レンダリングを応用した画像セグメンテーション「PointRend」
3つの要点
✔️CGのレンダリング技術を画像セグメンテーションに応用
✔️領域に応じてサンプリング密度を変化させ、確度が低いピクセルのみを重点的に予測する「PointRend」を提案
✔️演算量の増加を抑えつつ、インスタンス境界の分類において、高精度化を実現
PointRend: Image Segmentation as Rendering
written by Alexander Kirillov, Yuxin Wu, Kaiming He, Ross Girshick
(Submitted on 17 Dec 2019)
subjects : Computer Vision and Pattern Recognition (cs.CV)
画像セグメンテーションは、自動運転などにも応用される重要な研究分野です。
従来のセグメンテーションの方法では、入力画像をエンコードし、特徴量マップとしてラベリングしたのちに、デコードでアップサンプリングします。
例えば、この論文でも紹介されている DeepLabV3 では、デコードの際に、4倍のアップサンプリングを2回行うため、16倍にアップサンプリングすることになります。しかし、セグメンテーションは、ピクセル単位で細かく分類するタスクであるため、一度に大幅なアップサンプリングを実行すると、分類精度が落ちてしまいます。特に、線の細い境界領域の分類が粗くなってしまいます。
また、従来のネットワークは、画像を均一に分割し、各ピクセルに対して、セグメンテーションし、ラベリングしていきます。しかし、画像には低周波数領域(比較的滑らかで小さな色の変化)と高周波数領域(明らかな変化、オブジェクトの境界線)があります。低周波数領域の場合、高確率であれば特定のカテゴリに分類され、サンプリングする必要はほとんどありませんが、高周波領域の場合、サンプリングされたポイントがまばらであれば、分類されたオブジェクトの境界は粗くなってしまう可能性があります。オブジェクトの境界をアンダーサンプリングすると同時に、不必要に滑らかな領域をオーバーサンプリングされてしまう傾向があります。
Facebook が提案する「PointRend」では、特徴量マップのピクセル値の分布に応じて計算対象を選ぶサンプリングの密度を変えることで、必要なピクセルで必要な計算し、微調整をすることができます。そのため、詳細なラベリングが実現でき、境界線の分類精度が高くなります。また、選択的に計算をするため、従来の手法と比べて、計算効率も上がります。
また、Mask R-CNNなどの一般的なインスタンスセグメンテーションメタアーキテクチャや、FCNなどのセマンティックセグメンテーションメタアーキテクチャに組み込むこともでき、広く応用が可能です。
PointRend を構成する3つのモジュール
PointRend は、3つのモジュールで構成されています。
- Point Selection Strategy
- いくつかのポイントを選択して予測を行うことで、高解像度に変換された後の計算量を限定的にすることができ、計算量を抑制
- Point-wise Feature Representation
- 選択されたポイントごとにバイリニア補間を用いて特徴量を抽出
- Point Head
- ポイントごとに抽出された特徴量からラベルを予測するように学習した小さなニューラルネットワーク
Point Selection Strategy
推論
ポイントの選択方法は、CGの Adaptive Subdivision の古典的な手法を応用しています。
この手法では、その近隣と値が著しく異なる可能性が高いピクセルのみを計算していくことで、高解像度の画像を効率的にレンダリングし、他のピクセルは、既に計算されている出力値からバイリニア補間することによって算出します。PointRendでは、低解像度の粗いマップに対して、バイリニア補間を繰り返しレンダリングすることで、前マップで予測されたセグメンテーションのラベルをより高精度にアップサンプリングします。
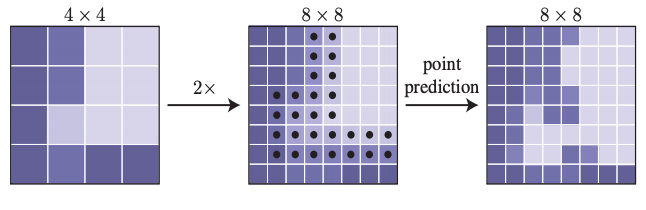
このアップサンプリングでは、N 個の不確実なポイント(たとえば、バイナリマスクの確率が0.5に最も近いポイント)を選び、 PointRendで、これら N 個のポイントポイントごとに特徴量を計算し、ラベルを予測していきます。
入力の解像度が M0 x M0, 出力の解像度を M x M とすると、PointRend では、N log2(M/M0)のポイントのみを予測することになります。
N log2(M/M0)<< M x M となるため、通常のセグメンテーションに比べて、計算量を削減できることもわかります。
例えば、M0=7, M=224, N=282 とした場合、PointRendでは、282*4.25=1410 のポイントのみを予測することになります。これは、2242 と比べると 1/15 になります。
学習
学習の際、PointRendでは、Point Head を学習するためのポイント選択も必要になります。
基本的には、推論で行われる細分化の方法に似ています。
しかし、推論時の細分化では、バックプロパゲーションでニューラルネットワークが学習できるよう、シークエンシャルな方法になっているが、学習時ではランダムサンプリングを用いた非反復の方法を採用しています。
学習時のポイント選択では、次の3つの原則を使用して、選択範囲を不確実な領域に偏らせ、ある程度の均一なカバレッジを維持するように設計されています。
- Over generation
一様分布から kN 個(k>1)をランダムにサンプリングすることにより、ポイントの候補を生成します。 - Importance sampling
補間後の kN から不確実性の高いポイントに注目し、特に不確実性の高い βN 個(β ∈ [0、1])のポイントを選択します。 - Coverage
残りの(1-β)N 個のポイントは均一な分布からサンプリングします。
また、学習中、予測値と損失関数は選択された N 個 のポイントのみで計算される効率的な方法になっています。これは RPN + Fast R-CNN と同様の考え方です。
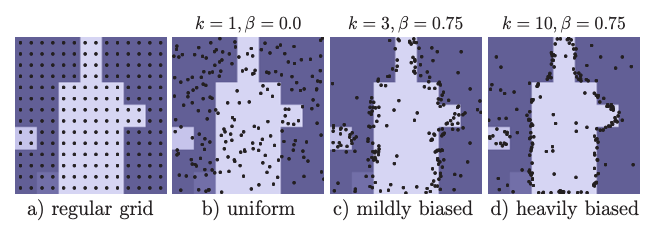
例えば、上図のように同じマップに対して N=142 をサンプリングする場合、高いパフォーマンスを達成するためには、領域ごとに少数のポイントのみがサンプリングされ、わずかに偏ったサンプリング方法(ex. mildly biased)の方が、より学習効率が向上します。
Point-wise Feature Representation と Point Head
PointRendは、Coarse prediction features と Fine-grained features を組み合わせることで Point Feature を形成します。
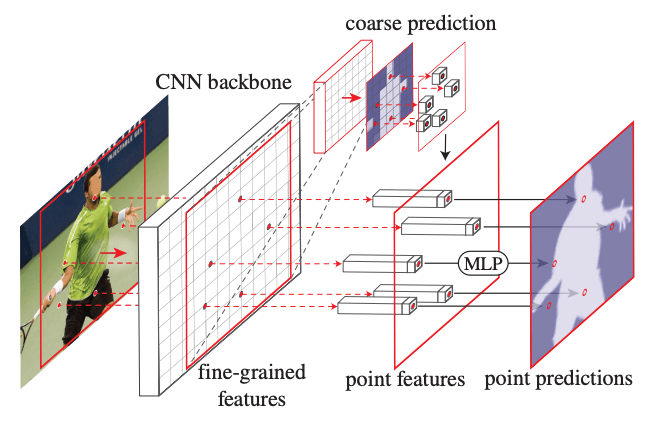
- Fine-grained features
PointRend が細部まで詳細にレンダリングできるようにするために、CNNで抽出した特徴マップ上で、サンプリングしたポイントごとに特徴量を抽出します。ポイントの値は、実数値の2D座標であるため、特徴マップ上でバイリニア補間することで、特徴量を算出します。
単一の特徴マップ(ResNetの res2 など)から特徴量を抽出できます。 また、Hypercolumn に従って、複数の特徴マップ(res2からres5、またはそれらの特徴ピラミッドに対応するもの)から抽出し、連結することもできます。 - Coarse prediction features
Fine-grained features は、詳細なセグメンテーションができる一方で、欠点が2つあります。
1つ目は、領域情報が含まれていないため、2つのインスタンスで bounding box が重なるポイントでは、同じ Fine-grained features になります。
しかし、それぞれのポイントは、1つのインスタンスにしかなりません。したがって、インスタンスセグメンテーションでは、同じポイントに対して異なるラベルを予測する可能性があります。そのため、追加でこれらを補完する領域情報を与える必要があります。
2つ目は、どの特徴マップを Fine-grained features として使うかに依存するため、場合によっては低解像度の特徴しが利用できない可能性があります。この場合、より文脈的および意味的な情報を含むものを与える必要があります。
これらを考慮して、Coarse prediction features では、明確なコンテキストや意味情報を含み、各ポイントは K-class prediction による K次元ベクトルを持ちます。解像度が粗いことで全体的な情報を表現しつつ、チャネルで semantic class を伝えます。 - Point head
選択されたポイントごとに特徴量が与えられると、PointRend は、MLP によってポイントごとにセグメンテーション予測を行います。
このMLPは、Graph Convolution または PointNet と同様に、すべてのポイント(およびすべての領域)で重みを共有します。
実験
Instance Segmentation
ベースとなるネットワークに Mask R-CNN with a ResNet-50 + FPN を使い、COCO と Cityscapes のデータセットを用いて、実験をしています。
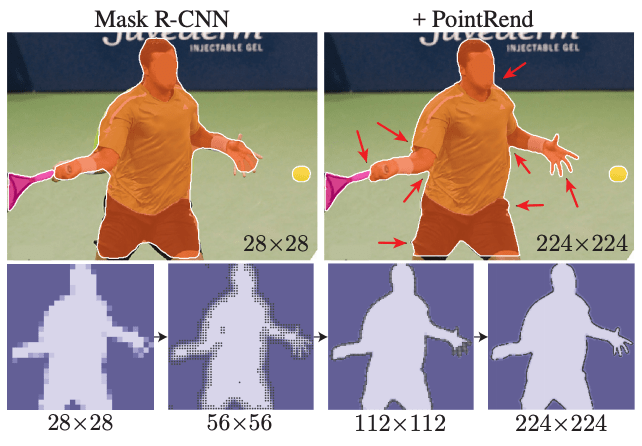
この実験では、Mask Head が 4x conv の標準のものと、PointRend のものを比較した結果、定性定量の両面で高い精度を示しています。
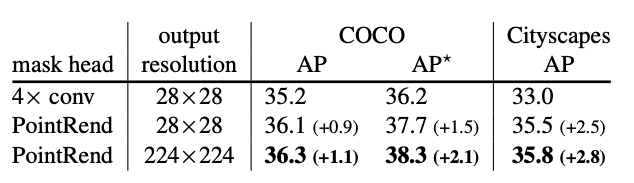
以下の図は、出力結果の一例です。高解像度の画像でより効果的に分類できていることがわかります。


Semantic Segmentation
ベースとなるネットワークに DeeplabV3 with ResNet-103 を使い、Cityscapes のデータセットを用いて、実験をしています。
この実験でも、PointRend を利用したもので、より高い精度を示しています。 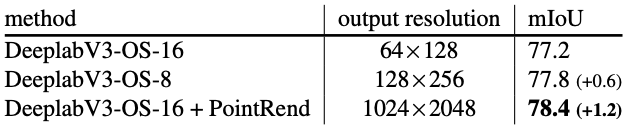
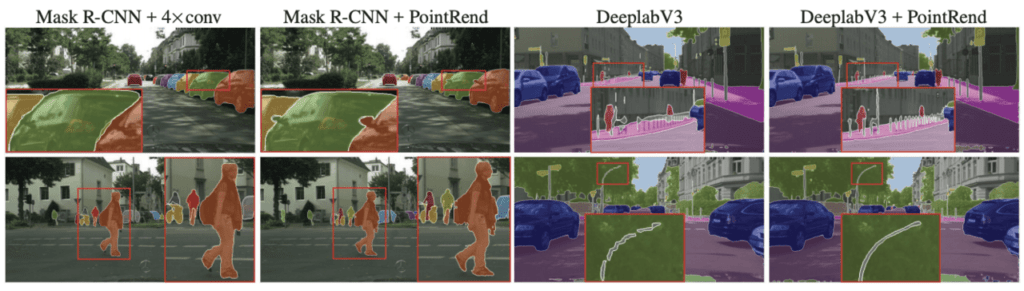
以下の図、右側は、出力結果の一例です。






この記事に関するカテゴリー






