Attention Map を活用した顔画像の超解像度技術「CAGFace」
3つの要点
✔️セグメンテーション技術によって生成した顔のパーツ情報 Attention Map によって、高解像度化を補強
✔️パッチベースにより、高解像度画像を利用した学習が可能
✔️Residual ユニットを採用することで高解像度プロセスを繰り返し適用した超高解像度化が可能
Component Attention Guided Face Super-Resolution Network: CAGFace
written by Ratheesh Kalarot, Tao Li, Fatih Porikli
(Submitted on 19 Oct 2019)
subjects : Computer Vision and Pattern Recognition (cs.CV)
顔認識では、個々人の顔のわずかな違いを認識する必要があります。元となる顔の解像度は低いと、顔同士のわずかな差を見分けることができず、顔認識精度が低下します。そこで、顔認識技術が高精度化する一方で、入力画像の高精度化も求められています。
高解像度化においてもディープラーニングを用いた方法が盛んに提案されています。しかし、従来の研究では、顔の全体画像に対して、高解像度化を行う方法が多くありますが、メモリなどの制限があります。
そのため、この論文では、顔の全体画像をそのまま処理するのではなく、パッチ単位で処理することで、大きな入力画像に対しても高解像度処理を効率的にできるようにしています。また、顔の Landmark を正確に検出するのではなく、顔のパーツ情報を表現するAttention Map を適用する方法を提案しています、これにより高精度に自然な高解像度な顔画像を生成することに成功しています。

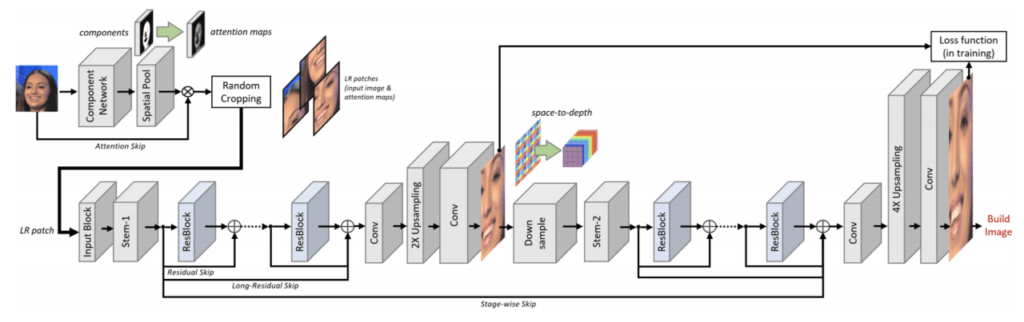
CAGFace の4つの構成要素
CAGFace は、4つの構成要素で成り立っています。
- Component Network
- セグメンテーションのネットワークを使って、顔のパーツ情報を取得
- Stem Layer
- Component Network で取得したパーツ情報を利用して、顔の特徴マップを取得
- Residual Backbone
- Residual Network によって、ネットワークを多層化し、より Context 情報を保持した特徴マップを取得
- Spatial Upsampling
- Deconvolution を使用せずに高解像度化
CAGFace では、これらが連なることで1つの高解像度化プロセスを構成し、このプロセスを繰り返すことで、さらに高解像度化していくことができます。
Component Network
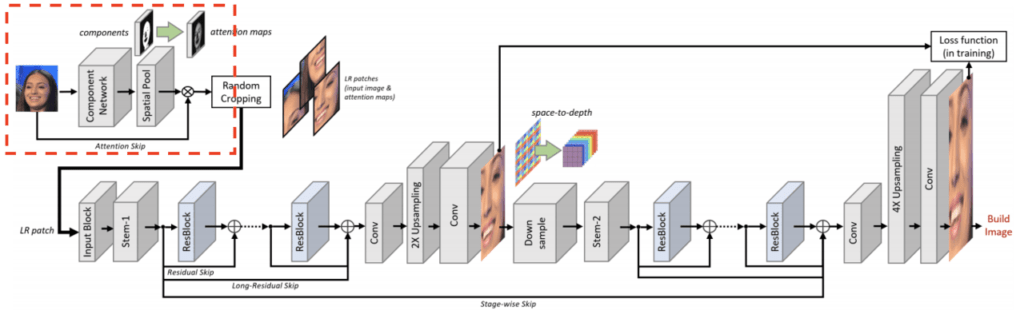
ここでは顔のパーツ情報を取得します。この Component Network には、BiSeNet をベースとしたネットワークを採用しています。このネットワークには、Spatial PathとContext Path の2つの Path があります。
Spatial Path には、3つの Conv Layer があり、高品質な空間情報を持った特徴マップが生成されます。また、Context Path は、Xception の後に Global Average Pooling が適用される構造になっており、豊富な Receptive Field をもつ、多様な注目領域を保持した特徴マップが生成されます。このため、高精度な顔のパーツ情報の Attention Map が取得できます。
この論文では、ネットワークの学習データとして、CelebAMask-HQ データセットを使用しています。このデータセットには、CelebA-HQから選定された 30,000枚の高解像度(1024×1024)の顔画像があり、各画像には 512×512のラベル付きバイナリセグメンテーションマスクと、19の顔のパーツ情報(肌、鼻、目、眉毛、耳、口、唇、髪、帽子、眼鏡、イヤリング、ネックレス、首など)が付与されています。
また、固有の Gaussian spatial kernel を Spatial Pooling Layer に適用することで、セグメンテーションの精度低下を抑制しています。これにより、最終的な Attention Map の値を鋭敏化させ、顔のパーツ情報を明確化する効果もあります。
最後に、入力画像とSpatial Pooling Layer から出力された結果を掛け合わせることで、Attention Map が取得できます。

Stem Layer
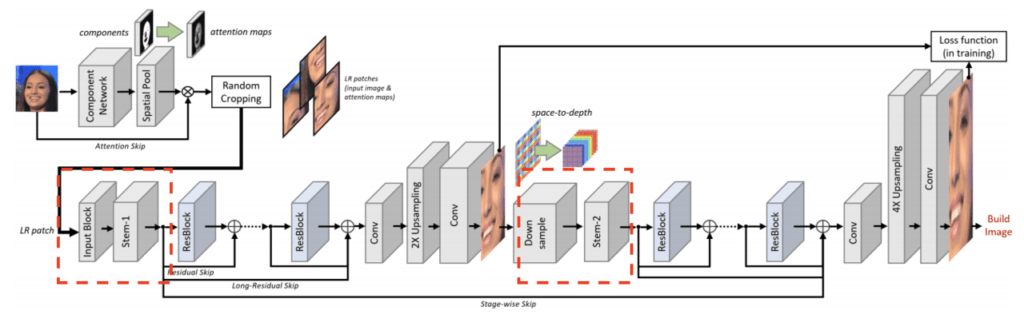
ここでは、Component Network で出力された Attention Map と 入力画像を重ね合わせたデータが適用されます。モデルの学習においては、このデータからランダムに Patch を生成し、Flipでデータ拡張したのち、畳み込みが適用されます。Depth方向のChannelは、低解像度画像に対応するヒートマップで重み付けされた Component の RGB Channel となっています。また、効率的な Backpropagetion のため、 -1 ~ 1 の値に正規化されています。
すべての Layer とプロセスで元の低解像度画像と同じ解像度となるように設計されているため、より効率的に学習できるようになっています。
Residual Backbone
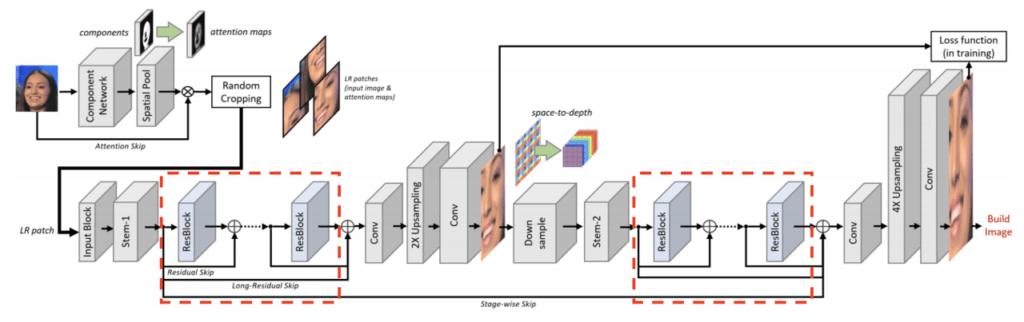
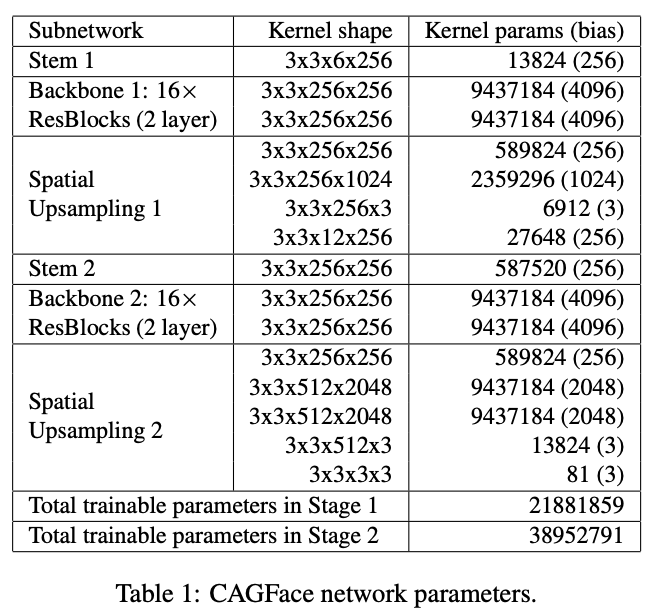
Residual Backbone では、Stem Layer で生成された低解像度の特徴マップに対して FCN(Fully Convolutional Network) を適用します。 Residual Backbone は16個の Residual Blockで構成されています。
各 Residual Block は、ReLUが続く Conv Layer と、最初の Conv Layer からの Skip Connection を持つ Conv Layer の2つで構成されています。同様に、Residual Backbone にも、入力から最後の Residual Block への Skip Connection があります。
この Skip Connection によって、多層化して豊富な Receptive Field を保持し、Context情報をより効率的に活用できるようになります。また、さまざまな抽象度の特徴を欠落なく学習し、細部にわたって特徴を捉えることができるようになります。
Spatial Upsampling
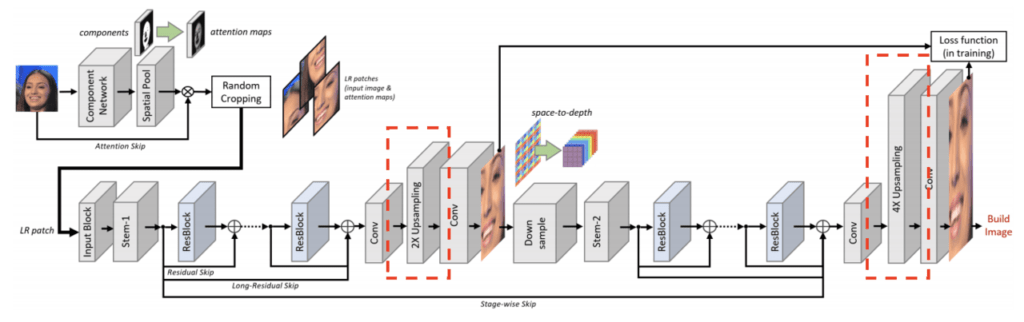
Spatial Upsampling層では、Residual Backbone で抽出した特徴マップから高解像度画像を生成します。ピクセルをシャッフルし、畳み込みFilterのセットを適用するため、アップサンプリングでのデコンボリューション演算が不要です。Spatial Upsampling層のフィルターの学習された重みを使用して、ピクセルあたりの比較的多数の特徴マップの Channel を高解像度画像に変換します。第1ステージと第2ステージの層数を4と5に設定します。(第2ステージの特徴マップはピクセルを生成する必要があるため、1つ層が増えています。)各ステージで2倍の超解像度を提供しますが、多層化され、特徴マップが十分に抽象化されているため、アップサンプリング係数をより大きな比率に設定することが可能です。
CAGFace の性能は?
データセット
Flickrからクロールされました、Flickr Faces HQ データセット(FFHQ) の 高解像度(1024×1024)の顔画像を使用しています。このデータセットは、年齢、民族、画像背景などの豊富な顔の属性情報を持つ 70,000枚のPNG画像で構成されます。また、眼鏡、サングラス、帽子などのアクセサリーもカバーしています。また、利用においては、比率がそれぞれ80%、15%、5%となるように、トレーニングデータ、テストデータ、検証データにランダムに分割しています。
評価指標
パフォーマンスを定量的に測定し、最新の方法と包括的に比較するために、PSNR(Peak Signal-to-Noise Ratio), SSIM(Similarity Index Measure), FID(Frechet Inception Distance), MS-SSIM(Multi-Scale Structural Similarity Index Measure) の4つの品質評価指標を利用しています。このうち、FID は次のように定義されます。
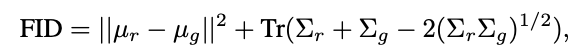
ここで、Xr ~ N(µr, Σr)および Xg ~ N(µg, Σg)は、それぞれ実際のサンプルと生成されたサンプルの Inception-v3 pool3 Layer の Activation です。 FID の値が低いほど、生成された画像が元の画像により近いことを意味します。
比較結果
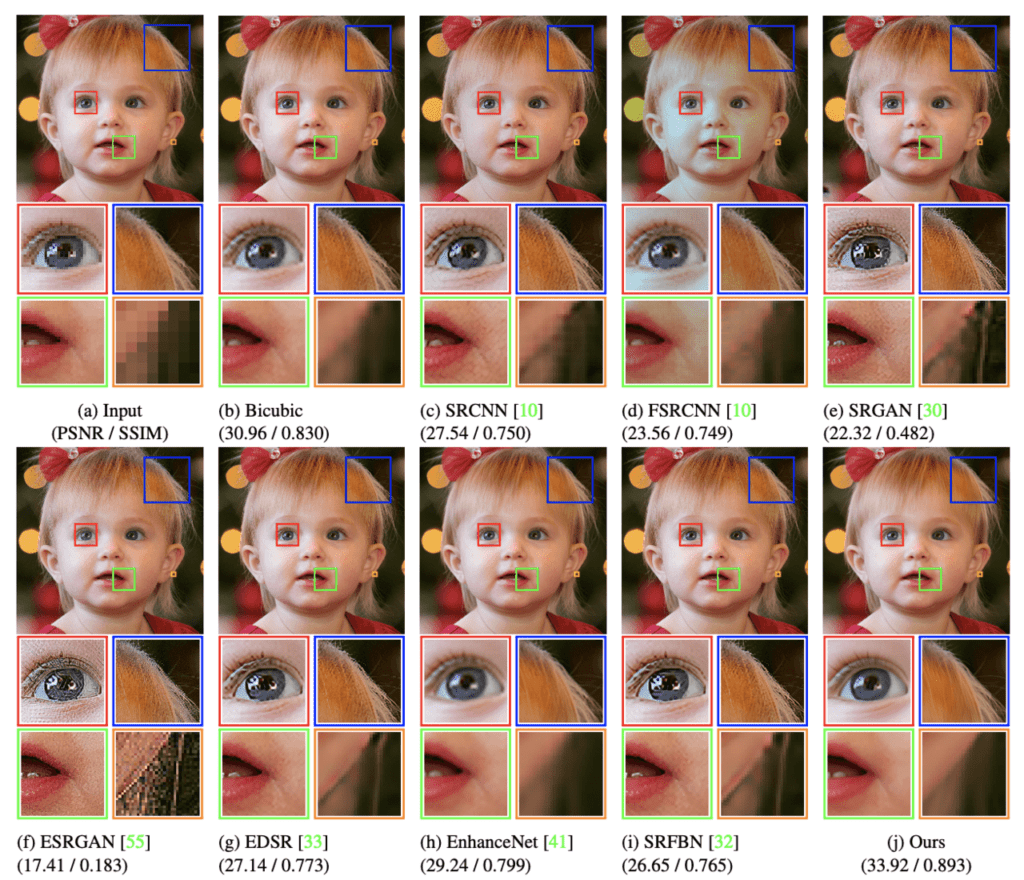
7つの最新の高解像度技術とバイキュービック補間と比較しています。
テストでは、入力画像を顔全体、またはパッチとして処理する方法があります。
- 顔画像全体を入力として使用する場合、顔全体を使用することで Semantics 情報が活用できると考えられます。この場合、入力画像を256×256に圧縮して使用しています。
- パッチを入力として使用する場合、256×256のパッチを作成します。パッチでは、GPUメモリに制限されることなく、非常に大きな出力を生成できます。
以下の図は、それぞれ1024 x 1024画像(パッチベース)と256 x 256画像(顔全体)に高解像度技術を適用した結果を比較したものです。

(Comparisons with the state-of-the-art for the whole-face version)
(Comparison with state-of-the-art methods for the patch-based version)
今回提案された方法が優れた性能を示していることがわかります。特に、パッチベースでは、Artifacts を発生させることなく高精度な高解像度画像を生成することができました。それに比べて、GANベースの方法では、目視で確認できる断片化、ノイズ、破損などが見られました。
また、以下の表に定量的な結果を示しています。このモデルでは、PSNR、SSIM、FIDなどのさまざまな指標で優れた精度を示しています。
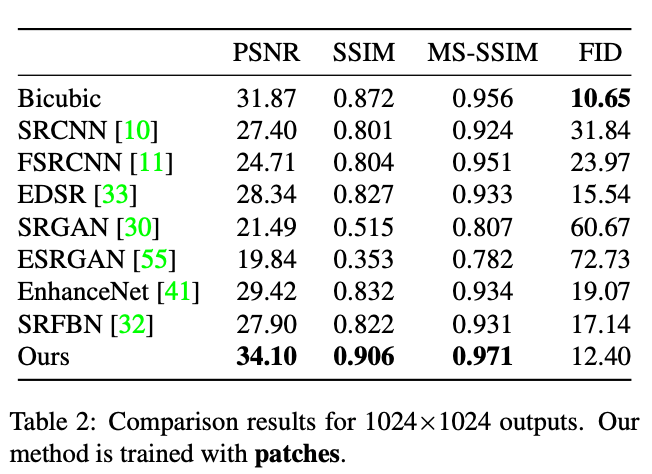
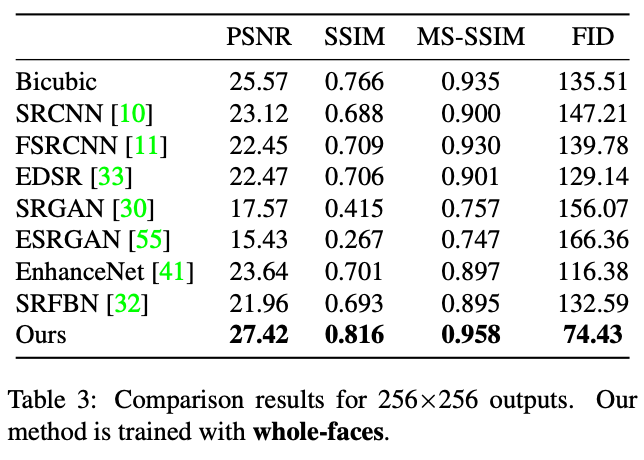
今回比較で使用した従来の方法では、顔のSemantic情報を利用していない、あるいは、バイアスのかかったSemantic情報が適用されています。いずれも高解像度化に顔のパーツ情報を使用していません。また、ほとんどの場合、トレーニングに低解像度画像を使用することになるため、学習できる特徴も制限されている可能性があります。
また、これは、Semantic バイアスがない決定論的アプローチであるバイキュービック補間が、他の比較対象のモデルよりも優れたパフォーマンスを発揮している理由とも言えるかもしれません。
まとめ
この論文では、Attention Map を適用し、中間および最後の Upsampling での損失関数を利用して高解像度化プロセスを正則化することで、大幅にパフォーマンスを向上できることがわかります。さらに、パッチベースにすることで、あらゆるサイズの入力画像を効率的に処理できるようになっています。
この論文のポイントは、次の3つにまとめられます。
- BackboneとLayer全体で元の低解像度画像をパッチ処理して高解像度画像を再構成するパッチベースの Fully Convolutional Network を導入しています。
- 高解像度化のステージを繰り返し適用。次のステージでは、前ステージで生成されたされた高解像度画像を活用し、高解像度化を段階的に強化しています。
- Perceptual Artifacts を誘発することなく、既存の方法よりも大幅に優れた性能を示しています。



この記事に関するカテゴリー






