
自動運転技術に応用可能な画像から3Dボリュームの生成する"VoxFormer"
3つの要点
✔️ Transformerベースのセマンティックシーン補完フレームワーク”VoxFormer”の提案
✔️ 2D画像のみから完全な3Dボリュームセマンティクスを出力することが可能である
✔️ LiDAR情報のデータセットを用いたカメラベースの手法
VoxFormer: Sparse Voxel Transformer for Camera-based 3D Semantic Scene Completion
written by Yiming Li, Zhiding Yu, Christopher Choy, Chaowei Xiao, Jose M. Alvarez, Sanja Fidler, Chen Feng, Anima Anandkumar
(Submitted on 23 Feb 2023 (v1), last revised 25 Mar 2023 (this version, v2))
Comments: CVPR 2023 Highlight
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Robotics (cs.RO)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
AI-SCHOLARイベント
AI技術は日進月歩で進み、皆さんもAI技術に関して多くのブームから衰退までを見ていると思います.そんな中,昨今のブームといえば,GPTからの大規模言語モデルだと思います.そこで,今回はAI-SCHOLARのメンバーを集めて,GPTの総論から話題にも上がるセキュリティ周りなどの技術者・研究者目線でのイベントを実施いたします.

はじめに
ここ数年、人工知能や情報技術の普及に伴い、自動運転の社会実装・普及の取り組みが増えてきました。自動運転にはまだ多くの課題が存在しますが、ドライブレコーダーやセンサの普及、またその他様々なアプローチから安全な走行を目指した研究が進んでいます。その中でも画像処理技術は、自動運転だけでなく、分野の発展・応用を担うものが多いです。
3Dにより場面の全容を把握することは、自動運転の”感知”において重要な問題です。例えば、自動運転車の走行計画やそのルートの作成などのタスクに直接影響します。しかし、現実世界からその3D情報を完璧に把握することはセンシングの技術不足や限定された画角、オクルージョンによる不完全さなどの理由から困難です。
本記事で紹介するVoxFormerは、カメラやセンサのスペックを選ばず、安全な自動走行を可能にするため、画像から3Dボリュームのセマンティックを生成します。
関連研究
現実世界から情報を得る際に起こる課題を解決するために、限られた観測範囲から完全にシーンの形状と意味を推論する技術SSC(semantic scene completion)が提案されました。SSCソリューションは、人間の部分的な観察からシーンの全体像とその意味を予測することに基づき、可視領域へのシーンの再構築と、隠れている領域へのシーンの幻影補完という2つのサブタスクを同時に対処します。しかし、最新のSSC手法と自動車運転における人間の知覚との間には大きな差があります。
また、既存のSSCソリューションの多くは、正確な3D形状測定を可能にするために、LiDAR(Light Detection and Ranging)を主要なセンサとして用いています。LiDARとは、レーザ光を照射して、その反射光を元に物体との距離や形を把握するセンサ技術です。しかし、 LiDARセンサーは高価で携帯性に優れていません。
その一方で、ドライブレコーダーなどのカメラは安価で、運転シーンの視覚的な手がかりを情報として受け取れます。そこでSSCソリューションの一つとして、MonoSceneでカメラベースでの研究が行われました。MonoSceneは、高密度な特徴プロジェクションを用いて2D画像入力を3D化します。しかし、このようなプロジェクションでは、必然的に可視領域の2D特徴が空またはオクルードボクセルに割り当てられてしまいます
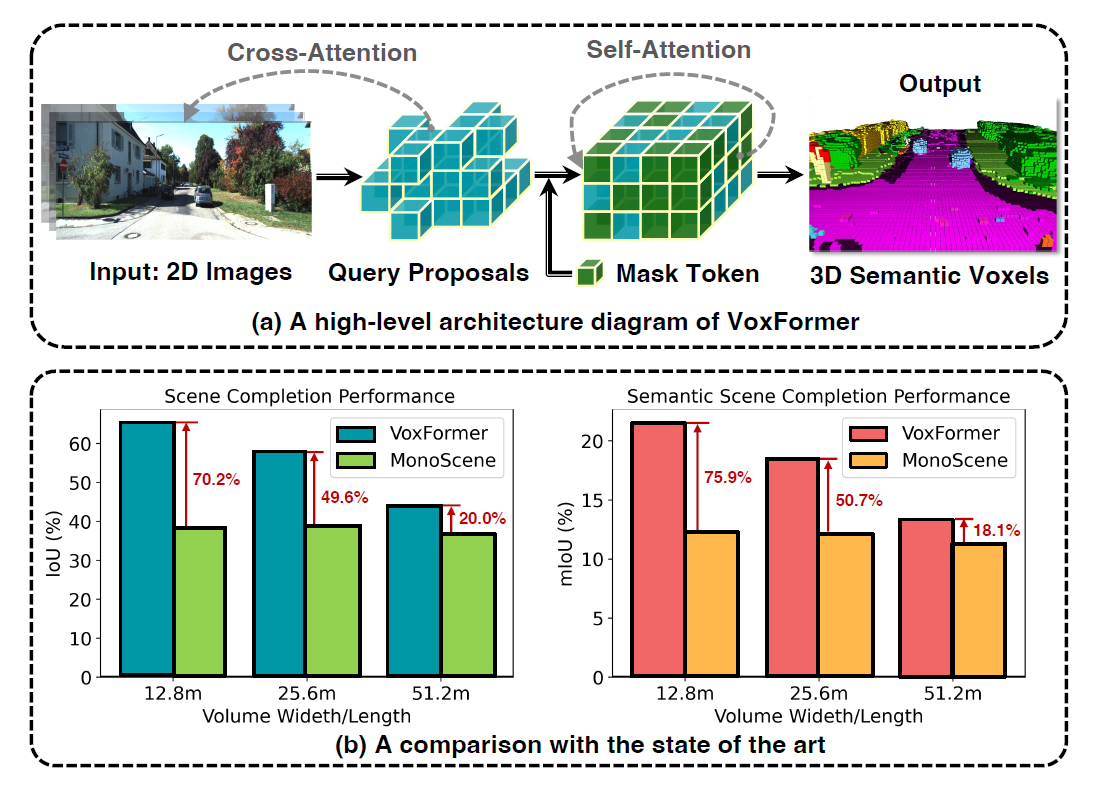 本研究で紹介する VoxFormerは、MonoSceneとは異なり、VoxFormerはスパースなQueryを表現するため3D-to-2Dクロスアテンションを考慮し、以下4つを実現します。
本研究で紹介する VoxFormerは、MonoSceneとは異なり、VoxFormerはスパースなQueryを表現するため3D-to-2Dクロスアテンションを考慮し、以下4つを実現します。
- 画像を3Dボクセル化された完全なセマンティックシーンに変換する新しい2段階フレームワークの開発
- 画像の奥行きから信頼性の高いQueryを生成する2D畳み込みに基づいた新しいQueryを提案するネットワークを構築する
- 完全な3Dシーン表現を実現するため、Masked Autoencoder (MAE)に似た新しいTransformer
- SemanticKITTIデータセットを使用しカメラベースの最先端SSC手法の実現
VoxFormerの概要
VoxFormerは、クラスに依存しないQuery提案(Stage-1)とクラス固有のセマンティックセグメンテーション(Stage2)からなります。Stage-1は占有ボクセルの疎なセットを提案し、Stage-2はStage-1の提案からシーンを表現します。
Stage-1には、画像深度を利用してシーンの形状を再構成する軽量な2D CNNベースのQuery提案ネットワークがあります。そして、全視野の前もって定義された学習可能なボクセルQueryから、ボクセルのスパースセットを提案します。
Stage-2は、 MAEライクなアーキテクチャである新しいsparse-to-denseに基づきます。提案ボクセルに特徴付けを行い、提案されていないボクセルを学習可能なマスクトークンと関連付け、ボクセルごとのセマンティックセグメンテーションによりシーンを表現します。
アーキテクチャ
下の図のように、TransFormerを用いたSSCでは、2D画像から3Dボクセルの特徴を学習します。
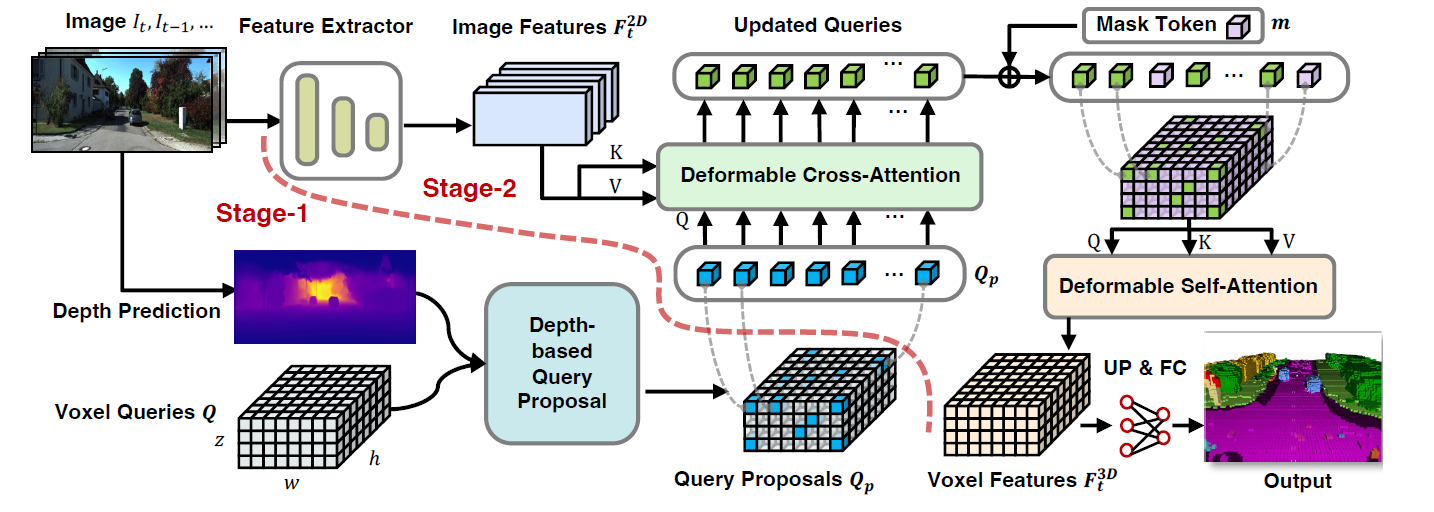
VoxFormerアーキテクチャは、RGB画像から2D特徴を抽出し、3DボクセルQueryの疎なセットを使用し、これらの2D特徴にインデックスを付け、カメラの投影行列を使用して3D位置を画像ストリームにリンクします。
ボクセルQueryは3D格子状の学習可能なパラメータであり、Attentionメカニズムによって画像から3Dボリューム内の特徴を問い合わせます。上の図の左下に示すように、3次元格子状の学習可能なパラメータのクラスタとして、合計Nq個のボクセルクエリをあらかじめ定義します。
また、いくつかのボクセルQueryは画像に注目するために選択され、残りのボクセルは3Dボクセル特徴を完成させるために別の学習可能なパラメータと関連付けられます。このパラメータをMaskトークンと呼び、これらは予測される欠損ボクセルの存在を示します。
訓練損失
Stage-2を重み付きクロスエントロピー損失で学習します。
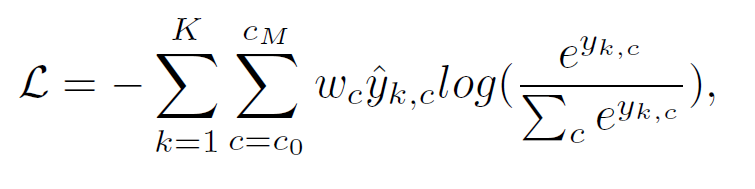
k:ボクセルインデックス K:ボクセルの総数 c:クラスインデックス
Stage-1では、空間解像度がより低く占有マップを予測するため、バイナリクロスエントロピーを採用します。
実験
データセット
LiDARシーケンスを用いたデータセットであるSemanticKITTIを用いて、VoxFormerの検証を行います。SemanticKITTIは、22個の屋外運転シナリオからなる”the KITTI Odometry Benchmark “の各LiDARスイープに対してセマンティックアノテーションします。
実装
・Stage-1
MobileStereoNetを使用し、直接深度を推定します。 MobileStereoNet のような奥行きは、ステレオ画像のみから低コストで擬似LiDAR点群を生成することが出来ます。
・Stage-2
cam2のRGB画像を1220×370に切り出し、ResNet50を用いて画像の特徴を抽出し、第3ステージの特徴をFPNで取り込み、入力画像サイズの1/16のサイズの特徴マップを生成します。 また、VoxFormerには、現在の画像のみを入力とするVoxFormer-Sと、現在と前の4枚の画像を入力とするVoxFormer-Tの2種類が用意されています。
評価
割り当てられた意味ラベルに関係なく、シーン補完の品質を評価するために、IoU(intersection over union)を採用しています。ベースラインとして、 VoxFormerとパブリックリソースを用いた最新のSSCと、以下3点で比較します。
- 2Dから3Dへの特徴投影に基づくカメラベースのSSC手法MonoScene
- JS3CNet、LMSCNet、SSCNetを含むLiDARベースのSSC手法と
- ステレオデプス(MobileStereoNet)によって生成された擬似LiDAR点群を入力とするRGB干渉ベースライン LMSCNetとSSCNet
結果
本記事では、カメラベースの手法との比較結果と、LiDAR ベースの手法との比較結果を取り上げます。
カメラベース手法との比較
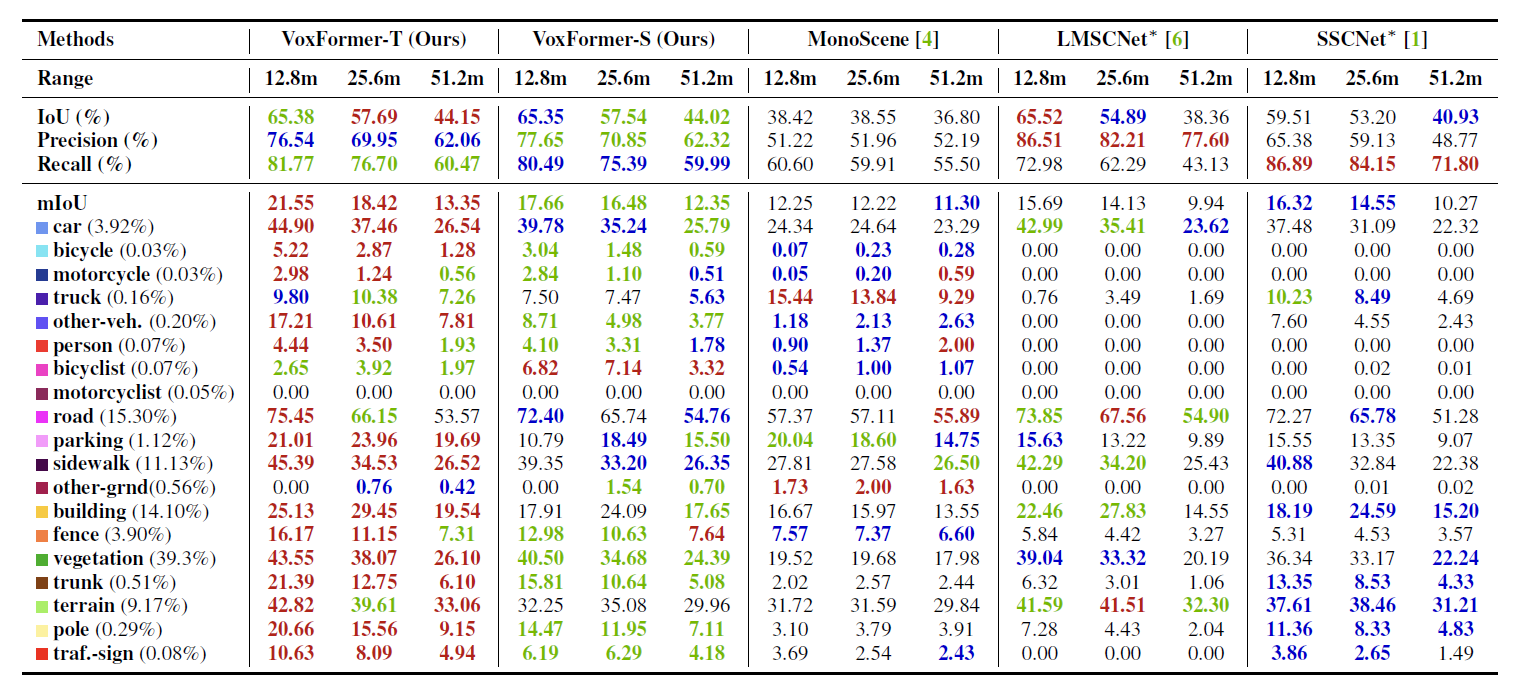 VoxFormer-Sは幾何学的補完性においてMonoSceneを大差で上回り、明示的な奥行き推定と補正を行うstage-1により、Query処理中に多くの空白を減らすことができたことが分かります。
VoxFormer-Sは幾何学的補完性においてMonoSceneを大差で上回り、明示的な奥行き推定と補正を行うstage-1により、Query処理中に多くの空白を減らすことができたことが分かります。
LiDAR ベースの手法との比較
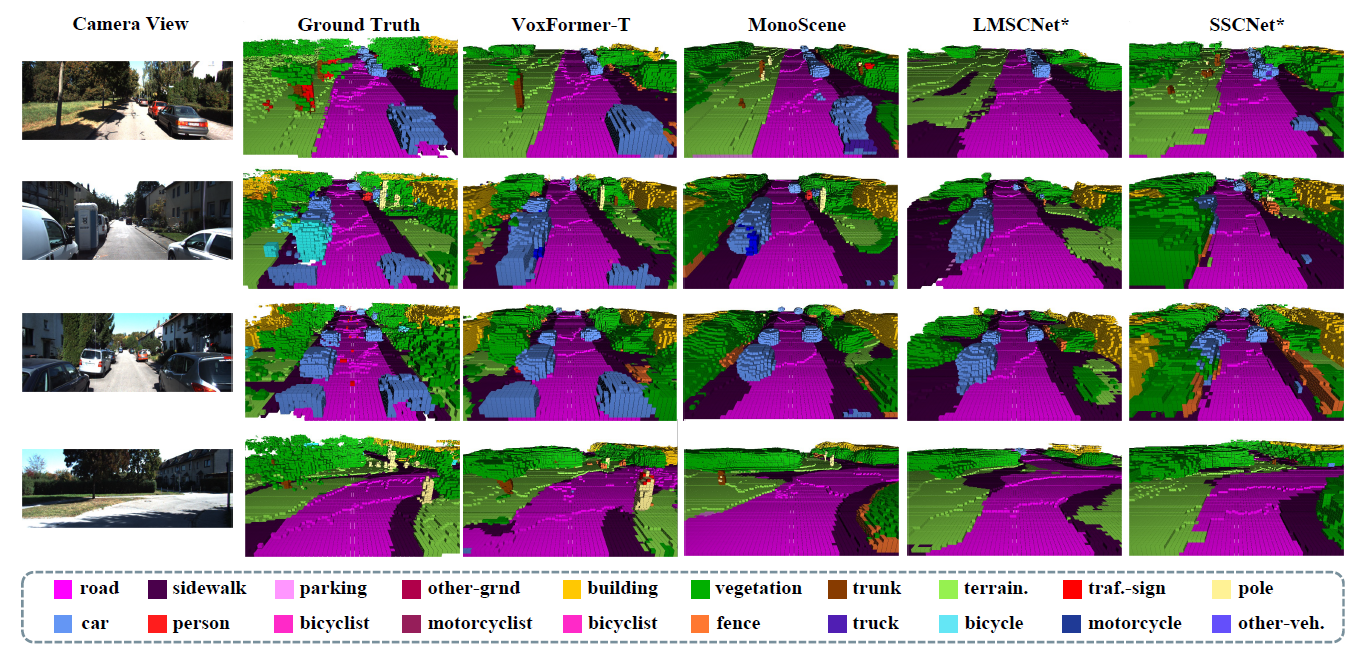
Ego Vehicle(自動運転システム搭載車)に近づくと 、LiDARを用いた手法との性能差は小さくなることが視覚的に分かります。
まとめ
VoxFormerでは、SemanticKITTIデータセットでの広範囲なテストにより、幾何学的補完と意味的分割において最先端の性能を達成することが示されました。ここで重要なのは、他のソリューションより、安全性が重要視される近距離領域での大きな改善が見られたことです。また、VoxFormerは、推論するために高価なカメラを必要とせず、安価なカメラで十分であるため、技術的な進歩だけでなく、実社会への導入コスト面についても考えられています。
今後、 VoxFormer のように高価なカメラやセンサなどを必要とせず、より精度の高いSSCソリューションの研究が進めば、自動運転技術の可能性を拡げると考えます。




この記事に関するカテゴリー





