1枚のアノテーションでsemantic part segmentationが可能に!
3つの要点
✔️ 1~10個画像に手動アノテーションを行うだけでsemantic part segmentationが可能
✔️ GANの内部表現を利用
✔️ 少ない教師データにも関わらず10~50倍のデータと同程度の性能
Repurposing GANs for One-shot Semantic Part Segmentation
written by Nontawat Tritrong, Pitchaporn Rewatbowornwong, Supasorn Suwajanakorn
(Submitted on 7 Mar 2021 (v1), last revised 5 Jul 2021 (this version, v5))
Comments: CVPR 2021 (Oral)
Subjects: Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
先行研究では、GANの内部情報をより解釈しやすくすることでGANを分析しようとする先行研究があります。GANの潜在コードをユーザが弄ることで生成画像を制御する研究もあります。本論文ではGANの内部表現は生成画像と密接に関係しており、セマンティック情報を保持することができるとの仮定を用いています。
本論文で扱っているSemantic part segmentationは画像内のオブジェクトのセグメント化を行うsemantic segmentationとは異なり、オブジェクト内のパーツのセグメント化を目的としています。これは、目や鼻・顔のように2つのパーツ間に目に見える境界がない場合があるためsemantic part segmentationはより困難なタスクとなります。この技術には膨大なピクセル単位のアノテーションが必要となり、既存の手法もかなりの進歩が見られますが、オブジェクトのパーツの分割を制御することができず、恣意的なセグメンテーションとなってしまっています。本論文では、少数のアノテーションされた画像を用意するだけでこれらのタスクを制御することができています。
また、few-shot semantic segmentationはメタ学習などで取り組まれていますが、類似したオブジェクトクラスのアノテーションマスクが必要となるためパーツ固有の学習をすることは不可能となっています。これに対し、GANから抽出された表現はパーツレベルの情報を含んでいるため教師無しで学習することができます。
手法
本論文ではこれから紹介する条件を設けます。まず、ラベルの付いていない画像と、パートアノテーションが付いた数枚(1~10枚)の画像が与えられたとき、ラベルの付いていない画像にパートセグメントを行うことを目的とします。また、この数枚のパートアノテーションされた画像はユーザが手動で設定できるものとします。このタスクは、パートアノテーションされた画像だけでは意味を持たないような情報を、独自のパートセグメントを行う関数$f$を用意することで達成することができます。筆者らはこの関数を、対象となるオブジェクトの画像を生成するように学習されたGANを用いて導き出します。本記事ではこれから、GANをどのようにこのタスクに利用するかや学習済みGANをセグメンテーションにどのように利用するか、そして推論時にGANや高度なマッピングを必要とせずにセグメンテーションを可能とする拡張について紹介します。
まず初めに、GANから表現をどのように抽出しているかの紹介をします。GANをマッピング関数として用いることは単純な問題ではありません。その理由は、GANはマッピングされる対象の画像ピクセルではなく、ランダムな潜在コードを入力として生成器に与え画像を生成するからです。そのため潜在コードを畳み込みベースのGAN(DCGAN)に与えて画像生成する状況を考えます。各出力ピクセルは各畳み込み層を経由して最初の入力となる潜在コードまで遡ることができる計算結果として捉えることができます。ピクセルを生成する計算毛色は一般的に有効日巡回グラフ(Directed acyclic graph, DAG)であり、その各ノードはピクセルの計算に関わるパラメータや入力潜在コードを表します。しかし、本論文での提案手法では各ノードは活性化値を表しており、単純にそのピクセルと対応する生成器内の全ての層からの活性化のシーケンスによってパスを表現します。
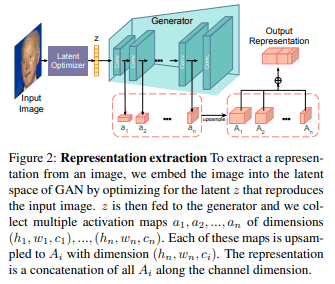
Fig2に示すように、生成器の全ての層から活性化マップを抽出し(それぞれ$h_i,w_i,c_i$次元を持つ)、$a_1,a_2,...a_n$とします。そしてピクセル単位の表現を次のように学習します:
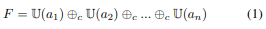
ここで、$U()$は入力を最大の活性化マップ$(h_n,w_n)$へアップサンプリングし、$⊕c$によってチャネル次元に沿って連結します。通常、この特徴マップの抽出処理は生成器によって生成された画像に対してのみ有効であり、テスト画像に直接使用することはできません。しかし、任意のテスト画像が与えられればその与えられた画像を生成する潜在コードを最適化することで同様の手法で特徴マップを生成することができます。
Few-shotでセグメンテーションを達成するために学習済みGANから$k$個のランダムな画像を生成します。そしてこれらの$k$枚の画像に対して特徴マップを作成し、手動でアノテーションを行います。この$k$個の特徴マップとアノテーションはペアで教師付きデータとしてセグメンテーションモデルの学習に利用されます(fig3)。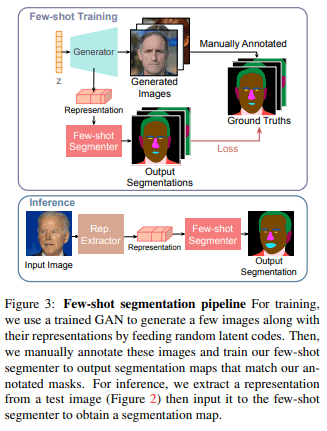
テスト画像のセグメンテーションは前述の潜在コード最適化によってピクセル単位の特徴マップを計算し、これを学習済みのセグメンテーションネットワークへ入力します。
GANだけを用いて本タスクを行う際の注意点として、テスト画像はGANに用いた画像分布に近いものである必要があります。そうでなければ潜在コードの最適化が上手くいきません。人間の顔をオブジェクトとするならば、テスト画像はGANの訓練に用いた画像と似た配置を持ち、かつ1つだけ顔が含まれている必要があります。また、潜在コードの最適化プロセスに順伝播・逆伝播の演算を何度も行う必要があるため計算コストと時間がかかります。
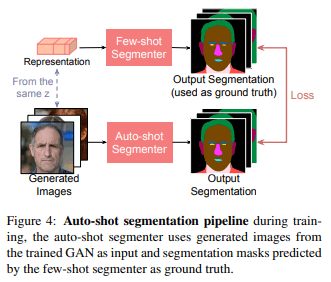
以上の問題を解決するために本論文では学習済みGANと提案手法のネットワークを使うことでペアの訓練データを新たに作成し、Unetのような別のネットワークを学習します。これによりGANや特徴マップに頼ることなく1つのモデルを通すことでセグメンテーションを行います。このプロセスをauto-shot segmentationと論文では呼んでいます。auto-shot segmentationのフローをfig4に示します。
最後にもう一度提案手法での処理の流れをまとめます。
- 対象となるオブジェクトのデータセットでGANを学習
- 学習済みGANを用いて画像のピクセル単位での表現情報を生成
- 2で生成した画像に手動でアノテーション
- 表現情報を入力としてfew-shotセグメンテーションを行う
- 4において新たにデータセットを作成し、新たにセグメンテーションマップを予測
実験
実験設定
論文では、学習済みGANとしてStyleGAN2を用いています。画像の表現情報抽出にはStyleGAN2の論文で提案されている手法を用いています。few-shot ネットワークは、畳み込みネットワーク(CNN)と多層パーセプトロン(MLP)の2つを用意し比較実験をします。CNNではleaky ReLU、MLPではReLUを出力層を除く全ての層で活性化関数として用いています。CNN、MLP共にOptimizerとしてAdamを採用し、損失関数はクロスエントロピーを用いています。また、Auto-shot segmentationネットワークには先にも述べた通りUNetを採用しています。UNetの学習にはGANの生成画像とfew-shotネットワークのセグメント画像のペアを訓練データとして用います。この際、データセットに対して以下のデータ拡張を行っています:
- ランダムな反転
- 0.5~2倍のランダムな拡大縮小
- -10~10度のランダムな回転
- 画像サイズの0%~50%のランダムな移動
本論文で用いられているデータセットと評価指標を以下に示します:
- データセット
- 人の顔(CelebAMask-HQ)
- 車(PASCAL-Part)
- 馬(PASCAL-Part)
- 評価指標
- intersect-over-union(IOU)
- そのクラスに属するピクセル数と総ピクセル数の比率
実験
・Human Face Part Segmentation
人間の顔のpart segmentation実験ではfew-shotセグメンテーションの際のアーキテクチャ(CNNorMLP)、partクラスの数(3or10)、手作業で何個アノテーションを行うか(1or5or10)を比較しています。
まず初めにCNNとMLPでの比較です。MLPはCNNと異なり、それぞれのピクセルを独立して推論を行っているためCNNより精度が低いと予想されますが、Table1を見るとsegmentationの予測に関してMLPはCNNとほぼ同程度の性能を持っています。
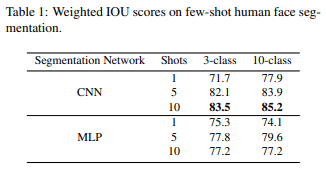
Table2は10-shot segmentationとそれを学習したauto-shot segmentationの比較です。auto-shot segmentationは10-shot segmentationによって生成されたデータセットにのみ依存しているにも関わらず服(clothes)を除くすべてのクラスで10-shot segmantationと同程度のIOUスコアを出しています。服のスコアが低くなることの原因として、服の種類(色や形)が多いためモデルが対応できていないことが考えられます。

次に、CNNを採用したfew-shot segmentationの生成画像とIOUをFig5及びTab3に示します。どちらを見ても10-shotが最も良い性能となっていることがわかります。

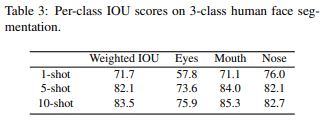
Fig6は提案手法と同じアーキテクチャを採用し、データセットとしてCelebAMask-HQを用いてラベル数を変え、教師有り学習を行った結果と提案手法であるfew-shot segmentationの結果の比較です。グラフを見ると1-shot segmentationを超えるためには100以上のアノテーションが必要となり、10-shot segmentationと同程度の性能を出すためには500程のアノテーションが必要となります。
・Car Part Segmentation
車のpart segmentationはポーズや外観のバリエーションが豊富なため顔画像よりも難しいタスクであることが予想されます。しかしFig7に示すように、提案手法のone-shotではタイヤや窓、ナンバープレートを識別できていることがわかります。

Table4は提案手法の10-shotによって訓練されたauto-shotとDeepCNN-DenseCRF及びOrdinal Multitask Part Segmentationと比較しています。完全教師有り学習であるベースラインと比較しても良い性能を出しています。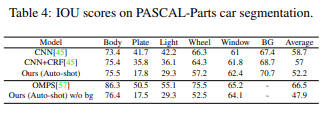
・Horse Part Segmentation
馬のセグメンテーションは先の2つに比べてさらに難しいタスクであることが予想されます。馬は立っているときやジャンプしているときなど様々なポーズがあり、脚と胴体の境界がはっきりしないことが理由として考えられます。予想通り、提案手法のone-shotは人の顔や車に比べて性能が劣りますが、Fig8のようにアノテーションの数を増やすことで大きな改善が見られます。

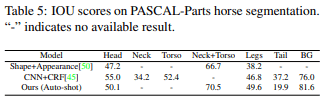
Table5は10-shotで訓練したauto-shotとShape+Appearance及びCNN+CRFと比較しています。Table6はRefineNet及びPose-Guided Knowledge Transferの結果を示しています。提案手法はRefineNetは上回りましたが、300枚以上の完全教師有り学習のPose-Guided Knowledge Transferよりはわずかに低い値となりました。

まとめ
本論文では、画像生成として使われているGANをfew-shot semantic part segmentationに利用するアプローチを提案しました。新規性はGANの生成プロセスから得られるピクセル単位の表現情報を 利用することにあります。提案手法は非常に少ないアノテーションでpart segmentationを可能とし、10~50倍のラベルを必要とする完全教師有りの手法と同程度の性能を出すことができます。また、few-shotで生成されたセグメント画像を新たにデータセットとして作成し学習を行うことでサイズや向きが異なる画像においても対応しています。本論文は教師無し表現学習であるGANが今後、物体のパーツのセマンティックやピクセル単位の予測に対して効果的かつ汎用的な蒸留タスクとして機能するという示唆を与えたと考えられます。





この記事に関するカテゴリー






