ダジャレを生成するAI!Pun-GAN
3つの要点
✔️ GANを用いた駄洒落文生成タスク
✔️ 駄洒落文コーパスを必要としない
✔️ 駄洒落文生成器と語義判別器から構成される
Pun-GAN: Generative Adversarial Network for Pun Generation
written by Fuli Luo, Shunyao Li, Pengcheng Yang, Lei li, Baobao Chang, Zhifang Sui, Xu Sun
(Submitted on 24 Oct 2019)
Comments: Accepted by IJCNLP 2019
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
code:

はじめに
クリエイティブに富んでより面白いテキストを生成することは知的な自然言語生成システムを構築するための重要なステップです。ここで、駄洒落とは2つの意味(語感)を持つ単語や、音が同じだが意味が異なる単語を巧妙で面白く使うことです。本論文では特に前者の駄洒落に着目します。例として、” I used to be a banker but I lost interest”を駄洒落文として紹介します。”interest”という駄洒落語は、好奇心とも利益とも解釈することができます。
ここで、駄洒落生成の問題として駄洒落文が2つの語義でラベル付けされた大規模な駄洒落コーパスが存在しないことが挙げられます。初期の研究としてはテンプレートを用 いたルールベースとなっているため創造性と柔軟性に欠けていました。その後、ニューラルネットワークをこのタスクに用いた研究が行われ、入力として与えられた語義が生成された文配列に含まれることを保証しました。しかし、その手法は2つの語義をサポートしているかを検出することができていませんでした。多クラス分類器を介して文中の単語の正しい語義を識別することを目的としているWord Sence Disambiguate(WSD)によって駄洒落文の検出を手助けすることができます。以上の動機に基づき、提案手法にはGenerative Adversarial Net(GAN)を用います。GANの生成器には2つの特定の意味を持つ単語をインプットとし、駄洒落文を生成するモデルを設定します。識別器は与えられた文が実在する文が否かを識別するモデルです。
また、駄洒落生成の評価にも本論文では取り組んでいます。本論文では自動評価及び人間による評価を行いました。その結果として提案手法であるPun-GANは曖昧性や多様性においてより質の高い駄洒落文を生成していることを示すことができました。
手法
GAN のアーキテクチャを図 1 に示します。GAN は駄洒落文生成器$𝐺_𝜃$と語義識別器$𝐷_𝜙$から構成されています。
Generator
生成器$𝐺_𝜃$は対象となる単語𝑤の 2 つの意味$(𝑠_1, 𝑠_2)$を入力として与え たときに単語$𝑤$を文に含むだけでなく対応する 2つの意味を表す文$𝑥$を出力します。生成器のモデルとしてはYuらの neural constrained language model(2018)を使用します。従来のニューラル言語モデルと異なる点は各タイムステップで生成される単語はそれぞれ$𝑠_1$と$𝑠_2$を入力として計算される 2 つの確率の最大の合計を持つべきという設定がされています。$t$番目の語彙の生成確率は以下のようになります:
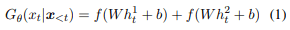
ここで、$h_t^1(h_t^2)$は$s_1(s_2)$を入力としたときの$t$番目のステップの隠れ状態であり、$f()$はソフトマックス関数です。$x_{<t}$は先行する$t-1$個の単語です。これにより文全体$\bf{x}$の生成確率は次のように定式化されます:
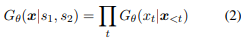
Discriminator
識別器は語義の数$𝑘$に”生成”カテゴリ(="Fake"カテゴリ)を加えた$𝑘+1$個のカテゴリにクラスを分類します。識別器は Kageback and Salomonsson のWSD(2016)を拡張したものです。識別器は以下のように計算されます:

ここで、$c$は$x$を入力としたときの双方向LSTMからの文脈ベクトルであり、$U_w$は単語固有のパラメータ、$y$はターゲットラベルとなっています。
損失関数
識別器の学習目的は、以下を最小化することとなります:
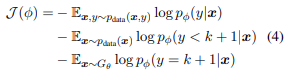
ここで、$p_{data}$は1つの語義しか持っていない文を指します。駄洒落文の生成を促すために識別器は2つの意味を同時に解釈することのできる曖昧な駄洒落文により高い報酬を割り当てる必要があります。駄洒落文の際、$𝐷_𝜙(𝑐_1|𝑥)$と$𝐷_𝜙(𝑐_2|𝑥)$の確率は近く、その2つの確率は多くを占めるように学習する必要があります。例えば(0.1,0.5,0.4)のようになっているときは駄洒落文である可能性が高くなるようにします。一方、(0.1,0.8,0.1)のようになっているときは(0.8)の意味を持つ一般的な文章であるとします。このように実現するために報酬を以下のように設計します:
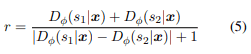
分母の1は分母が0にならないための数値です。
負の期待報酬を最小化することが生成器を学習する際の目的となります(式6)。
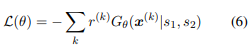
式6の勾配は以下のように近似することができます:
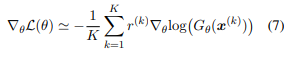
実験
実験設定
- 学習データ
- 英語版Wikipediaコーパスの単語に語義をタグ付けしたものによって生成器の事前学習
- 以下3つは識別器
- WSD用に手動アノテーションされたコーパスであるSemCor(式4の第1項)
- Wikipediaコーパス(第2項)
- 生成された駄洒落文(第3項)
- 評価データ
- 評価データ
- SemEval2017 task7の駄洒落データセット(人間が作った駄洒落文)
- 設定
- Word Embeddingを次元300でランダムに初期化
- サンプルサイズK:32、学習率:0.001、Optimizer:SGD
- 生成器を5エポック、識別器を4エポック分事前学習する
- 敵対的学習においては生成器は1エポックごと、識別器を5エポックごとに学習
- ベースラインモデル
- LM:通常のRNN
- CLM:与えられてた単語が生成された文章に現れることを保証する言語モデル
- CLM+JD:CLMを拡張した駄洒落文生成のための最先端モデル
- 評価
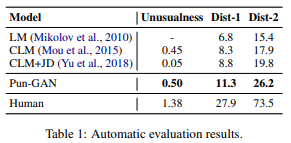
- 自動評価:生成された駄洒落文の対数確率から学習に用いた文の対数確率を引くことで珍しさを評価し、unigramとbigramの比率によって多様性を評価
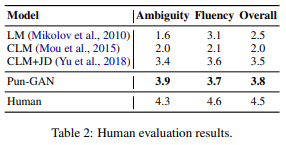
- 人間による評価:人間が、ランダムにサンプリングされた100個の出力を3つの基準にて1~5で評価する
- Ambiguity:文章が駄洒落文であるか
- Fluency:文章が流暢であるか
- Overall:総合的な評価
実験結果
実験結果をTab 1(自動評価)及びTab 2(人間による評価)に示します。Pun-GANはCLM+JDより創造的で意外性があり、より多様な文章を生成することができています。しかし、Pun-GANによる生成文と人間が書いた駄洒落文との間にはまだ大きな隔たりがあることも結果からわかります。
Pun-GANによる生成文の例をFig 2に示します。

最後に、Pun-GANのエラータイプをFig 3に示します。Pun-GANの生成文のエラータイプとして、1つの語義しかサポートしていない文(=駄洒落文でない文)、一般的でない文、文法が誤っている文が挙げられました。

まとめ
本記事では、駄洒落文生成のための敵対的生成ネットワークであるPun-GANを提案した論文を紹介しました。Pun-GANは駄洒落文生成器と語義判別器から構成されています。また、Pun-GANは駄洒落コーパスを必要としません。識別器からの報酬を介して学習することで駄洒落文生成の目的を達成しています。Pun-GANは汎用的で柔軟性があり、将来的には他の制約のあるテキスト生成タスクにも拡張できる可能性があると筆者らは述べています。
宣伝
cvpaper.challenge主催でComputer Visionの分野動向調査,国際発展に関して議論を行うシンポジウム(CCC2021)を開催します.
世界で活躍している研究者が良い研究を行うための講演や議論が聴ける貴重な機会が無料なので,みなさん貴重な機会を逃さないように!!




この記事に関するカテゴリー






