自動運転の可変シミュレータの生成:DriveGAN!
3つの要点
✔️ agentを制御可能なdifferentiable simulationの作成
✔️ Dynamics Simulatorを生成するDriveGANの提案
✔️ FVDやAction Consistencyなどの評価指標で高精度なシミュレータを生成することに成功
DriveGAN: Towards a Controllable High-Quality Neural Simulation
written by Seung Wook Kim, Jonah Philion, Antonio Torralba, Sanja Fidler
(Submitted on 30 Apr 2021)
Comments: Published as CVPR 2021 Oral.
Subjects: Computer Vision and Pattern Recognition (cs.CV); Robotics (cs.RO)
code:

概要
自動運転が公道で走るためには、何が必要でしょうか?近年では自動運転の公道での実験が可能になってきていますが、先日のWaymoの件では、片側車線が工事していたために道を誤って走行しまったというように、不十分な点も見受けられます (Waymo self-driving taxi confused by traffic cones flees help)。このように公道で実験を行う危険性や、天候や車両の台数など物理的な限界があるためにシミュレータを用いての実験が進められています。従来はこのようなシミュレータは人の手によって作成されていましたが、機械学習によって作成すすことで直接データから行動に応じた環境の変化を学習しスケーラブルなシミュレータを作成することができます。

そこで、この研究では機械学習技術を用いて自動運転の実証実験が可能なneural simulatorを生成しています。アテーションしていないフレーム列と対応する行動を観察することによってピクセル空間から直接動的な環境をシミュレートするように学習する、DriveGANを提案しています。DriveGANは教師なしで異なる構成物をdisentangling(もつれをほどくという意味で、画像空間から潜在空間、そして意味空間に写像して独立した集合として捉えられることで詳細は割愛します)することで制御性(controllability)を獲得しています。また、ハンドルによる制御に加えて、特定のシーンの特徴をサンプリングすることができ、天候や物体の位置を制御することが可能です。
DriveGANは完全に微分可能なシミュレータであるため、動画列を渡すとエージェントは同じシーンを再現することができ、同じシーン内で異なる行動を起こすことも可能です(re-simulation)。またDriveGANはVariational-Auto EncoderとGenerative Adversarial Networksによってdynamics engineが潜在空間の遷移を学習するように画像の潜在空間を学習させています。
Neural Simulatorとは
neural simulator は行動を伴う動画データを整理することでピクセル空間から直接エージェントの行動に応じた環境をシミュレートするように学習するもので、エージェントの行動以外の人間のアノテーションが必要ないことから、シミュレーションにおけるスケーラブルな方法となっています。
DriveGANについて
この研究の目的は動画列と対応する行動を観察することで高品質で制御可能なneural simulatorを学習することです。DriveGANは主に2つの側面から制御性を獲得しています。
- 与えた行動によって制御され得る自己エージェントが存在すること
- 現在のシーン物体や背景の色の変更などの異なり得る点を制御可能なこと
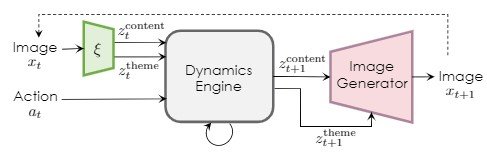
以下で使われている変数の設定をします。まず時間$t$の動画フレームを$x_t$、連続する行動を$a_t$と置きます。1からt秒目までの動画フレーム$x_{1:t}$と行動$a_t$を学習して次のフレームである$x_{t+1}$を生成します。Image encoder $\xi$は画像$x$においてdisentangleされた潜在変数$z^{theme}$と$z^{content}$を教師なし学習で生成します。ここで、themeとは背景の色や天候のピクセルの情報に左右されない情報のことで、contentは空間の要素を指します。
Dynamics Engineはrecurrent neural networkで構成され、現在の潜在変数と行動から次のステップの潜在変数を生成します。そして、生成された次のステップの潜在変数をimage decoderを用いて出力画像にします。
この研究では、World Modelを参考に、より高精度な時系列画像列を生成することに成功しています。次に画像を潜在空間に射影するために事前学習するencoder-decoderの構造について解説します。
Pre-trained Latent Space
DriveGANではStyleGANのimage decoderを用いて、theme-contentのdisentanglement用に若干改良しています。入力画像に対してGANの潜在変数を抽出することはnot trivial(自明でない)ため、encoder $\xi$を用いて明示的に画像$x$を潜在変数$z$へと射影します。ここで、損失関数のKullback Leibler項を制御するために、$\beta$-VAE を用いています。
StyleGANのadversarial lossをベースに以下のVAEの損失関数を追加してgeneratorを学習しています。
\begin{equation} L_{VAE} = E_{z \sim q(z|x)}[\log (p(x|z))] + \beta KL (q(z|x)||p(z)) \end{equation}
ここで、$p(z)$は標準事前分布で、$q(z|x)$はencoder $\xi$を用いた近似事後分布で、KLはKullback-Leibler情報量を表しています。再構成誤差を表す項では、ピクセル間の距離ではなく、入力と出力の画像間でのperceptual distance を減らすように学習しています。
制御可能なシミュレーションを作成するために、encoderとdecoderに工夫をしています。
・入力画像のthemeとcontentをdisentangle

encoder $\xi$は特徴抽出器$\xi^{feat}$と2つのencodingのヘッド$\xi^{content}$、そして$\xi^{theme}$で構成されています。$\xi^{feat}$は画像$x$を入力し、出力を2つのヘッドに渡すような複数の畳み込み層で構成されています。$\xi^{content}$は$ N x N$次元の$z^{content} \in \mathbb{R}^{N x N x D_1}$を生成します。その一方で、$\xi^{theme}$は出力画像のthemeを制御可能にするような単一ベクトルである$z^{theme} \in \mathbb{R}^{D_2}$を生成します。これらの潜在変数をまとめて、$z = \{ z^{content}, z^{theme} \}$で表します。
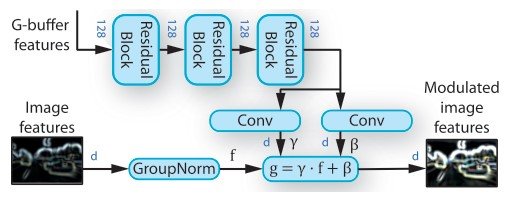
次に、ここで生成した潜在変数$z$をStyleGANのdecoderに入力します。StyleGANはgeneratorの各畳み込み層の後にadaptive instance normalization(AdaIN)を用いることで生成画像の見た目を制御することができます。AdaINは正規化された特徴量マップの空間的位置と同様のscalingとbiasを適応しています。
\begin{equation}AdaIN (m, \alpha, \gamma) = \mathcal{A}(m, \alpha, \gamma) = \alpha \frac{m - \mu(m)}{\sigma(m)} + \gamma \end{equation}
$m \in \mathbb{R}^{NxMx1}$は特徴量マップで$\alpha, \gamma$はscalingとbiasに対応する定数です。この$z^{theme}$をMLPに入力することでAdaIN層で用いられるscalingとbiasの値を得ます。
次に、$z^{content}$の形状より、$N x N$のグリッド位置に対応するcontent情報をencodeすることができます。通常のStyleGANでのブロック入力に代えて、ここでは$z^{content}$を入力としています。
さらに、グリッド位置のcontentを代替するために、標準事前分布から新たなベクトル$v \in \mathbb{R}^{1x1xD}$をサンプリングしています。これらのencodingに関する工夫を行うことで、AdaIN層で空間の位置とscalingとbiasが対応していることから、複数の物体が存在するシーンにおいて詳細な情報を得ることができるようになりました。また、discriminatorにはmulti-scale multi-patch discriminatorを用いており、より複雑なシーンの高精度な画像を生成することができます。損失関数はadversarial lossにはStyleGANと同じものを、そして、最終的なものは$L_{pretrain} = L_{VAE} + L_{GAN}$となります。
簡単な実験結果として、KL項で用いている$\beta$の値を小さくすることで再構成の品質が向上することがわかりましたが、学習した潜在空間はdynamics modelがdynamicsの学習が難しい場合に事前分布とはかけ離れた結果となることもわかりました。これは、$z$が$x$に過学習しているということで、過学習している潜在空間からの遷移の学習は今後の課題としています。
Dynamics Engine
上記のencoder-decoderで事前学習をした後、ここで紹介するDynamics Engineではステップごとに行動$a_t$を与えた遷移を、encoder-decoderで求めた潜在変数をもとに学習します。Dynamics Engineのパラメータのみを学習するために、encoderとdecoderのパラメータは固定しています。これによって学習する前にデータセットの潜在変数を事前に抽出することが可能となります。入力が潜在変数なので、画像で学習するよりも格段に早く学習可能です。また、潜在変数$z^{content}$から得たcontent情報をaction-dependentとaction-independentな特徴量にdisentangleしています。

3D環境では、視点は自己エージェントの動きに従って変化します。これの変化は空間的に自然に起こるため、各時間ステップでの空間遷移を学習するためにconvolutional LSTM moduleを行使しています。
また、$z_t$のみを入力とするLSTM moduleを追加しています。これにより、action $a_t$とは独立している情報を扱うことができます。
直感的には、$z^{a_{indep}}$はAdaIN層を通じて空間テンソルの$z^{a_{dep}}$のstyleを決めるために用いられています。$z^{a_{indep}}$自身はaction情報を得ることができないため、求める次のフレームを学習することができません。この構造では、物体の種類のようなaction-independentな特徴からシーンのレイアウトのようなaction-dependentな特徴をdisentangleすることができます。そのため、engineはdynamicsを学ぶには、action dependentな特徴のみを考慮すればよいことになります。こちらの方が小さなモデルで学習することが可能です。
次に学習です。学習では、adversarial lossとVAE lossで学習するために、GameGANの潜在空間における学習手順を拡張します。adversarial loss $L_{adv}$は2つのネットワーク ①latent discriminator ②temporal action-conditioned discriminatorから構成されています。
\begin{equation} L_{DE} = L_{adv} + L_{latent} + L_{action} + L_{KL} \end{equation}
$L_{adv}$はadversarial lossでhinge lossを用いています。また、真のデータに対して識別器の勾配にペナルティを課すように$R_1$の勾配正則化を行っています。$L_{action}$はactionの再構成損失で時間的な識別器の特徴量である$z_{t, t-1}$をlinear layerに通すことで入力したaction $a_{t-1}$を再構成し、それらの平均二乗誤差を計算しています。$L_{latent}$では、生成した$z_t$が入力した潜在変数にマッチしているかを測る損失関数で、KLペナルティを減らすように学習されます。
Differentiable Simulation
DriveGANは微分可能なので、動画を構成するいくつかの要因を見つけておくことで、シーンやシナリオを再現することが可能、エージェントのactionでさえも再現可能です。こういったシミュレーションをdifferentiable simulationと呼んでいます。構成するパラメータを見つけると、エージェントはDriveGANを用いて同じシーンで異なるactionを再シミュレーションすることができます。DriveGANはさらに、シーン内での様々な構成物をサンプリングしたり変化させることが可能なため、同じシナリオを用いて異なる天候や物体下でエージェントを実験することができます。
ここでのagentのテストを数式で表しています。
\begin{equation} \underset{a_{0 . . T-1}, \epsilon_{0 . . T-1}}{\operatorname{minimize}} \sum_{t=1}^{T}\left\|z_{t}-\hat{z}_{t}\right\|+\lambda_{1}\left\|a_{t}-a_{t-1}\right\|+\lambda_{2}\left\|\epsilon_{t}\right|| \end{equation}
$\epsilon$は確率変数でシミュレーション内で将来のシーンを確率的に生成します。現実の動画は$x_0, \ldots, x_T$で、$z_t$はモデルの出力、$\hat z_t$はencoderを用いて$x_t$をencodingした潜在変数、そして$\lambda_1, lamda_2$は正則化するためのハイパーパラメータです。actionの一貫性を保つために、$a_t$と$a_{t-1}$の正則項を用いています。
実験と評価
実験の設定
データセットにはいくつか用いており、自動運転用のシミュレータであるCarlaシミュレータ、物理エンジンと制御可能な仮想エージェントを有する現実世界の屋内の建物環境ををシミュレーション可能なGibson環境。そして、複数の街や高速道路で人間の運転を記録しているReal World Driving (RWD)を用いています。actionは2次元で、エージェントの速度と角速度から構成されています。
質的評価
シミュレータの質的側面は2つの視点で評価します。1つはシミュレータによって生成された動画が現実的なものであるか、とその分布が現実の動画の分布とマッチしているかどうか、そしてもう1つはactionが現実的に許容可能なものなのか、です。これらを測るために、2つの評価手法を作成して評価しています。
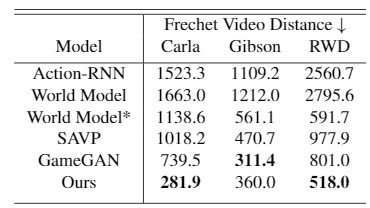
ベースラインとなるモデルは、シンプルなactionに従ったRNNモデルであるAction-RNN、Stochastic Adversarial Video Prediction (SAVP)、GameGAN、そして混合分布ネットワークがベースのRNNを用いて学習したWorld Modelです。以下が結果です。
評価手法として、1つ目に、Fr ́echet VideoDistance (FVD) を用いてground truthと生成動画の分布の距離を測っています。
また、人間による評価においても高品質な結果となっています。

2つ目は、actionの一貫性を測るための指標で、現実の動画から抜き出した2つの画像をCNNで学習し、画像内の遷移を表すactionを予測しています。そして、入力したactionと予測したものの平均二乗誤差を減らすようにモデルを学習します。

Differentiable Simulation
DriveGANでは事前分布からサンプリングした潜在変数$z^{a_{dep}}, z^{a_{indep}}, z^{content}, z^{theme}$を用いてシミュレーションを制御することができます。
以下の図では$z^{theme}$をサンプリングし変化させることで背景色や天候を変えることができています。
異なる$z^{a_{dep}}$をサンプリングすることで以下のようにインテリアを変化させることができます。

また、$z^{content}$は空間テンソルで各グリッドセルを変化させることで対応するセルの構成要素を変えることができます。
終わりに
DriveGANは制御可能な高品質なシミュレーションを提案しました。DriveGANはencoderとimage GANを用いてdynamics engineがフレーム間での遷移を学習できるように潜在空間を生成しています。教師なしでシーンの異なる構成物をdisentanglingしサンプリングすることに成功しています。これによりユーザはシミュレーションを行う際にインタラクティブにシーンを編集することができ、ユニークなシナリオを作ることができます。今後この研究によって、differentiable simulationをロボットや自動運転などのテストにコストがかかる実験の環境づくりが期待されます。
また、現在コードが公開されたら(執筆時:2021年6月7日)、以下のようなUIでシミュレータを使用することができると思うので、楽しみですね!






この記事に関するカテゴリー






