
GANとどう違う?君は画像生成モデルNeRFを知っているか。
3つの要点
✔️ NeRFとは新規視点の画像生成ネットワークである。
✔️ NeRFの入力は、5次元(空間座標のx,y,zと視点のθ,φ)で、出力は体積密度(≒透明感)と放射輝度(≒RGBカラー)である。
✔️ NeRFによって従来よりも複雑な形状を持つ対象物の新規視点画像を得ることに成功した。
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
written by Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, Ren Ng
(Submitted on 19 Mar 2020 (v1), last revised 3 Aug 2020 (this version, v2))
Comments: ECCV 2020
Subjects: Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
概要
まず「新規視点画像生成」を知るために下のアニメーションを見てください。


上のアニメーションは、NeRFによって生成されたものです。新規視点とはカメラの位置であり、新規視点画像生成とは「ある位置から対象物を見るとどんな画像を得られるか」の答えです。
最も簡単に上のアニメーションを作る方法は、カメラを動かしながら連続で撮影することです(動画と同じですね)。つまり少しずつ視点を変えながら対象物を連続で撮影することによって、立体的に眺めているように見えるわけです。ところがNeRFでは、極論すると正面、側面、背面の3視点から撮影するだけで、その間にある「斜め前」や「斜め後ろ」という「撮影していない視点」からの画像を得ることが可能になります。これが新規視点(novel view)の画像生成ということです。
はじめに
本研究では、ニューラルネットワークを用いて画像表現のパラメータを最適化することで、視点合成(view synthesis)における長年の問題に取り組んでいます。
著者らは、静的なシーン(static scene)を連続な5次元の関数として表しており、その関数は空間内の各点(x, y, z)における放射輝度(方向θ, φを持つ)と密度(density)を出力します。この関数は、各点を通過する光線がどれだけ輝度を蓄えているか(つまりどれくらい明るいのか)を制御する微分不透明度(differential opacity)のように働きます。
本手法では、畳み込み層をもたないMultilayer perceptron(MLP)を使った回帰によって、5次元の変数(x, y, z, θ, φ)から体積密度(volume density)とRGBカラーに変換します。
なお「3つの要点」では、「体積密度(≒透明感)」、「放射輝度(≒RGBカラー)」と書きましたが正確ではありません。体積密度とはレンダリング時に必要な変数であり、物体を通過する光の拡散、反射等を制御します。単純化して透明感と書きましたが、光と相互作用する要素と考えてください。そして放射輝度(emitted radiance)もまたRGBカラーとイコールではなく、物体表面のある点から出射される光(その点自身が光源となる光と、周囲から入った光の反射光あるいは透過光の和)を指しており、あくまでレンダリングに必要な変数として理解してください。
回帰の出力であるnerural radiance field(NeRF)を得るために、本研究では以下のように実験を行いました。
- 空間内でカメラを様々な位置に動かして、カメラの座標を記録する。
- 上記のカメラ位置と、それに伴う視線の方向をニューラルネットワークへの入力とする。またその位置からの画像を出力(教師)とする。
- なお色と輝度から2次元画像を生成する過程には古典的なボリュームレンダリングを用いる。この手法は微分可能であるのでニューラルネットワークによって最適化できる。
このような手順によって、実際に観測画像と出力結果の差分を最小化することで、モデルは最適化されます。以下にプロトコルの流れを示します。
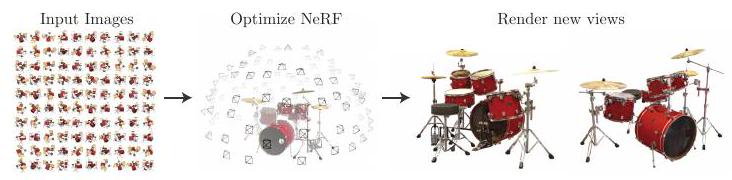
関連研究
本分野の最近の有望な方向性として、MLPを用いたシーンの符号化がありますが、複雑な形状をもつリアルなシーンを再現することはできていませんでした。画像(2次元)ではなく、3次元形状の表現に関する研究では、ShapeNetが知られていますが、そもそも教師データを揃えることが困難であり、研究の障壁となっています。
その後、微分可能なレンダリング関数を定式化することで2次元画像のみで3次元のニューラル陰形状表現(neural implicit shape representation)を最適化できるようになりました。Niemeyerらは、物体表面を3次元的専有場(occupancy field)とみなし、数値的(numerical)な手法により各光線の表面交差を求め、陰関数微分(implicit differentiation)により厳密に計算しました。そして各光線の交点の位置は、その点の拡散色(diffuse color)を予測するneural 3D textureへの入力として使われます。Sitzmannらは、neural 3D textureを用いて、連続3D座標における特徴ベクトルとRGBカラーを出力する微分可能なレンダリング関数を提案しました。
Neural Radiance Field Scene Representation
著者らは連続的シーンを5次元のベクトル値関数として表現しており、その入力は座標(x, y, z)と視線(θ, φ)であり、出力は色(r, g, b)と体積密度σです。
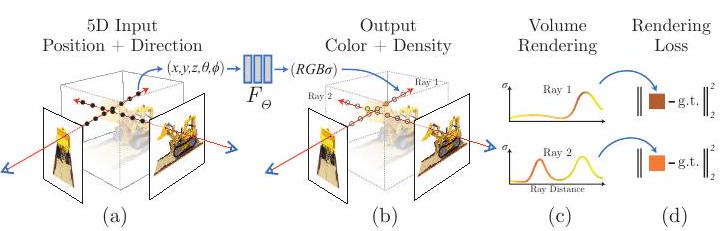
上図は、NeRFによるシーン表現と微分可能レンダリングの概要図です。5次元の入力(位置と視線)により、カメラ光線(camera ray、図中では目と赤色の矢印で表現)に沿った画像を合成しています。5変数(x, y, z, θ, φ)がMLP(F_Θ)に入力され、RGBカラーと体積密度を出力します(R, G, B, σ)。
Radiance Fieldによるボリュームレンダリング
体積密度σ(x)は、1つの光線が無限小の粒子が点xで終わる微分確率と解釈することができます。
$$C(\mathbf{r})=\int_{t_{n}}^{t_{f}} T(t) \sigma(\mathbf{r}(t)) \mathbf{c}(\mathbf{r}(t), \mathbf{d}) d t, \text { where } T(t)=\exp \left(-\int_{t_{n}}^{t} \sigma(\mathbf{r}(s)) d s\right)$$
C(r)は、近位t_nと遠位t_fをもつカメラ光線r(t)の予測される色です。関数T(t)は、光線が他の粒子とぶつからずにt_nからt_fまでに移動する確率を光線に沿った累積透過率で表しています。連続的なNeRF(neural radiance field)からビューをレンダリングするためには目的の仮想カメラが通過する各ピクセルについて積分しなければなりません。
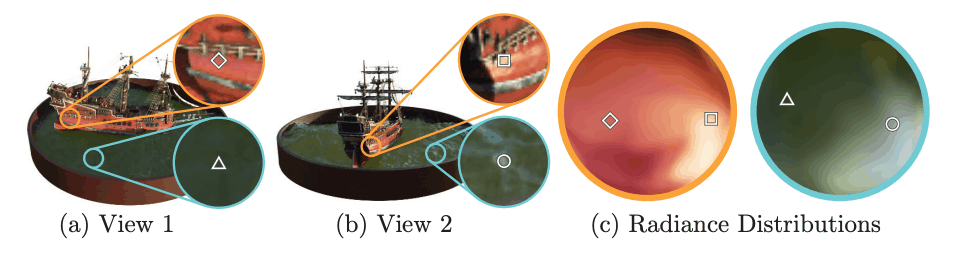
上図は、同一点でも視点が変わると色が変わっているという一例です。NeRFでは色は放射輝度と視線方向によって定まります。したがって同一座標でも視線が変わると色が変化します。
Neural Radiance Fieldの最適化
前節でレンダリングについて説明しましたが、実際にはそれだけではSOTA(state-of-the-art、最高品質)を達成することができません。前節では、xyzθφをネットワークF_Θに入力していましたが、これを以下の合成関数で置き換えます。
$$F_{\Theta}=F_{\Theta}^{\prime} \circ \gamma$$
F'_Θは、多層パーセプトロンです。
$$\gamma(p)=\left(\sin \left(2^{0} \pi p\right), \cos \left(2^{0} \pi p\right), \cdots, \sin \left(2^{L-1} \pi p\right), \cos \left(2^{L-1} \pi p\right)\right)$$
γは上記のように表される高周波関数です。
$$\hat{C}_{c}(\mathbf{r})=\sum_{i=1}^{N_{c}} w_{i} c_{i}, \quad w_{i}=T_{i}\left(1-\exp \left(-\sigma_{i} \delta_{i}\right)\right)$$
同様にCも上記のように単純化されます。
結果

Neural Volumes(NV)、Scene Representation Networks(SRN)、Local Light Field Fusion(LLFF)との比較です。いずれの画像もNeRFと比較すると歪んでおり、細部が潰れていることがわかります。

比較結果をまとめたものが上の表です。
$$\operatorname{SNR}=10 \log _{10} \frac{s^{2}}{e^{2}}$$
$$\operatorname{PSNR}=10 \log _{10} \frac{255^{2}}{e^{2}}$$
$$\operatorname{SSIM}(x, y)=[l(x, y)]^{\alpha} \times[c(x, y)]^{\beta} \times[s(x, y)]^{\gamma}$$
$$\left(x, x_{0}\right)=\sum_{l} \frac{1}{H_{l} W_{l}} \sum_{h, w}\left\|w_{l} \odot\left(\hat{y}_{h w}^{l}-\hat{y}_{0 h w}^{l}\right)\right\|_{2}^{2}$$
各指標は損失関数であり、ある視点からみたGTと生成画像の比較です。PSNR、SSIMは大きいほど良く、LPIPSは小さいほど良いことを示します。このことからNeRFは既存のどの手法よりも優れていることがわかります。
結論
本研究では、オブジェクトやシーンを連続関数として表現すべく、既存のMLPにおける問題点に取り組みました。著者らはシーンを5次元のNeural radiance fieldとして表現することで、優れたレンダリングを生成することに成功しました。これにより現実の物体から新たな視点画像を生成するグラフィックパイプラインを前進させることができました。





この記事に関するカテゴリー
