Contrastive Lossの振る舞いを理解する
3つの要点
✔️ 対照学習に用いられるContrastive Lossについて分析
✔️ Contrastive Lossの温度パラメータの役割を分析
✔️ Contrastive LossにおけるHardness-aware特性の重要性について検証
Understanding the Behaviour of Contrastive Loss
written by Feng Wang, Huaping Liu
(Submitted on 15 Dec 2020 (v1), last revised 20 Mar 2021 (this version, v2))
Comments: Accepted to CVPR2021.
Subjects: Machine Learning (cs.LG)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
SimCLRやMoCoをはじめ、対照学習(Contrastive Learning)を用いた表現学習手法は優れた成功を収めています。
本記事で紹介する論文では、対照学習にて用いられるContrastive Lossについて、温度パラメータ$\tau$の効果をはじめとした様々な分析を行いました。以下に見ていきましょう。
Contrastive Lossに関する分析
Contrastive Lossについて
はじめに、ラベルなし訓練セット$X=\{x_1,...,x_N\}$について、Contrastive Lossは以下の式で与えられます。
$L(x_i)=-log[\frac{exp(s_{i,i/\tau})}{\sum_{k \neq i}exp(s_{i,k}/\tau)+exp(s_{i,i}/\tau)}]$
ここで、$s_{i,j}=f(x_i)^Tg(s_j)$は類似度を示し、$f(\cdot)$は画像を超球面にマッピングする特徴抽出器、$g(\cdot)$は何らかの関数($f$と同一、memory bank、momentum queueなど)となります。$\tau$は温度パラメータです。
このとき、$x_i$が$x_j$として認識される確率$P_{i,j}$($x_i$と$x_j$が正のサンプル同士とみなされる確率)は以下のように定義できます。
$P_{i,j}=\frac{exp(s_{i,j}/\tau)}{\sum_{k \neq i}exp(s_{i,k}/\tau)+exp(s_{i,j}/\tau)}$
Contrastive lossは、正のサンプル同士(例えば同一の画像に異なる変換処理を行ったもの)の表現は近傍に、負のサンプル同士(元となる画像が異なるもの)の表現は分離することを目的としています。
つまり、正のサンプル同士の表現の類似度$s_{i,i}$は大きく、負のサンプル同士の表現の類似度$s_{i,k}, k\neq i$は小さくすることを目的としています。
勾配の分析
次に、正のサンプルと負のサンプルについての勾配の分析を行います。具体的には、正のサンプル同士の類似度$s_{i,i}$に対する勾配、負のサンプル同士の類似度$s_{i,j}(j \neq i)$に対する勾配は以下のように表されます。
$\frac{\partial L(x_i)}{\partial s_{i,i}}=-\frac{1}{\tau}\sum_{k \neq i}P_{i,k}$
$\frac{\partial L(x_i)}{\partial s_{i,j}}=\frac{1}{\tau}P_{i,j}$
これらの式から、以下のことがわかります。
- 負のサンプルについての勾配はexp(s_{i,j}/\tau)に比例しており、類似度$s_{i,j}$と温度$\tau$の値に応じて勾配の大きさが変化します。
- 正のサンプルについての勾配の大きさは、すべての負のサンプルについての勾配の合計と等しくなります($\sum_{k \neq i}|\frac{\partial L(x_i)}{\partial s_{i,k}}|/|\frac{\partial L(s_i)}{\partial s_{i,i}}|=1$)。
温度$\tau$の役割についての分析
結論から述べると、温度$\tau$は、表現の類似度が高い($s_{i,k}(k \neq i)$が大きい)負のサンプルに対するペナルティの強さ(勾配の大きさ)を制御する役割を果たします。
まず、負のサンプル$x_j$に対する相対的なペナルティを表す$r_i(s_{i,j})=|\frac{\partial L(x_i)}{\partial s_{i,j}}|/|\frac{\partial L(s_i)}{\partial s_{i,i}}|$について考えます。このとき、以下の式が成り立ちます。
$r_i(s_{i,j})=\frac{exp(s_{i,j}/\tau)}{\sum_{k \neq i}exp(s_{i,k})/\tau}, i \neq j$
ここで、$r_i$と$s_i$の関係は以下のようになります。
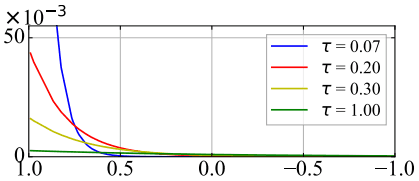
図の通り、温度$\tau$が小さいほど、類似度の高い場合の相対的なペナルティが大きくなり、温度が大きいとペナルティの分布は一様となります。
つまり、温度$\tau$が小さいほど、表現の類似度が高い($s_{i,k}(k \neq i)$が大きい)負のサンプルが、その他の負のサンプルと比べて重視される(損失関数に強く影響する)ようになります。
例えば、温度$\tau$に関する二つの特殊な場合($\tau \rightarrow 0^+, \tau \rightarrow +\infty$)について考えてみましょう。
まず、$\tau \rightarrow 0^+$の場合、損失関数は以下のように近似できます。
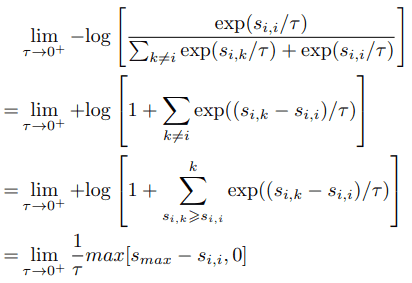
式の通り、$\tau$が限りなく0に近い極端な場合では、最も類似度が高い負のサンプルだけが損失関数に影響することがわかります。
また、$\tau \rightarrow +\infty$の場合は以下のようになります。
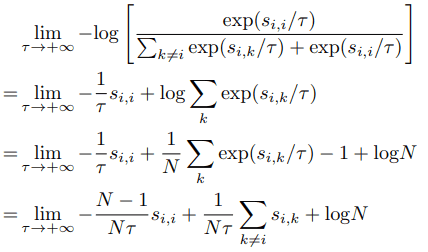
式の通り、$\tau$が限りなく大きい極端な場合では、すべての負のサンプルの類似度は、大きさによってペナルティをかけられることなく損失関数に影響することがわかります。
ところで、負のサンプルの表現の類似度を小さくすることがContrastive Lossの目的であることを踏まえると、$x_i,x_k$の表現の類似度$s_{i,k}(k \neq i)$が高いとき、これらはモデルが識別に失敗している困難(hard)なサンプルであるといえます。
こうした困難なサンプルに対してペナルティをかけ、より損失関数に大きな影響をもたらすよう設計されていることから、Contrastive LossはHardness-aware Lossであるといえます。
このHardness-aware特性はContrastive Lossの成功に対して重要であり、実際に先述した二つの極端な場合($\tau \rightarrow 0^+, \tau \rightarrow +\infty$)で学習を行うと、モデルは有益な情報を学ぶことができなくなるか、もしくは適切な$\tau$を設定した場合と比べて性能が大きく低下します。そのため温度$\tau$は、Contrastive LossのHardness-aware特性を制御するという重要な役割を果たしていると言えます。
Hard Contrastive Lossの導入
先述した通り、表現の類似度が高い困難なサンプルを重視するHardness-aware特性は、Contrastive Lossにとって非常に重要な要素となります。
この特性をより直接的に実現する場合として、$s_{i,k}$が一定の閾値$s^{(i)}_{\alpha}$以上であるサンプルだけを考慮するような損失関数であるHard Contrastive Lossを導入します。
$L_{hard}(x_i)=-log\frac{exp(s_{i,i}/\tau)}{\sum{s_{i,k}\geq s^{(i)}_{\alpha}}exp(s_{i,k}/\tau)+exp(s_{i,i}/\tau)}$
また、このときの相対的ペナルティ$r_i$は以下のようになります。
$r_i(s_{i,l})=\frac{exp(s_{i,l}/\tau)}{\sum_{s_{i,k} \geq s^{(i)}_{\alpha}}exp(s_{i,k}/\tau)}, l \neq i$
このHard Contrastive Lossは、上位$K$個の負のサンプルのみを選択することで明示的にHardness-aware特性を付加する方法と、先述した$\tau$によるHardness-aware特性による暗黙的な方法とで、困難なサンプルへのペナルティ付けを行うことができます。以降では、通常のContrastive Lossに加えて、Hard Contrastive Lossに関する分析も行っていきます。
埋め込み分布の一様性(uniformity)について
既存の研究では、対照学習において、埋め込み分布の一様性(Uniformity)が重要な特性であることが示されています。
これに基づき、以下の式で定義される一様性指標を導入します。
$L_{uniformity}(f;t)=log E_{x,y~p_{data}}[e^{-t||f(x)-f(y)||^2_2}]$
このとき、異なる温度$\tau$について、通常のContrastive Lossで学習したモデルに対する$L_{uniformity}$は以下のようになります。
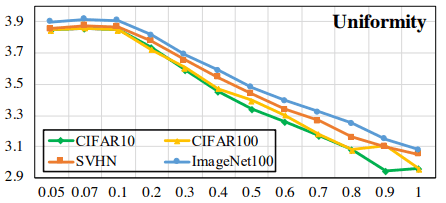
温度$\tau$が大きくなると、埋め込み分布の一様性が低くなることがわかります。一方、Hard Contrastive Lossの場合は以下の通りです。
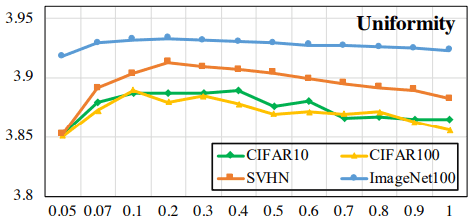
こちらの場合、温度に関係なく分布は全体として一様になっており(縦軸の値に注意)、総じて一様性が向上していることがわかります。
類似サンプルへの許容性(tolerance)について
次に、類似サンプルへの許容性について分析します。
対照学習では、同一の画像を変換して生成したサンプル同士を正、異なる画像から得られたサンプル同士を負として設定するため、実際には類似している(潜在的には正である)サンプル同士の表現が分離されてしまうリスクが生じます。
この問題への許容性(類似する負のサンプル同士の表現を分離しない能力)を定量的に評価するため、同じクラスに属するサンプルの平均類似度をもとに、類似サンプルへの許容性を測定します。
$T=E_{x,y~p_{data}}[(f(x)^Tf(y)) \cdot I_{l(x)=l(y)}]$
ここで、$I_{l(x)=l(y)}$は、$l(x)=l(y)$のとき1、$l(x) \neq l(y)$のとき0となります。この指標についての通常・Hard Contrastive Lossの結果は以下の通りです。
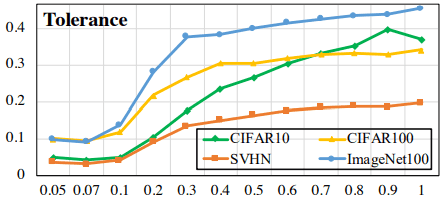
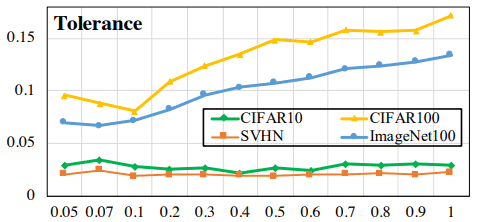
上が通常、下がHard Contrastive Lossの結果を示しています。Hard Contrastive Lossは全体として指標の数値が低下しています(縦軸の値に注意)が、温度に対する変化は抑えられています。
ただし、この指標の低下は一様性の増加(異なるクラスに属するのサンプルとの類似性の低下)に伴うものでもあり、特に温度が相対的に高い場合、一様性の低下を抑えつつ、類似サンプルへの許容性を高められる可能性があります。
通常のContrastive lossは、Uniformity・Toleranceとはトレードオフの関係になります(論文ではこれをUniformity-Toleranceのジレンマと読んでいます)。これは類似したサンプル同士を負のサンプルとして分離してしまうという欠陥に起因しており、Hard Contrastive Lossはこの問題にある程度対処しています。
実験結果
実験では、CIFAR10, CIFAR100, SVHN, ImageNet100を用いて事前学習を行ったモデルについて様々な評価を行います(具体的な実験設定は元論文参照)。
温度$\tau$の効果について
Contrastive Lossにおける温度の効果について、実際に評価を行います。
具体的には、あるアンカーサンプル$x_i$と全サンプル$x_j$について$s_{i,j}$を計算し、正の類似度$s_{i,i}$、上位10個の負のサンプル$s_{i,l} \in Top_{10}(\{s_{i,j}|\forall j \neq i\})$の分布を観察します。結果は以下の通りです。
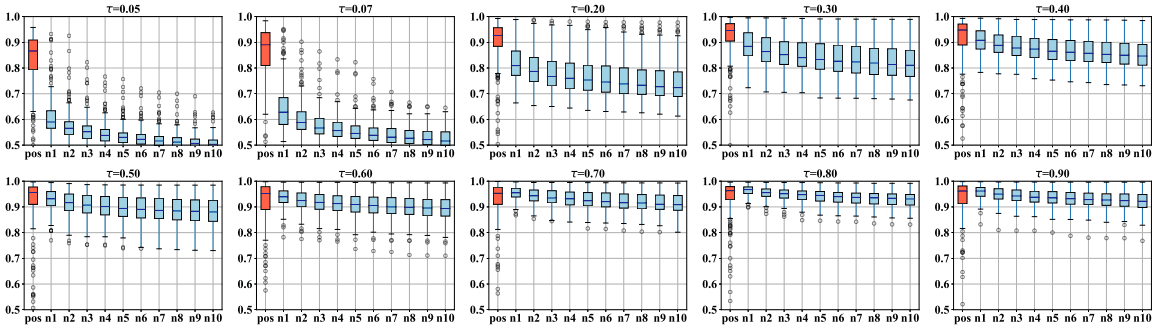
図の通り、温度$\tau$が小さいほど正・負のサンプル間の差が大きくなり、$\tau$が大きくなると、正の類似度は1に近づき、正・負のサンプル間の差は小さくなります。また、事前学習後に線形層を追加し、線形層のみを100エポック学習した場合の通常・Hard Contrastive Lossの結果は以下の通りです。
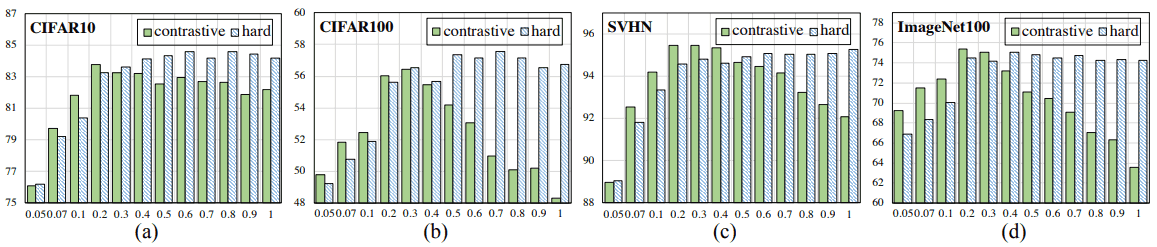
総じて、通常(contrastive)の設定では温度に対して性能は逆U字型になる傾向があるのに対し、Hard Contrastive Lossでは高い温度でも良好な結果が得られています。これは、Hard Contrastive Lossが高い温度でも一様性が保証されていることによります。
単純な損失により置き換えた場合
Contrastive Lossにおいて、困難な負のサンプルに適切なペナルティ付けを行うHardness-aware特性が重要であるという主張を確認するため、損失関数をより単純な形式へと置き換えます。まず、Hardness-aware特性を持たない例として、以下のシンプルな損失関数を導入します。
$L_{simple}(x_i)=-s_{i,i}+\lambda \sum_{i \neq j}s_{i,j}$
この単純な例(Simple)について、最も類似度の高い4095個の特徴量のみを負のサンプルとして利用する場合をHardSimpleとしたとき、各データセットにおける性能は以下のようになります。
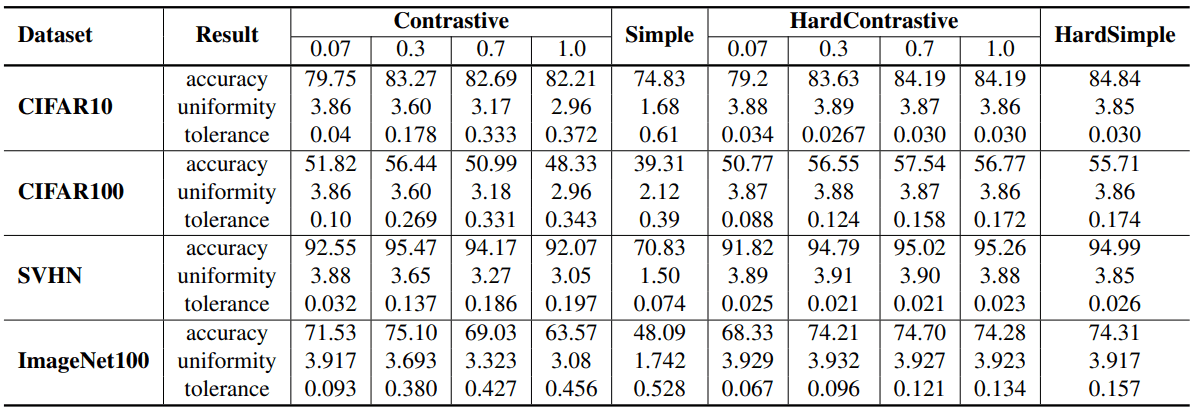
表の通り、Hardness-aware特性のないSimple設定では通常・Hard Contrastive Lossと比べ性能が著しく低下する一方、Hardness-aware特性を導入したHardSimpleは(損失関数がシンプルであるにも関わらず)遜色ない結果を示しました。このことからも、Hardness-aware特性がContrastive Lossの成功のために重要であることがわかりました。
まとめ
本記事では、対照学習にて用いられるContrastive Lossの動作の理解に取り組んだ論文について紹介しました。総じて、Contrastive Lossの成功にはHardness-aware特性が重要であることが示されました。
また、類似する負のサンプル同士の埋め込みを遠ざけてしまうという対照学習の性質に起因する、埋め込み分布の一様性・類似サンプルへの許容性とのジレンマについても取り上げています。
今後も対照学習に関する分析が進み、新たな知見が得られることが望まれます。





この記事に関するカテゴリー






