高速道路の新MDP!拡張可能な状態定義(前半)
3つの要点
✔️ 運転におけるPlanning(経路計画)
✔️ 高速道路での新しいMDP(Markov Decision Process)
✔️ 強化学習と逆強化学習の組み合わせ
Advanced Planning for Autonomous Vehicles Using Reinforcement Learning and Deep Inverse Reinforcement Learning
written by C You, J Lu, D Filev, P Tsiotras
(Submitted on 2019)
Comments: Robotics and Autonomous Systems 114 (2019): 1-18.
Subjects: 分野 (Machine Learning (cs.LG); Machine Learning (stat.ML))
はじめに
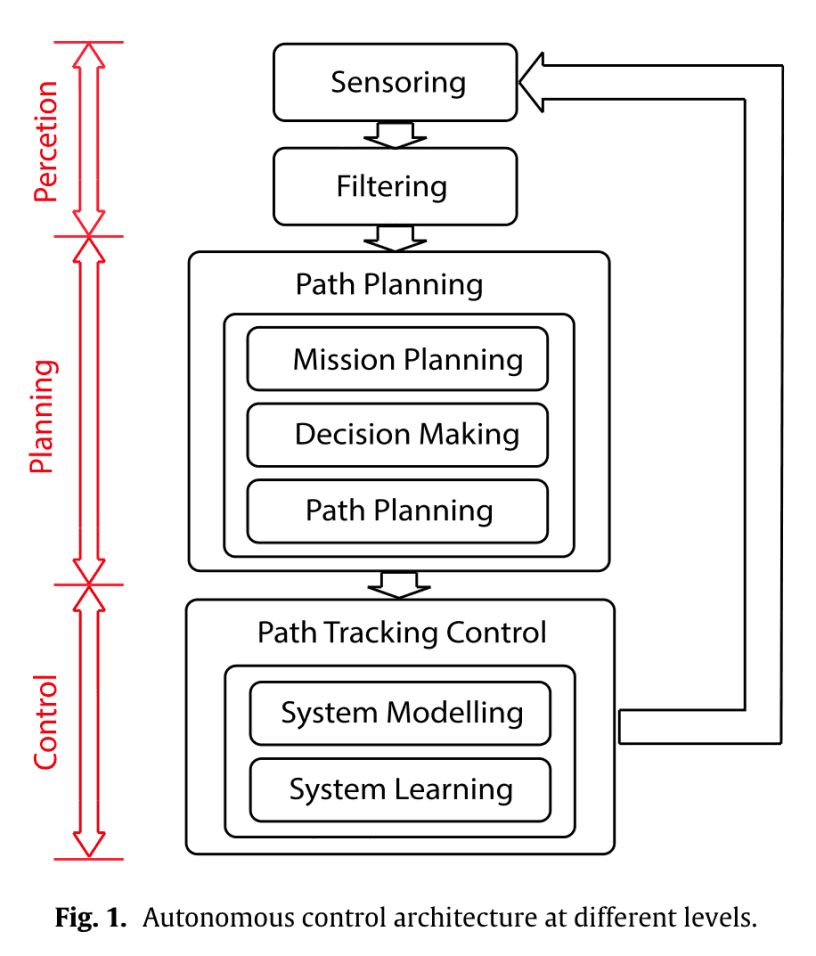
ドライバーのミスによる事故が多発しています。そのため,自動運転への関心が高まっています。自動運転には次図のように,知覚(Perception),計画(Planning),制御(Control)の3つのレベルがあります。本論文は,計画(Planning)の部分に関する研究です。
貢献
本論文の貢献は主に以下の3つです。
- 高速道路における新しいMDPモデル
- 道路の形状を考慮しており,拡張が容易
- 状態空間が大きくならないように車両の速度は削除
- Max Ent IRLの一般化による任意の非線形報酬関数
- モデルフリーのMDPのための3つのMax Ent deep IRLの提案
MDPはマルコフ決定過程(Markov Decision Process)のことです。本記事では前半部分として,提案手法の部分までを紹介いたします。後半では実験と結果を紹介いたします。それでは,論文を見ていきましょう。
交通モデリング
マルコフ決定過程
まずは基礎的なマルコフ決定過程の説明です。マルコフ決定過程はロボット工学,経済学,製造,自動運転など幅広い分野で使用されています。マルコフ決定過程はエージェントと環境の間の相互作用を確率論的にモデル化する数学的フレームワークです。エージェントは,タイムステップごとに報酬と環境の状態の表現(観測)を受け取り,行動をします。
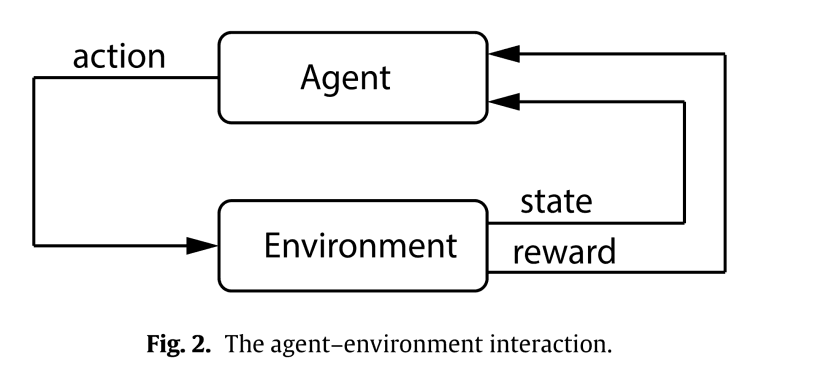
典型的なマルコフ決定過程は6つのタプルで構成されています。
$$(S, A,{\cal T},\gamma, D, R)$$
- $S$: 取りうる状態の集合(有限)
- $A$: 取りうる状態の集合(有限)
- ${\cal T}$: 状態遷移確率行列(すべての状態のペア)
- $\gamma$: 割引率$\gamma\in [0,1)$
- $D$: 初期状態分布
- $R$: 報酬関数
マルコフ性とは,将来の確率分布が,現在のみに依存し,過去に依存しない特性のことをいいます。式でいうと,$s$を状態,$a$を行動とすると,以下の式を満たす性質です。
$${\mathbb P}(s_{t+1}|s_t,a_t,s_{t-1},a_{t-1},...,s_0,a_0)={\mathbb P}(s_{t+1}|s_t,a_t) \tag{1}$$
マルコフ決定過程の問題は方策$\pi:S\rightarrow A$を見つけることです。最適な方策は以下の式で定義できます。
$$\pi^* = \arg\max_\pi {\mathbb E}\Biggl[\sum_{t=0}^\infty\gamma^t R(s_t,\pi(s_t))\Biggr] \tag{2}$$
また,マルコフ性を方策$\pi$を用いた式で表すと,
$${\mathbb P}^\pi(s_{t+1}|s_t)={\mathbb P}(s_{t+1}|s_t,\pi(s_t))\tag{3}$$
システムモデリング
ここでは次図のような高速道路のシナリオを想定して,マルコフ決定過程のモデリングを行います。
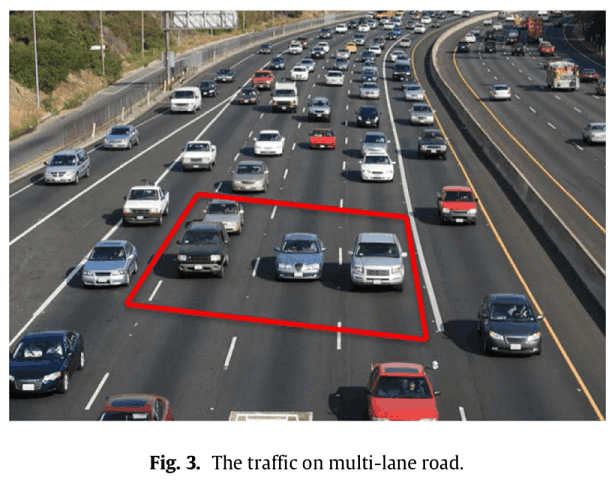
制御対象の車をHV(host Vehicle),その他すべての車をEVs(Environmental Vehicles)とします。行動集合${\cal A}$は{"速度維持", "加速", "減速", "左折", "右折"}です。
・状態定義
状態は,次図のように表わされます。
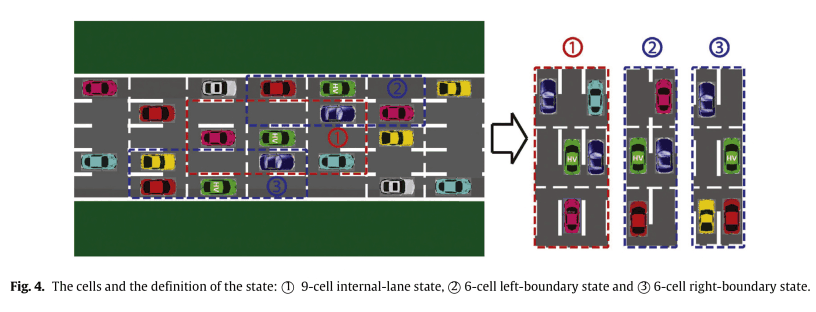
中央の車線にいる場合は9マスのセル,左右どちらかの端のレーンにいる場合には6つのセルで,状態が表現されます。図の緑色の車がHVであり,今回のエージェントです。この場合,周りのEVsが存在するかしないかをそれぞれカウントし,マルコフ決定過程の数は$2^8+2\times 2^5=320$です。この定義により,レーン数(2以上)や車の数が変化しても容易に拡張できます。
今回は,次図のようなカーブについても考慮します。
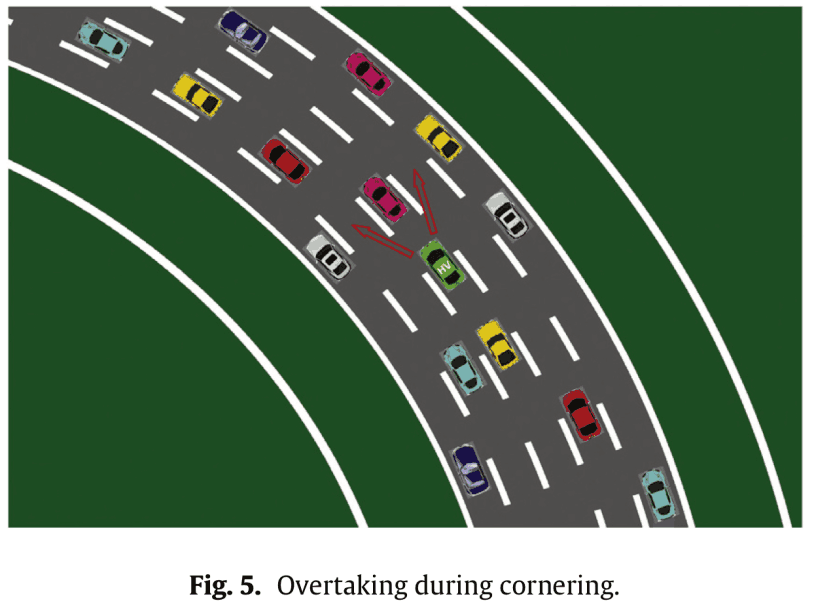
カーブでは,内側から追い越す場合と外側から追い越す場合という違いがあるため,今回は,直線,左カーブ,右カーブの3種類を考慮します。つまり,マルコフ決定過程の数は$320\times 3=960$となります。
このように,必要に応じてさらなるクラス分類が可能です。例えば,上り坂,下り坂,平坦などです。
・状態遷移
続いて状態遷移です。状態遷移には以下の仮定があります。
- レーン数$n$: $n\geq 2$
- EVs数$N$: $0\leq N\leq 8$
- EVsはHVとは異なる独自の方策を持つ
- EVsの行動はランダム
- EVsの方からHVに衝突することはない
- 各車両は各タイムステップで1つの行動をする
以上の仮定をもとに,状態$s_t$から$s_{t+1}$への遷移には2つのステップがあります。
- HVは$s_t$を観測し,現在の方策に従い行動$\pi(s_t)$
- EVsはHVの動作に従い,ランダムな行動をとる
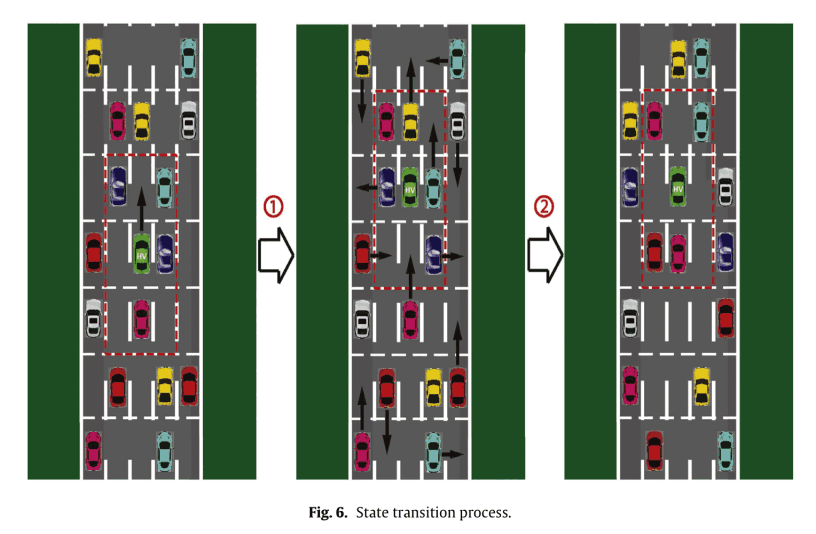
次図の例で説明すると,HVの安全な行動は加速か左への車線変更です。今回は加速が選択され,それに応じて周囲のEVsが安全なランダム行動をとります。
強化学習
強化学習アルゴリズムの選択
主な強化学習アルゴリズムは表形式か関数近似法です。表形式は有限で小さい状態行動空間のマルコフ決定過程を解くのに適しています。例えば,動的計画法,モンテカルロ法,TD学習法です。
従来の動的計画法は,価値関数を使用して最適方策の検索をします。例えば,価値反復法や方策反復法です。しかし,環境の完全な知識を必要とし,連続状態行動空間には使用できません。モンテカルロ法では,環境の完全な知識を必要としません。代わりに,環境とエージェントの相互作用の状態,行動,報酬のサンプルシーケンスが必要です。エピソードごとにサンプルリターンを平均化する,つまり,価値と対応する方策の学習は各エピソードの終了時に行われます。そのため,オンライン学習ができません。TD学習法は,動的計画法とモンテカルロ法を組み合わせたもので,利点は環境の完全な知識を必要としないことと,オンライン学習ができることです。例えばSarsaやQ-learningです。
SarsaとQ-learningの違いは現在の状態行動価値を更新する際に参照する将来の状態行動価値です。Sarsaは"state-action-reward-state-action"の略で,現在の状態における行動価値を更新するために,次ステップでのエージェントの行動価値を使用します。対して,Q-learningは,エージェントが次ステップで取りうる最大のこうどうかちを探索し,その値を使用して現在の状態での行動価値を更新します。よって,Sarsaはオンポリシーアルゴリズム,Q-learningはオフポリシーアルゴリズムです。
Q-learningはε-greedy法によって,各エピソードで簡単に"death"を引き起こすことができ,より良い方策を潜在的に提供できます。"death"とはエピソードが特定の状態(目標状態)に到着することで,エピソードを終了することです。
関数近似法は大規模または連続的な状態空間の問題に使用され,一連の(非線形)関数を使用して,価値,方策,報酬を表すことができます。理論的には,教師あり学習の領域で使用されるすべての方法は関数近似として強化学習に使用できます。例えば,ニューラルネットワークやナイーブベイズ,ガウス過程,サポートベクターマシンです。
前章で説明したマルコフ決定過程のモデルは状態と行動の数が有限であり,エージェントがEVsの動作を予測しないため,表形式でモデルフリーの方法を使用します。
・報酬関数
続いて,強化学習において重要な報酬関数についてです。運転タスクでは,ドライバーの行動を特徴付けることが難しく,実際の報酬関数が不明なので,報酬関数の設計は困難な作業です。また,報酬関数はドライバーごとに異なる可能性もあります。広く使われている報酬関数の設計方法としては,手動で選択した特徴の関数として表すことです。特徴はエージェントの行動と,環境の状態によって異なります。今回は特徴の線形結合を用いて報酬関数を表します。
$$R(s,a)=w^T\phi(s,a)\tag{4}$$
ただし,$w$は重みベクトル,$\phi$は特徴ベクトルです。
今回,$\phi$は以下の5つの要素で構成されています。
- 行動特徴
- HVの位置
- 追い越し戦略
- 共連れ
- 衝突事故
1では,ドライバーはより高い報酬が得られる特定の行動を好む可能性があります。2は,HVが道路の境界近くを走行しているかどうかです。3では,コーナーで追い越す際に,内側からか外側からか追い越しの好みがあるかもしれません。4は,HVがEVの背後にいるかどうかです。5は,HVとEVが同じマスにいるかどうかです。
これらの特徴べき取るを使用して,特定の特徴を奨励または罰するように重みベクトル$w$を設計し,強化学習を使用して合計報酬を最大化する最適方策を学習します。
別のアイデアとしては,ガウス過程やDNN(Deep Neural Netwark)などのパラメータ化された関数近似器を用いて報酬関数を設計することです。関数近似器のパラメータは,明確な物理的意味と直接関係していない可能性があるため,手動で設計することは難しく,データから学習します。
最大エントロピー原理と報酬関数
前章のアプローチでは,報酬関数の事前知識が不十分な場合不便です。そこで,報酬関数の手動での設計を回避して,エキスパートドライバーのデモから最適な運転方策を直接学ぶことができる,逆強化学習を用います。
最大エントロピー原理
最大エントロピー原理は,コンピュータサイエンスと統計学の多くの領域で利用されてきました。基本的な定式化では,ターゲット分布からのサンプルセットとターゲット分布に対する一連の制約が与えられ,制約を満たすような最大エントロピー分布を使用してターゲット分布を推定します。逆強化学習問題では過去の状態と行動からなるエージェントの時間履歴(デモ)が与えられ,報酬関数を推定します。以前の逆強化学習では報酬関数が一意に定まらないという課題がありましたが,最大エントロピーの原理を用いることによって,解を一意に決定できるようになりました。最初の最大エントロピー原理による逆強化学習(Maximum Entropy Inverse Reinforcement learning; Max Ent IRL)では,報酬関数は現在の状態にのみ依存し,特徴関数の線形結合で表されます。
$$R(s)=\sum_i w_i \phi_i(s)=w^T\phi(s)\tag{5}$$
また,デモ$\zeta \triangleq \{s_0,a_0,...,s_T,a_T\}$の確率は
$${\mathbb P}(\zeta|w)=\frac{1}{Z(w)}e^{\sum_{s\in \zeta}w^T\phi(s)}\tag{6a}$$
$${\mathbb P}(\zeta|w)=\frac{1}{Z(w)}e^{\sum_{s\in \zeta}w^T\phi(s)}\prod_{(s,as')\in\zeta}{\mathbb P}(s'|s,a)\tag{6b}$$
式(6a)が決定的マルコフ決定過程,式(6b)が確率的マルコフ決定過程を表します。式(6)のどちらの式も,パス(デモ)上の分布を示し,パスの確率がその報酬の指数に比例することを示します。これは,より高い報酬を持つパスがエージェントにとってより好ましい(確率が高くなる)ことを意味しています。逆強化学習の目標は,観測されたデモの尤度が式(6)の分布の下で最大になるような最適な重み$w^*$を見つけることです。
以下,新しい報酬構造を用いて逆強化学習問題を定式化していきます。
- $R(s)$ではなく,$R(s,a)$($\phi(s,a)$)を使う
- 確率的マルコフ決定過程を扱う
- デモは同じ状態$s_0$から開始する必要があり,$t=0$から$t=T$の同じ長さの期間にわたって観測される
表記
- $D$: デモのセット
- $N$: $D$内のデモの数
- $\Omega \supseteq$: 完全なパス空間
- $\phi_\zeta$: パス$\zeta \in D$に沿った特徴の数($\phi_\zeta = \sum_{(s,a)\in\zeta}$)
非パラメータ化特徴
まずはパラメータ化されていない,つまり,ニューラルネットワークなどで近似されていない場合の特徴について考えてみましょう。パラメータ化されていない特徴$\phi(s,a)$は状態と行動のみの関数です。これを用いて,報酬関数は次の形式の特徴の線形結合としてみなすことができます。
$$R(w;s,a)=w^T\phi(s,a)\tag{7}$$
報酬関数が未知の重みベクトル$w$に依存することを明示するため$R(w;s,a)$と表記しています。関連研究[2]より,観測値$D$の特徴制約の影響を受ける$\Omega$上の分布のエントロピーを最大化することは,式(6b)の最大エントロピー分布の下での$D$の尤度の最大化に同じです。つまり,式で表すと以下のようになります。
$$w^*=\arg \max_w {\cal L}_D(w)=\arg\max_w \frac{1}{N}\sum_{\zeta\in {\cal D}}\log{\cal P}(\zeta|w)\\ =\arg \max_w \frac{1}{N}(\sum_{\zeta\in{\cal D}}(w^T\phi_\zeta + \sum_{(s,a,s')\in\zeta}{\mathbb P}(s'|s,a)))-\log Z(w) \tag{8}$$
パラメータ化特徴
パラメータ化されていない特徴を使うには,手動で特徴を設計する必要がありますが,複雑な形式を持つ未知の報酬関数を上手く設計できるとは限りません。一般には困難な作業になります。そこで,パラメータ化された特徴を使います。パラメータ化された特徴を使うことで,パラメータを最適化することにより,手動で特徴を設計することを回避します。Max Ent IRL問題を定式化するために,特徴の線形結合で表される報酬関数を考えますが,特徴はパラメータ$\theta$に明示的に依存します。
$$R(w,\theta;s,a)=w^T\phi(\theta;s,a) \tag{9}$$
式(8)で重み$w$のみを調整するのではなく,$\theta$も調整し,次のように尤度${\cal L}_D$を最大化します。
$$w^*,\theta^*=\arg\max_{w,\theta} {\cal L}_D(w,\theta)=\arg\max_{w,\theta}\frac{1}{N} \sum_{\zeta\in {\cal D}}\log {\mathbb P}(\zeta | w,\theta)\\ =\arg\max_{w,\theta} \frac{1}{N} (\sum_{\zeta\in {\cal D}}(w^T\phi_\zeta(\theta)+\sum_{(s,a,s')\in\zeta}{\mathbb P}(s'|s,a)))-\log Z(w,\theta)\tag{10}$$
パラメータ化の様子を図で表すと,次のようになります。
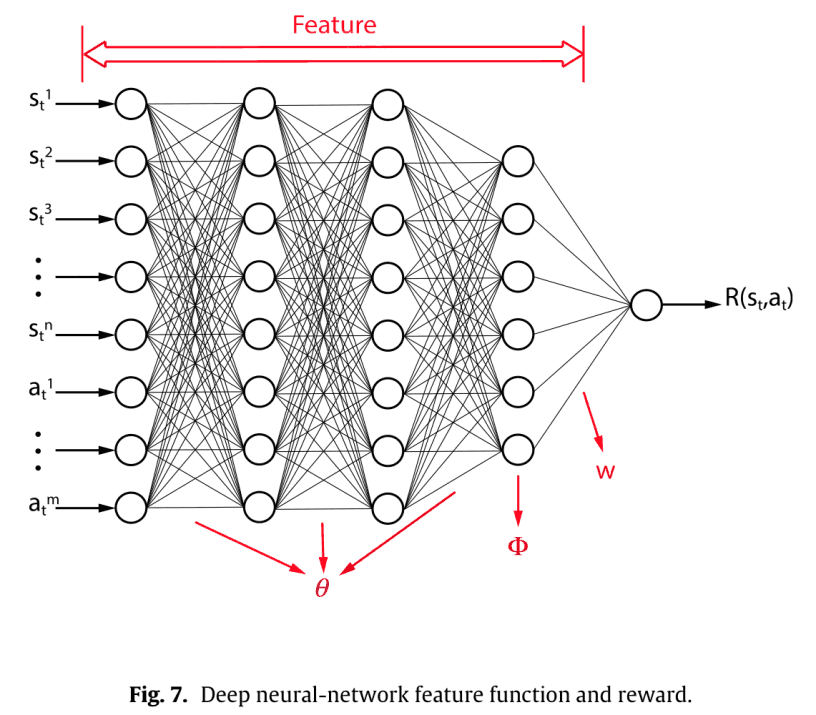
ここで,$w=1$にすると,単一のDNNを直接使用して報酬関数を表せます,パス空間$\Omega$全体の最大エントロピー分布は$\theta$のみを調整して得られます。
逆強化学習
報酬近似器
未知の報酬を回復するためDNNを関数近似器として利用します。関連研究から報酬関数の3つも定義を検討します。
- $R$: $S\rightarrow R$, $R(s)$
- $R$: $S\times A\rightarrow R$, $R(s,a)$
- $R$: $S\times A\times S\rightarrow R$, $R(s,a,s')$
1つ目の定義は,行動によらずゴール状態に到達したいときや,危険な状態を回避したいときに用います。この定義はエージェントが行動に対して特別な振る舞いがないことを表します。
2つ目定義は,行動を考慮するため,特定の行動に対するエージェントの好みを表現することができます。
3つ目の定義は,状態$s$で行動$a$を実行した後の次状態$s'$も考慮します。しかし,$s'$は環境の応答に依存し,エージェントは将来の状態を知らなくとも行動$a$を実行したときの期待報酬に従って行動を決定できます。よって,$R(s,a)$と$R(s,a,s')$は同等といえます。
以上のことから今回は,$R(s,a)$を用いることとします。
$R(s,a)$を表現するDNNの構造としては,次の図のように2種類考えられます。
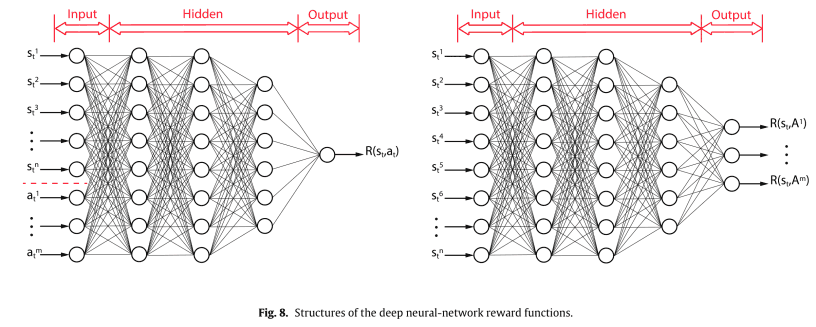
最大エントロピー逆強化学習
Fig.8.のパラメータの学習に用いられるIRLアルゴリズムを前章の最大エントロピー原理を用いて,説明します。
・モデル学習
状態遷移モデル${\mathbb P}(s'|s,a)$に関する知識の無い,完全モデルフリーの場合を考えます。モデル学習のアイデアは,各状態-行動-状態の訪問回数を分析し,状態遷移の確率を計算することです。
$${\mathbb P}(s'|s,a) = \frac{\nu(s,a,s')}{\sum_{s'\in S}\nu(s,a,s')} \tag{11}$$
ただし,$\nu(s,a,s')$は状態$s$で行動$a$をしたときの$s$から$s'$への状態遷移の総数です。$\nu(s,a,s')$が無限大に近づくにつれて,確率${\mathbb P}(s'|s,a)$は実際の値に近づきます。
モデルの学習はQ-Learningで行います。
・逆強化学習アルゴリズム
まずは,モデル学習の結果の${\mathbb P}(s'|s,a)$を利用して期待状態-行動訪問回数${\mathbb E}[\mu(s,a)]$を計算します。それをもとに$\frac{\partial{\cal L}_D}{\partial R}$を計算します。それを用いて,$\frac{\partial{\cal L}_D}{\partial \theta}$計算し,次式に従ってパラメータを更新します。
$$\Delta\theta = \lambda\frac{\partial{\cal L}_D}{\partial \theta}\tag{12}$$
・逆強化学習アルゴリズム改善
モデルを学習しても,状態-行動ペアごとに多数の訪問がある前では,良い結果が得られない場合があります。これは,状態遷移確率${\mathbb P}(s'|s,a)$の誤差→$\frac{\partial{\cal L}_D}{\partial R}$の誤差→$\theta$更新時の$\frac{\partial{\cal L}_D}{\partial \theta}$の誤差というように,誤差の蓄積が発生します。これに対して対応策を2つ示します。
- 逆強化学習の前に,収束するまでモデルを事前学習する
- デモを小さく分割して,長期の予測による大きな誤差を回避する
1つ目は,改善が見込めるが,それでも,システムが複雑な場合やデモ全体が確率システムの長期的な振る舞いを表す場合には、デモ${\cal D}$が環境のランダムな動作を表現するには不十分なことがあります。
今回は2つ目の策を用います。デモ${\cal D}$を分割します。$$\cal D_\tau = \zeta_\tau^i\,i=1,...,N_\tau$$
分割ルールは3つです。
- $\zeta_\tau^i$は$\tau\in S$から開始する
- $\zeta_\tau^i$の長さはすべての$\tau\in S$に関して一定で$\Delta T$
- $\zeta_\tau^i\subseteq \zeta$となるような経路$\zeta\in {\cal D}$
$\zeta_\tau$に対応するパス空間は$\Omega_\tau$として表され,デモ${\cal D}_\tau$から制約を受けて,すべての$\Omega_\tau$にわたる同時分布のエントロピーを最大化します。
おわりに
いかがでしたでしょうか。本記事では前半部分として,提案手法の部分までを紹介いたしました。提案されたMDP(マルコフ決定過程)の交通モデルは拡張しやすく魅力的ですね。逆強化学習では状態しか考慮しておらず,複雑なタスクに不向きだった報酬関数$R(s)$を拡張し,$R(s,a)$としました。この一般化はこの論文が初めてです。後半では実験と結果を紹介いたします。ぜひ後半の記事もご覧ください。
参考文献
[1] You Changxi, Jianbo Lu, Dimitar Filev, Panagiotis Tsiotras. "Advanced planning for autonomous vehicles using reinforcement learning and deep inverse reinforcement learning." Robotics and Autonomous Systems 114 (2019): 1-18.
[2] E.T. Jaynes, "Information theory and statistical mechanics", Phys. Rev. 106 (4) (1957) 620–630.




この記事に関するカテゴリー




