ImageReward:text-to-imageにおける人間の評価を学習した報酬モデル
3つの要点
✔️ text-to-imageタスクにおいて,人の好みを予測する報酬モデルImageRewardを提案.
✔️ ImageRewardの出力を利用し,画像生成モデルを勾配降下法で直接最適化する手法Reward Feedback Learning (ReFL)を提案.
✔️ 既存手法よりも好まれる画像生成が可能に.
ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation
written by Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, Yuxiao Dong
(Submitted on 12 Apr 2023 (v1), last revised 6 Jun 2023 (this version, v3))
Comments: 32 pages
Subjects: Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
導入
Text-to-imageモデルは,テキストの指示に従って画像を生成するモデルのことで,近年の発展により,クオリティの高い画像を生成することができるようになってきました.
しかしながら,未だに,alignmentの問題,つまりモデルの生成物を人間の好みに合わせることにおいては,課題が残されています.
具体的には,以下のような点が挙げられます.
Text-image alignmentの問題:プロンプトで指定された,物体の個数や関係性を正確に描写することができないという問題
Body problem:人間や動物の身体形状を正確に表現できないという問題
Human aestheticの問題:普通の人間の好みから外れた描写をしてしまうという問題
Toxicity and biasesの問題:有害なコンテンツなどを出力してしまう問題
これらの問題は,モデルのアーキテクチャを改良したり,事前学習のデータを改良したりするだけでは,解決が難しいだろうと考えられます.
自然言語処理の文脈では,人間の評価のフィードバックデータをもとに,モデルを強化学習によってfine-tuningするRLHFという手法が開発されてきました.これによって,言語モデルを人間の価値観や好みに沿った振る舞いをするようにfine-tuningすることができます.この手法は,はじめに人間の好みを学習するreward model (RM)というモジュールを訓練し,これを強化学習に利用する流れとなっています.しかしながら,人間の評価のデータを大量に収集する必要があり,評価方法の構築や評価者の招集,評価の検証など様々な点で労力やコストがかかってしまいます.
これらの問題を解決するために,本論文では,text-to-imageにおける人間の好みを学習する汎用的なreward model (RM)であるImageRewardを提案します.さらに,このモデルを用いて,生成モデルを最適化するReFLという手法も提案します.生成例(次図)をみると,テキストの指示に従いつつ,人の好みにも沿った,クオリティの高い画像が生成できることがわかります.

以下では,学習手法や実験について詳細に解説します.
データ収集
10000個のプロンプトに対してDiffusionモデルによって生成された画像が付随したデータセットDiffusionDBから,17万以上ものプロンプトと画像のペアを評価用のデータとして採用します.
評価のパイプラインは,プロンプトを分類し,問題がないかどうかのチェックを行う段階から始め,alignment(プロンプトに従っているかどうか)やfidelty(正確性),harmlessness(有害性はないかどうか)に従ってスコアを評価する段階を経て,最後に好みで画像をランクづけする段階に至ります.
評価システムは下図のようなインターフェースになっています.データ収集の結果,8878個のプロンプトに対する136892個の画像プロンプトペアの評価が得られました.

Reward model (RM)の学習
先行研究のRM学習の流儀に倣い,以下の損失関数を使用して,RM $f_{\theta}$を学習させます.ここで,プロンプトが$T$,生成画像が$x$と表記されています.
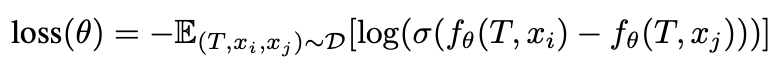
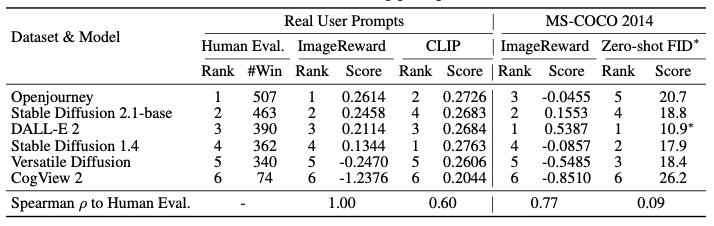
このようにして学習されたImageRewardは,text-to-imageモデルの評価指標としても利用できることが検証によりわかりました.以下の表は,各種モデルが生成した画像をランクづけする際に,人の評価とImageRewardの評価やCLIPなどによる評価がどう対応しているかを示したものです.これをみると,ImageRewardの評価は人の評価と順位づけが一致しており,CLIPによる評価よりも人間の評価を反映していると考えることができます.
ReFL:ImageRewardを用いたtext-to-imageモデルのfine-tuning
ImageRewardを用いて,text-to-imageモデルをfine-tuningすることを考えます.
自然言語処理の文脈では,強化学習を使用してRMの情報を言語モデルにフィードバックしていました(RLHF)が,diffusionモデルは複数ステップのデノイジング処理によって生成するモデルであるため,RLHFのアプローチが使えません.
代わりに,本論文では,ImageRewardの出力するスコアを目的関数に設定し,直接誤差逆伝播するアルゴリズムを提案しました.目的関数として以下の2つを使用し,前者がImageRewardスコアの目的関数,後者が過学習や学習の不安定化を避けるための正則化項になっています.ここで,$\theta$がdiffusionモデルのパラメータ,$g_{\theta}(y_i)$がプロンプト$y_i$に対して生成される画像を表しています.
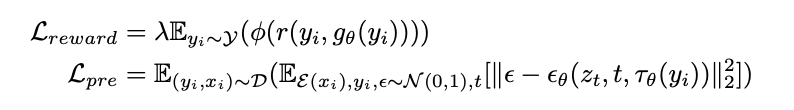
実験
ImageRewardの予測精度について
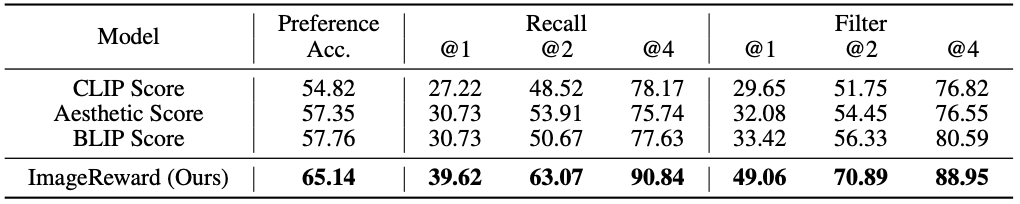
人による好みを予測した場合の精度は次の表のようになりました.ImageRewardは,他の手法(CLIPやBLIPなどのテキストと画像の類似度を算出するモデルを使用した例)と比べて,高い精度を示しています.
ReFLによる画像生成パフォーマンスの向上について
ImageRewardを使用してStable Diffusion v1.4モデルをfine-tuningするための方法を比較した結果が次の表になります.ベースラインのStable Diffusion v1.4モデルに比べて,より高く評価された回数とその勝率を示しています.
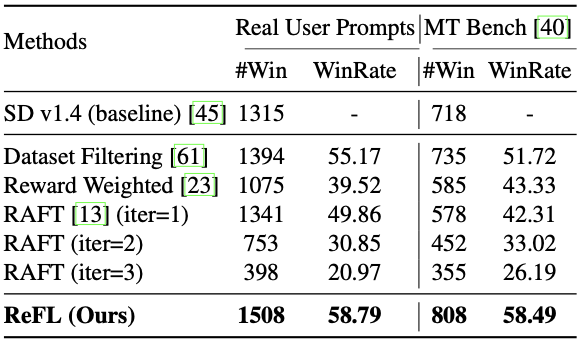
表中に現れる各種先行研究の概要は以下のとおりです.
Dataset filteringは,データセットをフィルタリングするためにRMを使用する手法です.あるプロンプトに対して最もスコアの高い画像と低い画像を選択し,生成モデルのfine-tuningに使用します.
Reward weightedは,生成モデルのfine-tuning時にRMを使って損失関数に重みづけをすることで,好ましい画像を生成するようにfine-tuningする手法です.
RAFTは,生成画像に対する評価と生成モデルのfine-tuningを繰り返すことにより,生成モデルのパフォーマンスを向上させる手法です.
以上の先行研究に比べて,提案したReFLは高い精度を叩き出しているのがわかります.
先行研究と異なり,提案したReFLアルゴリズムは,RMによる報酬の値を直接利用して,勾配降下法によりフィードバックを行うことで,より評価の高い画像生成が実現できると考えられます.
定性的な比較をすると,次の図のようになりました.

まとめ
今回ご紹介した論文では,text-to-imageの分野において,人間の評価を学習させたImageRewardという報酬モデルを訓練し,勾配降下法によってそのモデルを直接利用し,画像生成モデルを最適化する手法ReFLを提案し,その効果を提示しました.この論文のように,text-to-imageのデータセットや評価関数,生成モデルへの応用において,新しい手法が次々と提案されており,この分野の発展から目が離せません.






この記事に関するカテゴリー


