強化学習の環境紹介!
3つの要点
✔️ 様々な強化学習の学習に利用される環境の紹介
✔️ 複雑かつLong-horizonなタスクを想定したものなど環境ごとに評価目的が異なる
✔️ 評価したいことに応じて環境を正しく選ぶことが重要
RL environment list
Contributors by Andrew Szot Joseph Lim Youngwoon Lee dweep trivedi Edward Hu Nitish Gupta
はじめに
近年の強化学習の研究の進歩に伴い、強化学習のエージェントを学習させるための様々な環境が提案されています。では、学習を行いたいエージェントに対してどの環境を選べば良いのでしょうか? 本記事では、様々な強化学習の環境の中でも、頻繁に使われるであろう環境を紹介し、今後、強化学習を用いた実験を行う際の環境選択に役に立つよう紹介します。
ロボティクス
本章では強化学習をロボティクスに対して利用するための環境を紹介します。
Robosuite
Robosuiteは基本的なmanipulation task(Lift, Assemblyなど) を提供している環境です。また、様々なコントローラーやロボットに関しても評価することができ、現在は、Panda、Sawyer、IIWA (KUKA)、Jaco、Kinova3、UR5e、そしてBaxterのモデルを提供しています。またこの環境では、下図のように一つのロボットによるタスクだけではなく、複数のロボットを用いて解くタスクも用意してあります。この環境の優れているところは、比較的簡単に新しい環境を自作することが出来ることで、非常に便利なベンチマークとなる環境です。
robosuite: A Modular Simulation Framework and Benchmark for Robot Learning
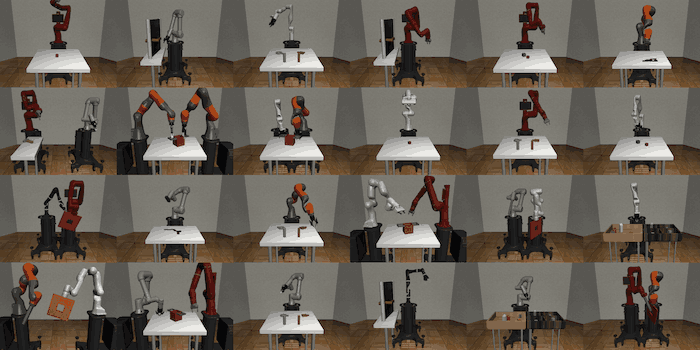
IKEA Furniture Assembly
ロボットを利用した家具の組み立てに関する環境で、非常に複雑かつ長期間に渡ってエージェントを実行しなければならないLong-horizon taskを提供しています。この環境には80以上もの家具が提供されており、環境のバックグラウンド、ライト、そしてテキスチャなどを簡単に変更することができます。現在はBaxterとSawyerロボットのモデルが提供されています。また、この環境ではdepth画像とsegmentation画像にアクセス出来るようになっています。
IKEA Furniture Assembly Environment for Long-Horizon Complex Manipulation Tasks

Meta-World
50種類のSawyerロボットによるmanipulationタスクが提供されています。この環境は主に、Multi-Task Learningなどで利用されることが多く、学習やテストに利用するタスクの数が異なる様々な評価のモードがあります。
Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning

RLBench
RL Benchも上で紹介した環境と同様に様々なmanipulation taskを提供している環境です。ただし、この環境はGeometric computer visionなどの研究分野なども考慮した環境になっています。この環境では、Few-shot learning, Meta-Learning, Sim-To-Real, Multi-Task Learningなど様々な研究分野に関する簡単なチュートリアルも用意されています。
RLBench: The Robot Learning Benchmark & Learning Environment

ゲーム
この章では、強化学習をゲームに応用する際の環境をいくつか紹介します。
Gym Retro
クラシックビデオゲームをGymの環境に適応させたもので、約1000種類ものゲームが用意されています。
Gotta Learn Fast: A New Benchmark for Generalization in RL

VizDoom
VizDoomは、Doomと呼ばれるシューティングゲームのシミュレーターで、画像情報を用いて強化学習を学習することができます。この環境にもいくつかのタスクが用意されており、敵を倒す、救急キットを集める等のタスクが用意されています。
ViZDoom: A Doom-based AI Research Platform for Visual Reinforcement Learning
StarCraft 2
StarCraft2のゲームを実行できるようにしたインターフェースで、Observationをこのインターフェースを通して受け取り、actionをインターフェースを通してゲームに送ることができます。これは特に、DeepMindによる研究にて主に利用された環境になります。
StarCraft II: A New Challenge for Reinforcement Learning
Minecraft
MineCraftのゲームを行うことが出来るシミュレーターです。

Suites
この章では様々な種類のタスク、環境を一式揃えたいわゆるSuitesと呼ばれるものを紹介していきます。
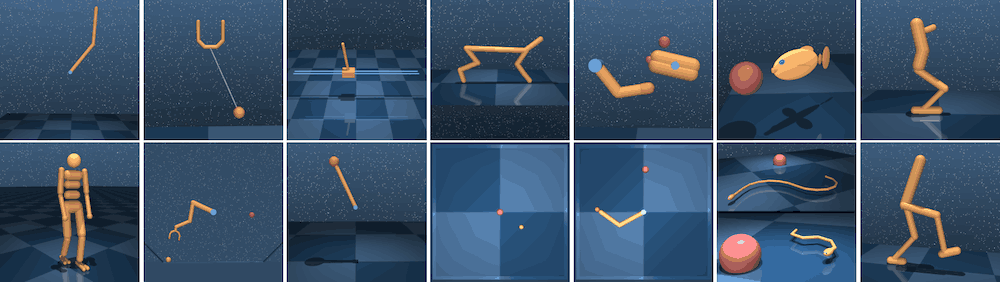
DeepMind Control Suite
DeepMindが提供している環境で、様々なcontrol taskが用意されております。代表的なものでは、Walkerなどエージェントが歩けるようにすることを目的としたタスクやReacherと呼ばれる2Dの環境においてエージェントがゴールに辿り着くようにするタスクなどがあります。この環境は様々な研究におけるベンチマークとして度々利用され、Image observationかlow-dimensional stateどちらをエージェントが受け取るかを簡単に切り替えたりすることができます。
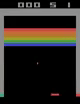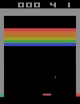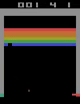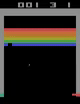
Open AI Gym Atari
OpenAIが提供している環境であり、59のAtariのゲームが用意されており、画像がobservationとして与えられます。
Open AI Gym Mujoco
連続制御に関するタスクを提供している環境で、MuJocoと呼ばれる非常に素早い物理シミュレーターを利用している環境です。この環境では、基本的にlow-dimenstional stateがobservationとして与えられます。

Open AI Gym Robotics
ShadowHand(下左図)とFetch(下右図) Robotの2つに関する、ゴールが与えられるようなタスクが提供されている環境です。
Multi-Goal Reinforcement Learning: Challenging Robotics Environments and Request for Research


Navigation
この章ではNavigationタスクを紹介していきます。
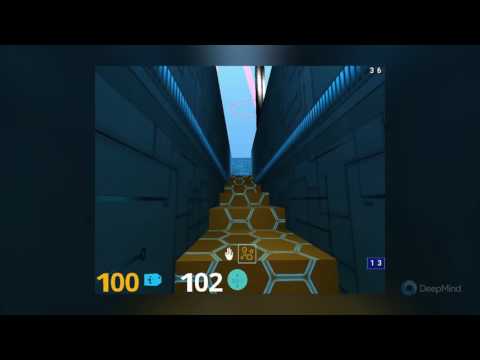
DeepMind Lab
DeepMindから提供されている環境で、困難な3D Navigationに関するタスクを提供しています。また、パズルを解くようなタスクなど様々なタスクが用意されています。
gym-minigrid
グリッドベースの軽量かつ高速な環境で、主に簡単な実験を行ったりする際などに使われたりします。また、この環境は簡単に変更かつ拡張可能なので使いやすいという利点もあります。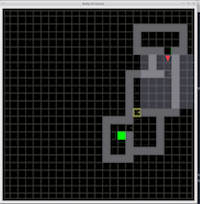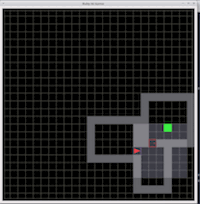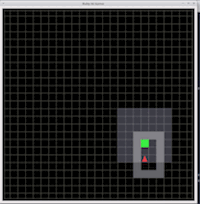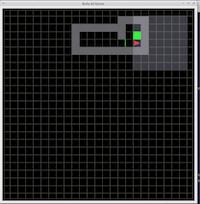
AI2THOR
AI2THORは、Home Navigationに関するシミュレーションで、様々な家具や物体とインタラクションすることができます。Agentのactionは基本的に離散的に表されます。主に、Long-horizonなタスクなどを用意することが可能です。
AI2-THOR: An Interactive 3D Environment for Visual AI

Gibson
GibsonもAI2THORと同様に屋内のnavigationに関するタスクを提供する環境ですが、Gibsonでは主にロボットが連続的制御によって動きます。
Gibson Env: Real-World Perception for Embodied Agents
Habitat
Habitatは、Facebookが提供しているシミュレーターで、フォトリアリスティックな環境です。したがって、sim2realなどで効果的であると考えられるシミュレーターになります。
Habitat: A Platform for Embodied AI Research

Multi-Agent
Multi-agent Particle Environment
Multi-Agent RLの学習を行うことが出来る、単純な環境で、連続的な値がobservationとして与えられ、行動は離散的に表されます。

OpenAI Multi-Agent Competition Environments
下図のように、連続制御に関する様々なMulti-agentタスクを提供しているもので、主にMulti-agentにおける競争に関して焦点が置かれています。
Emergent Complexity via Multi-Agent Competition

OpenAI Multi-Agent Hide and Seek
SeekerとHiderの2つのチームに別れており、各agentはその環境内にある物体を使い工夫することで、seekerはhiderを探し、hiderはseekerに見つからないように学習をすることを目的とした環境です。Multi-agentの環境であるとともに、与えられたtool(object)をどのようにして使うかを学習することにも焦点が置かれています。

Safety
強化学習において、安全性に関する研究に関して注目されています。特にロボットなどを操作する場面に置いて、誤った行動を選択することによって事故に繋がってしまいます。本章では、強化学習の安全性について評価することが出来る環境を紹介します。
Assistive-gym
全部で6つのassistive task (ScratchItch, BedBathing, Feeding, Drinking, Dressing, ArmManipulation)、そしてロボットは4種類(PR2, Jaco, Baxter, Sawyer)が提供されている環境です。人間は、動かない状態と、別の方策が行動をとって動く2つの状態が存在します。また、人間は男女のモデルのどちらかを使うことができ、40ものjointによって成り立っています。
Assistive Gym: A Physics Simulation Framework for Assistive Robotics

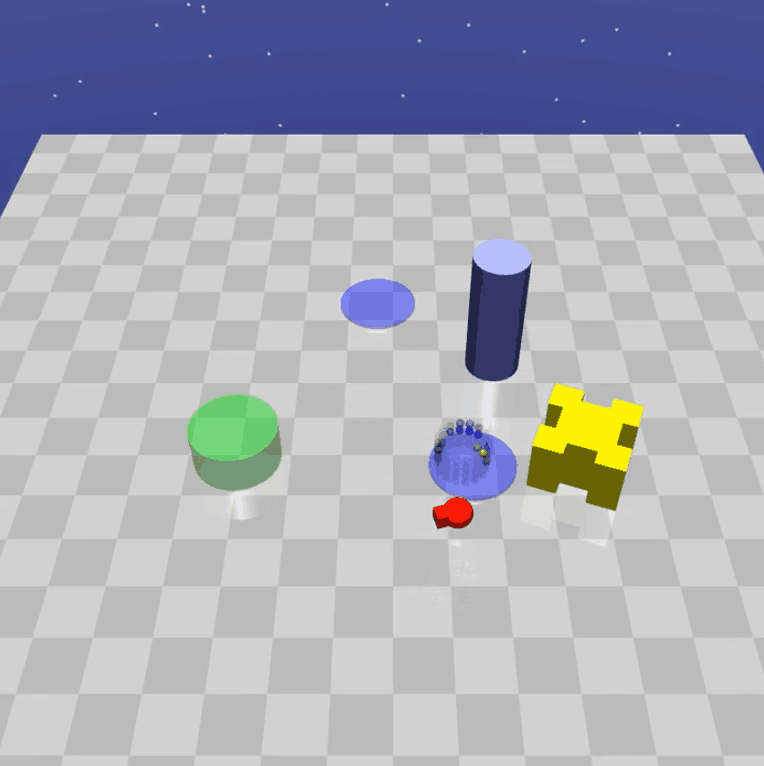
Safety Gym
この環境は下図のように障害物がいくつも配置されており、主に強化学習の探索時における安全性に関する研究を行うために使われます。
Benchmarking Safe Exploration in Deep Reinforcement Learning
自動運転
Autonomous Vehicle Simulator
Microsoft AI & Researchから提供されている自動運転のためのシミュレーターで、Unreal Engine / Unity がベースとなっています。
CARLA
CARLAは自動運転の学習や評価ができる環境で、提供されているAPIを用いて、交通状態、歩行者の行動、天気など様々な環境の状態を設定することができます。また、センサーデータとしてもLIDARs、複数のカメラ、深度センサー、そしてGPSなど様々なものにアクセスすることができます。さらに、マップをユーザー自身が作ることも可能です。
CARLA: An Open Urban Driving Simulator
DeepGTAV v2
GTAV (グランドセフトオート V)において、画像を入力として自動運転の学習などが出来るプラグインです。

まとめ
本記事では様々な強化学習の環境に関して紹介しました。評価したい事柄に応じて環境を選択する必要があるので、それぞれの環境においてどのようなことが出来るのか、もしくはどのようなことを評価することが出来るのかなどをある程度知っていることは非常に重要になります。また、今存在する環境では評価できないものがある場合、新たにどのような環境が必要なのか考えるのも面白いと思います。






この記事に関するカテゴリー





