Fairness×ドメイン適応 ~少ないデータにも公平性を~
3つの要点
✔️問題設定: 異なるドメイン間でFairness(公平)を達成する。
✔️問題設定を達成するためのフレームワークを提案した。
✔️2つのデータセット(UCI AdultとCOMPAS)で提案手法の有用性を示した。
今回紹介する論文はこちら。
Transfer of Machine Learning Fairness across Domainsです。日本語にすると、「複数ドメイン間におけるFairnessの転移」。Fairnessとドメイン適応という二つの分野を融合させた面白い問題設定の論文です。
論文名: Transfer of Machine Learning Fairness across Domains
Subjects: Machine Learning
Submit: 26 Jun 2019
Written by: Candice Schumann, Xuezhi Wang, Alex Beutel, Jilin Chen, Hai Qian, Ed H. Chi
復習
Fairnessとドメイン適応についての概要を書きました。どちらもご存知の方は読み飛ばしてください。
Fairnessとは
AIにおけるFairnessとは、「AIの判断を出来るだけ公平なものにしよう」という分野です。例えば、人間に関する情報を入力として、その人間が今後犯罪を犯すかどうかについて予測するAIを考えます。AIは傾向を掴もうと学習するので、もしある人種の犯罪率が高ければ、その人種の人間の犯罪確率を高く予測してしまいます。これは不公平だと感じないでしょうか。まだ犯罪を犯していない好青年が、ただただ自分の生まれた土地のせいで犯罪確率を高く予測されてしまうことになるのです。このような学習を防ごうと研究されている分野がFairnessです。
では、どのようなAIが公平であるかを定義しておく必要があります。本論文では、Equal Opportunity(機会均等)という概念を元に公平性を定義しています。Equal Opportunityとは、「AIがクラス1のデータに対する正答率はセンシティブ属性※に影響されない」という公平の定義です。例えば、入力された人間のデータが年収50,000ドルを超えるかどうかを判別するAIを考えます。Equal Opportunityとは、年収50,000ドルを超えるデータに対するAIの正答率が性別や人種に関係なしに同じであるべきというものです。そして本論文では、AIが公平であるかどうかの評価指標として、どれほどEqual Opportunityから離れているかを採用しています。具体的に言うと、「センシティブ属性を変化させた時の正答率の変化量」がFairnessの評価指標になります。(もっと専門的な言い方をすると、センシティブ属性の違いにより生まれるFPR(False Positive Rate)の差です。)
※センシティブ属性とは、その属性を判断基準にすることが差別に値するような属性のことで、人種や性別や肌の色などがそれに当たる。何がセンシティブ属性であるかは法律で定められている。
Fairnessについて詳しく知りたい方は当サイトで執筆したFairness入門という記事をご覧ください。
ドメイン適応とは
ドメイン適応とは、トレーニングデータの特徴量分布とテストデータの特徴量分布が異なる時、それぞれの分布を近づけるように学習することでテストデータにおける精度を向上させる手法です。分布が異なるとは具体的にどのような状況でしょうか。例えば、人の画像から男性と女性を判別するAIを考えます。手元には大量のラベル付きデータがありますが、それらはアメリカ人の画像だとします。そして我々は日本人の画像に関して精度を向上したいと考えているとします。このような状況の時、アメリカ人の画像と日本人の画像はどちらも人間の画像ですが、やはり双方に特徴量の違いは存在します。これが分布が異なるという状況です。
問題はいかにしてそれぞれの分布を近づけるかです。本論文では敵対的学習を使用しています。敵対的学習を使用したドメイン適応は下の論文が有名です。気になった方は是非読んでみてください。本記事では下の論文を読んでいなくてもわかるように説明するつもりです。頑張ります。
論文名: Domain-Adversarial Training of Neural Networks
Subjects: Machine Learning
Submit: 26 May 2016
Written by:Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle, François Laviolette, Mario Marchand, Victor Lempitsky
詳細は問題設定
この先の解説でイメージをしやすいように具体的なデータセットなどの問題設定を先に説明しておきます。
データセット
本論文で使用したデータセットはUCI AdultデータセットとCOMPASデータセットの二つです。
- UCI Adult
- 人間の情報からその人間が年収50,000ドル以上かどうかを予測する。
- 人種や性別などのセンシティブ属性を含む。
- COMPAS
- 人間の情報からその人間が2年以内に犯罪を犯すかどうかを予測する。
- 人種や性別などのセンシティブ属性を含む。
ここで、「UCI AdultとCOMPASのドメイン間でドメイン適応させるのか。」と勘違いしてしまうかもしれませんが、本論文における問題設定はそうではありません。
本論文における問題設定は、「異なるセンシティブ属性によって生じるドメインの違いを適応させる」というものです。もう少し噛み砕いた説明をします。例えばCOMPASを用いたとします。COMPASのデータの性別以外のセンシティブ属性を削ぎ落としたデータセットをDとします。また、人種以外のセンシティブ属性を削ぎ落としたデータセットをD’とします。当然、DとD’は異なる分布を持ちます。この2つの分布を近づける。つまり、「異なるセンシティブ属性によって生じるドメインの違いを適応させる」というタスクが本論文における問題設定です。
ちなみに例えにあげた性別と人種についてですが、論文内でも全く同じ設定です。また、UCI AdultにおいてもCOMPASにおいても全く同じ設定です。センシティブ属性として性別が存在するデータセットがソースドメインで、センシティブ属性として人種が存在するデータセットがターゲットドメインです。ということで、異なるセンシティブ属性によって生じるドメイン間の違いを埋めることでソースドメインの情報をターゲットドメインに活かそうというのが本論文におけるタスクです。
提案手法
下に提案手法のモデル図を記載しました。
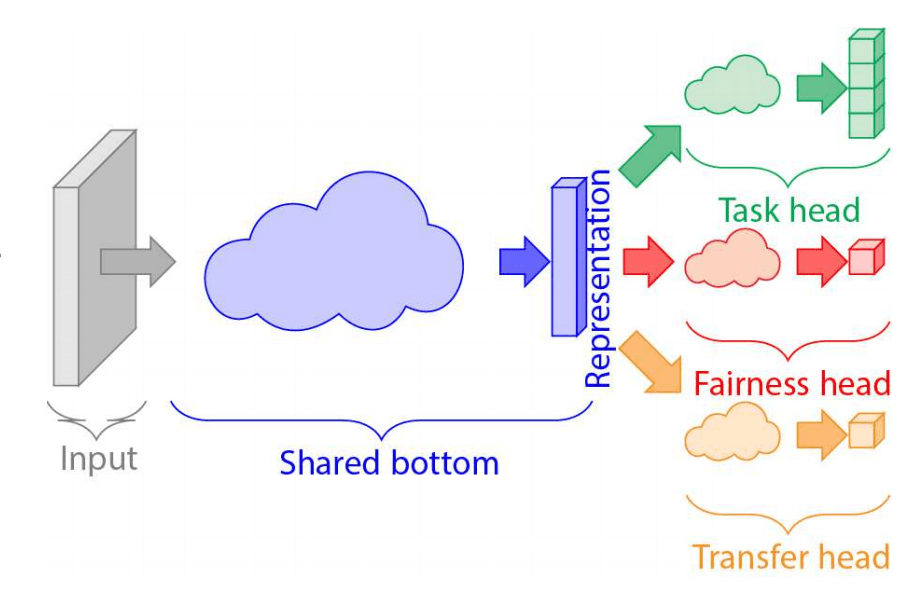
まず、入力はタブローデータと呼ばれるデータ形式で、性別や年齢などのデータが存在します。性別などの数字ではないカテゴリーデータはモデルに入力するために数字に変換します。その後、ニューラルネットワークに入力するわけですが、このままではスケールの違いが存在しますので、正規化処理などを行うのが一般的です。しかし、論文にそのような記述がなかったのでハッキリとはわかりません。とにかく、ニューラルネットワークによって入力データは32次元~128次元に埋め込まれます。(複数の次元でハイパーパラメータ探索を行なっている。)埋め込まれたベクトルが図中のRepresentationに当たります。以下、埋め込まれたベクトルのことをRepresentationベクトルと書くことにします。このRepresentationベクトルを用いて3つのタスクを行います。図に関して上から順に説明します。
- Task head
- AIに解かせたい任意のタスクです。
- 今回では、RepresentationベクトルからUCI Adultなら年収が50,000ドル以上かどうか、COMPASなら犯罪を犯すかどうかの確率を出力することになります。
- Fairness head
- Representationベクトルからセンシティブ属性の値を予測するタスクです。
- ここで重要なのが、Representationベクトルからセンシティブ属性の値を予測できることは良くない結果であるということです。なぜなら、Representationベクトルからセンシティブ属性の値を予測できるということは、Representationベクトルにセンシティブ属性の情報が残っているということが言えます。ならば、その情報はTask headにも渡されていることになります。センシティブ属性の情報を判別に用いることは良くないことなので、Representationベクトルからセンシティブ属性の値を予測できることは良くない結果であると言えます。よって、Fairness headの性能を下げるために、Fairness headに関しては負の勾配結果を逆伝播します。これで、よりセンシティブ属性の情報がRepresentationベクトルに残らないように学習が進むことになります。
- Transfer head
- Representationベクトルがどのドメインから来たベクトルかを予測するタスクです。
- Fairness headと同じようにどのドメインから来たベクトルかを予測できることは良くない結果です。どのドメインからきた値かを予測できることはRepresentationベクトルにドメインの情報が残っていることになります。我々が目指しているのは、ドメインに依存せずにタスクを達成するAIの設計です。したがって、Fairness headと同様に負の勾配結果を逆伝播します。これで、よりドメインの情報がRepresentationベクトルに残らないように学習が進むことになります。
以上の3つのタスクを行うことで、「予測精度が高い」かつ「Fairnessである」かつ「ドメインに依存しない」AIを作り出すことができます。
実験結果
下に実験結果を記載しました。
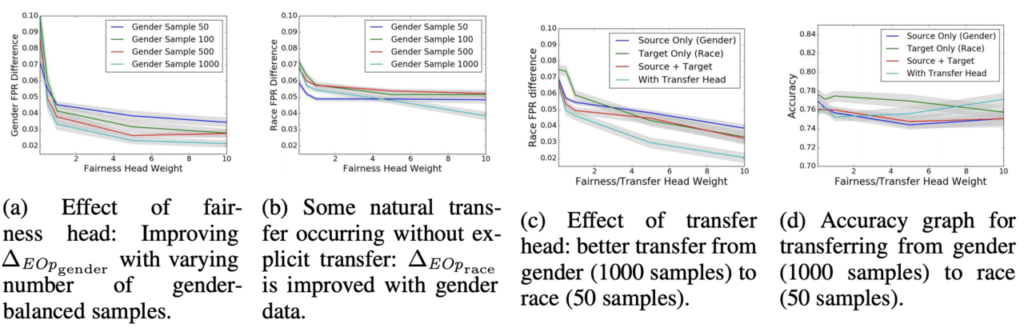
左から図(a)(b)(c)(d)となっており、下に説明を記載しました。(a)~(c)の縦軸に書かれているGender FRP DifferenceはEqual Opportunityから離れている度合いのことで、0に近いほどFairnessが達成できている値です。また、(a)~(d)の横軸には重みと書かれています。このフレームワークの目的関数にはどのheadをどれほど重要視するかを調節することができるハイパーパラメータが用意されています。重みとはそのパラメータのことです。重みは大きければ大きいほど重要度が高いことを示しています。
- (a)
- 横軸: Fairness headに対する重み
- 縦軸: ソースドメインにおけるEqual Opportunityから離れている度合い
- (b)
- 横軸: Fairness headに対する重み
- 縦軸: ターゲットドメインにおけるEqual Opportunityから離れている度合い
- (c)
- 横軸: Fairness/Transfer headに対する重み
- 縦軸: ターゲットドメインにおけるEqual Opportunityから離れている度合い
- (d)
- 横軸: Fairness/Transfer headに対する重み
- 縦軸: 精度
この図の見方を解説します。まず、(a)について。(a)は性別属性があるデータで学習し、性別属性があるデータでFairnessを計測した結果ですので、当然低い値に抑えられています。また、これも当然ですが、サンプル数が増えれば増えるほど低い値になっています。次に(b)について。(b)はTransfer head無しで、性別属性があるデータで学習し、人種属性があるデータでFairnessを計測した結果です。Transfer headが無いので、ドメイン間の違いをもろに受け、値を低く抑えられていません。(c)について。(c)はTransfer headありで、性別属性があるデータで学習し、人種属性があるデータでFairnessを計測した結果です。Transfer headがあるので、ドメイン間の違いをある程度解消でき、(b)に比べれば低く抑えられていることがわかります。最後に(d)について。(d)は(a)~(c)とは異なり縦軸がAccuracy(精度)となっています。水色の線を見ていただければわかる通り、Fairnessを達成するために少しの精度が犠牲になっていることがわかります。
まとめ
今回解説した論文では、異なるドメイン間におけるFairnessを達成するために3つのタスクを解かせるフレームワークを提案しました。提案された手法は非常にシンプルで、ドメイン適応における超有名な手法を取り入れただけです。このような手法がつい最近に発表されるということは、やはりFairnessという分野自体がまだまだ未成熟で、これから大きな発展が期待されるものではないかと筆者は考えます。Fairnessの発展を見届けるだけではなく、あなたもこの新興分野に身を投じてみるのも面白いかもしれませんね。



この記事に関するカテゴリー






