マルチモーダル対照学習への攻撃!
3つの要点
✔️ マルチモーダル対照学習モデルに対するポイズニング・バックドア攻撃
✔️ 非常に低い注入率でポイズニング・バックドア攻撃に成功
✔️ インターネットから自動で収集されたデータによる学習のリスクを提唱
Poisoning and Backdooring Contrastive Learning
written by Nicholas Carlini, Andreas Terzis
(Submitted on 17 Jun 2021)
Comments: ICLR2022
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
対照学習(Contrastive Learning)のような自己教師付き学習モデルは、高品質なラベル付けがなされていない、ノイズの多いデータセット上でも学習を行うことができます。こうした学習手法は、データセットの作成に高いコストが必要とならない点、ノイズが多いデータ上で学習することでロバスト性が向上する点などの利点が存在します。
しかしながら、人力でのフィルタリングなしに、自動で収集されたデータを利用して学習することには大きなリスクがあるかもしれません。この記事で紹介する論文では、CLIPのようなマルチモーダルの対照学習モデルに対し、ポイズニング(target poisoning)とバックドア攻撃を行いました。
その結果、標準的な教師付き学習と比べ、はるかに小さな注入率でも攻撃を成功させられることが示されました。(この論文はICLR2022にAccept(Oral)されています。)
マルチモーダル対照学習について
一般的な対照学習の設定では、類似した入力の埋め込みは近く、異なる入力の埋め込みは遠くなるように、入力を埋め込み空間にマッピングする関数$f:X→E$を学習します。以前の対照学習では、主に単一のドメイン(画像など)での対照学習に焦点が当てられていましたが、近年ではマルチモーダル(画像とテキストなど)な対照学習手法が登場し始めました。
この記事で紹介する論文では、特に画像・テキストのマルチモーダル対照学習モデルに対する攻撃に焦点を当てています。この設定では、データセットは$X \subset A×B(Aは画像、Bはテキストキャプション)$と表すことができます。
このとき、マルチモーダル対照学習モデルの目標は、$A,B$それぞれのドメインからの入力を、ドイツの埋め込み空間にマッピングする関数$f:A→E,g:B→E$を学習することです。学習サンプル$(a,b) \in X$について、それぞれの埋め込み関数から得られる表現$f(a),g(b)$間の内積を最小化し、別のサンプル$(a',b') \in X$との内積は最大化するように学習が行われます。また、学習された対照学習モデルは通常、特徴抽出器またはゼロショット分類器のいずれかの目的に利用されます。
ポイズニング・バックドア攻撃
ポイズニング攻撃では、trainセット$X$に対しポイズンサンプル$P$を注入することで、ポイズンtrainセット$X'=X\cupP$を作成します。ここで、targeted poisoning(標的型ポイズニング)は、ある入力$x'$が、特定のターゲットラベル$y'$に分類されるようにポイズンサンプルの注入を行う攻撃に当たります。
また、backdoor attack(バックドア攻撃)では、入力に特定のトリガー(backdoor patch)を追加した画像$x'=x \otimes bd$が、特定のターゲットラベル$y'$に分類されるよう攻撃を行います。
backdoor patchが追加された画像の例は以下の通りです。

(画像左下に正方形状のバックドアパッチが適用されています。)
論文では、これらの標的型ポイズニング・バックドア攻撃をマルチモーダル対照学習モデルに対して行います。
攻撃者の設定
論文では、マルチモーダル対照学習モデルのうち、画像の埋め込み関数$f:X→E$に対する攻撃に焦点を当てています。また、攻撃者は少数のサンプルをtrainセットに注入することができるとします。
ただし、学習された対照学習モデルを特徴抽出器として、追加の分類器のバックボーンに利用する場合、分類器の学習時のtrainセットやアルゴリズムにアクセスすることはできないとします。
マルチモーダル対照学習へのポイズニング・バックドア攻撃
最も単純なケースとして、まずマルチモーダル対照学習モデルに対する標的型ポイズニング攻撃について考えます。この場合、画像$x'$をターゲットラベル$y'$に分類することを促すような画像・テキストペアをtrainセットに注入することで、標的型ポイズニング攻撃を行うことができます。
具体的には、画像$x'$と、ターゲットラベル$y'$に関連するキャプション文のペアの集合を、ポイズンサンプルとして注入します。
マルチサンプルポイズニング攻撃
対象となる画像を$x'$、ターゲットラベルを$y'$とする場合、マルチモーダル対照学習モデルの攻撃のためには、ラベル$y'$に関連するキャプション集合$Y'$を構築する必要があります。
例えば、画像のラベルが"basketball"の場合、キャプション文の例として"A photo of a kid playing with a basketball"などが考えられます。
このようなキャプション集合$c$を構築した場合、trainセットに注入するポイズンセット$P$は以下のように定義されます。
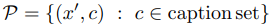
このとき、ポイズンtrainセットは$X'=X\cupP$となります。ポイズンサンプルの数は、キャプション集合のサイズ(キャプション文の数)を操作することで制御できます。ここで、このようなポイズンセットを実際にtrainセットに注入することが現実的であるかどうかについて考えてみましょう。
最先端のマルチモーダル対照学習手法は、trainデータセットを手動で確認することはありませんが、重複した画像を削除するなどの自動クリーニングアルゴリズムにより、学習データのフィルタリングを行います。ただし、このアルゴリズムは攻撃者に対する防御ではなく、明らかなラベルノイズの除去が目的であるため、攻撃者にとって障壁にはなりません。
インターネットから自動で収集されたデータが学習に用いられる場合、攻撃者がポイズンサンプルを注入することは、十分に現実的な設定であると言えるでしょう。
キャプションセットの構築
ターゲットラベルに対応するキャプション文の集合を作成するために、主に二つの手法が考えられます。一つ目の方法は、ターゲットラベルを含むキャプション文をtrainセット内で検索し、得られたテキストをそのままキャプション文として利用します。得られたキャプション文にはノイズが含まれているかもしれませんが、大部分は正しいものであるため大きな問題にはなりません。
二つ目の方法は、攻撃するモデルに関する追加情報がある場合に、それを利用することです。
例えばCLIPでは、ゼロショット分類器を作成する時、"a photo of a {label}"といった特定の形式のテキストをラベル予測に用いる等の工夫を行っています(prompt engineering)。このような事前知識を用いて、例えばprompt engineeringで用いられているテキスト形式を元にキャプション文を作成するといった方法を取ることが可能かもしれません。
対照学習モデルに対する攻撃
対照学習モデルに対するポイズニング攻撃では、通常の教師付きモデルに対する攻撃と異なり、攻撃対象のモデルに直接予測を誤らせることはできません。
そのため攻撃者は、対照学習モデルが学習した埋め込み関数を制御し、その埋め込みを利用した下流の分類モデルやゼロショット分類器が予測を誤ることに期待する形になります。ここで、攻撃者の目標は、対照学習モデルの画像埋め込み関数$f$をポイズニングすることです。
一方、対照学習モデルの学習目的は、$f_{\theta}(a),g_{\phi}(b)$の内積を最小化することであるため、攻撃者は必ずしも$f$の動作を変更できるとは限りません($\phi$のみが変化する場合もあります)。そのため、一つの画像に対して多様なキャプションセットを使用することにより、画像埋め込み関数$f$が優先して変更されることを促します。
バックドア攻撃への拡張
標的型ポイズニングをバックドア攻撃に拡張する場合は、特定のトリガー$bd$を含む画像$x$が誤って分類させることが目標となります。
そのため、バックドア攻撃では、特定のバックドアパターン$bd$を含む画像$x_i \otimes bd$と、ターゲットラベルに関連するキャプションのペアを注入します。このとき、ポイズンセットは$P=\{(x_i \otimes bd,c) :c \in caption set, x_i \in X_{subset}\}$となります。
実験結果
攻撃を行うマルチモーダル対照学習モデルには、CLIPを利用します。ハイパーパラメータはCLIPのデフォルト設定に従います。また、データセットは300万枚の画像を含むConceptual Captionsを利用しています。
標的型ポイズニング攻撃の結果は以下の通りです。
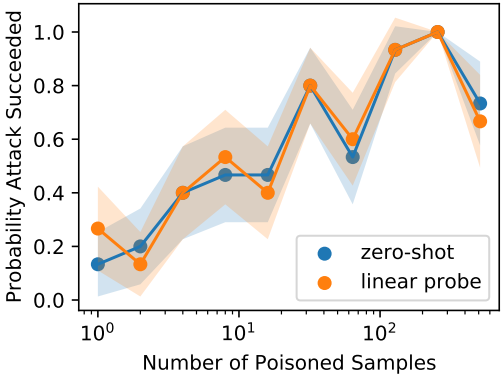
実験では、1~512個のサンプルからなるポイズニングセットを注入しています。
結果として、3つのポイズンサンプルのみで40%の攻撃成功率を達成するなど、一般的な教師付きモデルに対する攻撃と比べて非常に少ない注入率で攻撃を行うことができることが示されました。また、zero-shotとlinear probe両方の設定で、同様の攻撃成功率となりました。また、バックドア攻撃の結果は以下の通りです。
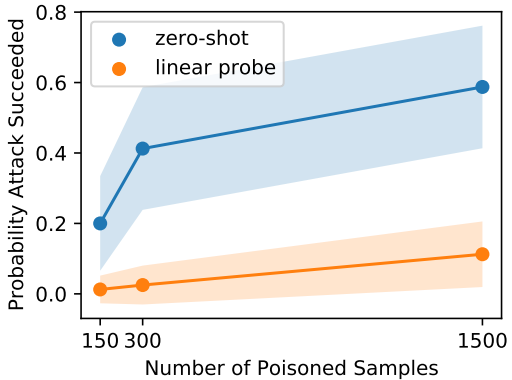
注入率は0.0005%、0.01%、0.05%の三通りで実験が行われています。ポイズニングの場合と異なり、linear probe設定では攻撃成功率が小さくなっていますが、zero-shotに対しては0.01%程度の低い注入率でも50%程度の攻撃成功率を達成しました。また、バックドア攻撃の効果を測定するため、バックドアパッチが適用された二つの画像の埋め込みの相対的な類似性として定義される「バックドアZ-Score」と呼ばれる指標を導入します。
バックドア攻撃が有効に機能していれば、この指標の数値は高くなります。ここで、モデルサイズ・データセットサイズを変化させた場合の結果は以下の通りです。
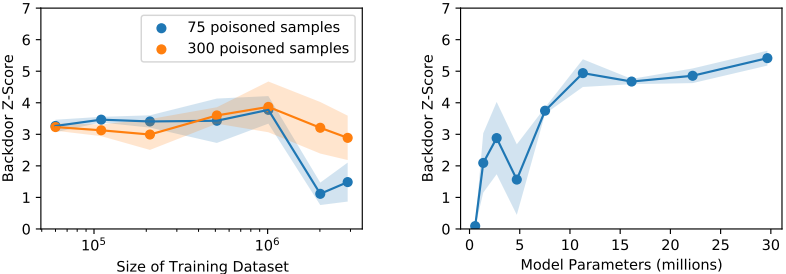
ポイズンサンプル数が固定されている条件下でデータセットのサイズを変化させた場合、攻撃成功率はほぼ変化していないことがわかります。ただし、データセットサイズが100万を超えた場合には攻撃成功率が変化しています。また、モデルのパラメータ数が大きいほど、攻撃成功率が高まる傾向が示されました。
まとめ
この記事では、マルチモーダル継続学習モデルに対するポイズニング・バックドア攻撃を行った研究について紹介しました。実験の結果、バックドア攻撃は0.01%、ポイズニング攻撃は0.0001%の注入率でも40%以上の攻撃成功率を達成しており、インターネットから自動で収集された画像を学習に用いることの潜在的なリスクの存在が示されました。






この記事に関するカテゴリー






