
お手軽!高精度!異常検知モデルPatchCoreの魅力
3つの要点
✔️ 異常検知問題ベンチマークであるMVTecデータセットにおいてSOTAを達成!
✔️ 事前学習済みモデルを活用することで特徴抽出部分のCNNの学習が不要
✔️ CNNから得られた特徴を効率的にサンプリングすることで推論の高速化が可能
Towards Total Recall in Industrial Anomaly Detection
written by Karsten Roth, Latha Pemula, Joaquin Zepeda, Bernhard Schölkopf, Thomas Brox, Peter Gehler
(Submitted on 15 Jun 2021 (v1), last revised 5 May 2022 (this version, v2))
Comments: Accepted to CVPR 2022
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
異常検知問題とは数あるデータの中から,ふるまいの異なるデータを検出するタスクです。本論文では特に工業用画像データの異常検知問題を扱っています。
実世界では正常画像を取得するのは比較的容易である一方,様々なパターンが考えられる異常な画像は取得することが難しいという課題があります。そのため,正常画像のみの学習で,異常画像を特定する様々なモデルが提案されてきました。
本論文ではPatchCoreと呼ばれるモデルを提案し,ベンチマークであるMVTecデータセットにおいてSOTAを達成しています[1]。PatchCoreの一番の特徴は事前学習済みモデルから得られる特徴を活用し,画像の特徴抽出に関する学習を改めて行わない点にあります。
以下でPatchCoreの詳細を説明します。
PatchCore
モデルの全体像
まず、PatchCoreの概要について説明します。
PatchCoreは、Memory Bankに含まれる正常画像の特徴ベクトルと判定したい画像(テストデータ)の特徴ベクトルの距離から異常度を算出し、その画像が正常か異常かを判断します。 また、画像のピクセルごとの異常度も得られるため、異常部位検出を行うこともできます。
次に、PatchCoreにおける学習・推論の流れを簡単に説明します。
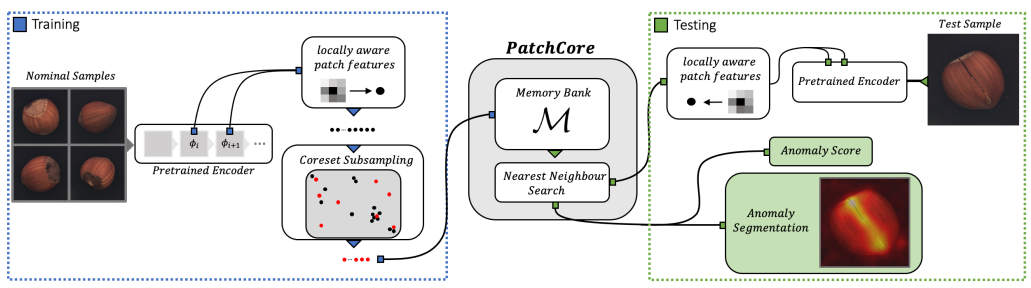
上の図の左側(青点線枠)が学習、右側(緑点線枠)が推論の流れとなっています。
学習では、正常画像のみを使用します。画像を学習済みのCNNモデルに通し、パッチごとの特徴ベクトルを得た(①)後、サンプリングを行い、選ばれた特徴ベクトルをMemory Bankに保存します(②)。
このようにして正常画像の特徴ベクトルが蓄積されたMemory Bankを用いて推論を行います。推論時も画像を学習済みのCNNモデルに通し、パッチごとの特徴ベクトルを得ます(①)。その後、得られた特徴ベクトルとMemory Bank内の特徴ベクトルの距離を基にして、画像とピクセルごとの異常度を算出します(③)。
ここまでPatchCoreの学習と推論の全体像を見てきましたが、以下で詳しい説明を行っていきます。特に上の説明で丸数字を付けた3つの部分を説明します。
①Locally aware patch features
1つ目は画像からパッチごとの特徴ベクトルを得るLocally aware patch featuresです。
PatchCoreでは、ImageNetと呼ばれるデータセットで学習済みのCNNモデル[2]を用いて画像から特徴ベクトルを獲得しています。このCNNモデルの部分は正常・異常を判定したいデータセットで改めて学習を行うことはしません。
さらに学習済みのCNNモデルから得られた特徴ベクトルに対して、適応的平均プーリング(Adaptive Average Pooling)を行います。ここまでの処理を数式で表現すると以下のようになります。
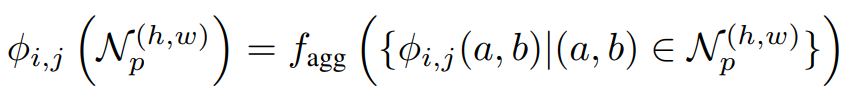
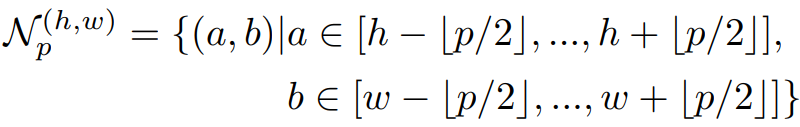
学習済みCNNモデルのどの層から得られる特徴ベクトルを使用するかという問題があります。候補の1つとして最終層が考えられます。
最終層は最も集約された、高い抽象度の(高レベルな)特徴ベクトルが得られるため、先行研究において使われている例がいくつかあります。しかし、この論文では最終層から得られる特徴ベクトルを用いることの問題点を2点指摘しています。
- 局所的な特徴が失われること
- 深い層の特徴ベクトルは高レベルである一方、畳み込みとプーリングが繰り返されているため、解像度が低くなっています。そのため、局所的(細か)な特徴が失われている可能性があるというわけです。
- 異なるドメイン(ImageNetの分類問題)に偏った特徴であること
- 学習済みモデルは推論対象とはドメインの異なったタスクで学習されており、深い層にはそのタスクに特化した特徴が多く含まれていると考えられます。そのため、ドメインの異なったタスクの影響が色濃い最終層特徴ベクトルを用いることは適切でないと主張しています。
そこでこの論文では、できるだけ高レベルかつ事前学習の影響が少ない特徴ベクトルを得るために学習済みモデルの中間層から特徴ベクトルを得ることを提案し、実験によりその有効性の検証を行っています。
下のグラフは特徴ベクトルを取得する学習済みモデルの層(横軸:数字が小さいほど浅く、大きいほど深い)と異常検知タスクにおける精度の関係(縦軸:大きい(上にいく)ほど高精度)を表しています。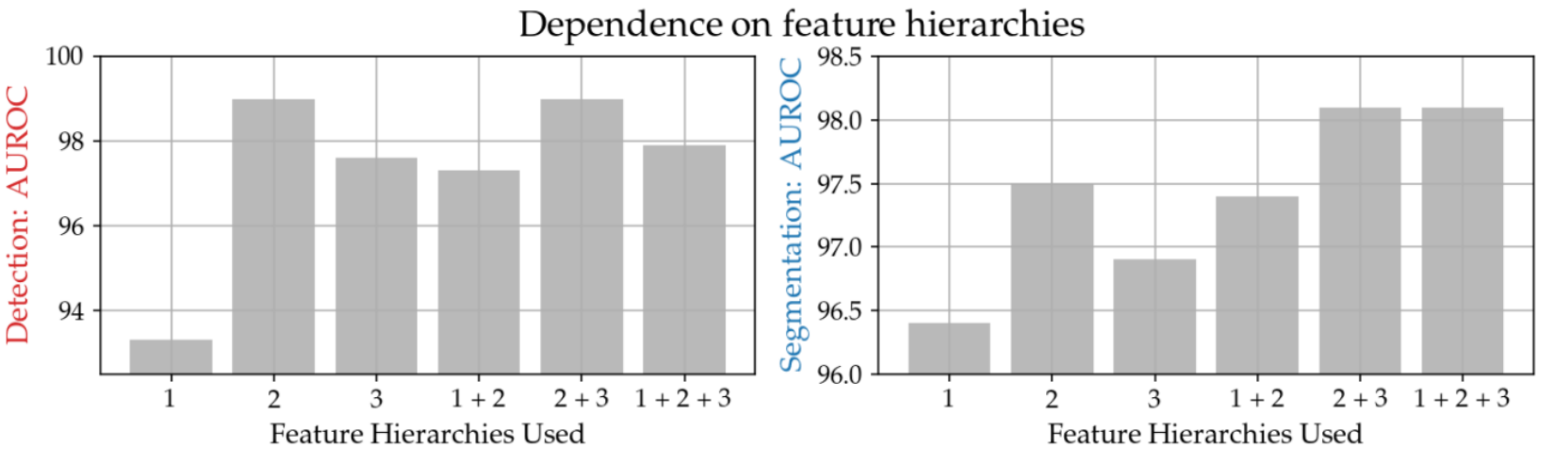
上のグラフを見ると、確かに中間層である「2」が含まれるパターンにおいて精度が高いことがわかります。この結果から、PatchCoreでは「2」と「3」の層から特徴ベクトルを獲得することとなっています(2+3)[3]。
②Coreset-reduced patch-feature memory bank
2つ目は①で得られた特徴ベクトルをMemory Bankに保存する部分であるCoreset-reduced patch-feature memory bankです。
学習データ数が増大すると、Memory Bankに格納すべきデータが増え、テストデータを評価するために必要な推論時間が長くなったり、保存するためのメモリの容量が増大するといった問題が生じます。
そのため、この論文ではCoreset Samplingにより、①で得られた特徴ベクトルに対してサンプリングを行った上でMemory Bankに保存することを提案しています。
サンプリング方法は以下のような式で表されます。Mはサンプリング前の特徴ベクトルの集合、MCはサンプリング後の特徴ベクトルの集合です。
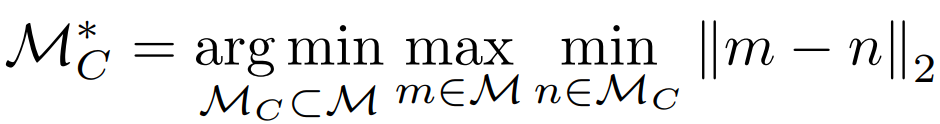
上の式はサンプリング前の特徴ベクトル(m)とサンプリング後の特徴ベクトルにおいて最小距離の最大値が最も小さくなるようにサンプリングを行うことを意味します。
しかし、この最適化問題はNP困難であるため、最適解を得るためには多くの計算時間を要します。そのため、この論文では最適解に近い解をより早く得られるように次の2つの工夫を行っています。
- 貪欲法による近似
- 先行研究で用いられた方法を採用している。
- ランダム射影による次元削減
- 特徴ベクトルの次元を削減することで、上で説明した最適化問題の計算量を抑えることができます。Johnson-Lindenstraussの補題を根拠に精度よく次元削減ができるとしています。
この論文ではCoreset Samplingの有効性の検証を行っています。
以下の図はダミーデータにCoreset Samplingを適用し、その結果を可視化したものです。
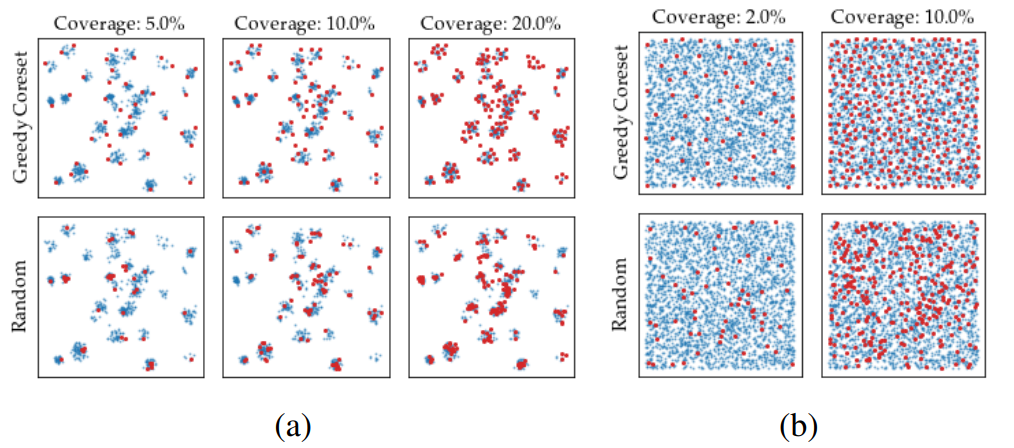
(a)と(b)の二つのダミーデータに対して、ランダムに次元削減を行ったときとCoreset Samplingを行ったときを比較しています。Coverageは元のサンプルデータからの削減率を表しています。下のRandomに比べて、上のCoreset Samplingのほうが効率的にサンプリングができていることがわかります。
また、以下のグラフは次元圧縮方法ごとの削減率(横軸)と異常検知タスクにおける精度(縦軸)の関係を表しています。
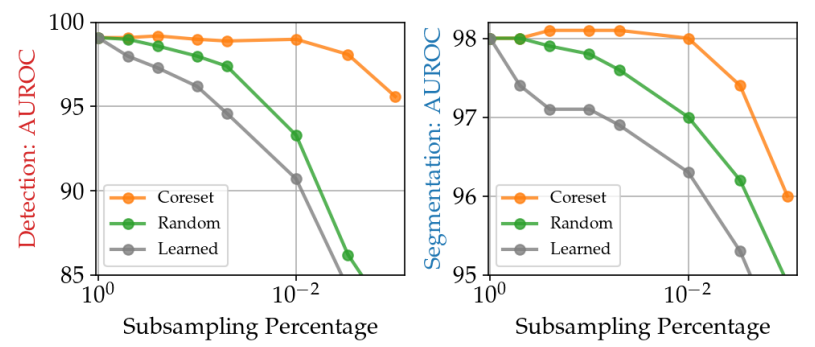
上のグラフを見てみると、Randomの場合は削減率が10-2程度になると精度が大きく下がってしまいますが、Coreset (Sampling)の場合、精度がそれほど落ちていないことがわかります。そのため、Coreset Samplingがデータ数を削減しながらも、異常検知に必要な特徴を残すことのできる効率的なサンプリング方法であるといえます。
最後に、これまで説明してきたMemory Bankに保存するアルゴリズム全体を以下に示します。

③Anomaly Detection with PatchCore
3つ目は②で得られたメモリバンクを用いて、判別したい画像(テストデータ)の異常度を算出するAnomaly Detection with PatchCoreです。
はじめに学習時と同様にテストデータの画像を学習済みのCNNモデルに通し、パッチごとの特徴ベクトルを得ます。
以下の式に従い、テストデータのパッチごとの特徴ベクトル(mtest)とMemory Bankに保存された特徴ベクトル(m)から異常度(s*)を算出します。
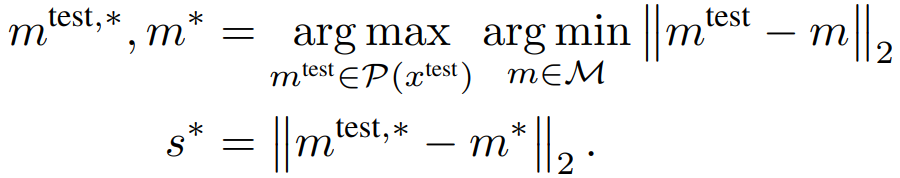
実験
実験設定
本論文では3種類のデータセットで提案手法の有効性を検証しています。
1つ目はMVTecデータセットです。ベンチマークとして広く用いられており,Bottle,Cable,Gridなど15のカテゴリーがある。本研究ではこのデータセットをメインに扱っています。
2つ目はMagnetic Tile Defects(MTD)データセットです。磁器タイル画像のヒビや傷を検出するタスクとなっています。
3つ目はMini Shanghai Tech Campus(mSTC)データセット[4]です。12の異なるシーンの歩行者映像で構成されており,喧嘩や自転車といった異常行動を検出するタスクとなっています。
評価指標
画像の正常・異常を見分ける性能の指標としてAUROC(Area under the Receiver Operator Curve)を用いています。また,適切な異常部位の検出性能の指標としてピクセル単位のAUROC(pixelwise AUROC)とPROが用いられています。PROは異常部位のサイズの影響を受けにくいという特徴があります。
結果
はじめにMVTecデータセットの結果[5]からみていきます。
下の表はAUROCにおける従来手法との比較結果です。

さらに下の表はpixelwise AUROCの結果を示しています。

PatchCoreではそれぞれ,メモリバンクのサブサンプリングを25%、10%、1%と変化させた場合の結果を示しています。AUROC,pixelwise AUROCいずれにおいてもPatchCoreの精度が高いことがわかります。また,メモリバンクのサブサンプリングの割合を減らしてもそれほど精度が落ち込まないこともわかります。
mSTCとMTDにおける結果は下の表の通りです。これらのデータセットにおいても従来手法の精度を上回る結果となっています。

推論時間
以下の表はMVTecデータセットにおける各手法における精度(AUROC,pixelwise AUROC,PRO)と推論時間を示しています。
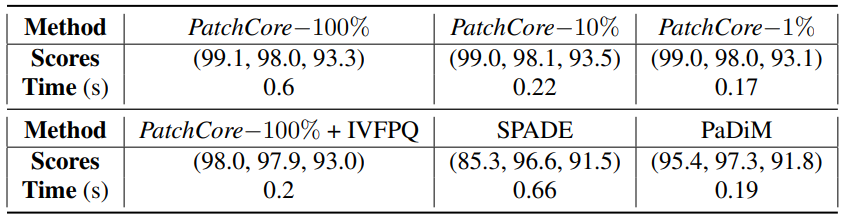
PatchCoreの結果に注目すると,Coreset Samplingの割合によって推論時間が大きく異なることがわかります。特に1%の場合,100%のときとそれほど変わらず,従来手法を上回る高い精度を保ったまま,高速な推論ができていることがわかります。
まとめ
MVTecデータセットにおいてSOTAを達成したPatchCoreについて紹介しました。
事前学習済みモデルを活用することで,特徴抽出部分(CNN)の学習が不要であることやCoreset Samplingにより特徴を効率的にサンプリングすることで推論時間の短縮が実現できることが大きな魅力だと感じました。
また,本論文では工業用画像データの異常検知問題を対象としていましたが,様々な分野に応用できると考えられます。
補足
[1]画像の正常・異常を見分ける精度である(image)AUROCにおいてSOTAを達成している。(2023年3月時点)
[2]ImageNetによる事前学習済モデルの中でもResNet50とWideResnet-50をこの論文では用いている。
[3]2つの層を用いると得られる特徴ベクトルの次元数(解像度)が異なってしまう。そのため、低解像度の特徴ベクトルに対してバイリニア補間を適用し、次元数をそろえている。
[4]オリジナルのSTCデータセットの動画フレームを5フレームごとにサブサンプリングしたものである。
[5]15のカテゴリーの平均の結果を示している。






この記事に関するカテゴリー






