未知の生態物質miRNAから疾患を予測できるのか!?強化学習を活用した、疾患予測モデルの提案
3つの要点
✔️ 未知のmiRNAと疾患における関連の予測を目的とした、シミュレーターの開発を目指す
✔️ Q-learningアルゴリズムをベースとした3つのサブモデル—CMF、NRLMF、LapRLS—を組み合わせ、最適な重みに最適化
✔️ 3つの疾患を対象にケーススタディをおこなった結果、大腸新生物と乳房新生物に関連する上位50のmiRNAを全て確認された
RFLMDA: A Novel Reinforcement Learning-Based Computational Model for Human MicroRNA-Disease Association Prediction
written by
(Submitted on 5 Dec 2021)
Comments: Biomolecules
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
背景
未知のmiRNAと疾患の関連を予測することは可能なのか?
本研究では、新たなリキッドバイオプシー—身体の負担が少ない低侵襲性の検体:血漿や尿など、を利用した診断技術—として注目されている、miRNAと疾患の関連をシミュレーションするシステムを提案しています。miRNAは、がんをはじめ、各種疾患と関連性が高いといわれている生体物質で、研究が盛んにおこなわれています;一方、分野の新規性から、未解明なことが多く、生物学的実験が解析手法の主流となっており、実施上の課題—規模が小さい、人手や材料資源への投資が大きいなど—が存在しています。そのため、実験のコスト削減を目的として、未知のmiRNAと疾患の関連における、方向性を指し示すシミュレーションが必要とされています。本研究では、こうした課題に対し、強化学習のQ-learningをベースとし、3つのサブモデル—CMF, NRLMF, LapRLS —を組み合わせたシミュレーションモデル—RFLMDA—を提案し、未知のmiRNAと疾患の関連性を高い精度で予測することを目指しています。
miRNAとは
まず初めに、本研究の解析対象である、miRNAについて簡単に解説します。
miRNAは、21-25塩基(nt)長の1本鎖RNA分子であり、真核生物において遺伝子の転写後発現調節に関与する生体物質です。ヒトゲノムには1000以上のmiRNAがコードされていると考えられ、標的mRNA—メッセンジャーRNA—を不安定化させ、翻訳抑制を通して、タンパク質産生を抑制します。人体を構成するタンパク質は、一般にセントラルドグマ—DNAからmRNAへと変換するプロセス:転写、と、mRNAからタンパク質へと変換するプロセス:翻訳—によって、DNAからタンパク質に変換されます。miRNAは、このプロセスの後者—翻訳—における最も重要な調節因子であり、疾患の発現をはじめとする、多くの生体現象と関連している、と考えられています。特に、特定のがんタイプ・ステージにおいて特異的な発現があり、また、多数の疾患やウイルス感染の識別においても関連性が高いことが報告されています。そのため、疾患診断の新規バイオマーカーや予後マーカーとして活用することができ、また、miRNAを用いた遺伝子治療の可能性が期待されています。
一方、miRNAが比較的新しく発見された分野であることから、未解明なことが多く、解析には、生物学的実験が主流となっています;そのため、こうした解析が抱える課題—規模が小さい、人手や材料資源への投資が大きい、実験期間が長い、制限が存在する—が存在しています。こうした背景から、miRNAと疾患の関連性に対して、一定の方向性を指し示すシミュレーターを開発し、生物学的実験の課題・コストを低減させる必要があります。
研究目的
本研究では、こうした課題—実験コストの削減—を解決するため、3つのモデルと強化学習を活用し、miRNAと疾患の関連性をシミュレートする手法—RFLMDA—を提案しています:具体的には、強化学習のQ-learningアルゴリズムをベースに、3つのサブモデル—CMF、 NRLMF, LapRLS—を組み合わせ、最適な重みSを割り当てます。こうした提案モデル—RFLMDA—に対する評価結果として、高い予測精度を達成したことが示されています:他の手法との比較し,RFLMDAがより良い予測精度—AUC、AUPR—を持つことが明確になりました;8つの疾患に対するシミュレーションの結果、これらの疾患に関連する上位50のmiRNAの多くが導出されたことを報告しています。
手法
データセット
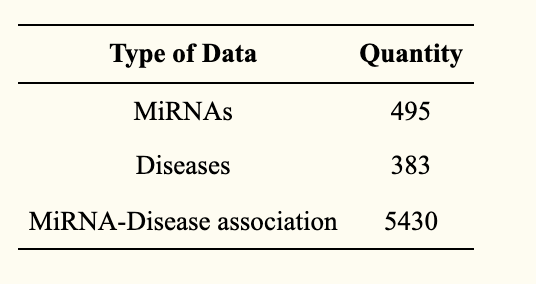
データセットには、ヒトにおけるmiRNAと疾患の関連データベース—HMDD v2.0 (http://www.cuilab.cn/hmdd, accessed date on 15 October 2021) —から取得したデータを活用しています(下表参照)。
また、miRNA間には相互作用があり、こうした相互作用が生物学的プロセスに影響を与える、と推察されます。そのため、本研究では、495行、495列のmiRNA機能的類似性隣接行列(下式)を構築し、こうした影響を考慮した学習をおこないます:下式では、行列の各要素は、2つのmiRNAの間の機能的類似性スコアを指します。
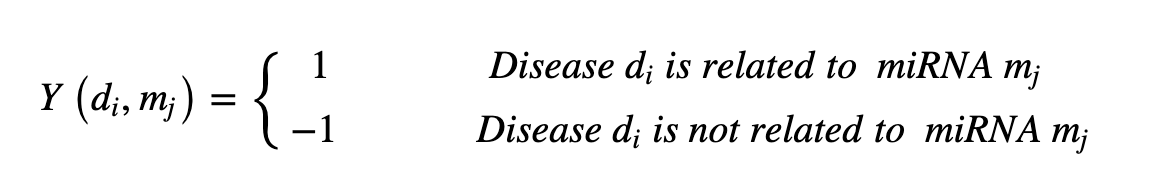
また、疾患についても、互いに類似性を持つことが想定されるため、意味的な類似性を定義しています(下式):各疾患は有向無サイクルグラフ(DAG)—ドットは疾患を、エッジは疾患間の関係を表す有向グラフ—をベースとして登用されています。
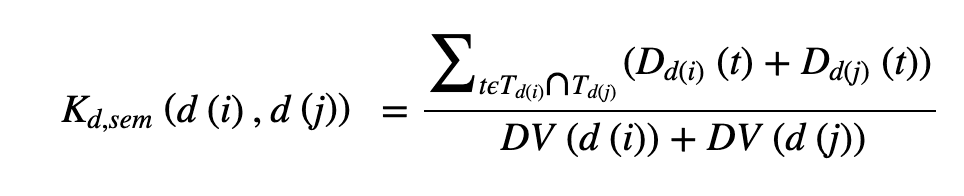
サブモデル
ここから、提案手法のベースとなっている、3つのサブモデル—CMF、NRLMF, LapRLS—について述べていきます。Collaborative Matrix Factorization(CMF)は、推薦システム関連—格付け予測やコールドスタート推薦など—で使用される古典的なモデルの一つです:具体的な動作として、目的関数(下記)の最小化をおこないます—A:miRNAの特徴行列、B:疾患の特徴行列、F:予測されるmiRNAと疾患の相互作用の行列、を指します。
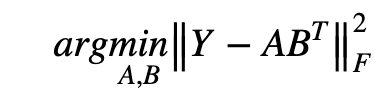
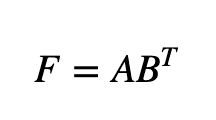
次に、Neighborhood Regularized Logistic Matrix Factorization (NRLMF)について述べます。このモデルは、ロジスティック行列因子法(LMF)と正則化を組み合わせ、関連を予測するモデルです。目的関数(下式)の最小化において、特定の変数—下式のU、V—に関する微分値を計算し、極値をもとに最適化をおこないます。
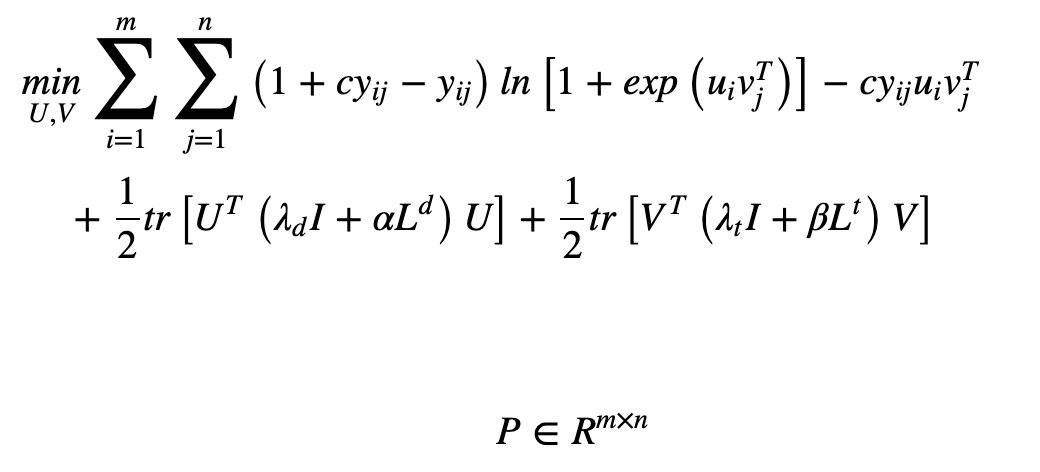
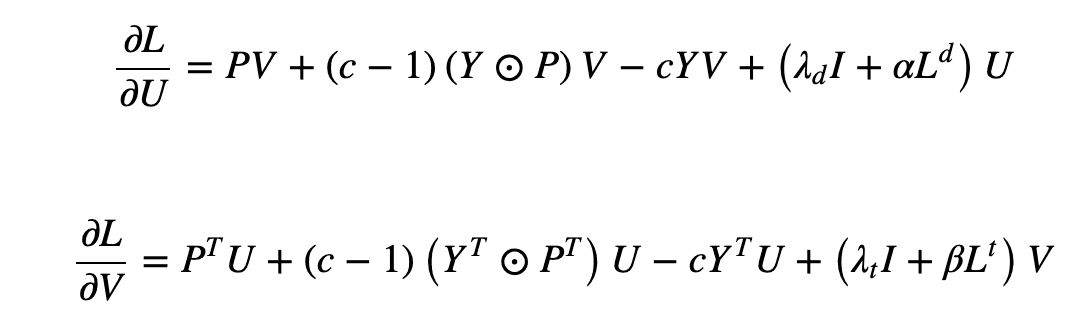
最後は、半教師付き学習法の一種である、Laplacian Regularized Least Squares (LapRLS)です。このモデルは、最近傍グラフを構築し、正則化を活用しています—最小二乗損失関数の係数にラプラシアングラフを導入しています(下式)。また、特徴として、大きく2点挙げられます:モデルのシンプルさ;ラプラシアン正則化サポートベクターマシンと同等の性能。
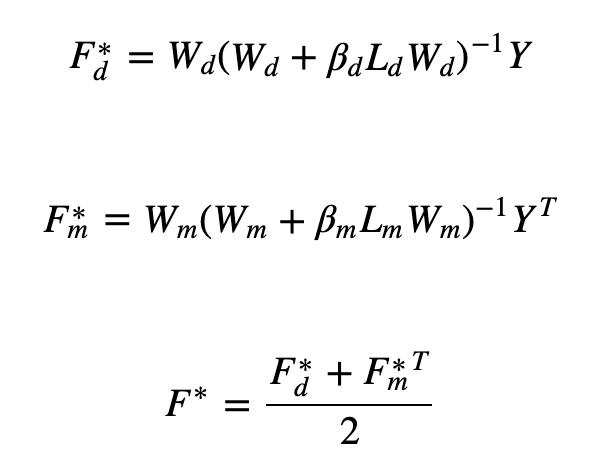
提案モデル
提案モデルでは、強化学習のアルゴリズムの一種Q-learning を活用し、上記3モデル—CMF、NRLMF, LapRLS—に対する最適な重みづけを割り当てることで構成されます。強化学習は、主に4要素—エージェント、報酬、環境状態、行動—を用いて学習をおこないます:エージェントは行動を起こすことで環境を操作し、現在状態から次の状態へ移動;タスクが終了後、エージェントには正、もしくは、負の報酬が与えられます。強化学習は累積報酬の最大化を目的として行動を選択することで、状況に応じた最適な解を導出することが特徴の一つです。

また、こうした強化学習で頻繁に使用されるのが、Q-leaning—マルコフモデルをベースにベルマン方程式で解き、時間差法を用いてオフポリシー学習を行うValue ベースの学習アルゴリズム—です(下図参照)。
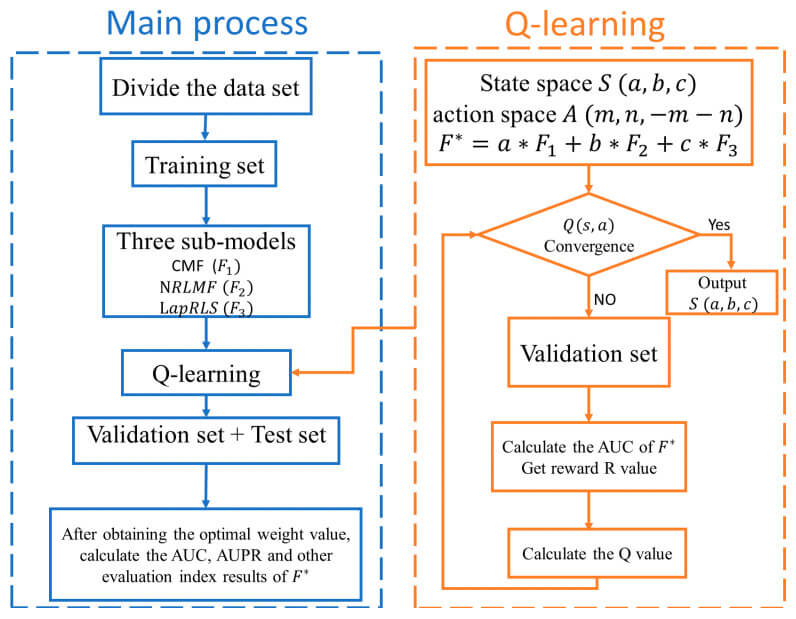
こうした手法をベースとして、提案モデルでは、最適な重みの導出し、各モデルに割り当てます:5 fold cross-validation—データセットを訓練集合、検証集合、テスト集合に8:1:1の割合で分割—により、最適な重みを導出し、組み合わせます。
強化学習における行動選択の評価指標として、AUCの差分を活用してます—Validationの各ラウンドで新しいAUCが生成され、AUCの差を報酬の指標とします:次の状態と今の状態におけるAUCの差が0より大きい場合、プラス1の報酬を与えます;そうでなければ、マイナス1の報酬を与えます。これらの連続的な反復学習により、報酬を連続的に収束させ、最適解に近づけます。具体的な提案モデルのアルゴリズムは以下のとおりです。
結果
本評価は、提案モデルにおける、最適な重みの導出およびmiRNAと疾患の関連性に対する予測精度の導出を目的としておこなっています。
評価指標
評価指標として、AUC(Area Under Curve)—ROC曲線と横軸で囲まれた平面グラフの面積、値の範囲:0~1—とAUPR (area under the PR curve)—PR曲線(precision recall curve):X軸をRecall、Y軸をPrecision、の囲まれた面積—を用いています。
既存モデルとの比較
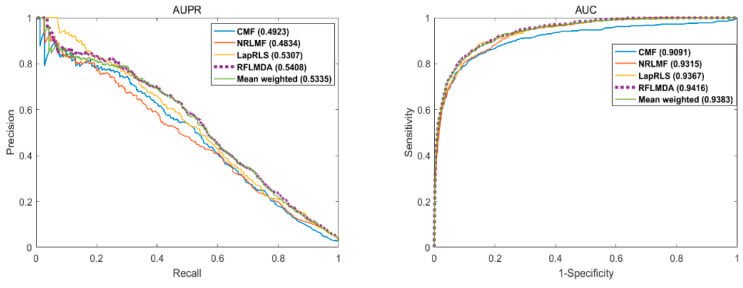
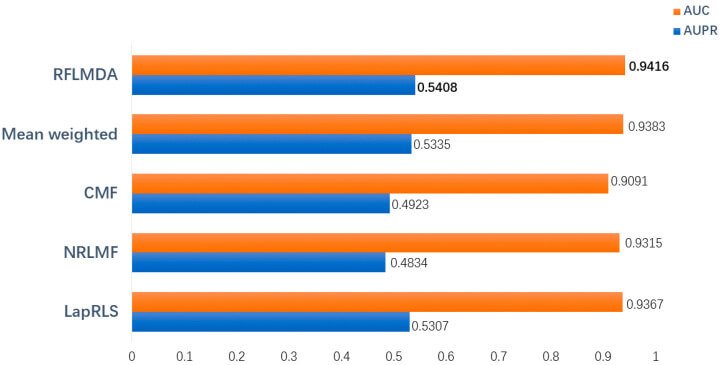
本評価は提案モデルであるRFLMDAの予測性能を導出する目的でおこなわれました。具体的には、提案モデルを含めた五つのモデル—RFLMDA 、Mean weighted:3つのサブモデル1/3の重みを付与、CMF、NRLMF、LapRLS —と比較し、上記の評価指標—AUC・AUPR—を導出しています。評価結果(下図)から、提案モデルが最も性能が高いことが示されています。
ケーススタディ
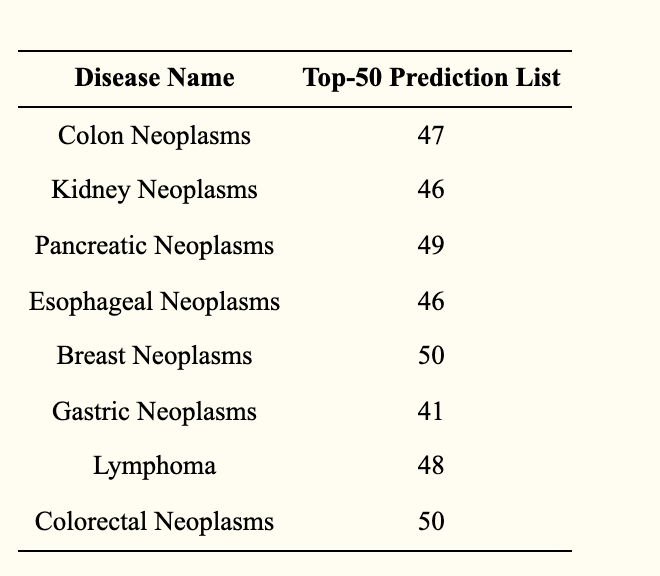
本評価は、モデルRFLMDAの予測性能をさらに明確にするために、ケーススタディを活用しています—この評価により、予測性能をより、客観的・効果的に評価できます。ここでは、HMDDにて報告されている、miRNAと疾患の関連を、8つの疾患—乳房腫瘍、胃腫瘍、大腸腫瘍、膵臓腫瘍、食道腫瘍、腎臓腫瘍、リンパ腫、大腸新生物—を対象に調査しています。評価結果(下表)から、これらの疾患において、関連性の高いmiRNAの上位50の多くが推定されていることがわかります。
考察
本研究では、強化学習のQ-learningアルゴリズムをベースとし、3モデル—CMF, NRLMF, LapRLS —を組み合わせたモデル—RFLMDA—を提案しています。本モデルでは、3モデルに対する重み:Sを、複数回の反復更新を通じて最適値になるように学習を行います。 5 fold cross -validationによる評価の結果,最適な重みは S (0.1735,0.2913,0.5352) となり、さらに高い予測精度を持つことが示されました—AUC:0.9416。 また、他手法との比較により、RFLMDAモデルがより高い性能を持つことが示されました。
RFLMDAの予測性能をさらなる検証として、8つの疾患に対するケーススタディとして、追加評価をおこなっています。その結果、大腸新生物と乳房新生物に関連する上位50のmiRNAを全て確認し、胃がん、大腸がん、膵臓がん、食道がん、腎臓がん、リンパ腫に関する上位50のmiRNAのうち、それぞれ41、47、49、46、46、48のmiRNAを確認しています。こうした評価結果から、RFLMDAは、miRNAにおいて、信頼性が高い候補を導出することができる、と示されました。
提案モデルの特徴として、miRNA-疾患関連予測の性能とプログラムの実行速度の最適化が考えられます。miRNAそのものの概念が新しいため、未知のmiRNAと疾患の関連性をシミュレーションできるツールは高い必要性がある、と考えられます。そのため、提案モデルにて未知のmiRNAと疾患における関連度に方向性を示し、ヒトの疾患治療や遺伝子医薬品の開発をより効果的に進展させられる、と考えられます。
一方、課題として、活用したモデルによる性能への制約、評価対象となる疾患以外の性能が不透明であること、が考えられます。前者では、今回採用した3モデル—CMF, NRLMF, LapRLS—の性能によって、提案モデルの予測精度が変化しうる、ことが考えられます;こうした課題に対しては、その他の学習モデル・分類モデルを組み合わせたモデルで試験する、などが検討されます。また、後者では、ケーススタディ以外の疾患—特に解決への需要の高い生活習慣病:糖尿病、心血管疾患など—における追加的な評価をおこなうことが必要となる、と考えられます。疾患ごとの特徴もあるため、必要に応じて、Q-learining以外のアルゴリズム—モデルベース学習:動的計画法(DP)、その他のモデルフリー学習:SARSA、モンテカルロ法—や、今回定義された類似度行列の再定義、が必要になると考えられます。





この記事に関するカテゴリー





