画像分類ニューラルネットワークの探索・可視化を可能にするActivation Atlasesとは
今回紹介するのは、画像認識におけるAIの中身を詳しく調査したという研究です。論文ではニューラルネットワークがどのように画像分類するかを可視化するアプローチ活性化アトラス(Activation Atlases)が紹介されています。
【参照】 Exploring Neural Networks with Activation Atlases
AIにおける解釈可能性
AIによる画像認識は画像ライブラリの写真への自動タグ付けから自動運転システムまで、さまざまなシナリオで現在展開されています。しかし、これらのモデルは解釈可能性に欠如しているため、監査または効果的にトラブルシューティングすることが難しくその適用性を制限します。現在、その判断過程がブラックボックスのまま使われることを国際的な枠組みである程度規制するとともに、AIの中身を専門家でなくても理解しやすくするための研究開発が進められています。
解釈可能性はディープニューラルネットワーク、特に画像などの非構造化データセットを扱うものの最大の課題の1つです。画像分類モデルがその知識をどのように構築するかを理解することはほとんど不可能でした。
これらの課題に対応するため、GoogleとOpenAIの研究者が、画像分類ニューラルネットワークの意思決定プロセスを視覚化するアプローチを提案しています。
3月に発表された「活性化アトラスを用いたニューラルネットワークの探索」と題されたこの研究論文では、画像分類方法の中間表現を視覚化する方法を提案する論文を発表しました。画像データセットを提示したときにニューラルネットワークがどのように「見ているのか」を人間が理解するのに役立つ活性化アトラス(Activation Atlases)と呼ばれる技術が紹介されています。
視覚化における課題
活性化アトラス(Activation Atlases)は、神経回路網の中間的な画像表現を理解するために、神経科学からいくつかのアイデアを借用しています。
例えば、人間は目を通して視覚信号を受け取ると、その情報は脳の新皮質領域によって処理されます。視覚信号のタイプが異なれば、ニューロンの異なるセットが活性化され、これらのニューロンは互いに結合して知覚対象の知識を活性化させます。実際の知識は個々のニューロンによって構築されるのではなく、相互に連結したニューロンのグループによって構築されるのです。
GoogleとOpenAIが提案した手法の起源は、昨年発表された論文「解釈可能性の構成要素」で紹介されたFeature Visualizationと呼ばれる手法です。しかしこのアプローチには、ネットワークの全体像を提供するのではなく、特定の入力に対してアクティブになる部分のみを提供するという制限がありました。
一方、活性化アトラスは、Feature Visualizationの原則に基づいて構築されていますが、ネットワークの全体像を提供するために拡張されています。入力画像によって引き起こされる活性化に焦点を当てる代わりに、活性化アトラスはニューロンの共通の組み合わせを視覚化し、知識がネットワークでどのように生成されるかのより包括的な視点を提供します。
活性化アトラス
活性化アトラスはImageNetデータセットで訓練された畳み込み画像分類ネットワーク、Inceptionv1から構築されています。分類ネットワークには画像が表示され、その画像に「カルボナーラ」、「スノーケル」、「フライパン」などの1,000の所定のクラスの1つからラベルを付けるように求められます。
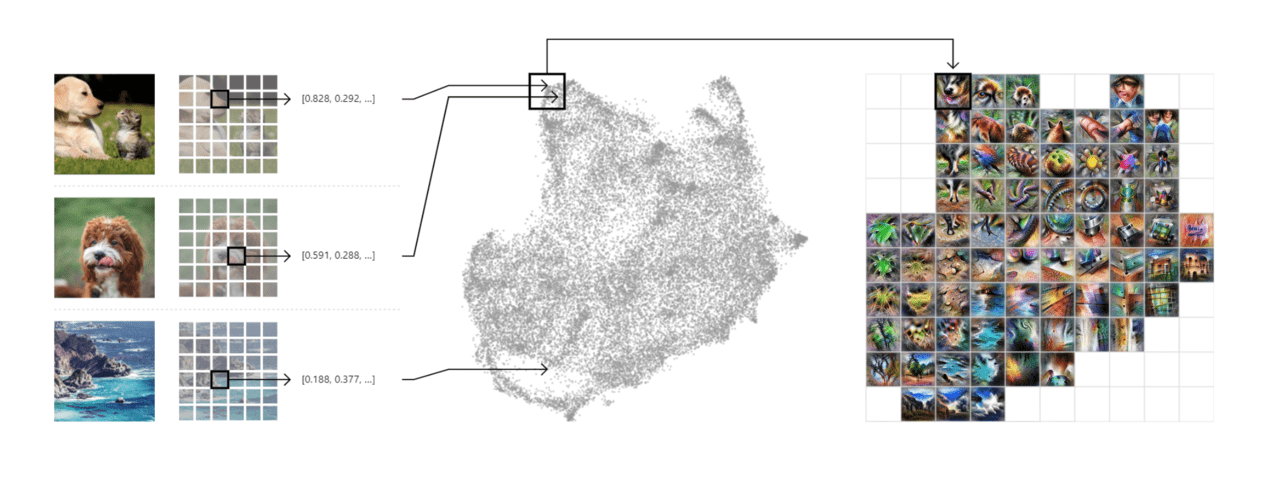 図1
図1
実行するためには、このネットワークに100枚の画像を分類させます。ネットワークはそれぞれが異なる種類の画像パッチ上で様々な程度に活性化する数百のニューロンからなる約10の層を通して画像データを漸進的に評価していきます。例えば、ある層の1つのニューロンは犬の耳に積極的に反応し、より前の層の別のニューロンはコントラストの高い垂直線に反応するかもしれません。活性化アトラスは、これらの各層から内部活性化を集めることによって構築されます。
複雑な一連の高次元ベクトルで表されるこれらの活性化を、次元縮小手法であるUMAPを介して有用な2Dレイアウトに投影します。(図1の真ん中)
最後に、それらはプロットされ、似ている活性化が互いに近くに配置されます。そしてこの活性化ベクトルを反復最適化プロセスを通して画像を作成します(図1の右)。すると分類途中の画像の集合体がWebページ上に表示され、それが層の数だけビジュアライズされます。(下画像)

中身を見てみる
以下は活性化アトラスが視覚化したニューラルネットワーク内の1つのレイヤです。これはこの層で画像を分類するためにネットワークが学んだ視覚的概念の宇宙を明らかにしています。この図は、モデルが開発したさまざまな視覚的抽象化と概念を反映しています。前述したように、このネットワークにはさらに多くの層があります。
さらに、活性化アトラスでは地図全体で特定のレイヤーを表示させる事ができます。これらの概念がネットワークに深く入るにつれてどのように洗練されて行くのかを見るために、個々の概念に着目してみます。例えば「キャベツ」のように、特定の分類に寄与する3つの層の領域に注目すると、これをはっきりと見ることができます。
この初期の層は他の層と比べて非常に非特異的です。

中間層では、画像は間違いなく葉に似ていますが、どんな種類の植物なのかよくわかりません。
最後の層では、これらの概念はさらに洗練されました。画像はキャベツに特有のもので、葉は丸いボールに湾曲しています。

また、新しい概念が古い概念の組み合わせから出現している事もわかりました。層から層へ動くとき概念が洗練されているだけでなく、新しい概念が古いものの組み合わせから現れるケースもあります。
例えば以下では1層目(左)と2層目(真ん中)の2つのアイデアが3層目(右)の活性化に融合しているように見えます。
それに加えて、特定のレイヤーの中からカテゴリ(ImageNetは1,000のカテゴリを持つ)を1つに絞ることもできます
この機能により、ネットワークが特定のクラスを分類するために最も頻繁に使用している概念を明らかにできます。例えば、以下に「red fox(アカギツネ)」の事例をあげます。ここでは、「red fox」を分類するためにネットワークが何に焦点を当てているのかをより明確に見ることができます。先のとがった耳、赤い毛皮に囲まれた白い鼻、および樹木が茂ったまたは雪に覆われた背景などがあります。

これらのアトラスは、モデル内の微妙な視覚的抽象化を明らかにするだけでなく、高レベルの間違いも明らかにします。たとえば、「ホオジロザメ」のアクティベーションアトラスを見ると、(予想どおり)水と三角フィンが見えますが、野球のように見えるものもあります。このように明らかな間違いを発見することもできます。
まとめ
活性化アトラス(Activation Atlases)は、ニューラルネットワークの進化する知識構築プロセスに対する独自の可視性を提供し、「ブラックボックスの内側を見る」ためのクリーンなメカニズムを提供してくれます。ニューラルネットワークの解釈可能性の観点から見た最も創造的な仕事の1つではないでしょうか ?



この記事に関するカテゴリー






