非エンジニアがTensorFlow2.0 Alphaのビギナー向けチュートリアルをやってみた
先日3/7に行われた『TensorFlow Dev Summit 2019』で発表されたTensorFlow2.0 alpha今回はそのビギナー向けチュートリアルをGoogle colabでやってみたので、デモの一つ一つを解説したいと思います。
皆さんも、コーディングができなくても試せる機械学習を体験してみませんか?
【参考】: https://www.tensorflow.org/alpha/tutorials/keras/basic_classification
【コード】: https://colab.research.google.com/github/tensorflow/docs/blob/master/site/en/r2/tutorials/quickstart/beginner.ipynb
そもそもTensorFlowって?
TensorFlowとはGoogleがオープンソースで開発・公開している機械学習のためのライブラリです。2017年に公開されて以来、様々な場面で機械学習のために利用されてきました。Pythonという言語に対応しておりユーザーが多いこともあってTensorFlowは非常にユーザー数が多い機械学習ライブラリとなりました。そして、今回2019年3月8日に新しいTensorFlow2.0のα版が公開されました。
実際にやってみた
さて、TensorFlow2.0 alphaが以下のサイトhttps://www.tensorflow.org/alphaで紹介されており、使い方やチュートリアルなどをみることが可能です。今回はこちらのサイトにあるビギナー向けのチュートリアルを機械学習ド素人の自分が実際にやってみました。また、今回のチュートリアルはGoogleColabのJupyterNotebookを用いることで自分のPCにも環境を構築する必要なく試せるので非エンジニアでも簡単に機械学習を体験できます。
TensorFlowの読み込み
最初にGoogleColabで検索し、GoogleColabへログインします。(Googleアカウントが必要です。)
そして、PYTHON3の新しいノートブックを選びます。
そうすると以下のような画面になります。
このようになったら、まずTensorFlow2.0をブラウザ上の環境に読み込みます。
!pip install -q tensorflow==2.0.0-alpha0
こちらを、貼り付けて貼り付けた箱の左側にある再生ボタンを押してみましょう。
コードが実行され、結果が出力されます。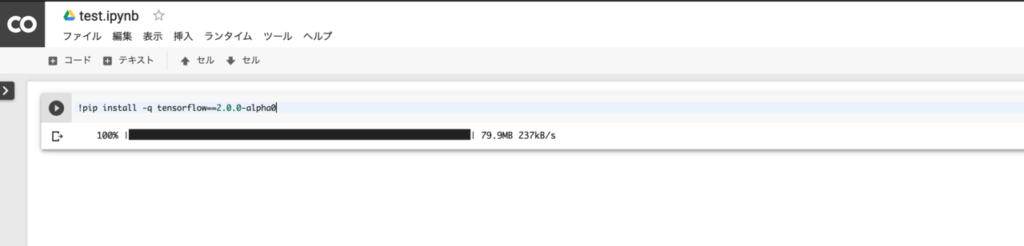
次に、実際にTensorFlow2.0 alphaが読み込まれているかを確認します。
from __future__ import absolute_import, division, print_function
# TensorFlow and tf.keras
import tensorflow as tf
from tensorflow import keras
# Helper libraries
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)
と入力し、出力してみると
と出ます。これが出ていれば無事、tesorflow2.0 alphaがインストールされているとのことです。
Fashion MNIST datasetをダウンロードする
さて、今回は FashionMNIST datasetを利用しますがこのデータセットは機械学習界における最初の一歩『Hello, World』みたいな時に使うようなデータベースとのことです。
中身はこのような感じになっています。![]()
服や靴などの画像データがたくさん入っていますね。
今回はこれらの画像データの判別を行います。fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
TensorFlowはKerasという深層学習ライブラリを利用できます。その中にあるfashion_mnistというデータセットを読み込むようにと指示をしているのが上記のコードです。
このコードを実行するとfashion_mnistの読み込みが始まります。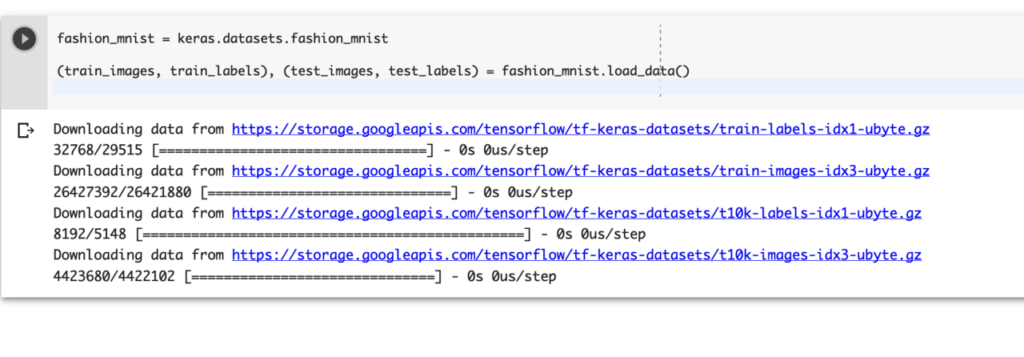
このような状態になっていれば無事データセットを読み込めています。
データセットの内容は60,000枚9種類の様々な服やサンダルの画像となっています。
データセットを確認する
読み込みが完了したら、データセットの中身を確認します。
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
こちらのコードを実行します。これは写真の分類の名前をモデルに定義しているコードになります。結果は出力されないので実行ボタンを押せばOKです。
次に、このコードを読み込みます。
train_images.shape
実行すると
という値が出力されます。
これは60,000種類の画像があり一つ一つが28ピクセル四方だということを示しています。
この段階では機械は60,000種類の写真をそれぞれ共通点を見出しておらず全く違う写真として認識しています。
そのため、len(train_labels)
と入力すると60,000種類の画像があるという意味の出力をします。
train_labels
こちらのコードは出力すると、以下のような出力が返ってきます。
これは、たくさんの種類の画像を機械が認識しているということを意味します。
今回は、その中からtestという種別のデータセットを利用します。
先ほどと全く同様にデータセットの中身を確認してみますと以下のようになります。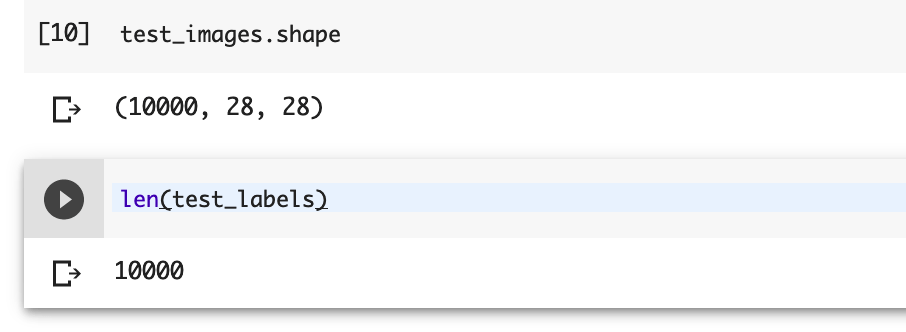
意味は、先ほどと同様の読み方で10,000種類10,000枚の28×28ピクセルの画像がデータとして読み込まれていることになります。
データの前処理
さて、ここまできたら実際に機械に学習をさせていきましょう。
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
plt.show()
こちらのコードを読み込みます。
すると、以下の画像のようにグラフのようになったピクセル画像が表示されます。

この処理は色が濃いところをピクセル単位で確認している処理になります。どのピクセルがどれだけ黒っぽいのか?これを基準に画像を判別するのです。
このグレースケールになっている部分、機械側は255段階のグレースケールで分類しています。この値を計算上0~1にしたいため255で割ってあげます。
train_images = train_images / 255.0
test_images = test_images / 255.0
結果は出力されない状態で大丈夫です。
ここで、最初の25枚のデータを確認しクラス名を確認します。ここでデータが正しいかどうかを確認します。
ここまでくればデータの準備は完了です。
モデルを作る
ニューラルネットワークの基礎は『レイヤー』と言われるものです。
レイヤーは一つの入力されたデータを処理し出力に変換・表現する一単位です。
これを多層に重ねることによってニューラルネットワークは作られています。model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])
こちらのコードにでkeras.layers.Flattenというのが今回の最初のレイヤーです。(カッコの中は読み込む画像についての設定を行なっている値です。)
このレイヤーでは2次元の画像データを一次元のデータに落とし込んでいます。ピクセルが縦横に並んでいるものを横一列に変換したのです。
その後、tf.keras.layers.Denseで脳神経と同じ処理を行います。カッコの中で処理の回数と種類を設定していますが、今回は内容が難しくなるので割愛させて頂きます。
学習の前にモデルに追加するものが三つありますので、以下のコードで追加します。
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
optimizer: モデルの正確性に基づいてモデルをどのように学習させるか方針を決定します
loss: モデルの正確性を測定します。
metrics: モデルのトレーニング状態を監視してエラーを検知します。
上記のコードでこれらの仕組みとその仕組みの種類を指定しているのです。
モデルを学習させる
いよいよ、作成したモデルを学習させます。
model.fit(train_images, train_labels, epochs=5)
このコードを打ち込むことでモデルの学習を開始できます。
コード中のカッコ内では関連づけるデータセットを指定し、学習のシリーズ回数を設定します。
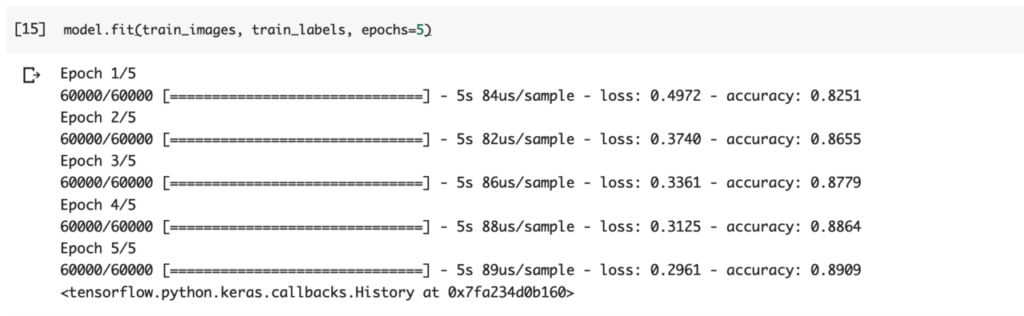
学習が完了すると以上のような出力があります。右端に学習した際のデータの正確性が記載されており、学習のシリーズが上がるに連れて正確性も上がっているのが確認できます。
正確性を確かめる
実際に判別する前にモデルが使えるか?正確性をチェックします。
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('\nTest accuracy:', test_acc)
こちらのコードを実行するとAccuracyがパーセンテージで表示されます。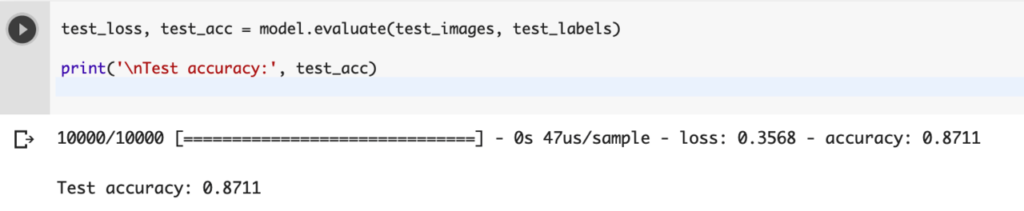
実際に判別させてみる。
さて、ここまできたら最後に実際に判別を行ってみましょう。
plt.imshow(train_images[0])
このコードで一番最初にセットされているイメージデータが表示できます。
この場合は靴のようですね。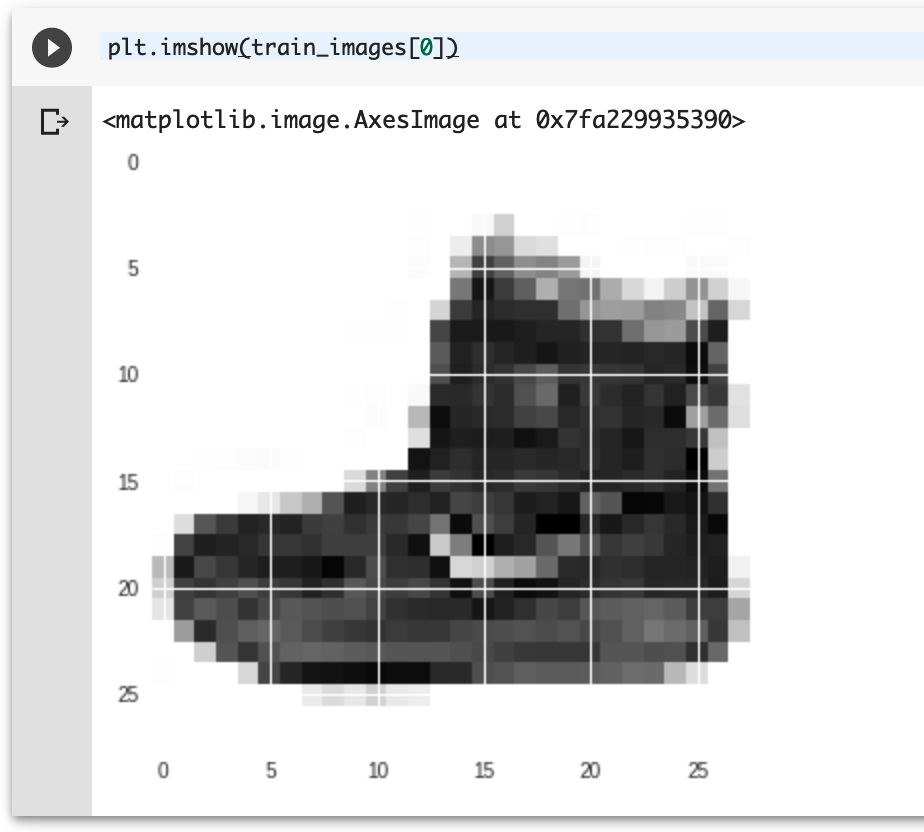
こちらの靴を見分けられるかテストします。
predictions = model.predict(test_images)
を実行したのちに
predictions[0]
を実行します。すると、文字列が出てきます。
この文字列は各種別に対するAIの確からしさです。つまり、この画像に関しては、九番目の種別=uncle bootsの可能性が最も高いということを数値的に示しているのです。
ですが、これ、わかりづらいですよね?
こちらのコードを記述してみましょう。
def plot_image(i, predictions_array, true_label, img):
predictions_array, true_label, img = predictions_array[i],
true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
predictions_array, true_label = predictions_array[i], true_label[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
これを実行したら、次に以下のコードを記述・実行します。
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions, test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions, test_labels)
plt.show()
すると以下のように各種の可能性のグラフが表示されます。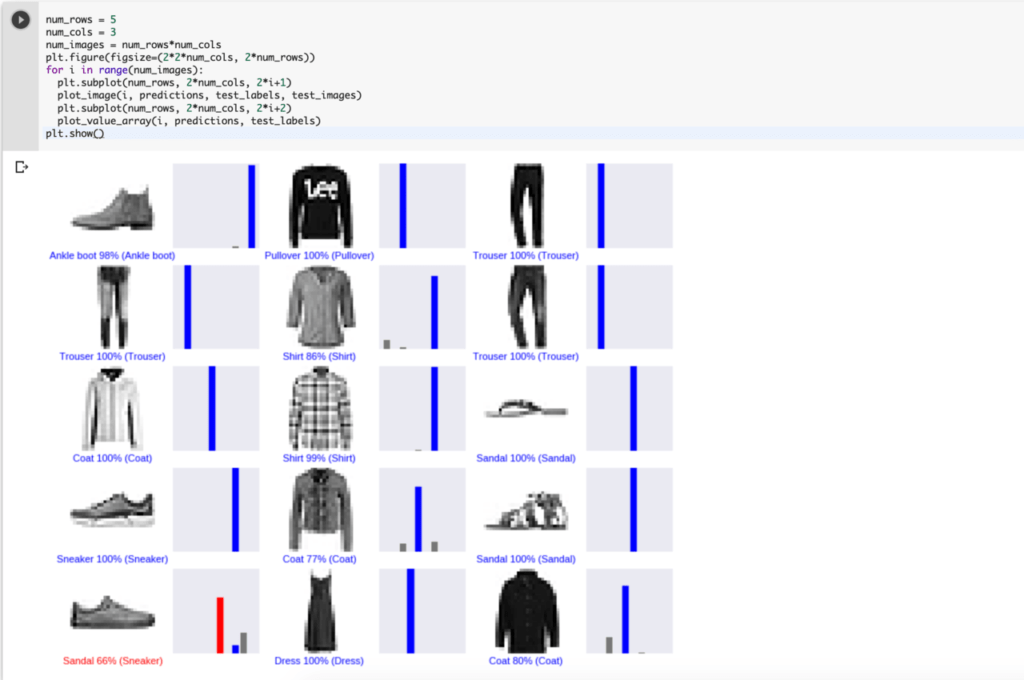
右のグラフは、可能性の数値を表しています。
数値のタグは右から、’T-shirt/top’, ‘Trouser’, ‘Pullover’, ‘Dress’, ‘Coat’, ‘Sandal’, ‘Shirt’, ‘Sneaker’, ‘Bag’, ‘Ankle boot’となっています。
まとめ
いかがでしたでしょうか?
意外と簡単に機械学習を実装することができたかと思います。
機械学習についてはライブラリが準備されたりGoogleColabみたいな簡単なお試し環境などもあり非エンジニアでも検索しながら試しに触ってみるということができるようになってきています。
今回はTesorFlow2.0Alphaが公開されたのでちょうどいい機会として取り組んでみましたが、この内容はGoogleが公式にビギナー向けのチュートリアルとして開設とともに公開している内容です。
エンジニアの世界の一端を覗くためにもぜひこのようなチュートリアルをお試しすることをお勧めします!



この記事に関するカテゴリー






