高速道路の新MDP!拡張可能な状態定義(後半)
3つの要点
✔️ 運転におけるPlanning(経路計画)
✔️ 高速道路での新しいMDP(Markov Decision Process)
✔️ 強化学習と逆強化学習の組み合わせ
Advanced Planning for Autonomous Vehicles Using Reinforcement Learning and Deep Inverse Reinforcement Learning
written by C You, J Lu, D Filev, P Tsiotras
(Submitted on 2019)
Comments: Robotics and Autonomous Systems 114 (2019): 1-18.
Subjects: 分野 (Machine Learning (cs.LG); Machine Learning (stat.ML))
はじめに
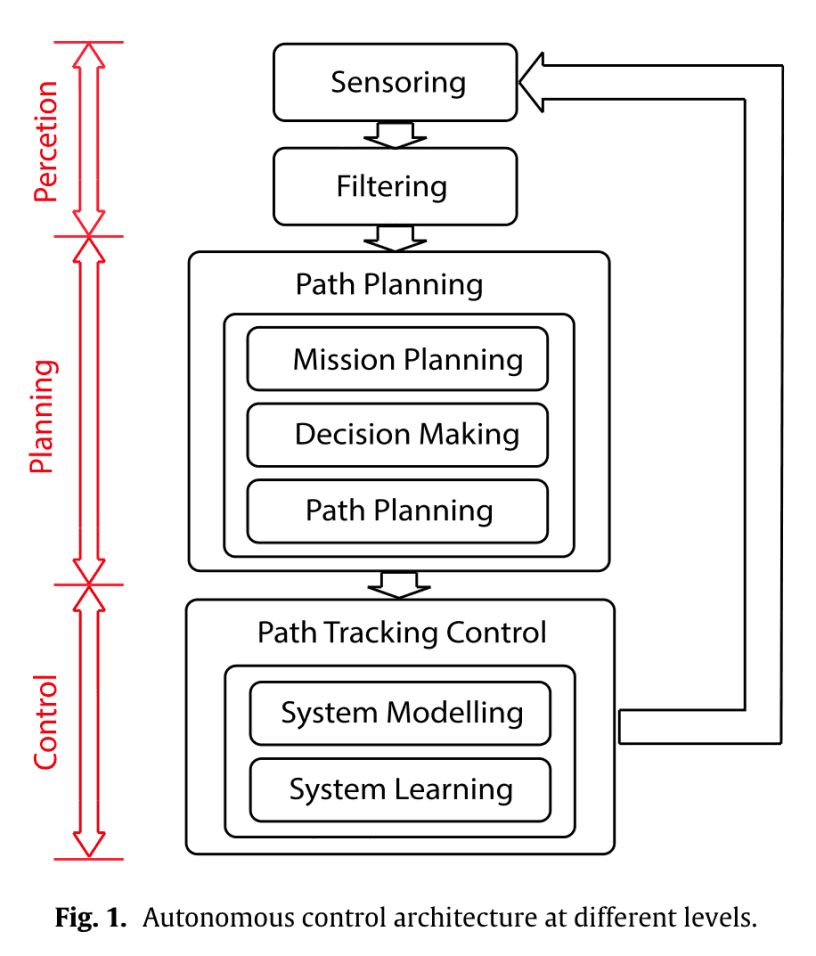
ドライバーのミスによる事故が多発しています。そのため,自動運転への関心が高まっています。自動運転には次図のように,知覚(Perception),計画(Planning),制御(Control)の3つのレベルがあります。本論文は,計画(Planning)の部分に関する研究です。
貢献
本論文の貢献は主に以下の3つです。
- 高速道路における新しいMDPモデル
- 道路の形状を考慮しており,拡張が容易
- 状態空間が大きくならないように車両の速度は削除
- Max Ent IRLの一般化による任意の非線形報酬関数
- モデルフリーのMDPのための3つのMax Ent deep IRLの提案
MDPはマルコフ決定過程(Markov Decision Process)のことです。前回記事(前半)では提案手法までを説明しました。高速道路の交通モデルの新しいMDP(マルコフ決定過程)の定義や,最大エントロピー逆強化学習の拡張を提案しました。
それでは,実験を見ていきましょう。
実験・結果・分析
この章では説明した交通モデルに強化学習と逆強化学習のアルゴリズムを実装し,結果を分析します。
交通シミュレーター
今回実験で用いたシミュレーターの内容です。PygameというPythonライブラリを用いて作成されました。車線数は5です。車種(トラック,セダンなど)は区別しません。HVは緑色です。各EVはランダム方策を持ちます。ランダム方策は,周囲の全車両(HVとEVs)を使用して状態$s_{EV}$を定義し,EVが衝突を起こさない行動セットを探し,その後,そのセットからランダムに行動を決定するというものです。
強化学習による運転行動の設定(エキスパート)
ここでは,強化学習を用いてエキスパートの運転行動を獲得します。今回は追い越しと追従の2種類用意しました。設計した重み$w_1$(追い越し)と$w_2$(追従)はTable 1に示されています。
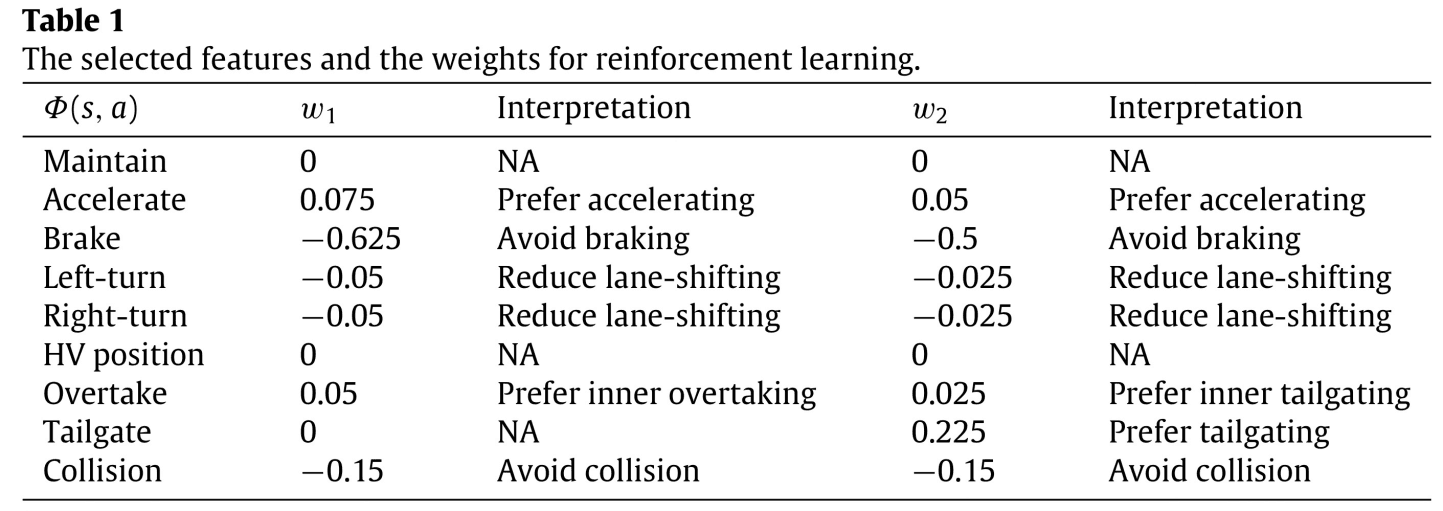
$w_1$の設計による望ましい運転動作(追い越し)は以下の通りです。
- HVの前方のセルが空いていれば,HVは加速して前方のセルを占有する
- HVの前にEV があり,追い越しができない場合,HVは速度を維持
- 片側だけが追い越し可能な場合は,最初に車線変更し,加速し,その後,速度継持することでHVは前のEVを追い越す
- HVは,左右両側から追い越し可能な場合,コーナーの内側から追い越す
- HVは,追い越しをしない限り車線は変更しない
- HVは,ブレーキをかけて後ろのセルを占有しない
- 衝突は許可されない
$w_2$の設計による望ましい運転動作(追従)は以下の通りです。
- HVの前にEVがあるとき,HVはその速度を維持
- HVは,前方のセルが空いていて,車線変更による追従が起こらない場合,加速して前方のセルを占有
- HVの前にEVがいないとき,HVは車線変更をしてEVを追従する
- HVは,コーナーの内側の車線の車両を追従することを好む
- HVは,追従しない限り車線変更をしない
- HVは,ブレーキをかけて後ろのセルを占有しない
- 衝突は許可されない
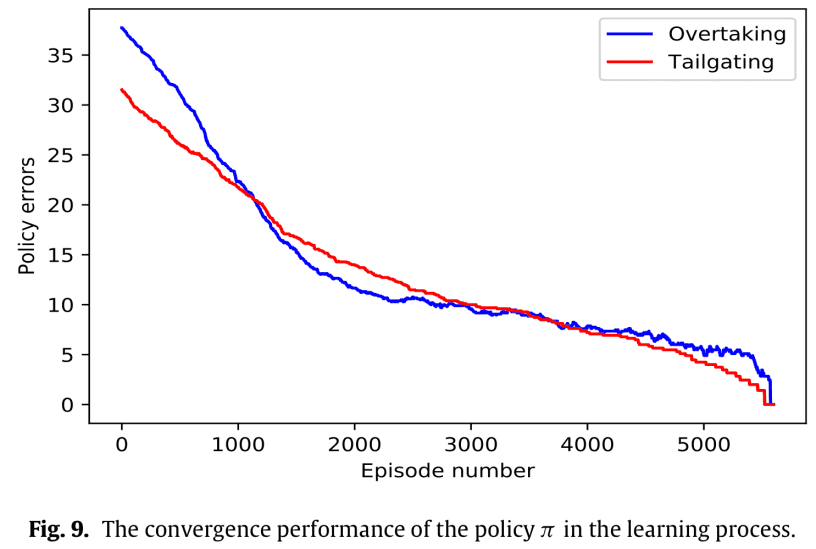
Q-learningを用いて,これらの最適方策学習しました。$w_1$: $\pi_1^*$,$w_2$: $\pi_2^*$に対応します。次の図は収束の様子です。
方策$\pi_1^*$を使用したシミュレーション結果の例を示します。
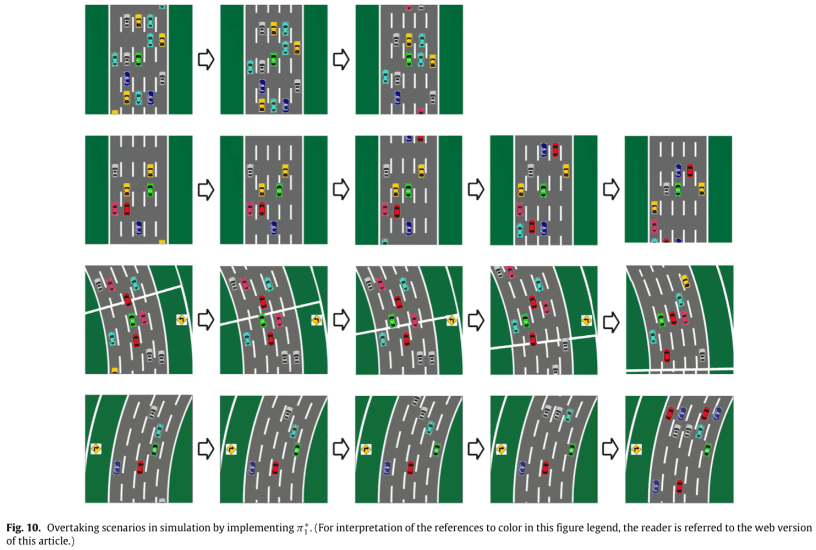
1行目は,HVの前にスペースがあるシナリオです。HVは加速し,黄色の車両の後ろについています。
2行目は,HVの前に1台の車両があり,追い越しのために左右両方の車線が利用できるシナリオです。直線道路なので追い越しは左右どちらからでもよいです。今回は左から追い越し,青色の車に追いつくまで加速しています。
3行目は,HVの前方と右方に車両があるシナリオです。HVは左車線のみを使用して追い越しができます。
4行目は,HVの前に1台の車両があり,追い越しのために左右両方の車線が利用できるシナリオです。コーナーの内側である右方に車線変更をして加速しましたが,シアンの車も加速するため追い越しは完了しませんでした。
これらの行動は,重み$w_1$の設計で目的とした行動と合致しており,うまく学習できたといえます。
逆強化学習による運転行動の獲得
まず,DNNを用いて表される報酬関数を学習するために,$\pi_1^*$と$\pi_2^*$を実装し,最大エントロピー原理を利用して,推定方策${\hat\pi}_1^*$と${\hat\pi}_2^*$を取得します。まず,Fig. 8.のDNNの構造を選択し,報酬関数を表現します。今回は便利な2つ目の方の構造を使いました。状態ベクトル$s_t$は,9台の車両の位置(1HVと8EVs)と道路の種類の10次元です。$A$の中には5つの行動があります。速度維持,加速,減速,車線変更右,車線変更左です。シミュレーションの初期状態$s_0$はFig. 11.です。HVの周囲には3つのEVsがいて,5車線道路の中央の車線にいます。シミュレーション期間$T$は1500で,デモ数は500です。
次に,シミュレーションデータを用いて方策を獲得するために,3種類の最大エントロピー逆強化学習を実装しました。Algorithm 4が従来の最大エントロピー逆強化学習で,Algorithm 5, 6が提案手法の最大エントロピー逆強化学習です。Algorithm 5, 6の違いは,分割の期間$\Delta T$です。結果をTable 2に示します。
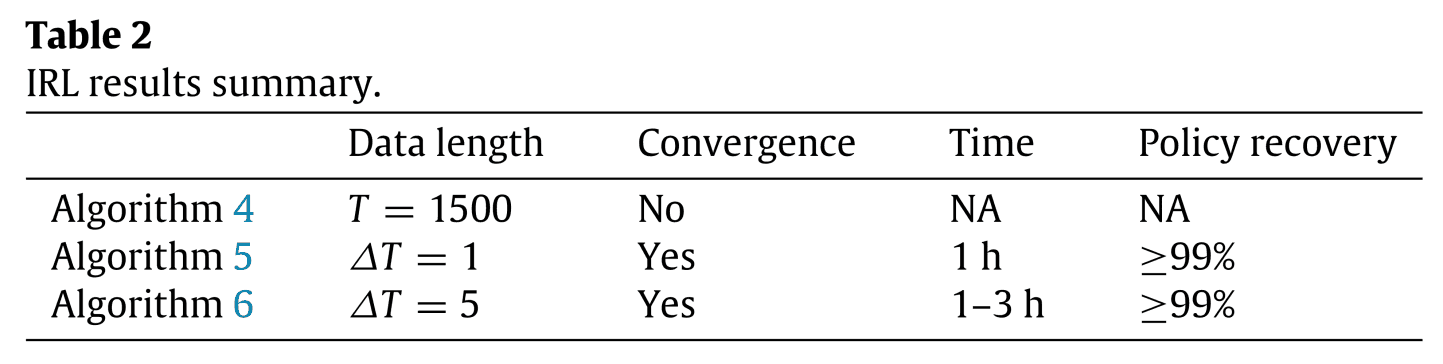
Table 2 を見ると,従来手法であるAlgorithm 4 は収束していません。これは,データが長く,確率論的なシステムの動作が原因と考えられています。提案手法Algorithm 5, 6 は収束しています。Algorithm 5 は$\Delta T =1$なので,状態-行動ペアの訪問回数の期待値の計算をしないので,計算時間がAlgorithm 6 に比べて短いです。
また,学習された方策${\hat\pi}_1^*$(追い越し)と${\hat\pi}_2^*$(追従)をシミュレーションで実装しました。${\hat\pi}_1^*$は$\pi_1^*$と同様だったので,先ほどのFig. 10.と同様です。${\hat\pi}_2^*$をFig. 12.に示します。
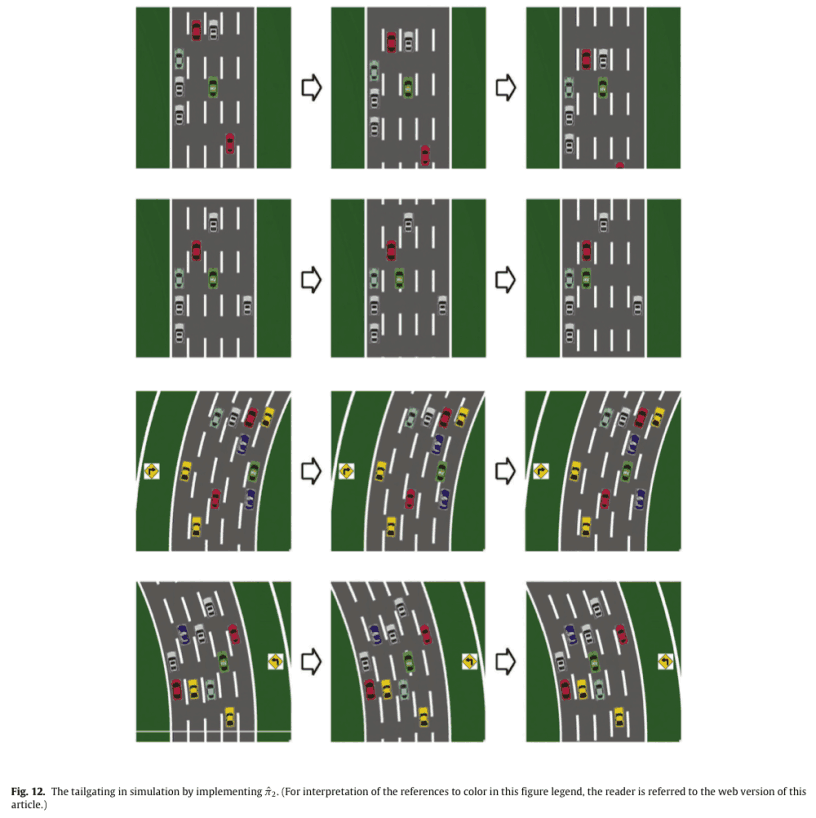
1行目は,HVの前にスペースがあるシナリオです。HVは車線変更でEVを追従することはできないので,加速して前方のスペースを埋めます。
2行目は,HVが左に車線変更して追従するシナリオです。
3行目は,2行目と似ていますが,コーナリングのシナリオです。
4行目は,HVは左はどちらでも車線変更による追従ができますが,カーブの内側を好むため,左側を追従します。
これらの行動は,重み$w_2$の設計で目的とした行動と合致しており,うまく方策$\pi_2$から方策を獲得できたといえます。
結論
確率的マルコフ決定過程を使用して交通をモデル化し,強化学習と逆強化学習を用いて望ましい運転行動を実現しました。状態とMDP交通モデルの定義は柔軟であり,任恙の数のレーンと任意の数のEVを交通モデル化できるます。道路のカーブによって運転方策が変わる可能性があり,それを考慮に入れることができるます。状態の定義は容易にスケールし,MDP の問題を効率的に解けるますが,このモデルは異なる車速や車種を区別せず,各車両を質点として扱っています。この論文の結果を現実のシナリオで使用するには,追加の作業が必要です。例えば,交通内の(相対的な)速度によってMDP の状態の大きさを動的に変更するなどです。ドライバーの報酬関数を設計することでQ-learningを使って対応する最適方策を学習し,追い越しや追従といった典型的な運転行動を示すことができました。5車線の道路と,EVsのランダムな方策を用いて,これらを示しました。
データから方策と報酬関数を回復するために,最大エントロピー原理に基づく新しいモデルフリーの逆強化学習手法を提案した。既存手法のほとんどは$R(s)$ だが,より多様な運な行動を設計できる$R(s,a)$ を用いました。任意のパラメータ化された,連続的微分可能な関数近似(DNN) による最大エントロピー逆強化学習の初めての一般化です。
確率的システムの知誠が限られているとき,長いデモをIRLに使用するのは難しいことを示しました。
誤差は主に2つの要因から生じます。
- データ量がシステムの確率的な挙動を表すのに十分でない場合
- 確率論的システムの予測誤差が蓄積され,モデルフリー問題で長期的に大きくなる場合
これに対して,デモを短いデータ片に分け,データ片上の同時分布のエントロピーを最大化することで,IRLアルゴリズムを改良しました。
提案手法はシミュレーションにより検証されました。
おわりに
今後の方針としては,高忠実度シミュレーションまたは現実のタスクでのコントローラの設計や不完全知覚での意思決定のための部分的観測MDPの導入,交通フローをよりよく制御するためのマルチエージェントの導入があります。CARLA等を用いたシミュレーションで今回の手法を用いたりするとおもしろいかもしれません。また,運転には不完全知覚が存在すると言われているので,それに対処するのも必要です。今回の論文は運転をEnd-to-Endで全部やろうという論文ではありませんでしたが,新しいMDPは拡張が可能でとても魅力的です。他のEnd-to-Endの手法のPlanningの補助として使用できたら,事故防止や渋滞緩和などにつながるかもしれません。この手法はそのまま現実のタスクで使うのは難しそうですが,ナビコマンドのように使用し,制御と組み合わせると面白そうです。
参考文献
[1] You Changxi, Jianbo Lu, Dimitar Filev, Panagiotis Tsiotras. "Advanced planning for autonomous vehicles using reinforcement learning and deep inverse reinforcement learning." Robotics and Autonomous Systems 114 (2019): 1-18.
[2] E.T. Jaynes, "Information theory and statistical mechanics", Phys. Rev. 106 (4) (1957) 620–630.




この記事に関するカテゴリー




