
進化したオフラインモデルベース強化学習!! 画像データから実ロボットを使ったタスクを解く?
3つの要点
✔️ 新しいOffline Model-based RLの手法であるLOMPOを提案
✔️ 潜在空間上で不確かさの定量化を行う
✔️ 実世界のロボットに対してもタスクを解くことが出来た
Offline Reinforcement Learning from Images with Latent Space Models
written by Rafael Rafailov, Tianhe Tu, Aravind Rajeswaran, Chelsea Finn
(Submitted on 21 Dec 2020)
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Robotics (cs.RO)

はじめに
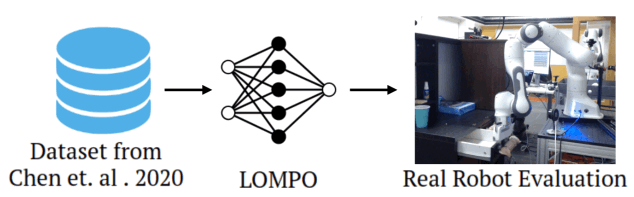
近年、様々な利点からonline RL (強化学習)だけではなく、offline RLに注目が集まっています。過去の論文では、online RLを低次元のstateを入力として学習を行うものが多かったのですが、画像を入力としてpolicy(方策)を学習することは、シミュレーションではなく現実世界のロボットに対して応用するために重要なことです。そこで、本記事では、画像を入力とした場合でもpolicyを学習することができるOffline model-based policy optimization (LOMPO)と呼ばれる手法を紹介します。この手法は、モデルベースであるために、その環境の遷移についてのモデリングを行い、それを元にpolicy optimizationを行うことでpolicyを得ます。下図は、本記事で紹介する手法の全体的な流れで、offline RLであることから、あらかじめタスクに関するデータが与えられます。そして提案手法であるLOMPOによりpolicyを学習し、最終的にロボットを使ってパフォーマンスを評価します。
では、なぜ画像を入力とした場合の、特にoffline model-based RLが難しいのでしょうか。今までのoffline model-based RLは、学習されたモデルにより生成されたobservationの不確かさを定量化し(予測のvarianceをとるなど)、不確かさが大きい際にpenalizeを行うなどをすることで、extrapolation errorや、未知のobservationによるエラー (error on out-of-distribution)を回避することを試みました。しかし、画像に対してこれを行うと、生成するものが高次元であるためにとても効率が悪く向いていません。そこで、提案手法であるLOMPOは、潜在空間上でのダイナミクスを学習し、潜在空間上で不確かさを定量化することで、画像を入力とした場合でもpolicyを学習することが出来るようにしました。では、詳しい手法について紹介していきます。
続きを読むには
(6791文字画像13枚)AI-SCHOLARに
登録いただく必要があります。



この記事に関するカテゴリー






