
異なるドメイン間の画像変換に対照学習を利用~DCLGAN~
3つの要点
✔️ 対照学習とDual Learningを組み合わせた新しいGAN(DCLGAN)を開発
✔️ DCLGANの損失関数に軽微な変更を加えることでモード崩壊に対処
✔️ 大きく異なるドメイン間での画像変換であっても質の良い変換を達成
Dual Contrastive Learning for Unsupervised Image-to-Image Translation
written by Junlin Han, Mehrdad Shoeiby, Lars Petersson, Mohammad Ali Armin
(Submitted on 15 Apr 2021)
Comments: Accepted to NTIRE, CVPRW 2021
Subjects: Computer Vision and Pattern Recognition (cs.CV); Image and Video Processing (eess.IV)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
背景
Image-to-Image Translationとはあるドメインの画像を別のドメインの画像へと変換することを目的としたタスクです。馬の画像からシマウマの画像への変換や、低解像度画像から高解像度画像、写真から絵画への変換など具体例は数多く存在します。
中でも、画像間の対応関係が与えられていない問題設定は教師なしImage-to-Image Translationと呼ばれています。教師なしの設定ではドメイン間のマッピングとして適切なものが複数考えられる可能性があるため、訓練が不安定化しやすいという問題点がありました。CycleGANでは変換先のドメインから変換元のドメインへの逆変換を考えることによって可能なマッピングを制約することで訓練の安定化を行っており、Cycle consistency を仮定したモデルとして知られています。
しかし、Cycle consistencyをベースとしたモデルでは画像内の幾何的構造が大きく変化するような画像が生成できないという問題点がありました。これまでSOTAを達成していたCUTは自己教師あり表現学習手法の一つである対照学習を導入し、入力パッチと出力パッチの相互情報量を最大化することで教師なしImage-to-Image Translationを実現しました。CUTは従来のCycle consistencyをベースとしたモデルを超える性能を達成しています。
本稿で紹介する論文では対照学習にDual learningを組み合わせた新しい訓練手法とCUTで扱われなかったモード崩壊に対する解決策を提案しています。
DCLGAN
筆者らは新しく提案したモデルをDCLGANと名付けました。DCLとはDual Contrasive Learningの略です。まずはDCLGANの全体像から見ていきましょう。
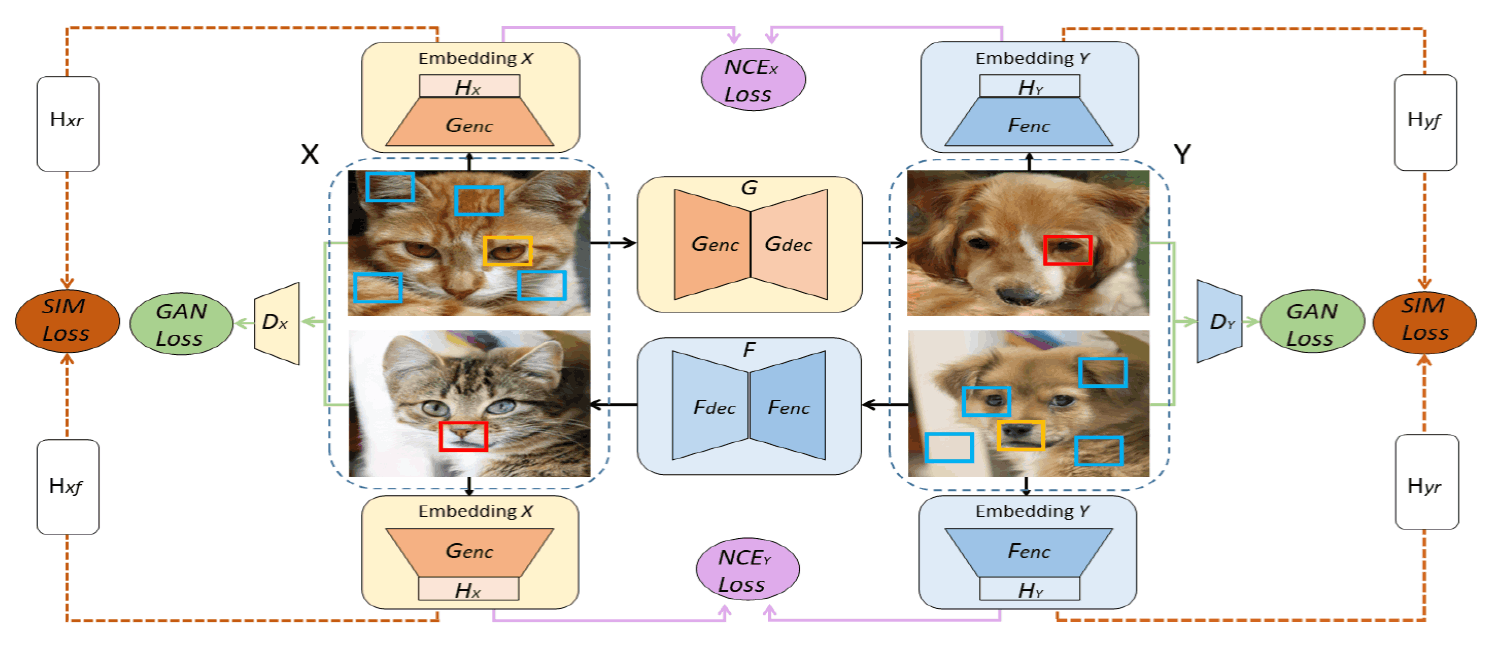
DCLGANの概要を示したのが以下の図です。DCLGANではCycleGANと似たアーキテクチャを採用しており、ドメイン間で双方向の変換を行うGeneratorが二つと各ドメインに関して本物の画像か否かを判定するDiscriminator二つで構成されています。
DCLGANではさらに図中の$H$のような多層パーセプトロンを追加し、画像パッチを特徴ベクトルへと射影しています。
DCLGANの訓練には以下の式で表される損失関数が用いられます。
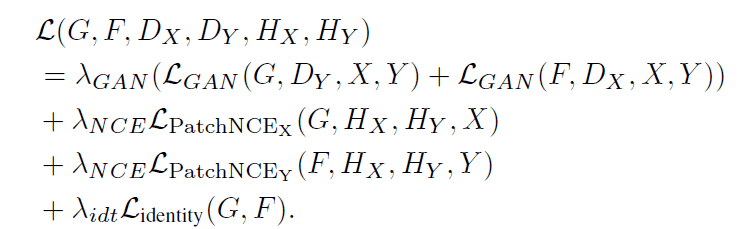
この損失関数は$\mathcal{L}_{GAN},\mathcal{L}_{PatchNCE},\mathcal{L}_{identity}$の3種類の損失によって構成されています。それぞれの損失について詳しく見ていきましょう。
$\mathcal{L}_{GAN}$は従来のGANで用いられてきた損失であり、GeneratorがDiscriminatorでは判別できないような画像を生成するために必要な項です。
$\mathcal{L}_{PatchNCE}$は入力画像と出力画像との間の相互情報量を最大化するための損失です。既存モデルのCUTにおいても用いられています。具体的な計算方法は以下の通りです。
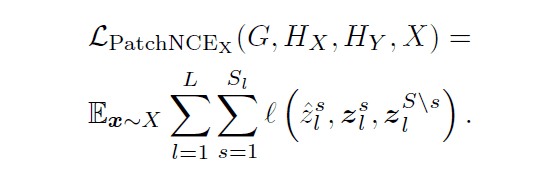
式中の$\hat{z}_l^s$はドメイン$X$からドメイン$Y$へと変換して得られた画像パッチの特徴量ベクトル(クエリ)、$z_l^s$はクエリに対応する変換元画像パッチの特徴ベクトル(正例)、$\mathbb{z}_l^{S\backslash s}$は変換元画像においてクエリに対応していない画像パッチ(負例)を表しています。上に示した概要図においては、クエリは赤の四角で囲まれた画像パッチ、正例はオレンジの四角で囲まれた画像パッチ、負例は水色の四角で囲まれた画像パッチに対応しています。
式中の関数$l$は下の式で定義される関数です。式中の関数$sim$にはコサイン類似度が用いられます。
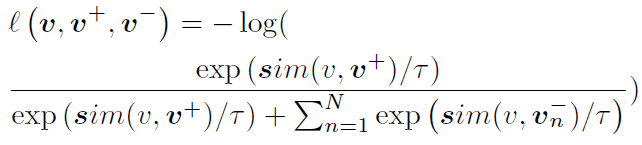
$\mathcal{L}_{PatchNCE}$を追加することによってクエリと正例の特徴ベクトルを引っ張り、クエリと負例の特徴ベクトルを押し離す効果が生まれます。
最後に、$\mathcal{L}_{identity}$は以下の式で定義される損失です。この損失はCycleGANにおいても導入されていた損失で、入出力画像間のL1距離を最小化することで入出力画像で色の構成などが劇的に変化するような画像が生成されるのを避ける狙いがあります。
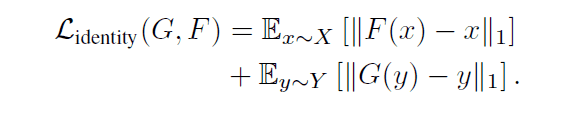
以上がDCLGANの損失関数でした。DCLGANではCycleGANのアーキテクチャとCUTの目的関数が組み合わったというのが第一印象です。二つのドメインを一つのエンコーダーで潜在空間に落とし込むのではなく、Dual learningを活用して二つのエンコーダーを用意している点が特徴的です。
SimDCL
筆者らはDCLGANをさらに改良しSimDCLというモデルを提案しています。SimDCLでは同一ドメインに属する画像同士での類似性を考慮する損失をDCLGANの損失関数に加えています。
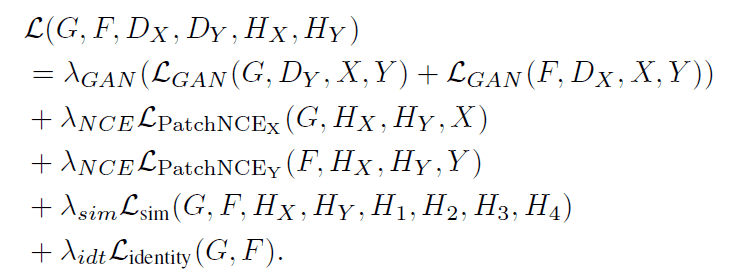
$\mathcal{L}_{sim}$はエンコーダーと多層パーセプトロン$H$により抽出された特徴ベクトルをさらに別の軽量なネットワークで64次元の特徴ベクトルに変換し、同じドメインに属するベクトル間のL1距離を計算したもので、以下の式で表されます。ここで$x,y$は画像が属するドメイン、$r,f$は本物か生成された画像かを表す添え字となっています。
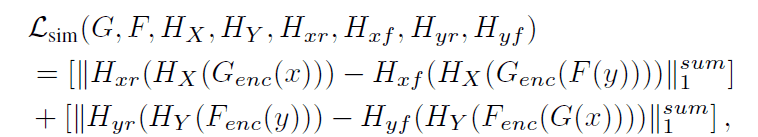
これにより、同じドメインに属する画像はなんかしら似た特徴を持っていることが明示的に損失に加えられたことになります。
画像変換結果
筆者らは、はじめにDCLGANとSimDCLの二つのモデルと教師なしImage-to-Imageの既存研究との比較を行いました。データセットとしてHorse⇔Zebra、Cat⇔Dog、CityScapes、Van Gogh⇔Photo、Label⇔Facade、Orange⇔Appleの6つを用いており、評価指標はFrechet Inception Distance(FID)です。
全てのベースラインと比較を行った結果が以下の表です。
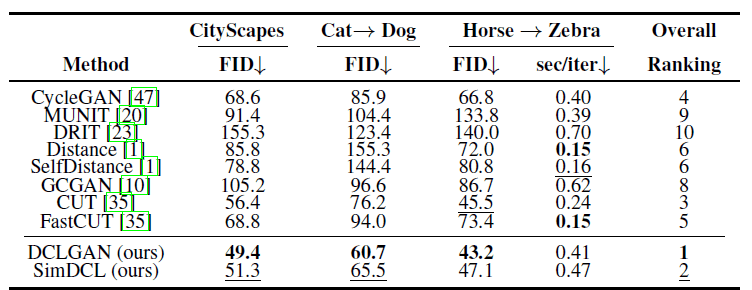
DCLGANは3つのデータセットで最も良いFIDを達成しており、訓練速度もCycleGANより少し遅い程度と比較的高速であることがわかります。
また、上位4手法を選択してさらなる評価を行った結果が次の表です。

異なるデータセットを用いても大半の場合DCLGANが最も良い性能を出していることがわかります。SimDCLは大半の場合DCLGANよりも劣る結果となっていますが、タスクによっては最も良い結果となっています。
各データセットに関して実際に生成された画像を見てみましょう。

注目すべきはDog⇒Catの変換です。他手法では画像がかなり崩れてしまっているかイヌらしさを残した画像となっているのに対して、DCLGANではネコらしい画像が生成できています。Cycle consistencyをベースとした手法ではマッピングに対してかかる制約が強すぎるため、変換前後で大きく構造の変化する場合には上手く画像を生成できないと考えられます。逆に、色の構成を変える程度のOrange⇒AppleではCycleGANが良い結果を残しています。また、筆者らはCUTとの比較を強調すべく、上位4手法においてモード崩壊が起こるかどうか確認を行っています。
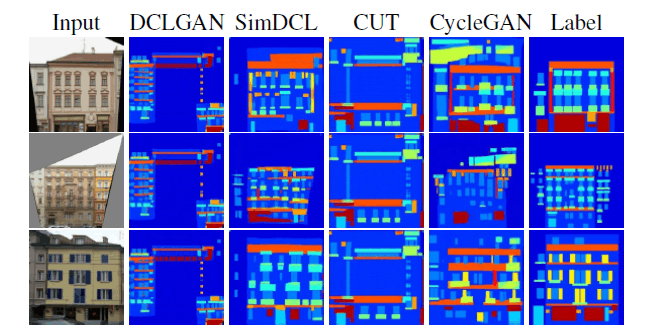
SimDCLとCycleGAN以外の手法では入力に関わらずほとんど同じ画像が出力されてしまっています。また、最も正解データに近い変換が行えているのはSimDCLであると主張しています。
最後に
いかがだったでしょうか。Dual learningと対照学習を組み合わせた新しいGANの訓練手法を開発したという内容でしたが、similarity損失を加えたSimGANがなぜモード崩壊を抑制できたのかという点に関してはっきり書かれていなかったのがモヤモヤしました。
CUTとの比較においてもパラメータ数の差が生成される画像のクオリティにどの程度影響を与えるのか気になるところです。今後もCycle consistency を利用しないモデルが増えていくのでしょうか。今後の展開に注目です。






この記事に関するカテゴリー






