセットについて、画像内の視覚的なクラスの集合$C$を発見し、$D$から得られた画像内の全ピクセルにクラスを割り当てる関数$f_{\theta}$を学習することが目標となります。
提案手法であるPiCIEでは、(各画像ではなく)画像内の全ピクセルをクラスタに割り当てる、ピクセルレベルのクラスタリングとしてこの問題を解決します。
ただし、このようなクラスタリングを適切に行うには、各ピクセルを優れた特徴表現に変換することが求められますが、このような特徴空間は事前に与えられてはいません。
そのためPiCIEでは、ピクセルレベルのクラスタリングと、そのための特徴表現の学習とを行います。
ピクセルレベルのクラスタリングによるベースライン
ピクセルレベルのクラスタリングについて考える前に、画像レベルのクラスタリングを行う場合の既存研究について取り上げます。
ここで課題となるのは、クラスタリングのためには優れた特徴表現が必要ですが、その特徴表現を得るためにはクラスラベルが必要になるというジレンマです。
この問題を解決するため、DeepClusterでは、特徴表現を求めてクラスタリングを行い、そのクラスタリングにより得られたクラスタを疑似ラベルとして利用し特徴表現を学習する、という処理を行います。この方法は教師なしセマンティックセグメンテーションにも拡張することができます。
つまり、各ピクセルについての特徴表現を求めてピクセルごとにクラスタリングを行い、その疑似ラベルを用いてピクセルごとの特徴表現を学習する、という処理を行います。
具体的には、ラベルなし画像$x_i (i=1,...,n)$について、$f_\theta$により得られた特徴テンソルを$f_\theta(x)$、ピクセル$p$に対応する特徴表現を$f_\theta(x)[p]$、各ピクセルの分類を行う分類器を$g_w(\cdot)$とすると、以下の二つの処理を繰り返し行うベースラインが考えられます。
1. 現在の特徴表現とk-means法(実際にはMini Batch K-Means法)により、データセット内画像の各ピクセルのクラスタリングを行います。
$min_{y,\mu} \sum_{i,p} ||f_\theta(x_i)[p]-\mu_{y_{ip}}||^2$
ここで、$y_{ip}$は$i$番目の画像の$p$番目のピクセルのクラスタラベルを、$\mu_k$は$k$番目のクラスタの中心点(centroid)を表します。
2.クラスタリングにより得た疑似ラベルをもとに、クロスエントロピー損失を用いたピクセルごとの分類器を学習します。
$min_{\theta,w} \sum_{i,p} L_{CE}(g_w(f_\theta(x_i)[p]),y_{ip})$
$L_{CE}(g_w(f_\theta(x_i)[p]),y_{ip})=-log\frac{e^s_{y_{ip}}}{\sum_ke^{s_k}}$
ここで、$s_k$は分類器$g_w(f_\theta(x_i,p))$の$k$番目のクラスに対応するスコア出力です。これらをベースラインとして、提案手法のPiCIEは以下に述べる修正を施します。
分類器のノンパラメトリック化
前述したベースラインでは、各ピクセルのクラス分類を行う分類器$g_w(\cdot)$を用いています。
しかし、この分類器の学習に用いられる疑似ラベルは学習途中に常に変化するため、この分類器の出力はノイズが多くなり、有効に機能しない恐れがあります。
そのため、ピクセル分類器$g_w$は利用せず、各クラスタの中心点との距離を利用した単純なピクセルのラベル付けを行います。
$min_\theta \sum_{i,p}L_{clust}(f_\theta(x_i)[p],y_{ip},\mu)$
$L_{clust}(f_\theta(x_i)[p],y_{ip},\mu)=-log(\frac{e^{-d(f_\theta(x_i)[p],\mu_{y_{ip}})}}{\sum_l e^{-d(f_\theta(x_i)[p],\mu_l)}})$
ここで、$d(\cdot,\cdot)$はコサイン距離となります。
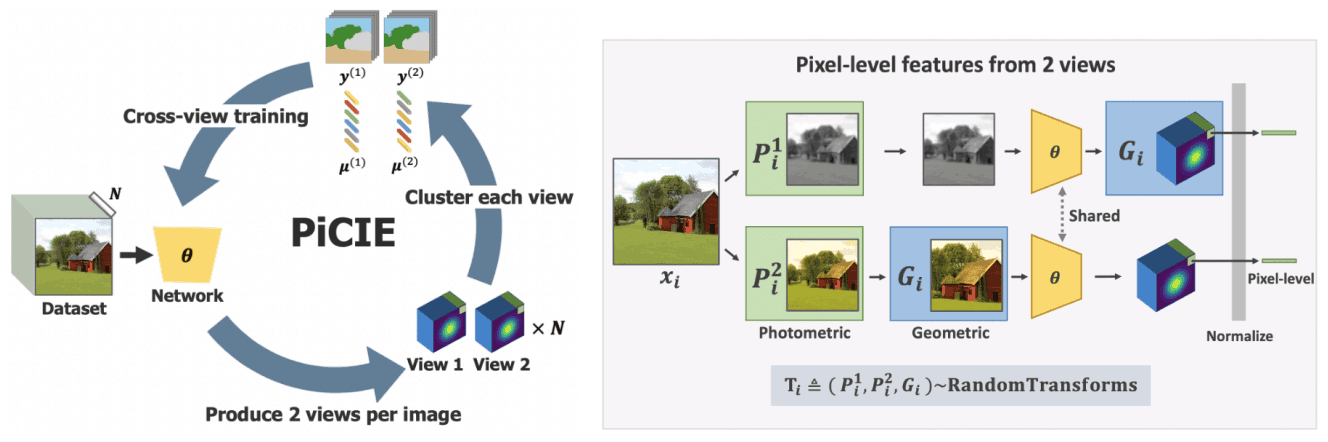
帰納的バイアスの導入
上述した学習手順に加え、セマンティックセグメンテーションのために二つの帰納的バイアス(inductive bias)を導入します。
- フォトメトリック変換に対する不変性(Iinvariance to photometric transformations):ピクセルの色が多少変化してもラベルは不変である。(例えば、画像全体の明度が変化してもラベルが変わることはありません。)
- 幾何学的変換に対する等変性(Equivariance to geometric transformations):画像が幾何学的に変化すれば、ラベルも同様に変化する。(例えば、画像の一部を拡大すれば、ラベルも同様に拡大されたものとなります。)
具体的には、画像$x$に対するセマンティックラベル出力を$Y$、フォトメトリック変換を$P$、幾何学的変換を$G$とすると、これらの変換を受けた画像$G(P(x))$の出力は$G(Y)$となります。
予測結果がこれらの特性を満たすよう、以下に示す処理を行います。
・フォトメトリック変換に対する不変性について
まず、フォトメトリック変換に対する不変性について考えます。
データセット内の画像$x_i$について、2つのフォトメトリック変換$P^{(1)}_i$,$P^{(2)}_i$をランダムにサンプリングします。これらの変換を行った画像について、各ピクセルに対応する二つの特徴ベクトルが得られます。
$z^{(1)}_{ip}=f_\theta(P^{(1)}_i(x_i))[p]$
$z^{(2)}_{ip}=f_\theta(P^{(2)}_i(x_i))[p]$
これらの特徴ベクトルに基づき、二つの疑似ラベルと中心点を得ることができます。
$y^{(1)},\mu^{(1)}=arg min_{y,\mu} \sum_{i,p}||z^{(1)}_{ip}-\mu_{y_{ip}}||2$
$y^{(2)},\mu^{(2)}=arg min_{y,\mu} \sum_{i,p}||z^{(2)}_{ip}-\mu_{y_{ip}}||2$
これらの疑似ラベルと中心点に基づき、以下に示す二つの損失関数を導入します。
$L_{within}=\sum_{i,p}L_{clust}(z^{(1)}_{ip},y^{(1)}_{ip},\mu^{(1)})+L_{clust}(z^{(2)}_{ip},y^{(2)}_{ip},\mu^{(2)})$
$L_{cross}=\sum_{i,p}L_{clust}(z^{(1)}_{ip},y^{(2)}_{ip},\mu^{(2)})+L_{clust}(z^{(2)}_{ip},y^{(1)}_{ip},\mu^{(1)})$
$L_{within}$により、フォトメトリック変換を受けた場合にも、特徴ベクトルのクラスタリングが有効に機能するよう(擬似ラベルに対応する中心点に近くなるよう)学習を行います。
一方$L_{cross}$では、異なるフォトメトリック変換を受けた画像に対応する疑似ラベル・中心点についても特徴ベクトルのクラスタリングが有効に機能するよう学習を行うことで、フォトメトリック変換に対する不変性を実現します。
・幾何学的変換に対する等変性について
さらに、幾何学的変換に対する等変性を導入します。具体的には、幾何学的変換$G_i$を、先述した2つの特徴ベクトルに組み込みます。
$z^{(1)}_{ip} = f_\theta(Gi(P^{(1)}_i (xi)))[p]$
$z^{(2)}_{ip} = G_i(f_\theta(P^{(2)}_i (xi)))[p]$
このとき、$z^{(1)}_{ip}$ではフォトメトリック変換を受けた画像$P^{(1)}_i (xi)$に、$z^{(2)}_{ip}$ではフォトメトリック変換を受けた画像の特徴ベクトル$f_\theta(P^{(2)}_i (xi))$に対し、それぞれ幾何学的変換を行います。
これらの特徴ベクトルをもとに、先述した損失関数を組み合わせた損失関数$L_{total}=L_{within}+L_{cross}$を利用することで、不変性・等変性をもとにした学習を行います。
最終的に、PiCIEのパイプライン・疑似コードは以下のようになります。

実験結果
実験では、COCO・Cityscapesデータセットを用いて検証を行います(実験設定は省略します)。COCO・Cityscapesデータセットに対する提案手法の予測例は以下のようになります。
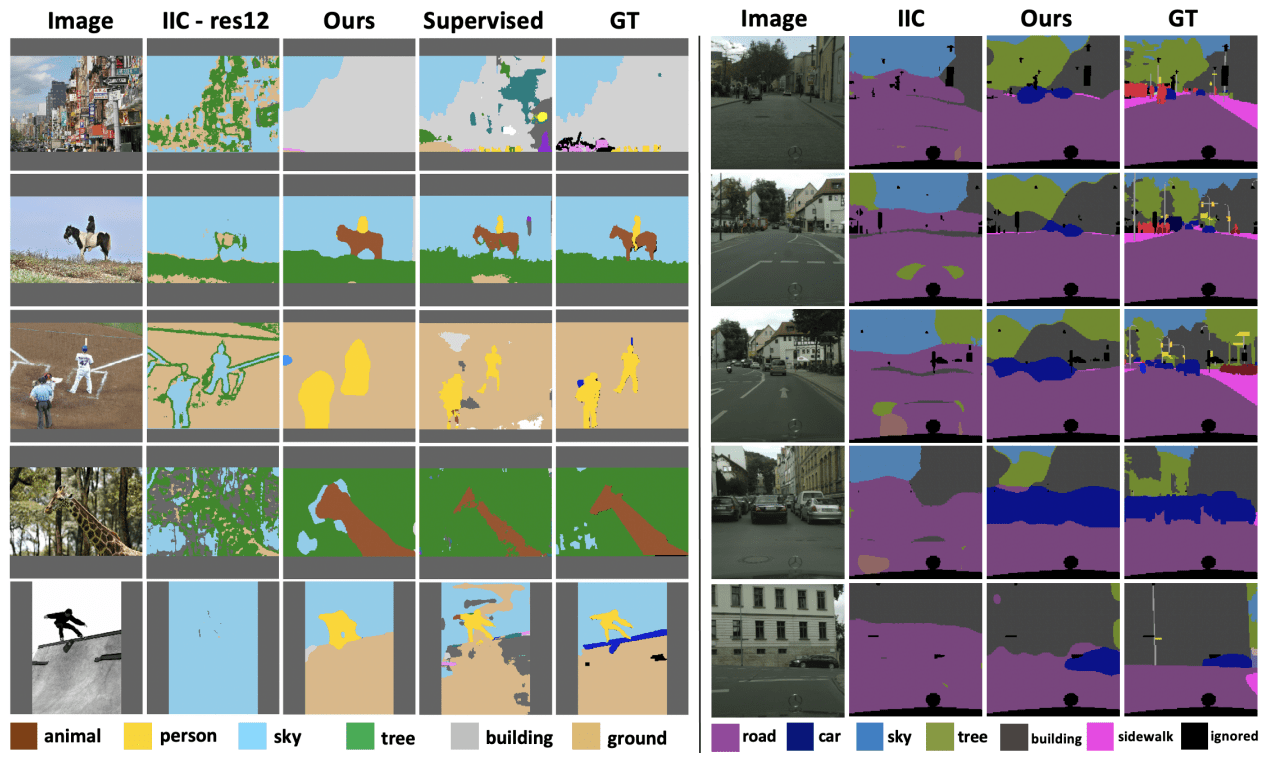
図の通り、ベースラインとなる既存手法のIICと比べ、提案手法は優れた予測結果を示しています。また、SupervisedやGround Truthと比べても遜色ありません。
また、COCOデータセット全体に対する性能、二つのカテゴリ(Stuff/Thing)に対する性能、Cityscapesデータセットに対する性能はそれぞれ以下の通りです。
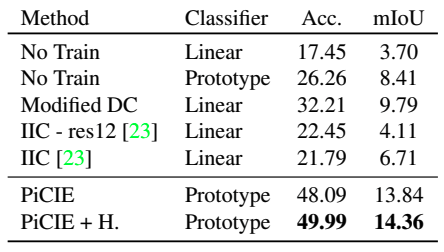
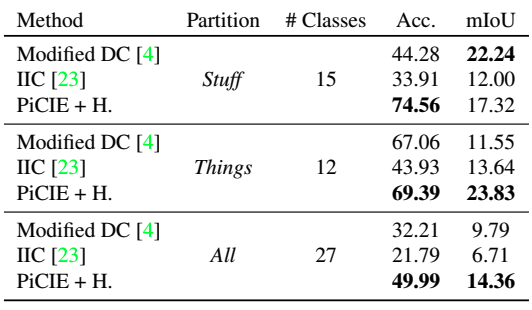

Modified DCは、DeepClusterをセマンティックセグメンテーションのために修正したものを示しています。また、+HはOverclustering(クラスタ数の大きい場合についても共同で最適化を行う)を示しています。総じて、既存の教師なし手法と比べ、提案手法は優れた結果を示しました。
まとめ
教師なしセマンティックセグメンテーションという困難な問題について、本記事で紹介した論文では、ピクセルレベルのクラスタリングと二つの帰納的バイアスを導入することにより対処し、優れた結果を示しました。
これらは非常にシンプルであり、タスク固有の処理や細かいハイパーパラメータチューニングを必要としないにも関わらず、COCOデータセットのstuff・thingsカテゴリの両方で良好に動作しており、教師なしセマンティックセグメンテーションのための新たな道を切り拓いたといえるのではないでしょうか。






この記事に関するカテゴリー





