圧縮動画ベースで実現するリアルタイムの表情認識!?
3つの要点
✔️ 圧縮動画から直接、表情認識する方法を提案
✔️ 圧縮動画には表情筋の動きが差分データとして埋め込まれているため、表情の本質的な特徴量を活用した堅牢なモデル構築が可能
✔️ 差分データを活用することで計算コストの削減と処理速度の高速化を実現
Identity-aware Facial Expression Recognition in Compressed Video
written by Xiaofeng Liu, Linghao Jin, Xu Han, Jun Lu, Jane You, Lingsheng Kong
(Submitted on 1 Jan 2021 (v1), last revised 7 Jan 2021 (this version, v2))
Comments: Accepted at ICPR 2020
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Multimedia (cs.MM)


概要
NetflixやYouTube、TikTokなどインターネット上で動画データを送受信することは当たり前になっています。5Gの普及が進むとこの傾向はさらに強まると考えられます。
この動画データはデータサイズが大きいため、一般的に圧縮された形式で扱われます。復元できる範囲で無駄なデータを省き、必要最小限のデータのみにすることで、動画を効率よく扱うことができます。これはこの記事のテーマである表情認識にも大きく影響します。
表情認識が利用されるシーンは、撮影した動画からハイライトシーンを自動抽出した作業効率化やマーケティング素材の検索、医療分野における患者の様子の観察、あるいは、人の感情に応じて動作を変えるロボットなど様々です。これらは、いずれも大量の動画データを処理することが求められます。特に人の感情に応じて動作を変えるロボットでは、リアルタイムの反応が求められるため、できる限り効率的に処理することも必要です。
これまでの手法のほとんどは、圧縮動画をデコードしたシーケンスのRGB画像を処理するものでしたが、この論文が紹介する「IFERCV」では、圧縮された動画データから直接、表情認識します。この結果、従来と同程度の精度で3倍の処理速度を実現しています。
圧縮データを用いた表情認識モデル「IFERCV」
前述のように、動画の表情認識を行う場合、従来の手法は下図(黄色)のように、一旦RGB画像にデコードしていました。一方で、
IFERCVは下図(緑色)のように、圧縮動画をデコードせずにそのまま表情認識をします。このため、従来と比べて、デコードの処理を省き、データ量の少ない圧縮データで表情認識の処理ができるため、処理速度が格段に上がります。
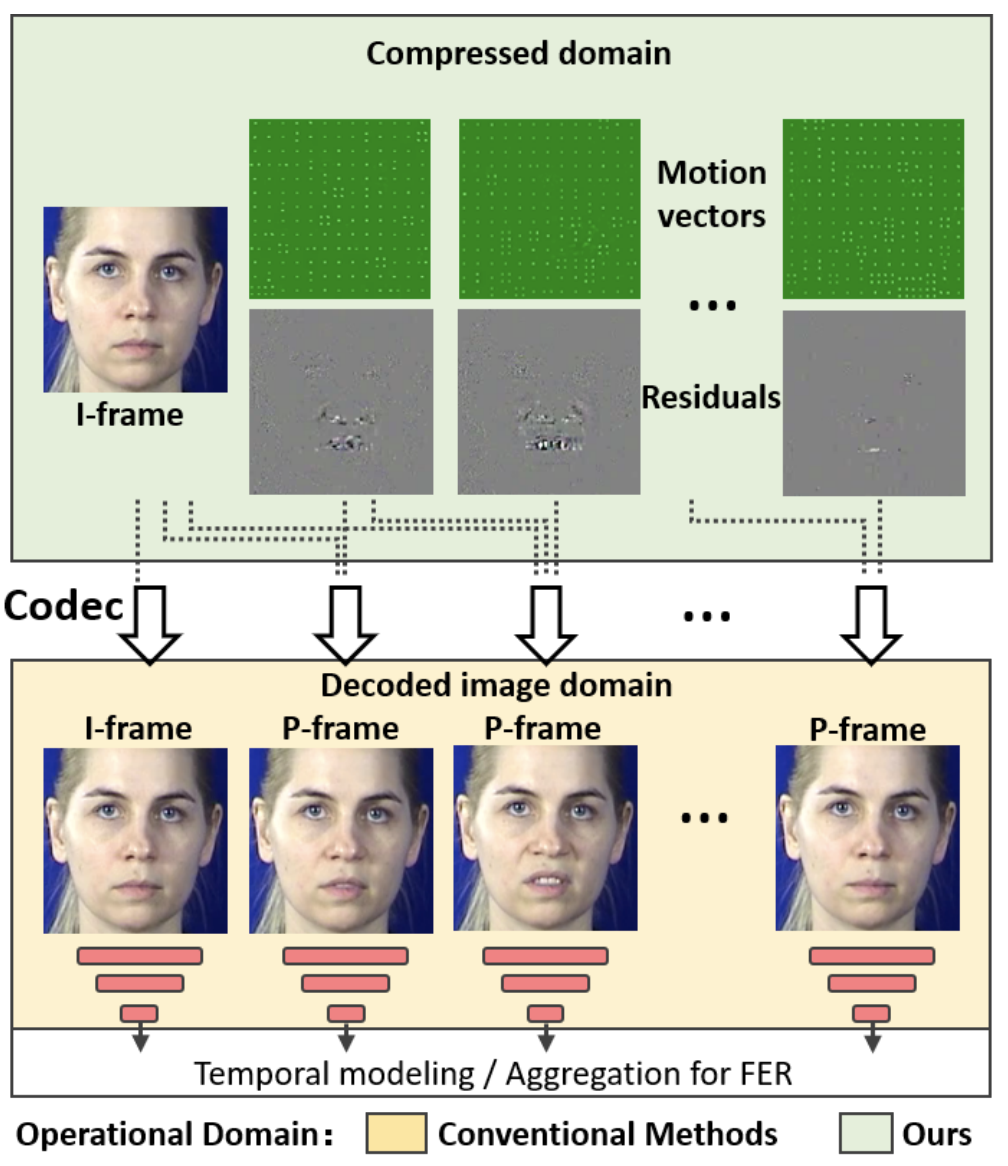
動画は、一般的にIフレームとPフレームから構成されます。Iフレーム(Intra-coded Frame)は、キーフレームとも呼ばれ、フレーム間で予測を行っていないキーとなるフレームです。また、Pフレーム(Predicted Frame)は、時間的に前のフレームから予測される画像との差分(Residuals)を考慮したフレームです。この時、フレーム中の物体の動きなどの補正情報である動きベクトル(Motion Vectors)も合わせて埋め込まれています。
圧縮動画では、元のフレーム情報をそのまま保持せず、基準となるIフレームとその変化を表す差分(Residuals)と動きベクトル(Motion Vectors)の組み合わせに簡略化することで情報を圧縮しています。
この論文では、この差分(Residuals)から直接的に表情認識を行っています。概要は下図のようになります。
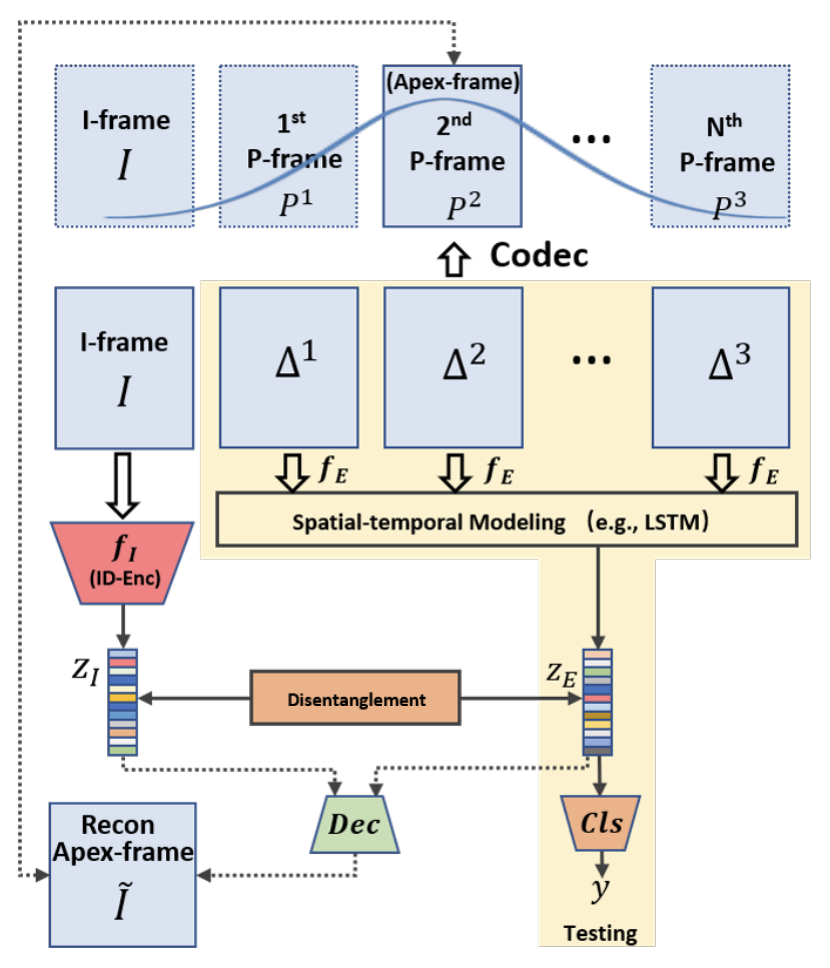
IフレームとPフレームをそれぞれIとP、差分と動きベクトルをそれぞれΔとTで表しています。PとΔにある添字は、Iフレームからの時間経過を表しています。この手法では、表情変化の学習をしやすくするために、Iフレームとして基準となる真顔のフレームを選び、学習済みのFaceNet(fI)を利用して真顔の特徴量(ZI)を抽出しています。
次に表情の変化に関する特徴量を抽出するために、Δに対して典型的なCNN-LSTMを利用しています。一連のΔtに対してCNN(fE)を適用したのち、LSTMによってfEから抽出した特徴量を1つに集約し、最終的に表情変化を特徴量化したZEを抽出しています。
この時、差分データであるΔは一般的なフレームと比べると、はるかに情報量が少ないため、従来の表情認識で使用されるCNNよりもシンプルで高速なものを利用することができます。その結果、計算負荷が大幅に小さくなります。さらに、Disentanglment Learningを利用して、ZIとZEを「真顔」と「表情がある顔」の2つに明確に分離させることで、より本質的な表情の特徴情報を抽出し、堅牢なモデル構築も行っています。
具体的には、ZIとZEからApex-frameに該当するIフレームをデコードしています。Apex-frameとは表情の変化がもっとも顕著になっているフレームです。Apex-frameのラベルが付いている画像と、ZIとZEからデコードした画像の再現性が高くなるように学習させることで、ZIとZEを「真顔」と「表情がある顔」の2つに分離させています。
表情認識のデータセット(CK+、MMIなど)は、真顔から表情顔への変化がわかるようになっているものが多いため、「真顔」と「もっとも表情が変化した顔」(Apex-frame)を選んで使用することができます。
実験結果
ここでは、CK+とAFEWの2つのデータセットを使って、SOTAのモデルと性能を比較しています。CK+(Extended Cohn-Kanade)は、表情認識のタスクで広く使われているベンチマークです。被写体は背景がブランクの状態でカメラを向いた状態で撮影されています。つまり、ある程度整えられた環境で撮影された動画のデータセットです。各動画は無表情から表情がある表情へと変化する593の画像シーケンスで構成され、最後がもっとも表情の変化が大きいフレームになっています。表情のラベルは、Anger、Disgust、Fear、Happiness、Sadness、Surpriseの6つです。被写体の人数は123人です。
AFEW(Acted Facial Expressions in the Wild)は、映画のビデオクリップで構成されています。そのため、CK+と異なり、撮影条件を整えていない、より実際の環境に近い状況で撮影された動画のデータセットです。表情のラベルは、CK+と同様に、Anger、Disgust、Fear、Happiness、Sadness、Surpriseの6つです。 被写体は不明ですが、動画数は1,809個です。
CK+の実験結果
まずCK+による従来モデルとの性能比較の結果は下表の通りです。ここでは各モデルを公平に比較するために、画像ベース、アンサンブルのモデルは含まれていません。
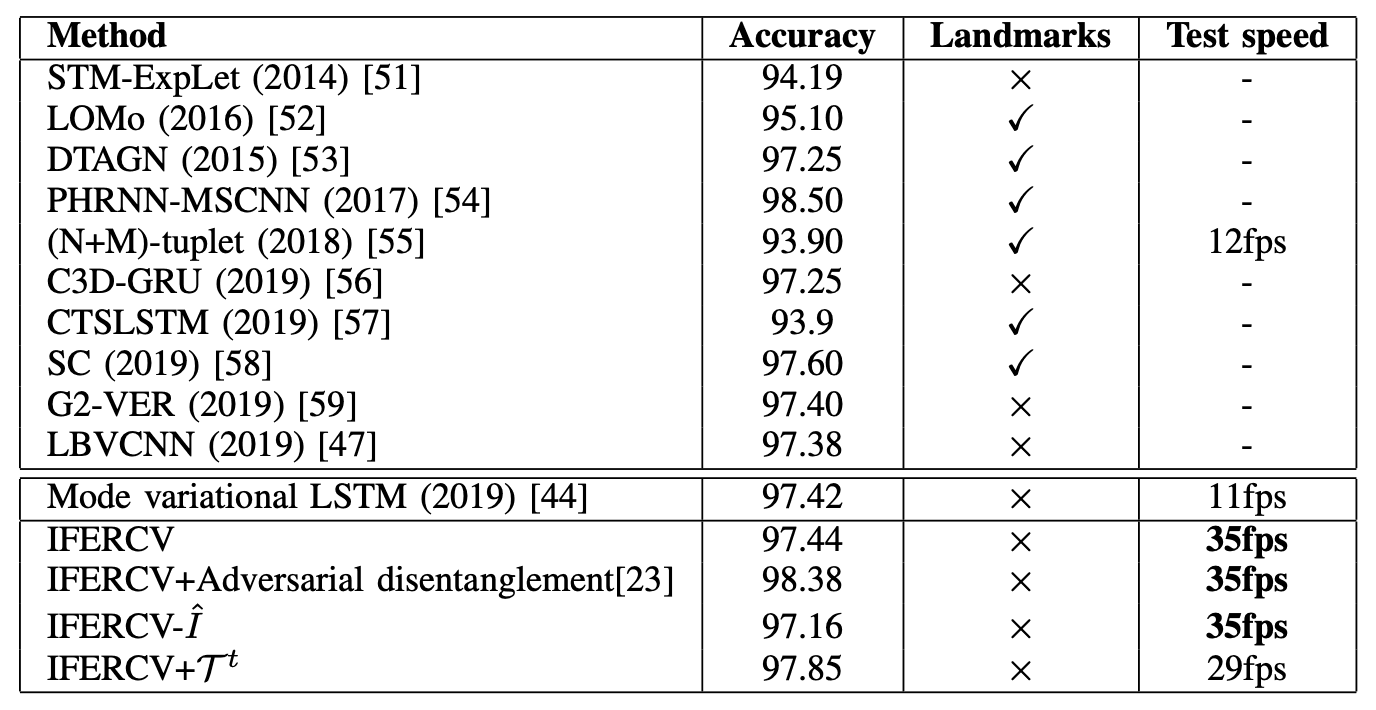
高い性能を達成している多くのモデル(LOMo、DTAGN、PHRNN-MSCNN、CTSLSTM、SCなど)が、顔のランドマーク情報を利用しています。これらは高精度なFace Landmarkの検出モデルに大きく依存しています。このFace Landmark自体が難しいタスクであり、計算量も増えてしまいます。
一方で、今回提案するIFERCVはMode variational LSTMをベースとして、Face Landmark、3D Face Model、Optical Flowなど補完情報を利用せずに、SOTAの精度を達成しています。また、圧縮ベースで処理するIFERCVは、動画をデコードする必要がないため、ベースとしているMode variational LSTMよりも約3倍高速に処理でき、高い精度を達成できます。
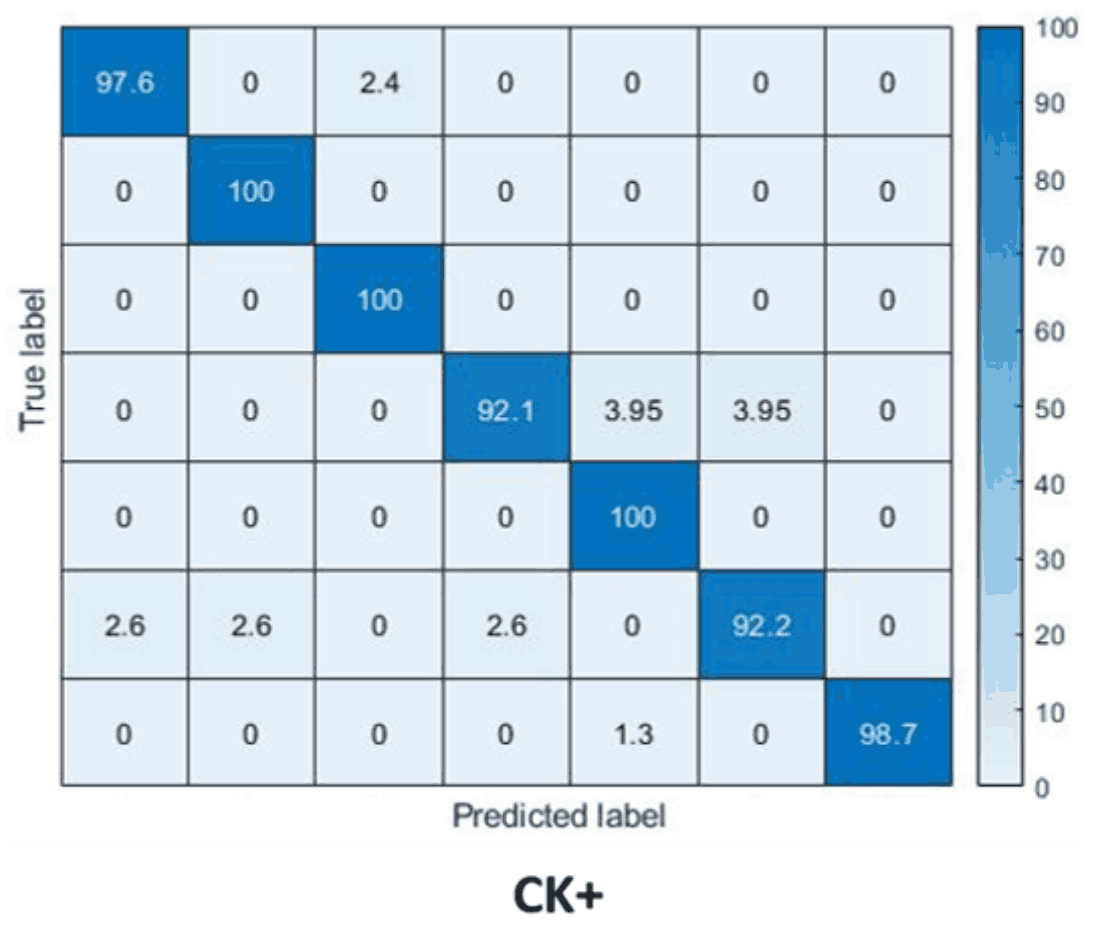
Confusion Matrixは以下のようになります。各行と列は、上/左からAnger、Disgust、Fear、Happiness、Neutral、Sadness、Surpriseを表していますが、いずれにおいても高い精度を達成していることがわかります。
AFEWの実験結果
次にAFEWによる従来モデルとの性能比較の結果は下表の通りです。ここでも各モデルを公平に比較するために、アンサンブルのモデルは含まれていません。(表は論文から引用していますが、Model typeとAccuracyの項目名が逆になっていると思われます。)
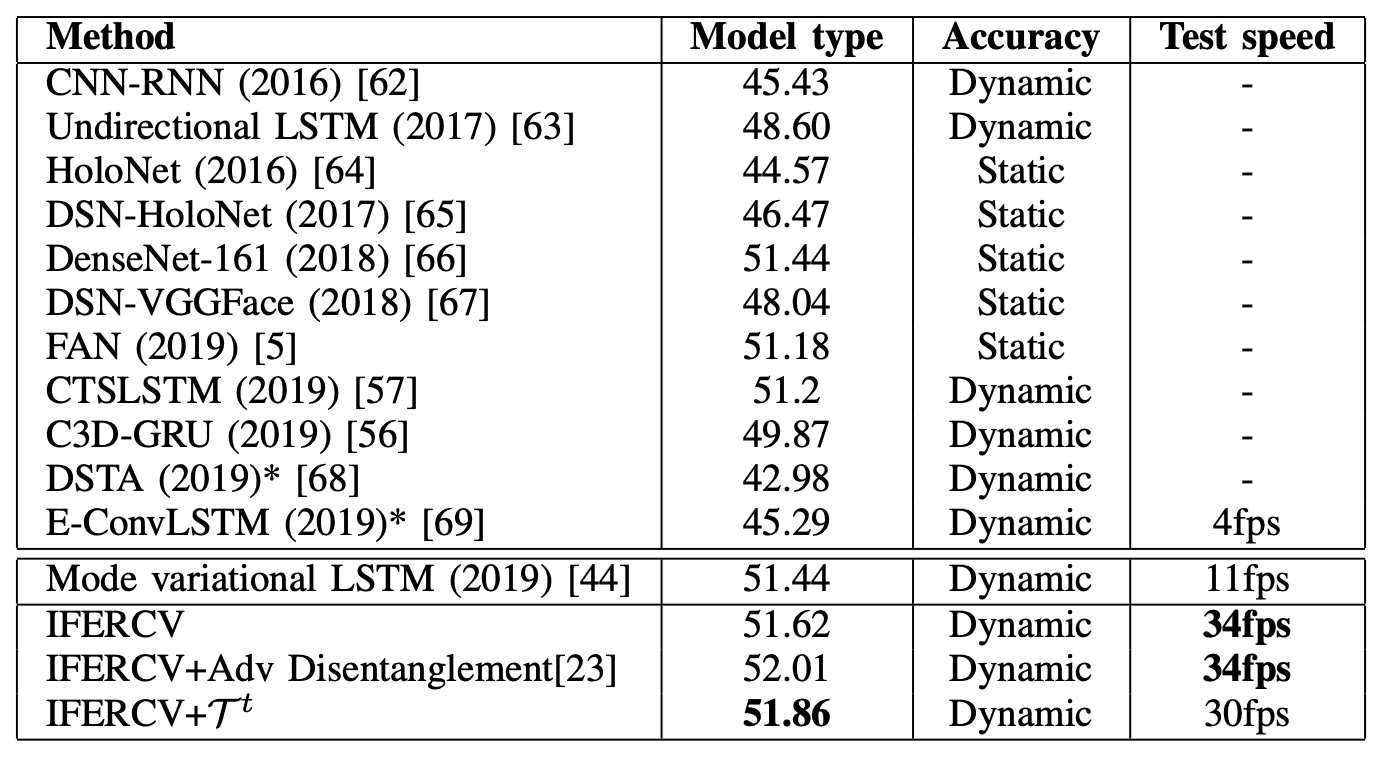
AFEWは、CK+に比べると撮影環境が整っていないため、Accuracyは全体的に低くなっています。また、ここでは音声データは利用していません。
IFERCVは、圧縮ベースでSOTAの手法と比べて同等以上の認識パフォーマンスを達成しています。また、ベースとして使用しているMode variation LSTMに比べて、こちらも3倍の処理速度を実現しています。認識精度は不十分であるものの、圧縮ベースの処理によって、実際に近い撮影環境においても、リアルタイムに近い速度で表情認識できる可能性を示しています。
従来モデルは、動画をデコードする必要があり、さらに補完情報を利用するなど複雑なデータ処理をする必要があります。一方で、提案されたIFERCVは、これらの処理を省くことができます。また、Test speedを大幅に向上させ、以前のモデルと同様の精度を達成していることがわかります。
今回は、画像圧縮のみに焦点をあてて検証をしていますが、音声データを利用したマルチモーダルを試すことで、さらに精度を向上できる可能性もあります。
まとめ
この論文では、圧縮された動画データから直接、表情認識する方法を提案しています。圧縮された画像データには、表情筋の動きが差分データとしてうまくエンコードされているため、顔の表情の本質的な特徴量が得られ、堅牢なモデルが構築できるという考えに基づいています。差分データを活用することで、動画内でほとんど変化がない背景などの冗長なデータを省き、少ない計算コストで学習できるという効果も期待できます。
IFERCVでは、Iフレームと差分データから抽出した特徴量にDisentanglmentを適用することで、顔識別情報と表情情報を切り離し、本質的な表情情報を抽出する方法も適用しています。
これらを適用することでIFERCVを代表的な動画ベースのFERベンチマークと比較した結果、補完情報などを適用せずにSOTAの精度を達成しています。さらに、処理速度も大幅に改善し、リアルタイムFERに向けて期待できる結果を示しています。





この記事に関するカテゴリー






