
生成AIを活用したUIプロトタイピング「UI-Diffuser」
3つの要点
✔️ 生成AIを活用してUI画像を生成し、UIデザインを効率化
✔️ UIコンポーネントとテキストからUIを自動生成
✔️ 現時点ではUIデザイナーにアイデアを提供するツールとして有用
Boosting GUI Prototyping with Diffusion Models
written by Jialiang Wei, Anne-Lise Courbis, Thomas Lambolais, Binbin Xu, Pierre Louis Bernard, Gérard Dray
(Submitted on 9 Jun 2023)
Subjects: Software Engineering (cs.SE); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
Comments: Accepted for The 31st IEEE International Requirements Engineering Conference 2023, RE@Next! track
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
概要
この論文では、モバイルのUI生成モデルを提案しています。
モバイルUIは、ユーザーに対してアプリの親しみやすさや使いやすさなど、エンゲージメントに影響を与える重要な要素です。皆さんも同じようなアプリがあれば、古いデザインのアプリよりも、モダンなイケてるデザインのアプリを選ぶのではないでしょうか。しかしながら、アプリ開発において、どんなUIが良いのかをゼロから考えるのは、大変に時間と労力がかかります。
そこで、この論文では、UIデザインをサポートするために、最近発展が目覚ましい生成AI(Stable Diffusion)を応用して、UIのプロトタイプを自動生成する「UI-Diffuser」を提案しています。
「UI-Diffuser」では、簡単なテキストのプロンプトとUIコンポーネントを入力するだけで、UIデザインを生成してくれます。2022年から話題になっている生成AI「ChatGPT」を利用したことがある方は実感していると思いますが、生成AIでいくつか候補を作成してもらい、それらを修正する方が、ゼロからアイデアを考えるよりも遥かに簡単で楽であることがわかると思います。
この記事では、この「UI-Diffuser」の仕組みと、その有用性についてご紹介します。
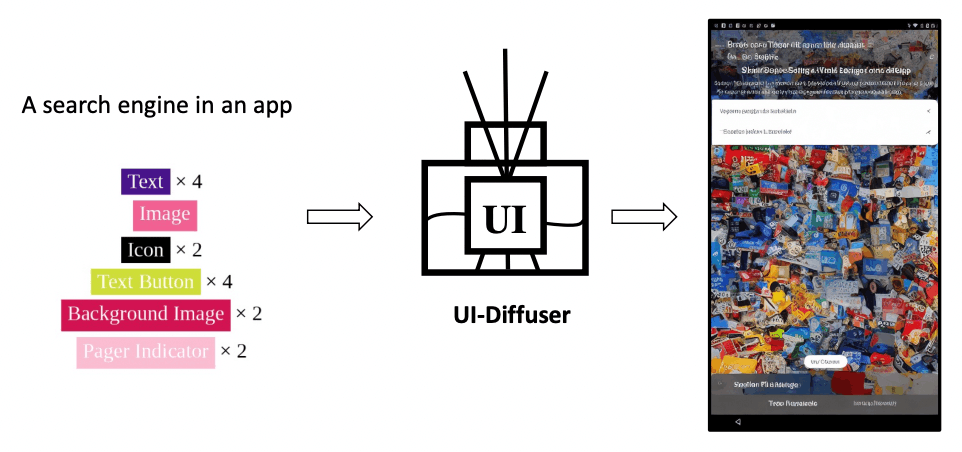
「UI-Diffuser」とは?
「UI-Diffuser」の概要は下図のとおりです。2つのステップで構成されています。1つ目のステップでは、UIコンポートネント(テキスト、アイコン、ボタン、画像)を入力すると、UIコンポーネントから、もっともらしいレイアウトを生成します。次のステップでは、1つ目のステップで生成されたレイアウトとテキストのプロンプト("A search engine in an app")を組み合わせて、Stable Diffusionによって、UIデザインを生成します。
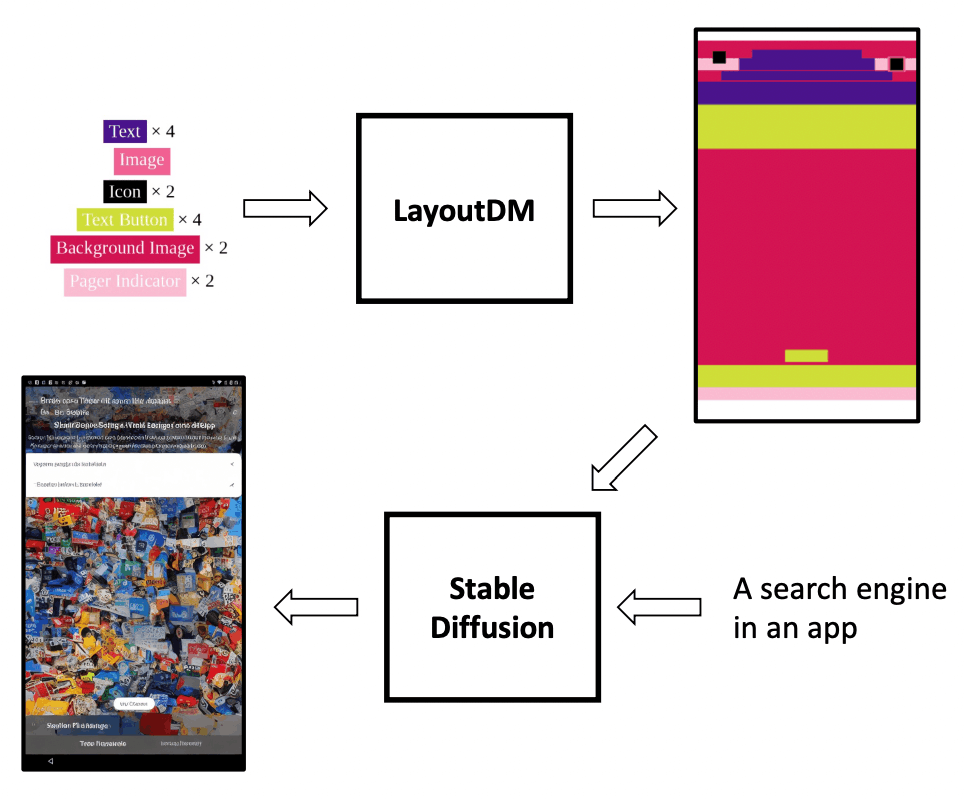
1つ目のステップのレイアウトの生成では「LayoutDM」という手法を利用しています。これは、2023年にCyberAgentが発表しているものです(arXiv、ブログ)。指定されたコンポートントを元に、カテゴリ、サイズ、位置、コンポーネント間の関係など様々な要素を考慮して、構造化されたUIのレイアウトを生成します。2つ目のステップのUIデザインの生成では、以下のようなアーキテクチャが提案されています。Text Encoder(CLIP)、Image Information Creator(UNet)、Image Decoder(VAE)、ControlNetの4つのコンポーネントから構成されています。
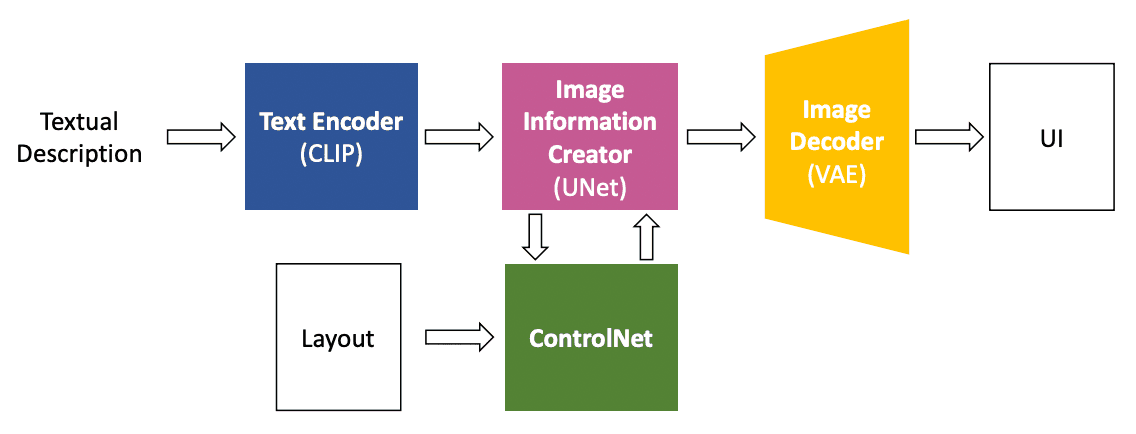
LayoputDMで生成したレイアウトとテキストのプロンプトが入力されると、UIデザインの画像が生成されます。まず、テキストのプロンプトがText Encoder(CLIP)でToken Embeddingに変換され、Image Information Creator(UNet)がToken Embeddingに基づいてImage Embeddingを生成し、最後にImage Decoder(VAE)がUIデザインの画像を生成します。レイアウトなどの追加の入力条件をサポートするために、ControlNetをUNetに統合しています。LayoputDMで生成したレイアウトは、このUNet統合されたControlNetに入力されます。
「UI-Diffuser」の有用性は?
下表は、「UI-Diffuser」で生成したUIデザインのサンプルです。1列目の「Components and Descriptions」は、「UI-Diffuser」に入力したUIコンポーネントとテキストのプロンプトを示し、2列目の「Generated Layouts」は、「UI-Diffuser」に入力したUIコンポーネントから生成されたレイアウトを示しています。3列目の「Generated UIs」が最終的なUIデザインのサンプルです。UIコンポーネントとテキストのプロンプトを入力すると、ほんの数秒でUIデザインが生成されます。

「UI-Diffuser」で生成されたUIデザインは、一見すると高品質ですが、よく見てみると、UIコンポーネントが欠落している場合や、デザイン性がやや低いものも散見さてます。例えば、上表の5行目の「Generated UIs」では「Advertisement」のコンポーネントは無視されています。このサンプルから「UI-Diffuser」によって作成されるUIデザインは、完全に機能するUIプロトタイプツールというよりも、UIデザイナーにアイデアを提供してインスピレーションを与えることができるツールとして適していると考えられます。
まとめ
この論文では、UIコンポーネントと簡単なテキストのプロンプトでUIデザインの画像を自動生成する「UI-Diffuser」を提案しています。デモンストレーションで有用性を確認した結果、現時点では、このツールによってUIデザインを完全に置き換えることは難しいものの、UIデザイナーにアイデアを提供してインスピレーションを与えることができるプロトタイピングツールとして、可能性が示されています。しかしながら、入力されたUIコンポーネントが生成された画像に含まれていなかったり、デザイン性が低かったりといった問題が見られるため、今後の改善が求められるとしています。
この研究チームは、改善に向けて、まずはベンチマークを構築し、生成されたUIのデザイン性、UIコンポーネントとの互換性、テキスト記述との互換性という 3 つの重要な要素を調査することにより、UI-Diffuserの包括的な評価を実施する予定としています。
さらに、UI-Diffuserを強化するために「高品質のスクリーンショットの説明文を含むデータセットの開発」「生成されたUI画像からのコンポーネントの切取り」「生成されたUIからのコード生成」などにも取り組む予定としています。例えば「生成されたUI画像からのコンポーネントの切取り」に関して、生成されたUI画像は、UIデザインのアイデアとして有用ですが、通常は編集したり、直接再利用したりできません。
そこで、この制限を克服するために、生成されたレイアウト画像内の絶対位置に基づいて、生成されたUI画像の各コンポーネントをトリミングする方法も検討しているようです。例えば、UIコンポーネントは互いに重なり合う可能性があり、上部コンポーネントをトリミングすると下部コンポーネントに空白スペースが生じることもあるため、このような場合、空白部分を下位成分の色で埋める方法なども検討しています。
また、「生成されたUIからのコード生成」に関しては、生成したUIデザインから、デザインに対応するコードを生成できる機能も検討しているようです。UI-Diffuserで生成されるレイアウト画像にはコンポーネントのカテゴリ、サイズ、位置が含まれているため、対応するコードを生成することが可能です。
Figmaなどの既存のデザインツールにも、デザインを検索したり、作成したデザインのコードを確認する機能はありますが、これは意外に時間がかかり大変な作業です。もし生成AIで自動化すれば、より柔軟にさまざまなデザインを生成し、より直感的に自然言語でデザインを生成することができるようになります。今後、誰でもより簡単にUIデザインのプロトタイプが作成できるようになり、アプリ開発がより一層、効率化されることが期待されます。






この記事に関するカテゴリー

