ベースクラスも忘却しないFew-shot物体検出
3つの要点
✔️ 学習したベースクラスの情報を忘却せずに、few-shotクラスも検出できる物体検出モデル、Retentive R-CNNを開発した。
✔️ Retentive R-CNNは、few-shot検出のベンチマークにおいてSOTAを記録した。
✔️ ベースクラス検出においても全く性能が下がらなかった。
Generalized Few-Shot Object Detection without Forgetting
written by Zhibo Fan, Yuchen Ma, Zeming Li, Jian Sun
(Submitted on 20 May 2021)
Comments: CVPR 2021.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
Deep learningは大量の学習データで学習することで高い性能を示してきましたが、限られた量のデータしか得られない状況もあります。そのような状況下でも検知を可能にするfew-shot learningという手法が提案されてきました。しかしながら、従来の手法ではfew-shotクラスの検知のみに特化し、ベースクラスの情報を致命的に忘却してしまう問題があります。物体検出では、一枚の画像に両方のクラスが含まれる可能性があるため、両方のクラスに対して高い検出性能が求められます。このような研究はGeneralized Few-Shot Detection(G-FSD)と呼ばれています。本研究では、転移学習ベースのベースクラス検出機に、両クラスの検出性能を改善できる情報が含まれていることを発見し、それらを用いたBias-Balanced RPNとRe-detectorからなるRetentive R-CNNを開発しました。
問題設定
基本クラスを$C_b$, few-shotクラスを$C_n$, それぞれのクラスを含むデータセットを$D_b$, $D_n$とします。$D_b$は十分な量の学習データを含んでおり、$D_n$は少量の学習データしかありません。我々の目標は、$D_b$の学習情報を忘れずに$D_n$のデータを検知するモデル$f$を学習することです。本研究では、meta learningベースと比べて学習時間がかからず、高い性能が期待できる転移学習ベースを採用しました。まず$D_b$でベースクラス検出器$f^b$を学習し、$D_n$でファインチューニングして$f^n$を得ます。しかしながら、ファインチューニングの段階でベースクラスに対する検出性能は劣化してしまいます。この問題に対処するために、先行研究のTFA(Two-stage Finetuning Approach)を分析しました。TFAはまず通常のR-CNNとして$D_b$で学習し、分類ヘッドとボックス回帰ヘッドの最終層を$D_n$でチューニングします。ファインチューニングされた重みとベース検出器の重みは結合され、$D_n$と$D_b$のサンプルを同数含んだデータセットでもう一度ファインチューニングされます。
Retentive R-CNN
本論文で提案するG-FSDモデルのRetentive R-CNNは、上述の$f^b$の情報を活用するBias-Balanced RPNとRe-detectorから成ります。概略図を下図に示します。
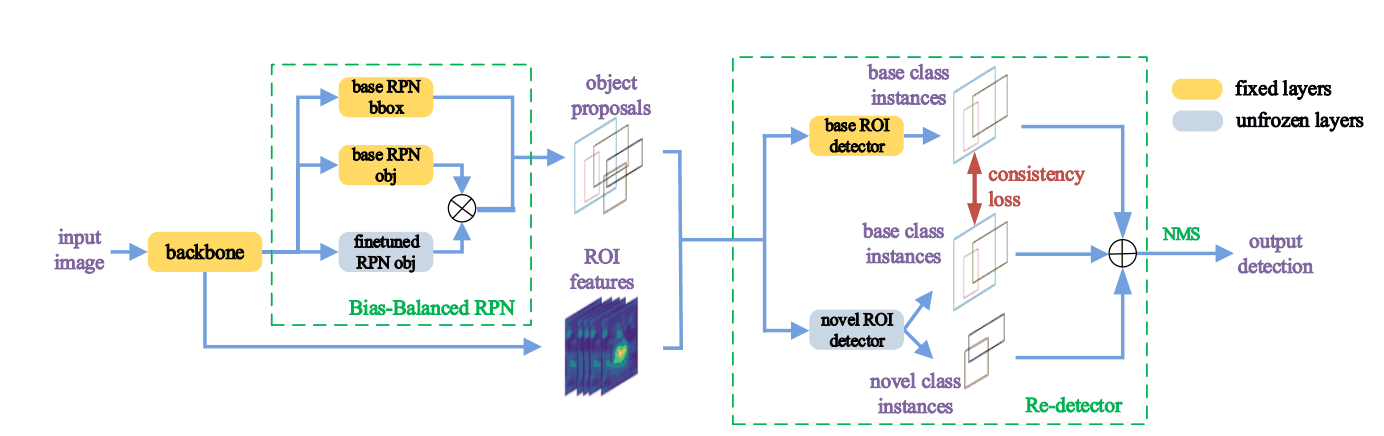
Re-detector
Re-detectorは二つの検出器ヘッドから成り、一方は$f^b$の重みで$C_b$のオブジェクトを予測($det^b$)し、他方はファインチューニングされた重みで$C_b \cup C_n$のオブジェクトを予測($det^n$)します。両クラスを検出することで偽陽性を減らすことができます。TFAと同様に、$det^n$の最終層の分類とボックス回帰のみファインチューニングしました。ここで$det^n$を正則化するために、auxiliary consistecy lossを導入しました。$det^b, det^n$によって最終的にクラス$c$と予測される確率を$p_c^b, p_c^n$としたとき、consistecy lossは下記のようになります。
$$L_{con}=\sum_{c \in C_b}\tilde{p_c^n}\log(\frac{\tilde{p_c^n}}{\tilde{p_c^b}})$$
ただし$\tilde{p_i^n}=\frac{p_i^n}{\sum_{c \in C_b}{p_c^n}}, \tilde{p_i^b}$についても同様です。最終的なファインチューニング時のRe-detectorのloss関数は
$$L_{det}=L_{cls}^n+L_{box}^n+\lambda L_{con}$$
となります。ただし$\lambda$はバランスパラメータです。
Bias-Balanced RPN
R-CNNではRPNがオブジェクトプロポーサルを生成するので、RPNの精度がとても重要になります。しかし、学習済みのRPNではfew-shotクラスのオブジェクトを見落としてしまうため、最終層をファインチューニングしました。また、ベースクラスでの精度を保つために、学習済みRPNとファインチューニングされたRPNを統合したBias-Balanced RPNを提案しました。サイズ$H\times W$の特徴マップが与えられた時、ベースRPNはオブジェクトマップ$O_b^{H\times W}$を、ファインチーニングされたRPNは$O_n^{H \times W}$を生成し、最終的な出力$O^{H\times W}=max(O_b^{H\times W}, O_n^{H\times W})$を取ります。最終的なRetentive R-CNNのloss関数は下記のようになります。
$$L_{ft}=L_{obj}^n+L_{det}$$
ただし$L_{obj}^n$はファインチューニングしたRPNのオブジェクト層のバイナリークロスエントロピーです。
実験結果
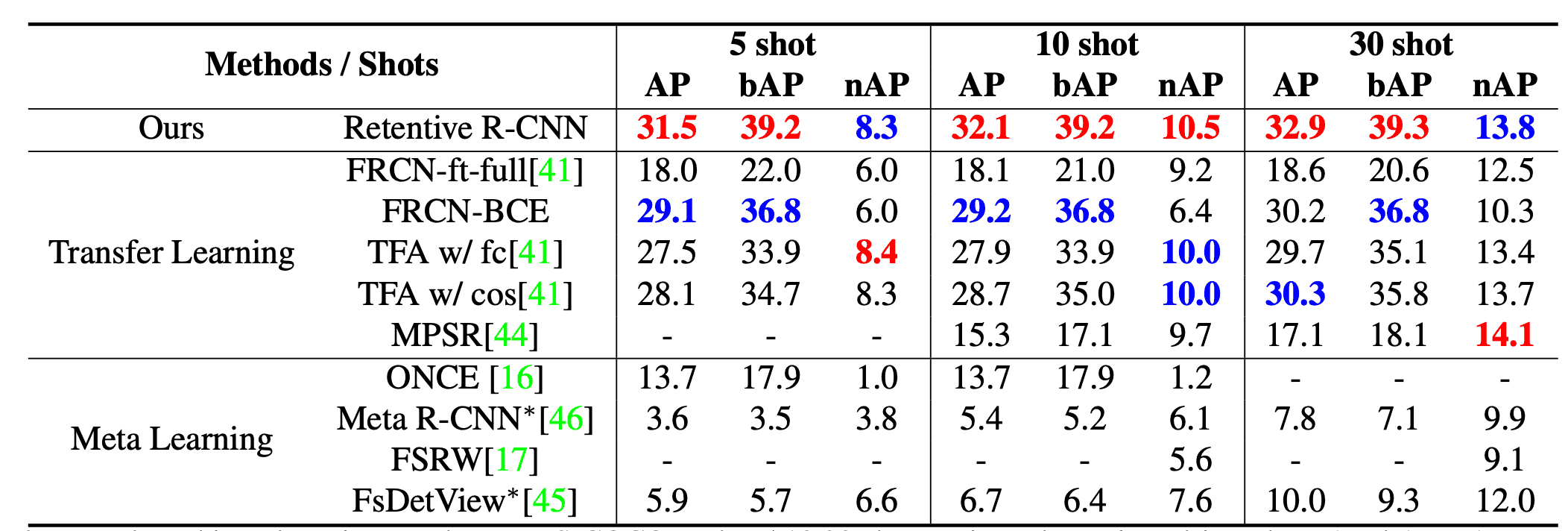
MS-COCOデータセットに対する各モデルの結果は下表のようになりました。AP,bAP,nAPはそれぞれ全体、ベースクラス、few-shotクラスに対する平均適合率です。特にAPとbAPは全てのshot数でRetentive R-CNNが最も良い結果となっています。nAPが僅かに上回った別のモデルも、bAPでは大きく性能が下がり、G-FSDとしては我々のモデルが最も良い結果となりました。
また、10-shotにおけるRetentive R-CNNとTFA w/cosの予測結果の例を下図に示します。図から分かるように、TFAは分かりにくいオブジェクトや複数のオブジェクトが含まれる画像で見過ごしが多いのに対し、我々のモデルはそれらもよく検出できていることが分かります。

結論
本論文では、G-FSDを実現するためにRetentive R-CNNを開発しました。これは転移学習ベースの手法で、従来見過ごされていた情報を利用し、Bias-Balanced RPNが学習済みRPNのバイアスを和らげ、Re-detectorが両クラスを高精度で検出することによって実現されました。Retentive R-CNNは、few-shot検出のベンチマークにおいてSOTAを記録し、ベースクラスの検出性能も劣化しませんでした。しかしながら、few-shotクラスとベースクラスの検出性能差は依然として大きく、今後さらなる改善が期待されます。






この記事に関するカテゴリー






