CNNは位置情報を知っているのではないか?
3つの要点
✔️ CNNは位置情報をエンコードしている
✔️ 0パディングによって位置情報を学習する
✔️ 深い層に位置情報は保持されている
How Much Position Information Do Convolutional Neural Networks Encode?
written by Md Amirul Islam, Sen Jia, Neil D. B. Bruce
(Submitted on 22 Jan 2020)
Comments: Accepted to ICLR2020
Subjects: Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
Paper Official Code COMM Code
はじめ
CNNは分類や検出タスクなどの多くのコンピュータビジョンタスクで成功してきました。基本的にCNNは物体の特徴抽出器としての役割がメインです。なぜなら、局所的なフィルタによって学習され、基本的には位置情報は持たないとされているからです。そのため、この点を指摘され、カプセルネットなどの位置情報の獲得をメインとしたモデルも提案されています。なので多くの皆さんが、CNNは位置情報をほとんど持たないと考えていませんか?
しかし、この研究でその暗黙的に考えられてきた考えが覆るかもしれません。
図1をご覧ください。
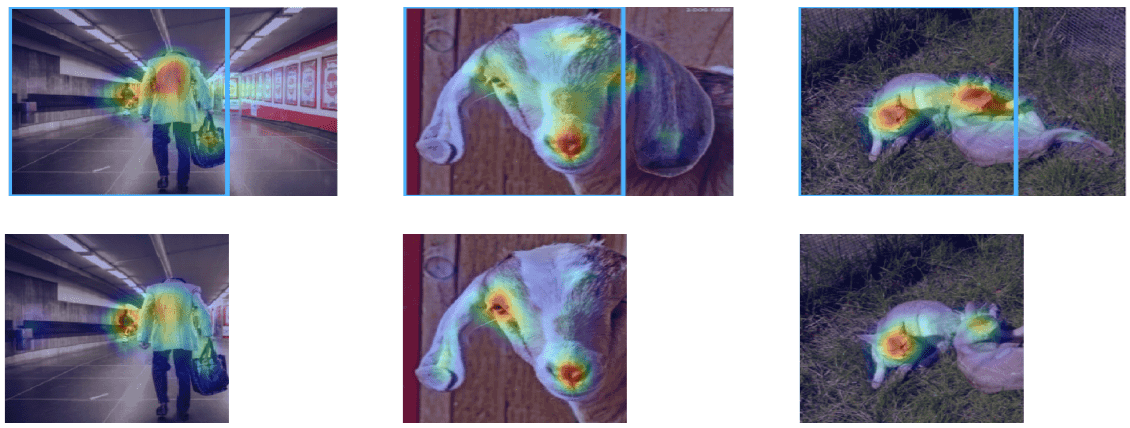
図1. 画像の顕著領域
上段を見てください。左では真ん中にいる男性に顕著領域があります。同じようにほとんどの画像が真ん中周辺に顕著領域が存在していることがわかります。次に上段の青いラインで画像をクロップした画像を下段に示しています。ここでおかしなことに気付きます。画像をクロップしただけなので、テクスチャ等にはなんの変化もないので顕著領域が変わることはないはずです。しかし、クロップした画像の顕著領域は明らかに左にシフト(中央領域)しています。(これは学習画像的にも顕著領域は画像の中央部にあることを学習したためにこの現象が起きたのだと思います。)これは、我々が暗黙的に考えていたCNNは位置情報を持たないに反しています。
この結果から著者たちは、人間にわからないだけで、CNNは位置情報をエンコード(取得)しているのではないかという仮説をたてました。今回のご紹介する記事はCNNの位置情報に関する内容となります。
この論文はICLR2020に採択され、査読者が全員満点(8点)をつけた論文です(満点評価を受けたのは2594本の論文のうちわずか34本)。他の論文の点数が気になる方はここをご覧ください。
続きを読むには
(5457文字画像10枚)AI-SCHOLARに
登録いただく必要があります。



この記事に関するカテゴリー






