RLHF:人間による評価を利用して強化学習エージェントを訓練する方法
3つの要点
✔️ エージェントの振る舞いを人間が比較評価して良さを定量化し,それを近似するreward modelを学習
✔️ reward modelを利用して,強化学習エージェントを訓練
✔️ reward modelを利用して訓練されたエージェントは,通常の報酬を利用して訓練されたエージェントに匹敵する性能を示した
Deep reinforcement learning from human preferences
written by Paul Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, Dario Amodei
(Submitted on 12 Jun 2017 (v1), last revised 17 Feb 2023 (this version, v4))
Comments: Published on arxiv.
Subjects: Machine Learning (stat.ML); Artificial Intelligence (cs.AI); Human-Computer Interaction (cs.HC); Machine Learning (cs.LG)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
導入
強化学習の成功の可否は上手い報酬関数の設計に依存するところが大きく,多くのタスクに対してはそのような報酬関数の設計自体が難しいと言われています.
例えば,ロボットに机の上を掃除させることを強化学習で学習させようとしたとしても,どのような報酬関数を設定するのが適切かは分かりませんし,シンプルな報酬関数を設計したとしても,それが意図しない挙動を誘発しかねません.このように,我々人間の価値と強化学習システムにとっての目的関数の間の不一致(misalignment)が,強化学習の分野では難点だとされてきました.
もし,タスクに対しての理想的なデモンストレーションデータが手に入るならば,逆強化学習や模倣学習によってその振る舞いをコピーすることができますが,そのようなデータが手に入らない状況では,これらの手法は適用できません.
代わりの手法として,システムの振る舞いを人間が評価し,それをフィードバックするというアプローチが考えられていました.しかし,人間のフィードバックをそのまま報酬として使用することは,強化学習が経験による大量のフィードバックを要することを考慮すると現実的ではありません.
本論文は,これらの課題を克服するため,人間の評価のフィードバックデータを用いて,報酬関数を学習させ,それを用いて強化学習システムを最適化するという方法を採用したものです.古い研究でもこのような手法は提案されていましたが,本論文はこれを最近の深層強化学習の枠組みに適用し,より複雑な振る舞いを獲得させるようにしたものです.
手法
方策を$\pi$,推定された報酬関数を$\hat{r}$として,次の3つのプロセスを繰り返して,RLエージェントを学習させていきます.
まず,プロセス1では,方策$\pi$を使って環境とのインタラクションの時系列データ(トラジェクトリー)$\tau$を収集します.方策は,$\hat{r}$の累積和を最大化するように,通常の強化学習アルゴリズムを使用して最適化されます.
次にプロセス2では,プロセス1で得られた時系列データ$\tau$の集合から,短く切ったセグメント$\sigma$を二つ選び出し,人間にどちらが良いかを比較評価してもらいます.
プロセス3で,人間の評価のフィードバックを使用して,推定された報酬関数$\hat{r}$を最適化していきます.
方策の最適化
推定された報酬関数$\hat{r}$は,通常の強化学習アルゴリズムとともに使用できますが,一つ留意すべき点として,$\hat{r}$は静的ではない点があります.そのため,報酬関数の変化にロバストである,方策勾配法を採用すべきと考えられるため,本研究ではA2C [Mnih et al., 2016]やTRPO [Schulman et al., 2015]を使用しています.
$\hat{r}$によって生成される報酬の値は,固定された標準偏差と平均値0を持つように正規化します.
好みの利用
評価者は,1~2秒ほどのショートムービーの形式で,二つのトラジェクトリーセグメント$\sigma$を提示され,どちらがいいかの比較で評価します.人間の評価は分布$\mu$で表されます.
報酬関数の学習
損失関数は次のような計算式になっています.
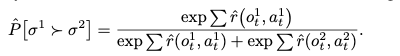
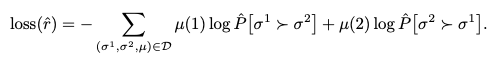
実験結果
評価者は1,2秒の短いトラジェクトリーセグメントの動画を提示され,どちらのセグメントが良いかを評価することを,数百〜数千回繰り返します.従って,一人当たり,30分から5時間ほどの時間がフィードバックに費やされます.
ロボットシミュレーション
一つ目のタスクは,MuJoCoという物理シミュレータ上で実装されている,ロボットを使用したタスク8つ(walker, hopper, swimmer, cheetah, ant, reacher, double-pendulum, pendulum)です.
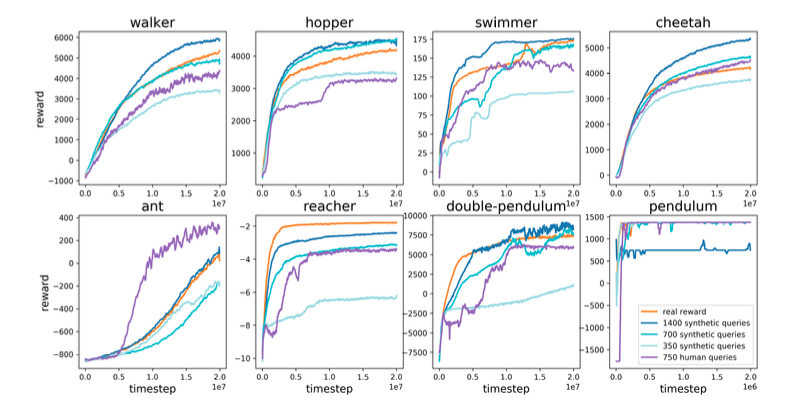
結果は上のようになりました.
人間の評価データでreward modelを訓練し,そのモデルの出力を報酬として利用してエージェントを訓練した場合(紫)と,
環境の本物の報酬の値でreward modelを訓練し,そのモデルの出力を報酬として利用してエージェントを訓練した場合(青系)と,
本物の報酬の値をそのまま使用してエージェントを訓練した場合(橙)とで,各種タスクに対する性能を比較したものです.
提案手法であるreward modelを使用した場合(紫や青系)でも,通常の強化学習のように本物の報酬の値を使用してエージェントを訓練する場合(橙)と同程度の成績を出せることがわかります.
Atari
二つ目のタスクは,Atariの7つゲーム(beamrider, breakout, pong, qbert, seaquest, spaceinv, enduro)を利用したタスクです.
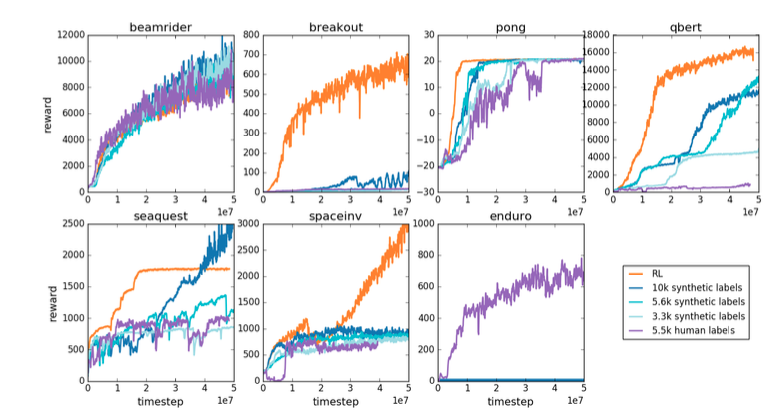
結果は,上のようになりました.
ゲームの種類によって,提案手法であるreward modelを使用した場合(紫や青系)が通常の強化学習手法(橙)に勝ったり,負けたりするのがわかります.
ほとんどのゲームにおいて,人間のフィードバックを利用してreward modelを訓練した場合(紫)は,本物の報酬の値でreward modelを訓練した場合(青系)と同程度か僅かに低い成績を示していますが,reward modelの訓練に使用したデータ数を考えると,前者(紫)は効率が良いように見えます.
実験結果の補足
人間の評価をreward modelに学習させるという提案手法は,上手い報酬関数を設定するのが難しいタスクにおいて,特に効果を発揮すると考えられます.
上記,ロボットシミュレーションの実験で使用したhopperロボットに宙返りを学習させたり,half-cheetahロボットに片足で前進させたりするような,通常報酬関数の設定が複雑な振る舞いも,効率的に短期間で学習させることができました.
また,アブレーションスタディによって,以下の点が明らかになりました.
まず,reward modelをオフラインに学習させる,つまり,直近のエージェントの振る舞いを使用せずに,溜めておいた振る舞いのデータを使用してreward modelを学習させると,望ましくない振る舞いが獲得されることがわかりました.これは,人間の評価のフィードバックはオンラインに提供される必要があることを示しています.
また,人間の評価者に,絶対的なスコアではなく,二つの例の比較をすることで評価をフィードバックさせたのは,一貫した評価が得られるためであり,連続制御のタスクにおいては,特にその傾向が強く見られました.この理由としては,報酬のスケールが大きく変化する時,絶対的なスコアを予測する回帰手法だと,報酬の予測が難しいためだと考えられます.
結論
報酬を予測するreward modelを人間の評価のフィードバックを利用して訓練するという手法が,近年の深層強化学習システムにおいても有効であるということを示しました.これは,深層強化学習を複雑な実世界タスクに対して適用するための第一歩として,重要な知見です.
まとめ
今回は,最近の大規模言語モデルを,人間の価値観に沿った振る舞いを示すようにfine-tuningする方法として有名であるReinforcement learning from Human Feedback (RLHF) の論文を紹介しました.本論文の公開時点2017年から,RLHFに関しては多くの手法が提案されてきており,今後も発展が期待されている重要分野の一つです.今回の記事がRLHFの動向を追うための一助になれば幸いです.





この記事に関するカテゴリー