座標系に基づきマイクロパッチからイメージを結合していくGANが登場
論文:COCO-GAN: Generation by Parts via Conditional Coordinating
現在の最先端の生成モデルでは、大規模な画像データを扱う研究が盛んです。これらのモデルは空間次元が大きいだけでなく、多数のパラメータを持ちます。ここ数年、合成画像の解像度は毎年ほぼ2倍になっており、より大きなバッチサイズがGANにとって非常にいい影響を与えていることが分かっています。しかし、技術的に克服するのが難しい問題としてメモリー予算の限界があります。
一方、人間は、生物学的制限のため周囲の環境の一部としか相互作用できません。そのため環境の一部を観察し見解の一部をまとめ、それらの空間的関係を推論することを学びます。論文では、このような人間の能力に触発され、条件として与えられた空間座標系に基づいて、パーツ(マイクロパッチ)を再構成するGANモデルを提案しています。
画像の一部のみから、潜像ベクトルを推定し、いくつかのマイクロパッチの特性を局所的に保持しながら結合し、フルイメージに近づけていくというものです。
GAN(COCO-GAN)
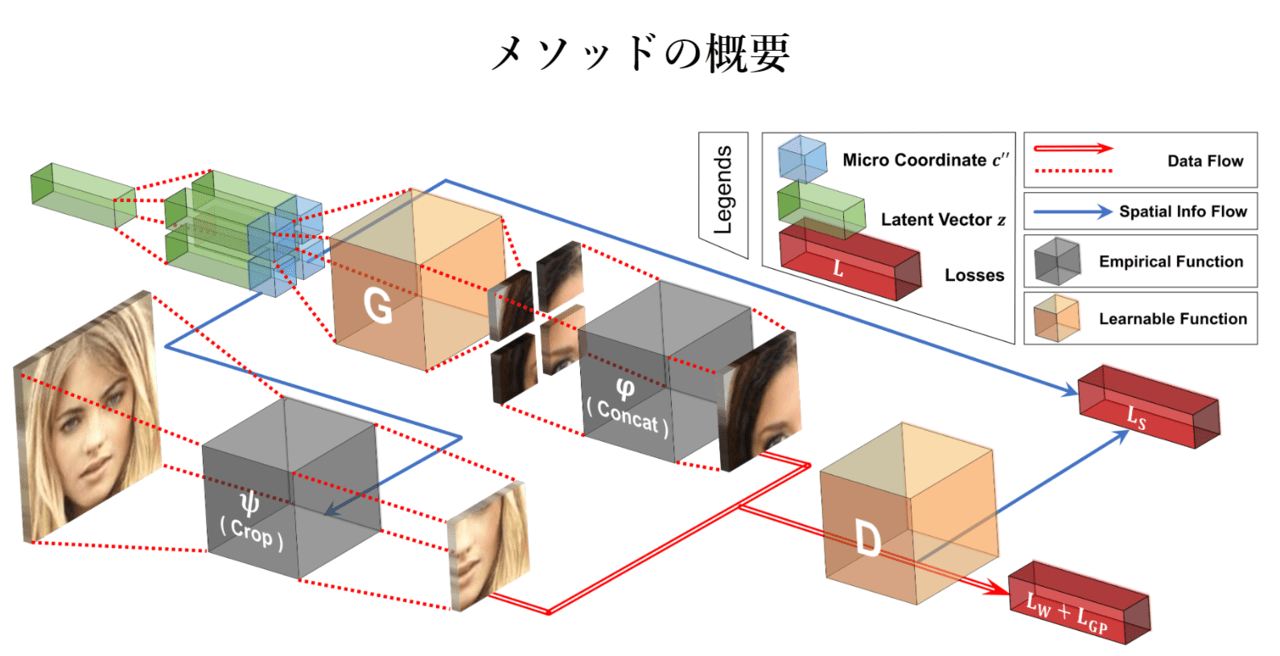
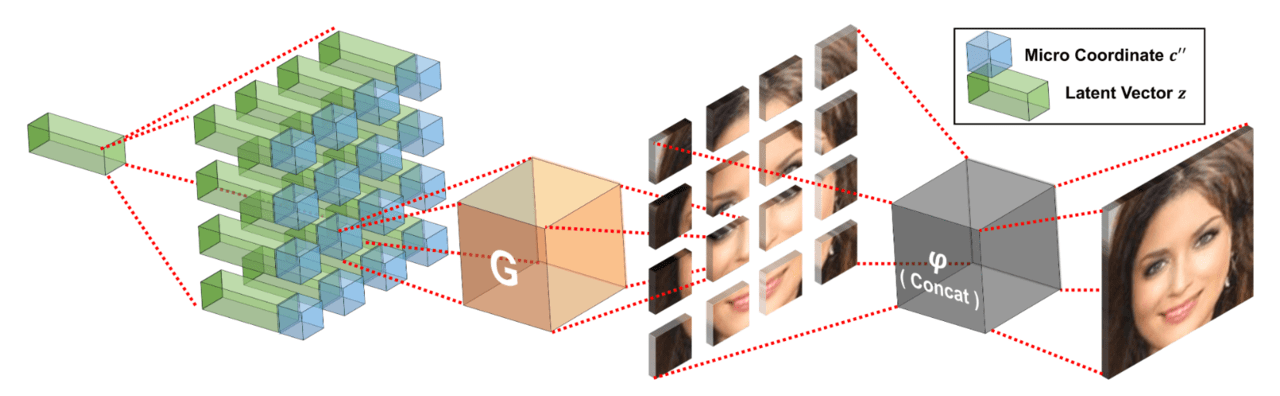
潜在変数が数回複製されるとマイクロ座標系と連結され、それらが生成器に供給されマクロパッチが生成されます。複数の生成されたマクロパッチは後でより大きな(しかしフルイメージよりはまだ小さい)マクロパッチを形成するために一緒に結合されます。このように繰り返し複数のマイクロパッチを連結して、より大きなマクロパッチを形成していきます。
一方、識別器は、実際のマクロパッチと偽のマクロパッチとの間の識別、また、マクロパッチの座標系を予測する補助的なタスクの識別を学習します
テスト段階では、生成器によって生成されたマイクロパッチは、最終的な出力としてフルイメージに直接結合されます。生成された画像は、単純な連結に加えていかなる後処理も加えていません。さらに、COCO-GANを使用すると、メモリ使用量は、フルイメージ解像度ではなく、マイクロのパッチサイズに関連するようになります。
フルイメージではなくビューが限定されているため、生成器が現実的なマクロパッチを生成する唯一の方法は、すべての座標にわたって共有される潜在ベクトルからの情報を利用することです。さらに、隣接するマイクロパッチと完全に一致するパッチを作成しなければなりません。そのため生成器は同じ潜在変数を共有するマイクロパッチ間の空間的関係を学習します。
GANはなぜ動くの
生成的モデリングは通常、潜在空間から画像空間へのマッピングをすることを目的としています。COCO-GANの場合、潜在変数が潜在空間からサンプリングされると、対応する画像が暗黙的に選択されます。しかし、COCO-GANは、従来のGANのように画像を直接生成することはせず、代わりに、条件として与えられた座標系を考慮して、画像のどの部分を生成してグラデーションを取得するかを選択します。
このように潜在変数からの画像マッピングは間接的な方法で構築されます。
次の図では、CelebAデータセットでフルパッチ解像度128 x 128のマイクロパッチを4 x 4ピクセルに設定しています。言い換えれば、フル画像は1024個のマイクロパッチで組み合わされています。このように非常に制限されたパッチサイズから視覚的にもっともらしいフルイメージを構成することができます。


COCO-GANは柔軟な座標系ベースのフレームワークであると考えると、パノラマに適した円柱座標系など、任意の座標系にフレームワークを簡単に適応させることができます。
例えば、以下のように円柱座標系を適用したCOCO-GANによって綺麗なパノラマを生成することができます。




この記事に関するカテゴリー






