HyperCLOVAの紹介:韓国GPT-3
3つの要点
✔️ HyperCLOVAと呼ばれる韓国語のGPT3規模の言語モデル
✔️ 様々なサイズのHyperCLOVAを様々なNLPタスクで実験
✔️ HyperCLOVAが提供するサービスを配布するためのプラットフォームであるHyperCLOVA Studio
What Changes Can Large-scale Language Models Bring? Intensive Study on HyperCLOVA: Billions-scale Korean Generative Pretrained Transformers
written by Boseop Kim, HyoungSeok Kim, Sang-Woo Lee, Gichang Lee, Donghyun Kwak, Dong Hyeon Jeon, Sunghyun Park, Sungju Kim, Seonhoon Kim, Dongpil Seo, Heungsub Lee, Minyoung Jeong, Sungjae Lee, Minsub Kim, Suk Hyun Ko, Seokhun Kim, Taeyong Park, Jinuk Kim, Soyoung Kang, Na-Hyeon Ryu, Kang Min Yoo, Minsuk Chang, Soobin Suh, Sookyo In, Jinseong Park, Kyungduk Kim, Hiun Kim, Jisu Jeong, Yong Goo Yeo, Donghoon Ham, Dongju Park, Min Young Lee, Jaewook Kang, Inho Kang, Jung-Woo Ha, Woomyoung Park, Nako Sung
(Submitted on 10 Sep 2021)
Comments: Accepted to EMNLP2021.
Subjects: Computation and Language (cs.CL)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめ
GPT-3は、大規模かつ強力な言語モデルであり、AIコミュニティの内外から大きな注目を集めています。GPT-3は、in-context information(タスクの説明と数ショットの例からなる離散的なプロンプト)を用いて、対象タスクの予測を推論します。しかし、まだいくつかの課題があると考えています。GPT-3の学習データは、英語に大きく偏っており(92.7%)、他の言語への適用やテストが困難です。そこで、HyperCLOVAという韓国語のin-context大規模モデルを学習します。現在、13Bまでのパラメータを持つモデル、GPT-3は175Bのパラメータを持つモデルがありますが、13〜175Bの間のモデルの徹底的な分析は存在しません。そこで、39B、82Bのモデルも学習させて、ミッドレンジ(比較的)のモデルでも解析ができるようにしています。また、言語固有のトークン化の効果や、HyperCLOVAのゼロショット、数ショット機能などを調査します。最後に、大規模言語モデル上で入力の後方勾配を必要とする高度なプロンプトベースの学習法を実験します。
HyperCLOVA
データセットとモデルの学習
GPT-3の学習データは、文字数ベースでわずか0.02%の韓国語データで構成されています。そこで、ユーザーが作成したコンテンツや外部のパートナーが提供したコンテンツなど、インターネット上の大規模な学習データを構築しました。その結果、約561Bトークンの韓国語データが得られました。GPT-3と同じアーキテクチャを採用し、以下のような構成をとっています。中規模モデルの分析が重要な理由は、中規模モデルについては研究が行われていないにもかかわらず、実際のアプリケーションにとってより妥当なサイズであるためです。
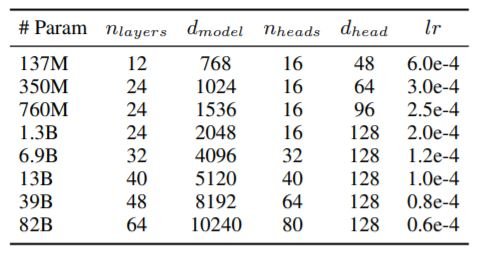
Megatron-LMを使用し、1,024個のA100 GPUを搭載した128台の強力にクラスタ化されたDGXサーバを含むNVIDIA Superpod上でモデルを学習しました。最適化器としてコサイン学習率とweight decayを用い、ミニバッチサイズを1024としたAdamWを使用しています。
Korean Tokenization
韓国語は、名詞の後に助詞が続き、動詞や形容詞の語幹の後に語尾が続き、様々な文法的性質を表す膠着語です。韓国語に英語のようなトークン化を用いると、韓国語の言語モデルの性能が低下することがわかっています。そこで、形態素を考慮したバイトレベルのBPEをトークン化手法として使用しています。
韓国語の言語的特徴を考慮したKorQuADと2つのAI Hub翻訳タスクで、我々のトークン化手法をテストしました。また、韓国語のトークン化に広く使われているbyte-level BPEやchar-level BPEのトークン化と比較しました。charレベルのトークン化では、out-of-vocabulary(OOV)が発生したり、韓国語の文字が省略されたりすることがあります。韓国語から英語への翻訳において、形態素解析器が性能を低下させることを除けば、他のすべてのタスクにおいて、我々の手法はバイトレベルBPEやチャーレベルBPEよりも優れています。これは、大規模言語モデルにおける言語固有のトークン化の重要性を示しています。
実験と評価
モデル評価には、5つの異なるデータセットを使用。NSMCは映画レビューのデータセット、KorQuAD 1.0は韓国語の機械読解のデータセット、AI Hub Korean-English corpusは様々なソースから集めた韓英の並列文、YNATは7つのクラスからなるトピック分類問題、KLUE-STSは文の類似性予測のデータセットです。
In-Context Few-Shot Learning
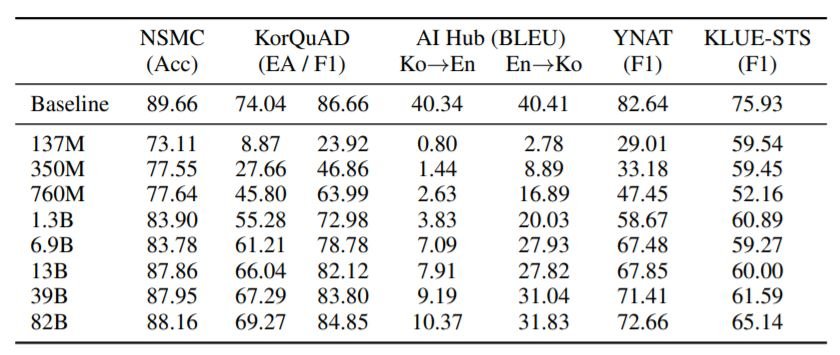
上の表は様々なin-context learningタスクでの結果を示しています。予想通り、モデルサイズが大きくなるにつれて、性能は単調に向上しています。しかし、KLUE-STSや翻訳タスクでは、ベースラインよりもはるかに低い性能となっています。今後、より洗練されたプロンプトエンジニアリングにより、これらの結果が改善されることを期待しています。
Prompt-Based Tuning (p-tuning)
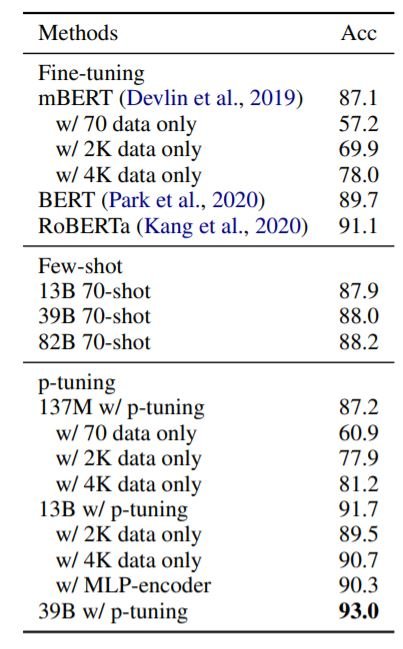
上の表は、NSMCにおけるp-tuningの結果を示しています。p-tuningによって、HyperCLOVAは、モデルのパラメータに変更を加えることなく、他のすべてのモデルを上回ることができます。わずか4Kのインスタンスを用いたp-tuningは、150Kのインスタンスを用いてfine-tuningしたRoBERTaを十分に上回ることができます。
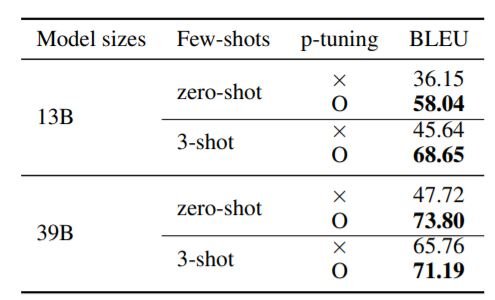
上の表は、p-tuningが、内部で行ったクエリの変更において、ゼロショットおよび3ショットのパフォーマンスを大幅に改善したことを示しています。これは、GPT3スケールモデルの入力データの後方勾配にアクセスすることで、タスクに対するモデルの表現力を向上させることができることを示唆しています。これは、GPT3スケールのモデルを学習するためのリソースを持たない研究者にとって、非常に有益なことです。
HyperCLOVA Studio
この強力なモデルを配布するために、HyperCLOVA Studioを紹介します。HyperCLOVA Studioは、HyperCLOVAによって生成された共有成果物を構築し、コミュニケーションするための場所です。これにより、AIエンジニアの関与を最小限に抑えながら、AIサービスのラピッドプロトタイピングを行うことができます。次に、HyperCLOVAのいくつかのユースケースシナリオについて説明します。

キャラクターボット:HyperCLOVAでは、数行の説明文といくつかのダイアログ例だけで特定の個性を持ったChatBOTを作成できることがわかりました。上の画像(a)はその一例です(プロンプトはイタリック、出力は通常のフォント)。
ゼロショットの転送データ増強:ここでの目的は、ユーザーの意図に合わせて発話を行うことです。例えば、「一人で予約問い合わせ」という意図に対して、「一人で予約しても大丈夫ですか」といった文章を出力します。意図の内容は様々で、「予約の問い合わせ」のような短いものでも構いません。
イベントタイトルの生成:HyperCLOVAは、イベントタイトルの生成タスクに非常に有効です。例:商品のプロモーションイベントの場合、イベントの日付とキーワードを含む5つの商品例をプロンプトとして受け取り、適切なイベント名(Jewelry for you who shinesely shinesely)を出力します。また、HyperCLOVAは、広告の見出しを生成するタスクのように、他のドメインにも最小限の労力で適応することができます。
これら以外にも、HyperCLOVAは入力勾配APIを提供しており、p-tuningを使ってローカルな下流タスクのパフォーマンスを向上させるのに役立ちます。また、HyperCLOVAの誤用を防ぐために、入力と出力のフィルターを提供しています。
HyperCLOVAのような大規模モデルは、NLP運用のライフサイクルを加速する上で有益であると考えています。MLシステムの開発と監視は反復的なプロセスであり、現在は専門家が特定のタスクを何度も行う必要があります。これはコストがかかり、企業が自社製品とAIを統合する妨げになっています。現状では課題となっていますが、HyperCLOVAはLow/No Code AIのパラダイムに役立ち、専門家でなくても開発が可能になることで、MLシステムの開発コストを根本的に削減することができます。
まとめ
本稿では、言語固有のトークン化、p-tuningなどの重要性を強調することで、言語固有の大規模モデルを開発するための貴重な洞察を与えています。HyperCLOVA(Studio)の背景にある目的は、非専門家が独自のAIモデルを構築できるようにすることで、韓国におけるAIの開発を民主化することです。同時に、これらのモデルの誤用、公平性、バイアスなどの問題を認識し、良い方向に向かうように常に努力することが必要です。





この記事に関するカテゴリー






