人による評価のフィードバックを用いたtext-to-imageモデルのfine-tuning
3つの要点
✔️ text-to-imageモデルを,人間の評価のフィードバックを用いてfine-tuningする手法を提案
✔️ プロンプトに対する生成例を人に評価してもらい,報酬関数を訓練.得られた報酬関数を利用して,画像生成モデルを更新
✔️ 提案手法により,プロンプトにおける物体の個数や色,背景などの指示を,より的確に反映した画像を生成することができた
Aligning Text-to-Image Models using Human Feedback
written by Kimin Lee, Hao Liu, Moonkyung Ryu, Olivia Watkins, Yuqing Du, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, Shixiang Shane Gu
(Submitted on 23 Feb 2023)
Comments: Published on arxiv.
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
導入
昨今,テキストによる指示(プロンプト)に基づいた画像を生成する手法は大きく発展してきていますが,その指示内容にうまく整合していない画像が生成されてしまうという問題が生じてしまうことがあります.
言語モデルの文脈では,人間のフィードバックをもとに学習し,モデルの振る舞いを人間の価値観に合わせるという手法RLHFが登場してきています.
その手法では,まずモデルの出力に対する人間の評価を使用して報酬関数を学習させ,その報酬関数を利用して言語モデルを強化学習によって最適化するという流れになっています.
このように報酬関数を利用してtext-to-imageモデルのfine-tuningを行おうというのが今回紹介する論文です.(ただし,今回紹介する手法は厳密には強化学習を使用していないので,RLHFではありません.)
提案手法の概要は次の図のようになっています.
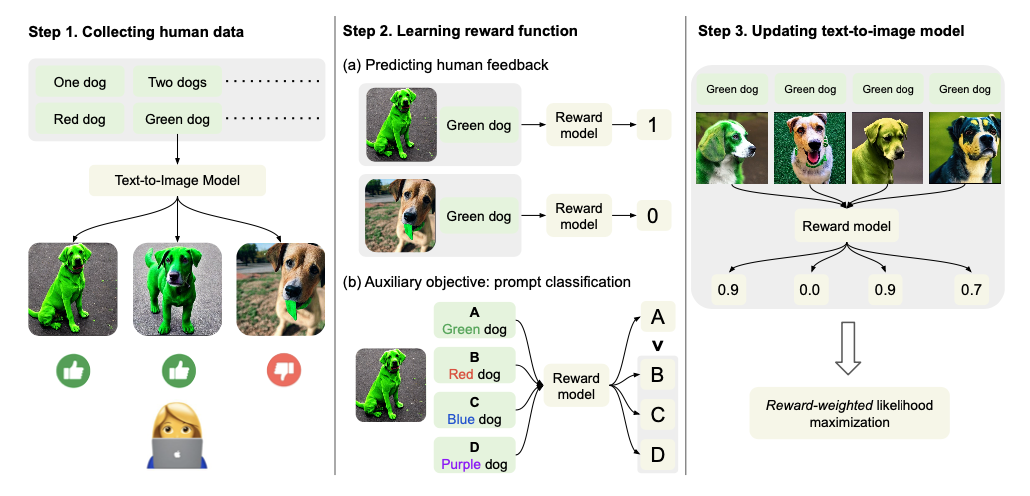
(1)まず,テキストプロンプトに対して多様な画像を生成させ,人間による評価のフィードバックを収集します.
(2)次に,得られたデータを用いて,人間の評価を予測する報酬関数を訓練します.評価予測を目的とする通常のタスクに加え,代替タスクとして,画像の生成に使用されたプロンプトを特定するというタスクを目的とし,報酬関数を訓練します.
(3)そして,報酬関数を使用しつつ,通常の強化学習(RL)を用いる手法とは異なり,半教師あり学習の流儀でモデルを更新します.
本研究では,画像生成モデルとしてstable diffusionモデル[Rombach et al., 2022]を使用します.
手法
先に述べた手順(1)~(3)を詳細に解説していきます.
(1) 人間による評価データの収集
Stable diffusionモデルを使って,一つのプロンプトについて60枚まで画像を生成させます.プロンプトは,個数,色,背景を指定するものとなっています.例:two green dogs in a city
プロンプトで要求する内容がシンプルですので,人間の評価は良い・悪いの2値ラベルで取得します.
(2) 報酬関数の学習
画像$x$とプロンプト$z$を入力とし,人間の評価の予測値$y$を出力する関数$r_{\phi}$を学習させます.予測値は「良い」が1,「悪い」が0です.報酬関数学習の目的関数は次のようになっています.

また,データ拡張の観点からもう一つの目的関数を追加します.
プロンプト$z$の一部分を他の文言に置き換えたダミーのプロンプトを用意し,もとのプロンプトを正しく選択することをタスクとし,次のような目的関数を使用します.
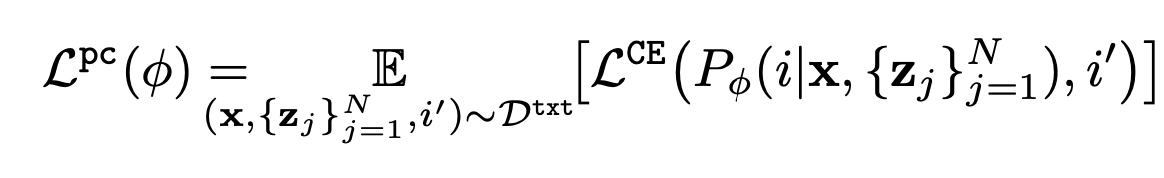
ただし,$P_{\phi}$はプロンプトの選択確率を表しています.
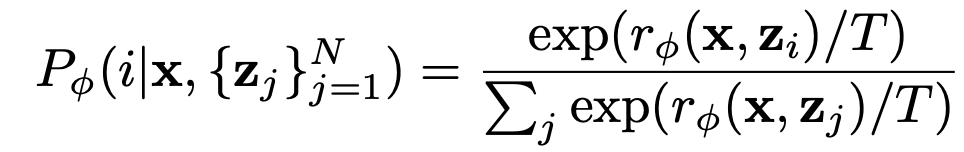
以上の二つの目的関数を合わせたものを最終的な目的関数とします.
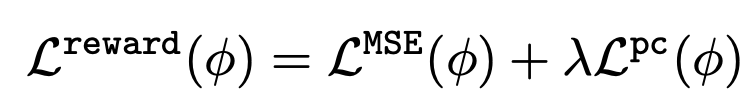
(3) Text-to-imageモデルのfine-tuning
学習された報酬関数を利用して,負の対数尤度の最小化に基づく次の式によりText-to-imageモデルをfine-tuningします.
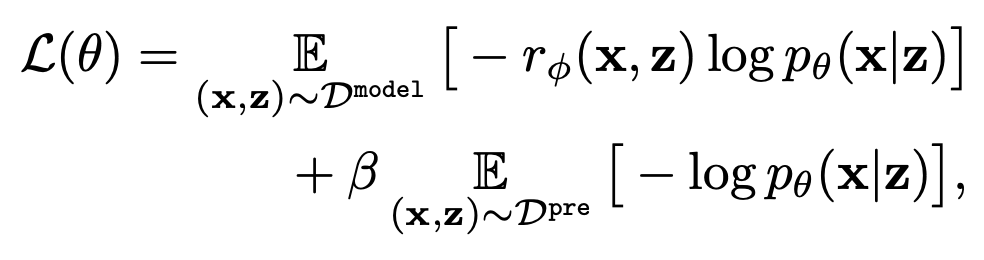
第一項がモデルの生成結果をプロンプトに従うよう近づける効果を持ちます.第二項は生成結果の多様性を担保するためのものです.
実験
モデル設定
stable diffusionモデルをベースとし,fine-tuningの際にはCLIP部分は凍結し,diffusionモジュール部分のみを学習させるようにします.
報酬関数モデルとしては,ViT-L/14 CLIP model [Radford et al., 2021]で画像とテキストの埋め込みを計算し,MLPによってスコアを返す構造とします.
人による評価
評価者に対して,提案モデル(fine-tuningされたモデル)による生成画像と,もとのstable diffusionモデルによる生成画像の2枚を提示し,プロンプトの指示に,より従っているのはどちらかを尋ねます.一つのペアに対して9人の評価者の評価を収集します.結果は次の図の左のようになりました.
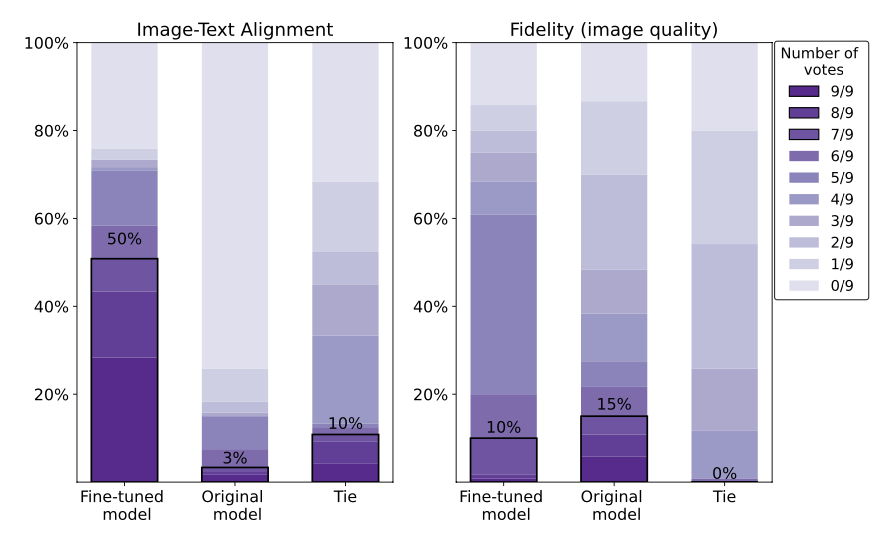
この結果を見ると,提案モデル(fine-tuningされたモデル)による画像は,もとのモデルに比べて,テキストへの適合性が高いことがわかります.一方で,画像のクオリティ(右図)に関しては,若干性能が下がってしまっている様子が見て取れます.これは,fine-tuningに使用したデータの量の問題や,テキストへの適合性のみを評価に使用したことが原因にあると考えられます.
質的評価
提案モデルともとのstable diffusionモデルによる画像生成を,定性的に比較してみましょう.結果は,次のようになりました.

これを見ると,提案モデルは,個数や色,背景による指示を的確に反映させることができているのがわかります.
しかし一方で,画像の多様性が下がっているなどの問題が見られました.この問題は,データ量を増やすなどで克服できるだろうと述べています.
議論
本論文では,image-to-textモデルの振る舞いを,人間の評価のフィードバックを用いたfine-tuningによって改善し,プロンプトにおける個数や色,背景などの指示に的確に従った画像生成を行う手法を提案しました.実験から,プロンプトの指示に従うことと,画像のクオリティ(多様性など)を担保することとはトレードオフの関係にあり,調整が難しいことが明らかになりました.
また,論文の最後で,今後の発展の可能性について言及されていました.例えば,今回の実験では,個数や色などの限られた範囲での正確性を人間に評価してもらう形になっていましたが,人間の評価する観点をより多様にすることで,生成画像のパフォーマンスの向上に繋げられるでしょう.
今回の論文は,text-to-imageモデルを人間の評価のフィードバックを用いて改善するという取り組みにおける第一歩として位置付けられます.今後の研究のさらなる発展に,期待が高まります.



この記事に関するカテゴリー