訓練データ分布の"外側"の生成!?State of the ArtのGAN「COCO-GAN」
※本記事は、2019年5月15日に配信された記事と同じ論文を題材にしておりますが、全く違うライターが執筆しております。
該当記事: 座標系に基づきマイクロパッチからイメージを結合していくGANが登場
3つの要点
✔️訓練データに存在しない画像の生成。その名も外挿
✔️現時点で世界で最も高精細な画像を生成可能なGAN
✔️画像をパッチごとに生成することで計算量を削減
概要
GANにはある一つの限界があるとされていました。それは、訓練データにない画像の生成は不可能であると。
この訓練データの生成分布(訓練データがサンプリングされると仮定される分布)の外側の生成を外挿 (Extrapolation)といいます。
しかし、今回紹介するCOCO-GANではこの不可能を可能にする結果を一つ示しました。
結果はそれだけではありません。
現在GANはProgressive GAN (PGGAN)やBigGANといった現実の画像と見分けがつかないほど高精細な画像の生成が可能となってきました。
しかし、これらのGANは高精細の画像を生成できる反面、画像の生成にも時間が掛かる上訓練にも非常に長い時間※1が必要です。
COCO-GANはパッチごと(分割してバラバラにしたもの)に生成するという斬新なアプローチを取ることで訓練時間や生成時間を短縮しています。
さらに、COCO-GANは現時点で世界で最も高精細な画像を生成するGANでもあります。
恐ろしいことに、COCO-GANの提案手法は非常に単純ですが威力はとても大きく、この発想だけで外挿、SOTA (State of the Art)、計算量削減、パノラマ画像生成の4つ達成してしまいました。
それでは見ていきましょう。
※1 Progressive GANの訓練にはNVIDIAの現在最も高速に処理が可能なGPUであるTesla V100を1台用いて2週間掛かります(解像度が1024×1024のCelebA-HQというデータセットの場合)
本論文のメインアイデアと貢献
メインアイデア
本論文のメインアイデアはシンプルに一つです。下に提案手法の図を示します。
画像をパッチごとに分割して生成する
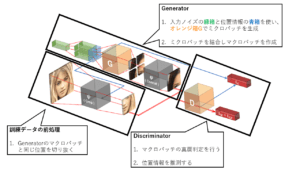
今までのGANと違う点は画像全体を一度に生成してしまうのではなく、ミクロパッチごとに生成して合成してマクロパッチを作成し、マクロパッチごとでのGANの訓練を行う点です。
最終的に全体の画像を生成することは訓練中は一度もなく、テストの段階のみに以下の図のようにミクロパッチを画像全体分生成して合成します。

貢献
本論文の貢献は4つあります。
- 訓練データの生成分布の外側の生成である”外挿”を可能にした
- CelebA、LSUN bedroomの2つのデータセットにおいてSOTAを達成
- Generatorがパッチごとの生成により縮小化し、計算量とパラメータ数の削減
- パノラマの画像を特殊は処理なしで生成可能にした
外挿については実験結果を見ることで直感的なものとなります。
貢献3についてはパッチごとに生成するので、計算量とパラメータ数が少ないのは明らかなのか本文中で詳しい議論や実験は行われていません。
それでは論文の実験結果を見ていきましょう。
実験結果
今回紹介する実験結果は3つあります。1つ目が貢献1について、2つ目が貢献2について、3つ目が貢献4についての実験結果となっています。
実験結果1:訓練データの外側の生成、”外挿”を行う

上図は生成されたベッドルームの画像であり、とても高精細な画像が生成されていることが確認できます。
しかし、驚くのは高精細さだけではありません。この画像はある大きな画像から切り抜かれた一部なのです。
以下に本来の生成されている画像を示します。

上図の赤枠の中が切り抜かれた部分です。本来は上図のように解像度が384×384の画像です (切り抜かれている部分は訓練データと同様の解像度256×256)。
著者らはこの画像の外側の境界を超えた訓練データ外の生成を Beyond-Boundary Generationという名前で提案しています。
このように訓練データに存在しない部分を生成可能になるということは生半可なことではありません※3。
Generatorは訓練データ分布に獲得する分布が近づくように訓練が進みます。なので、訓練データ分布外の分布を獲得するということは訓練データのバイアスに縛られることなく、かつ生成データの整合性は取りながら学習を行えるということです※2。
この結果はGANにおける大きなブレイクスルーと成り得る可能性があります。
※2 人間は草原にいる犬と家の中にいる猫を別々に見た際、犬と猫が同時に草原にいるところを想像できます。これは我々は訓練データ(今回は犬と猫)のバイアスに縛られることなく、かつ整合性を取りながら想像できるので可能なことです。GANでもこれと同様のことが出来るかもしれないことを示唆しています。
※3 そのままパッチごとに訓練しただけではやや外側が不自然になるので、著者らはAppendix E (論文の本文の後の付録)にて外側を自然にするテクニックを記述しています。
実験結果2:GANにおいて世界で最も高精細な画像を生成

上図は生成されたセレブの画像です (CelebA)。とても高精細な生成が行えていることがはっきりとわかります。定性的に高精細なのは明らかですが、定量的にもSOTAを達成しています。
以下に定量評価を行っている表を示します。
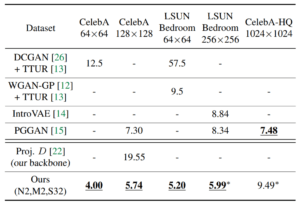
評価指標はFID (Fréchet Inception Distance) と呼ばれる訓練データと生成画像との分布間距離 (どれだけ生成画像が訓練データに近いか)を比較しています。
COCO-GANはCelebA-HQ以外のデータセットにおいてSOTAを達成しています※4。
この結果はパッチごとの生成する次元が小さい(4×4の場合は16次元、256×256の場合は65,536次元)ので探索が行いやすく、かつ隣のパッチとの整合性を取らなくてはいけないという幾何的な制約があるので、最適化しやすいのだと考えられます※5。
※4 アスタリスク (*) が付いているものは訓練が収束していないので、まだポテンシャルを残していると著者らは主張しています。ICCVのoralですが、検証している項目といい少し実験が甘いのではないのだろうかと思ってしまいます。
※5 このSOTAの結果に対しての深い考察は全く論文中でされていないので、この考察については本記事の執筆者独自の考察です。
実験結果3:パノラマ画像の生成

上図はパノラマ画像を720°まで拡張させたときの生成結果です。360°以上何も変わっていないように見えるので、この実験は一体なんなんだ?と思うかもしれません。
通常のGANでは画像が循環している (一周回ってもう一度一周回っても同じ風景がある) ということは学習できません。それゆえ、通常のGANでパノラマ画像を循環させて生成する際には特殊な処理が必要になってきます。
しかし、COCO-GANでは位置情報を角度 (sinとcos) で表すことで循環性を獲得することが可能になっています。
これが出来るようになって何が嬉しいかというとVRなどでは限られた計算資源の中で高解像度な視界の生成が要求されます。そこで、COCO-GANを使うことで循環性を保持しつつ少ない計算量で視界の生成が可能となると著者らは使い道について言及しています。
結論
本論文はGANにおいてパッチごとの学習を行うことで外挿、SOTA、計算量削減、パノラマ画像生成を可能にする手法を提案しました。GANにおいてデータセットのバイアスに縛られるので外挿は難しいという論文がICLR2020に投稿されたばかりなのに、外挿を成し遂げられた論文としてとても大きな貢献があります。
今後はGANの汎化への道しるべとなることが大いに期待されます。
ディープラーニングは限界と噂されることに絶望している暇など我々にはもうないかもしれません。
COCO-GAN: Generation by Parts via Conditional Coordinating
(Submitted on Mar 2019 in Proc of ICCV)
written by Chieh Hubert Lin, Chia-Che Chang, Yu-Sheng Chen, Da-Cheng Juan, Wei Wei and Hwann-Tzong Chen.
accepted by the International Conference on Computer Vision, ICCV 2019




この記事に関するカテゴリー






