活用方法は無限大!AIが可能にした世界線
今回は論文を基準とした解説ではなく、技術ベースで記事を書いていますので、少しいつもと違うと思いますが、ぜひお読みください。
これを読まれている多くの方はpose estimation(姿勢推定)という言葉を聞いたことがあると思います。簡単に説明すれば、人がどのような姿勢を取っているかを推定する技術です。みなさんがもっともpose estimationを知ったきっかけにもなったのは、CVPR2017で発表され、多くの人が知ったであろうOpenPoseが有名ですね。今回はそんなpose estimationについて、深ぼっていきたいと思っています。
Pose Estimationの社会的ニーズの広がり
ではなぜ、今回pose estimationについて記事を書いているかというと、近年動画SNSが爆発的に普及し、それに引っ張られるように動画に関する研究も増えています。すなわち、動画データが一般的になってきたとも言えます。さらに、SNSだけではなく、防犯カメラなど、防犯や管理といった観点でも今や当たり前になっています。
そこに対して、顧客行動分析や介護における患者の状態把握、不審な動きをする人の監視などにpose estimationが重要なポイントとなり、一気にビジネス活用を進めた大きな要因に皆さんご存知のDeep learningがとても絡んでいます。
10年くらい前では、tree modelを使用した古典的なものがあり、今では考えられないくらい精度面や活用で多くの課題があり、ビジネス活用は難しいと言われていました。そこから、Deep learningが頭角を現して、一気に精度と活用面の課題が解決されていき、Deep learningが中心となってビジネスを発展させている領域とも言えます。記事にした理由はここになります。そんなビジネスの発展が進むpose estimationについて調べてみました。
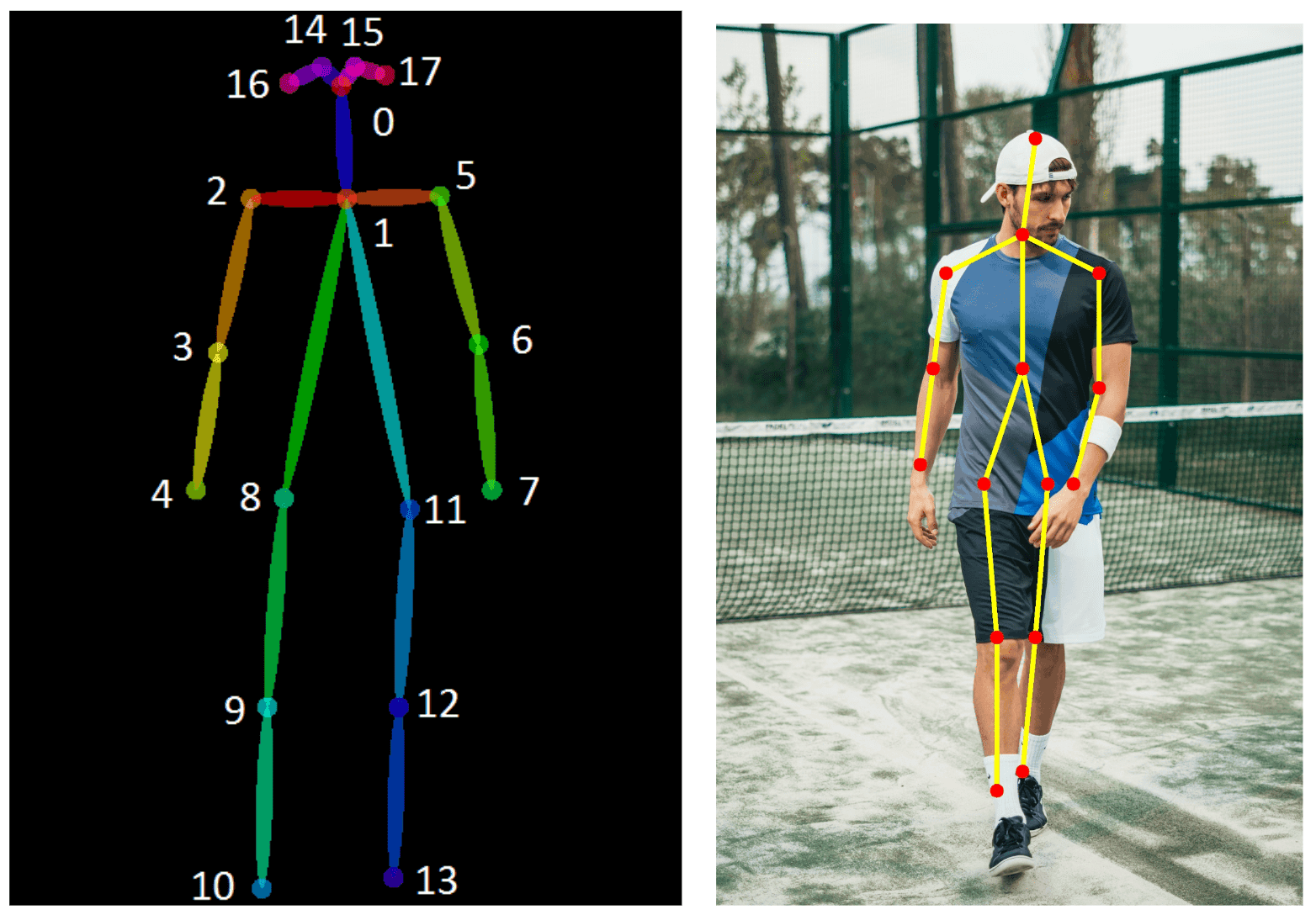
出典:A 2019 guide to Human Pose Estimation with Deep Learning
どんな活用が考えられる?
動画を人がずっと見続けることは不可能です。なので、必ずどこかでシステムによる自動化は必要です。そんな中、なぜ姿勢なのか?動画中には色んなデータが含まれる中で、人を相手にする時点で体の姿勢は統一的に含まれています。そして、人が何をするにも姿勢が重要でした。
そこから人の姿勢、すなわち、行動から新たな付加価値を創出したいというニーズが出てきたのだと思います。
例えば、
スポーツ:選手の動きを分析し、怪我の予防や練習メニューのコーチングに活用したい。
管理:特定の動きをする人を監視する。立入禁止区域に近づいてくる人くらいは従来の技術でもわかりますが、それでは偶然近づいた人も全部トラッキングしてしまい、管理コストを増やすだけの結果になります。そこで、立入禁止区域に意図的に入ろうとする行動をトラッキングすることで無駄なトラッキングを防ぐことも可能となります。
人の行動を分析することでさらなる価値を創出できます。そして、自社サービスに付加価値をつけたり、競合との差別化につなげたりしているということです。
Pose estimationについて
上記で「ビジネスの発展が進むpose estimationについて調べてみました。」と書いています。現在ではあまりにも当たり前となってきており、意外と知られていないpose estimationの技術的な部分について見ていきましょう。
そもそもpose estimationには回帰とヒートマップ検出の2通りがあります。
回帰
人物の画像特徴量から骨格関節位置を座標として直接予測します。回帰の場合は,ピクセル単位で関節位置を予測する必要があるため、ピクセル単位で厳密に位置を特定することが難しいです。
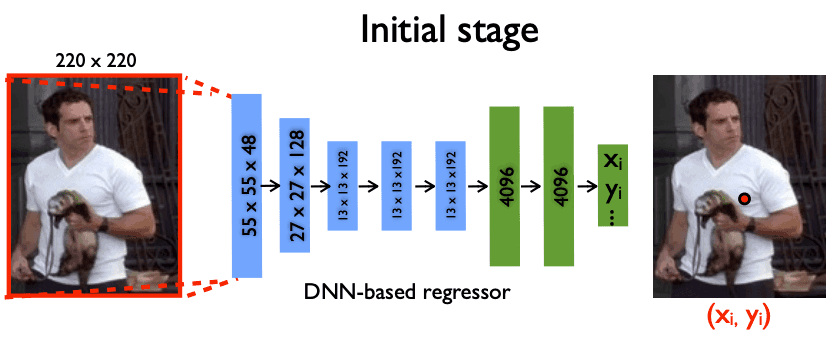
引用:DeepPose: Human Pose Estimation via Deep Neural Networks
ヒートマップ
1ピクセル単位で、部位ごとの関節点の確率を計算する→一定の範囲で位置ズレを許容します。回帰よりは少しのズレを許容するので、現状のpose estimationモデルはこちらの方法が主流となっています。皆さんが比較的触れているモデルもこちらの考えになります。
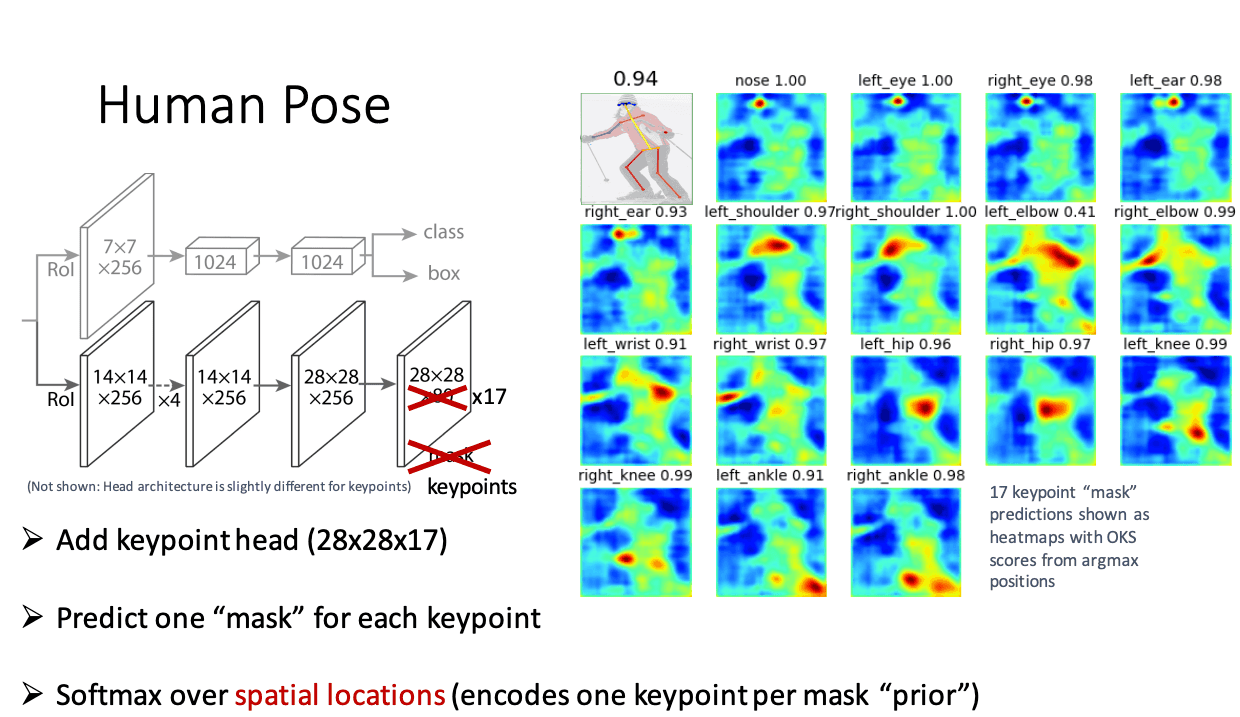
引用:Deep Learning for Instance-level Object Understanding
さらにpose estimationは性質によって、2種類(Top-DownとBottom-Up)に分かれます。
Top-Down
先に人物を検出し、検出した人物に対して骨格座標を予測します。
- 物体検出を行い、人物の特定を行う。
- 検出した人物に対し、骨格点座標を予測する。
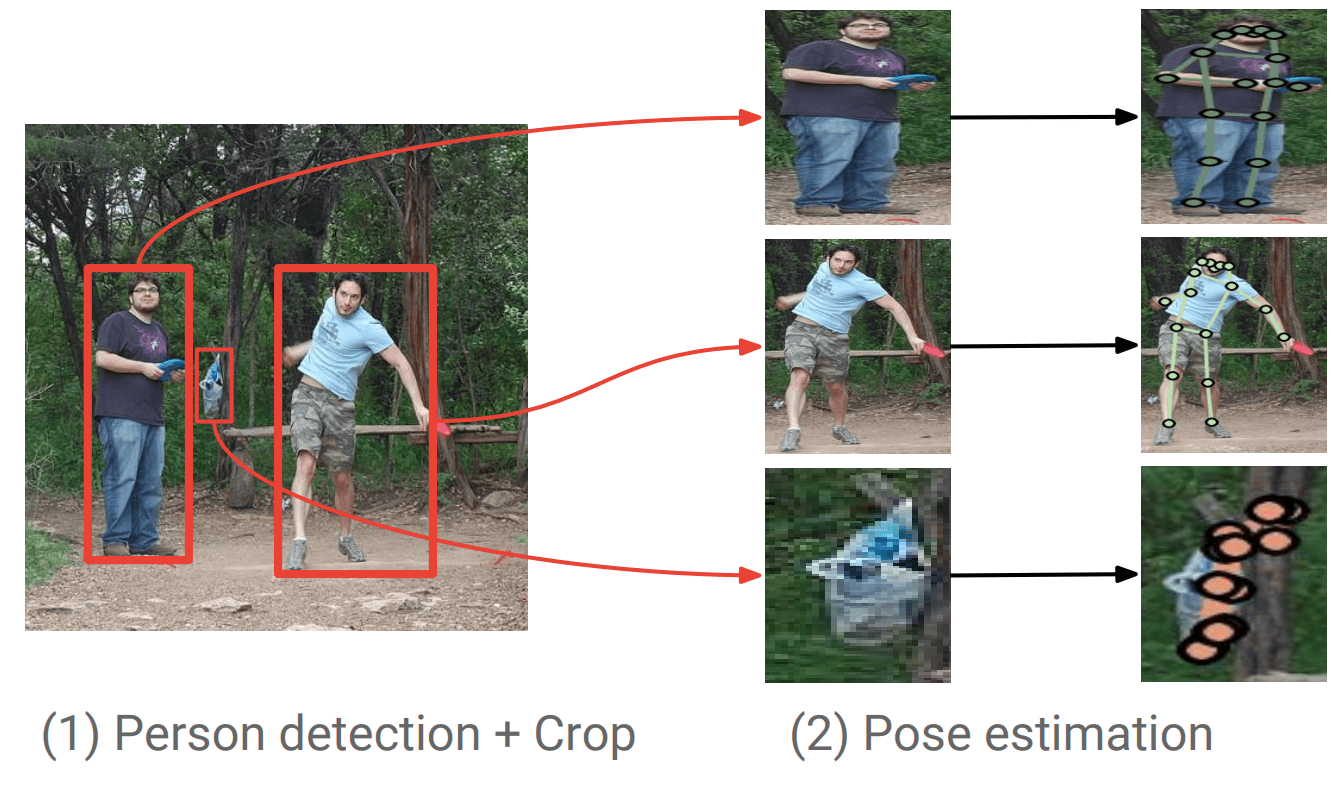
引用:Towards Accurate Multi-person Pose Estimation in the Wild
Bottom-Up
最初に骨格点を一気に検出し、検出した骨格点をグルーピングすることでその人物全体の骨格点とする方法
- 画像から関節点のキーポイント座標のみを検出(対象自体は区別しない)
- 検出したキーポイントを、距離をもとに最適化することで人物ごとにグルーピング

引用:DeepCut: Joint Subset Partition and Labeling for Multi Person Pose Estimation
まとめると...

現在一般的に使われる技術
現状世の中で一般的に使用されているpose estimationのうち、主要なものを紹介する
Top-Down アプローチ
- DeepPose
- Mask R-CNN
- SimpleBaseline
- HRNeT
Bottom-Up アプローチ
- OpenPose
- PoseNet
- Associative Embedding
- HigherHRNeT
実際に聞いてみた
知識やリサーチだけだとわからないので、大手企業の実績や業界的に名前を聞くようになったVisionPoseに注目し,実際に開発を行った株式会社ネクストシステム システム開発部エキスパート/名嘉 洋之さん、システム開発部サブマネージャー/小柳賢二さんに開発された技術についてお話を聞いてみました。
左:システム開発部サブマネージャー/小柳賢二さん, 右:システム開発部エキスパート/名嘉 洋之さん


開発されているVisionPoseってどんなものですか?
VisionPoseは、マーカーレスで人の骨格・姿勢情報が2D/3D解析可能な、弊社独自開発の姿勢推定AIエンジンです。カメラ映像の他、静止画・動画からの推定も可能です。さまざまな開発にご活用いただけるSDK形式と、研究用途にご利用いただける機材一体型のパッケージ形式での提供を行っており、現在は国内大手企業を中心に、シリーズ累計300本以上ご購入いただいています。(2021年11月時点)VisionPose WEBサイト

-これをみる限りでも業種も幅広くて、用途も複数存在しており、最初に述べた社会的ニーズの広がりにも一致しますね。
一般的に使われる技術があるなかで、なぜVisionPoseを開発したのですか?
VisionPose開発のきっかけは2017年10月に当時の主力製品であった、ARサイネージ「Kinesys(キネシス)」に利用していたモーションセンサー付カメラ「Kinect V2」が突然生産中止となり、匹敵する代替カメラが見つからないという事業上の窮地に立たされたことでした。
生産中止に伴いひとまずKinect V2をかき集めた際の写真です。

-まさにpose estimationが出た時ですね。それは困りますね。そして、この写真は笑い事じゃないですが笑えますね。
そこで当社では以前より受託開発などでノウハウを蓄積していた技術分野である「画像認識AI」を応用し、モーションセンサーを必要とせず通常のWEBカメラのみでリアルタイムに人間の動きを検出できるpose estimation技術を独自に開発したことがVisionPose開発のきっかけです。
2017年12月に簡易的なデモをSNSで公開したところ好評を得たことにより、本格的に開発をスタートさせ、約1年の開発を経て2018年11月に製品として販売を開始しました。
VisionPoseの特長は何ですか?
最大30箇所の骨格情報を3D座標で検出でき、SDKだけでなく、すぐに使えるアプリを2種同梱している点が特長です。具体的にはカメラからリアルタイムで骨格情報を検出できる「BodyAndColor」と、動画や画像から骨格情報を検出できる「VP Analyzer」が同梱していますので、開発等に利用しやすくなっています。
また追加学習ができる点も特長です。VisionPoseには、日常生活の一般的な姿勢を認識しやすいように学習させた、弊社の学習済モデルを標準搭載しています。例えばダンスやスポーツなどの特定分野においては追加学習(※)を行うことで解析精度の向上が見込めます。また、精度の向上だけでなく検出ポイントの追加も可能です。※追加学習はオプションサービスです。
さらに、pose estimationには幅広い利用用途が存在する点から、幅広いOSやデバイスに対応しています。リアルタイム処理に優れ、端末コストを抑えつつ省スペースで運用が可能なエッジデバイスにも対応しているため製造現場でも利用しやすくなっている点や、買い切りで商用利用が可能である点も特長と言えます。
-まずは気になったのは、最大30箇所ということで、一般的に提供されているものよりも多いですね。さらに用途に合わせて、追加学習というのもニーズに答えるためには重要ですね。
あとは、海外のpose estimationを活用すると、iOS等のなにかのソリューションについていたりする以外は基本的にはオープンソースか論文が多いです。そうなると自社サービスにpose estimationを組み込むときの不明点や質問などはissue等に投げることが多く、とても大変な作業です。そういった面で日本語サポートがある点も特長といえるかもしれません。
-確かにそうですね。めちゃくちゃ手助けしてくれる人もいますが、基本的にはサポートってところはそこまでないですからね。さらにエッジで完結しているのも圧倒的に強いですね。
Bottom-UpのAIなので、画像に映った人物を一人ずつ解析するのではなく、まず画像全体に映ったキーポイントを対象物の違いを考えずに検出したあと、人物ごとにグルーピングします。そのためカメラ内に映る人数が増えても速度が落ちることがなく、複数人に強いシステムと言えます。
そもそもTop-Downではなく、Bottom-Upを採用した理由はなんですか?
複数人写っている場合でもリアルタイムで動くようにするためです。ユーザーが使用する環境で複数人映るような状況もありFPSが落ちると使いづらいと思ったので、複数人でも速度が低下しないBottom-upにしました。
しかし映る人数が増えても速度が落ちることがないという利点がある反面、グルーピングの精度によって、 複数人の推論の際に、キーポイントが混ざってしまうという課題が存在します。
そこで弊社では多様な複数人のデータを用いて、グルーピング精度を高めるための学習を行っています。
追加学習を自社で行えるのは強みですね。学習する上での苦労などはありましたか?
はい。VisionPoseを開発する際に最初に使用した大規模データセットはキーポイントの数が17ポイントだったのですが、もともと弊社の目的としてはKinect V2の代わりになるものを作ることでしたから、30ポイントに自社学習で増やしています。
この学習については、グリーンバックを背景に弊社の社員をあらゆるポーズ、または角度で約7000枚撮影したあと、さらに背景を合成させたりなどパターンを増やすことで数万枚のデータを作成しました。(精度上げるため&30ポイントに増やすため)その上、これらの画像データ1枚1枚にキーポイント打つという作業を行っており、かなり根気のいる作業でした。
▼(左)学習用のデータ撮影風景(右)ポイントを打つ位置の認識を骨格レベルであわせるアノテーター


ただ弊社には学習を効率化するために「アノテーションツール」という教師データ作成ツールを自社開発していまして、サーバーを立てて複数人で同時に作業できるように環境を作っているので、普通に作業をするより早く学習作業を終えることができたと思います。
教師データ作成ツール『VP ANNOTATION TOOL(アノテーションツール)』紹介動画
学習については、まだまだ改善の余地があると考えていまして、他にも弊社では、教師データの作成を手軽にするアプローチとして、3DCGの人間に様々な環境で色々なポーズをさせて、教師データを作成できるツールを作るなど、作業コストの減少を目指しています。
このような苦労があった一方で、ノウハウが増えたのは良かったですね。
例えば今までは人の教師データだけを学習していましたが、背景と区別できない問題があったため、人がいない状態(背景)を学習させたら精度が上がったりなど、試行錯誤の末に得たものもありました。
今まで提供してきた中でビックリするような活用方法や業界ってありますか?
そうですね、動物やロボットなど人物以外の適用でしょうか。
近年、国内の畜産分野では、労働者の減少・高齢化が進んで深刻な人手不足であるのに対し、農林水産省の補助事業により農場の大規模化が進み、飼育する数は増加傾向にあります。
人手不足の影響で十分な観察時間を割くことができない場合、病気発見の遅れや発情期発見の遅れに繋がるため、労働者の負担を軽減しつつ、生産性を向上させる管理技術が必要です。従来の装着型の機器(ウェアラブルデバイス)では農林水産省のプロジェクト等して、生産効率の向上が実証されつつありますが、導入コストが高額な点や家畜への負担も大きく課題も多くあります。
そのためマーカーレスで且つ、安価に手に入りやすい一般的なカメラでの実現が期待されていました。
そこで弊社では牛や馬など家畜の姿勢をVisionPoseに学習させ、カメラ映像からリアルタイムで複数の家畜の骨格検出に成功しました。取得した骨格データを元に家畜の姿勢や行動を判別することで、家畜の発病を早期に検出したり、発情を表す、他の牛の上に乗りかかる行動(乗駕行動)などを検出することで繁殖期のサポートが期待できます。
-ついに人間以外も来てるんですね。これはリサーチしてもわからないことでした。エッジで活用しやすいというVisionPoseと追加学習という強みがまさに社会的にニーズに適応しているということですね。
いくつか事例を教えてください
追加学習の事例としては、エイベックス・マネジメント株式会社様のダンスのスコア化が可能な自動採点アプリにVisionPoseを活用いただいています。VisionPoseは最大で30ポイントのキーポイントを検出できますが、ダンスを評価する上で「かかと」が大事とのことで、追加学習を行い32ポイントに増やしています。他にも追加学習でラケットやバットの先をキーポイントとして追加したいというお客様にも対応しています。
他の利用用途としては、
スポーツ分野については、ゴルフや野球などフォーム解析にご利用いただいていたりします。フォームの良し悪しを自分で分析し改善することはなかなか難しいことだと思いますが、VisionPoseでフォームの骨格情報を細かく取得し、定量的に評価することでフォーム分析や改善に役立てることができます。
また、一般社団法人Sports Science Laboratory様では少年野球選手の投球障害の関連性を導くことで、ケガを予兆して回避し、コンディションの維持のためにVisionPoseをご利用いただいていますね。
スポーツ以外の領域で言えば、医療リハビリ分野では株式会社トヨタ自動車様で下肢麻痺のリハビリテーション支援を目的としたロボットに弊社の姿勢推定技術を活用されてます。
まだ詳しくはお伝えできませんがエンタメ業界大手の企業様にもご活用いただく予定です。
また自社でも活用しています。スマホカメラに全身を映すだけで3DCGキャラクターに動きを反映できる全身モーションキャプチャアプリ「ミチコンPlus」や、スクワットなどの反復トレーニングの回数をカメラ映像からAIで自動的にカウントできるAIモーションカウンターアプリ「家トレ」、デジタルサイネージの前に立つだけで仮想的に服が試着できるなど、人物の動きと連動した体感型コンテンツを多く搭載する「Kinesys」などさまざまな開発を行っています。
今後どんなアップデートをしていく予定ですか?
今後は、VisionPoseをベースとした新たなサービスの開発も力をいれていく予定です。直近では時系列データによる行動解析を予定しています。
VisionPoseを使用して時系列データを学習させることにより、特定動作を検出させることができるようにしたものです。
例えば、静的データのみで寝姿を見ると「寝ている状態」なのか、「倒れている状態」なのか姿勢だけで判別することは難しいですが、時系列データに対応すると「立ち姿 → 寝姿 = 倒れている」というように因果関係から判断が可能になります。
具体的には、転倒した人、万引き、商品を手にとった、商品を戻した、など今まで姿勢データだけだと分からなかった新たな情報が手に入ります。これらの技術を活用することで小売店や工場現場、医療施設、介護・保育施設などさまざまな現場での行動解析を行えるようになります。
また、VisionPoseは2021年の11月より海外向けにECサイトをOPENしました。より幅広いお客様にご利用いただくことでノウハウを蓄積し、皆様により良いサービスをお届けできるよう、誠心誠意取り組んでまいります。
企業紹介
株式会社ネクストシステムは「夢を現実に、未来を創る」を合言葉に、姿勢推定AIエンジン「VisionPose」やARサイネージ「Kinesys」の開発・販売をはじめ、AIによる行動解析、xR(AR/VR/MR)を利用した最先端システムの研究開発などを行うソフトウェア開発会社です。
ネクストシステムWEBサイト
Twitter
Facebook
Youtube
Website



この記事に関するカテゴリー





