
ControlNetが拡散モデルに革命をもたらす?Stable DiffusionのAIキャラクターに特定のポーズの指示が可能に!
3つの要点
✔️ ControlNetは、大規模な拡散モデルを制御し、追加の入力条件に対応させるために使用されるニューラルネットワーク
✔️ タスクに特化した条件をエンドツーエンドで学習することができ、トレーニングデータセットが少ない場合でもロバストである
✔️ Stable Diffusionのような大規模な拡散モデルをControlNetで補強することで、エッジマップ、セグメンテーションマップ、キーポイントなどの条件入力が可能に
Adding Conditional Control to Text-to-Image Diffusion Models
written by Lvmin Zhang, Maneesh Agrawala
(Submitted on 10 Feb 2023)
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Graphics (cs.GR); Human-Computer Interaction (cs.HC); Multimedia (cs.MM)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
先行研究と比べてどこがすごい?
本論文は2023年2月10日に発表され、その数日後にはStable Diffusion用WebUI向けの拡張機能がGitHubに実装され瞬く間に世界中で話題となりました。なぜなら、AIによる画像生成を行うときにキャラクターに特定のポーズを取らせたりすることが容易に可能になったからです。
AIイラストはControlnetの登場で完全にゲームチェンジしましたわ。線画から色塗りができるのは本当に素晴らしい機能!「あくまで自分の線のまま」にすることも、「AIに補正してもらう」こともできるのがポイントです。
— 賢木イオ@スタジオ真榊 (@studiomasakaki) March 5, 2023
これは色指定をしていませんが、「赤い髪・黒い服・黄色の目」と指定すると、 pic.twitter.com/V0flFRYmqp
はじめに(introduction)
本稿では、大規模な画像拡散モデルを制御してタスク固有の入力条件を学習させるエンドツーエンドのニューラルネットワークアーキテクチャであるControlNetを紹介します。
ControlNetは、大規模な拡散モデルの重みを訓練可能なコピーとロックされたコピーにクローン化し、「zero convolution」と呼ばれる独自のタイプの畳み込みレイヤーを使用してそれらを接続します。この論文では、ControlNetを個人用のパソコン(Nvidia RTX 3090 Tl 1台)で小さなデータセットを用いて訓練した場合でも、特定のタスクでテラバイト(TB)のGPUメモリと数千のGPUを持つ大規模計算クラスタで学習した商用モデルに匹敵する競争力のある結果を得られることを実証しています。
大規模なText-to-imageモデルを使えば、簡単なテキストプロンプトを入力するだけで、視覚的に魅力的な画像を生成することができます。しかし、この方法は、物体の形状や姿勢の理解など、問題設定が明確な特定の画像処理タスクに有効かどうかという疑問を投げかけています。この論文では、特定のタスクはデータセットが小さいことが多く、利用可能な時間とメモリ領域内で大規模なモデルを最適化するために、高速な学習方法と事前学習された重みが必要な場合があることを示唆しています。さらに、様々な画像処理問題には、問題定義、ユーザーによる制御、または画像アノテーションの形態が多様であり、人間の指示による手続き的な手法ではなく、学習による解決策が必要となる場合があります。そこで提案されるのがControlNetです。
ControlNetは、重みを学習可能なコピーとロックされたコピーに分け、ロックされたコピーは元の重みを保持し、学習可能なコピーは、タスク固有のデータセットで条件付きな制御を学習します。ControlNetでは、畳み込み層を使用し、生成可能な重みを保存することで、異なる規模のデータセットで学習を行うことができ、zero convolutionと呼ばれる独自のタイプの畳み込み層を使用して、拡散モデルをfine-tuningするのと同じくらい速く学習することができます。
提案手法
1.ControlNetの詳細
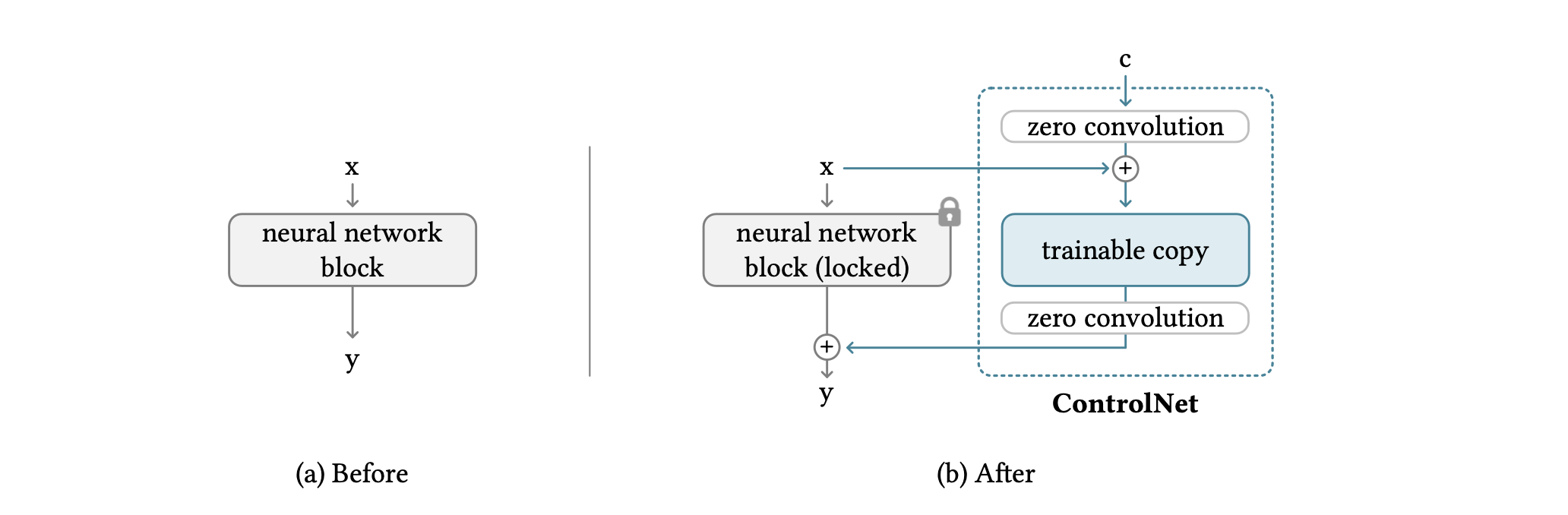
ControlNetは、ニューラルネットワークブロックの入力条件を操作して、ニューラルネットワーク全体の動作をより細かく制御することができます。ここで言う、「ネットワークブロック」とは、ニューラルネットワークを構築するために一般的によく使用される単位のことです。例えば「resnet」ブロックや「transformer」ブロックなどです。
ネットワークブロックは、「zero convolution」と呼ばれる特別な畳み込み層で接続されており、これにより、ニューラルネットワークの各層が保持されたまま、より高度な制御が可能となります。zero convolutionは、ゼロで初期化された1×1の畳み込み層であり、訓練可能なコピーと元のパラメータの両方を含む構造を持ちます。また、zero convolutionの勾配計算は簡単で、特定の入力に対する勾配がゼロであるため、ニューラルネットワークブロックの重みとバイアスの勾配は影響を受けません。これにより、zero convolution は、学習によってゼロから最適なパラメータに成長するユニークな接続層となります。(1)がzero convolusion接続前の数式、(2)が接続後の数式となっています。

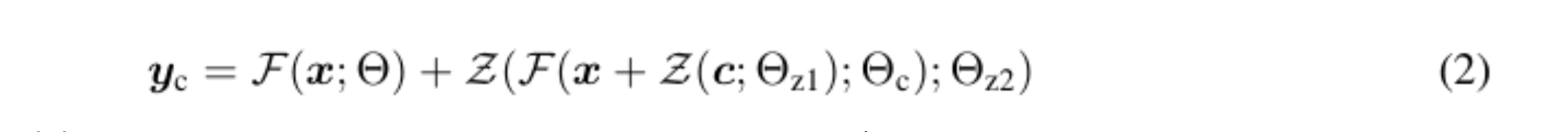
2.画像拡散モデルにおけるControlNet
Stable Diffusionと呼ばれる大規模なテキストから画像への拡散モデルを制御するためにControlNetを使用することについて説明します。Stable Diffusionは基本的に、エンコーダー、ミドルブロック、スキップ接続されたデコーダーを含む25のブロックを持つU-netです。このモデルは、テキストをエンコードするためにOpenAI CLIPを使用し、拡散の時間ステップをエンコードするためにpositional encodingを使用しています。モデルを効率的に学習するために、512x512画像のデータセット全体を、VQ-GANに似た方法で64x64の「潜在画像」に前処理します。このため、ControlNetは画像ベースの条件を64x64の特徴空間に変換し、畳み込みサイズと一致させる必要があります。
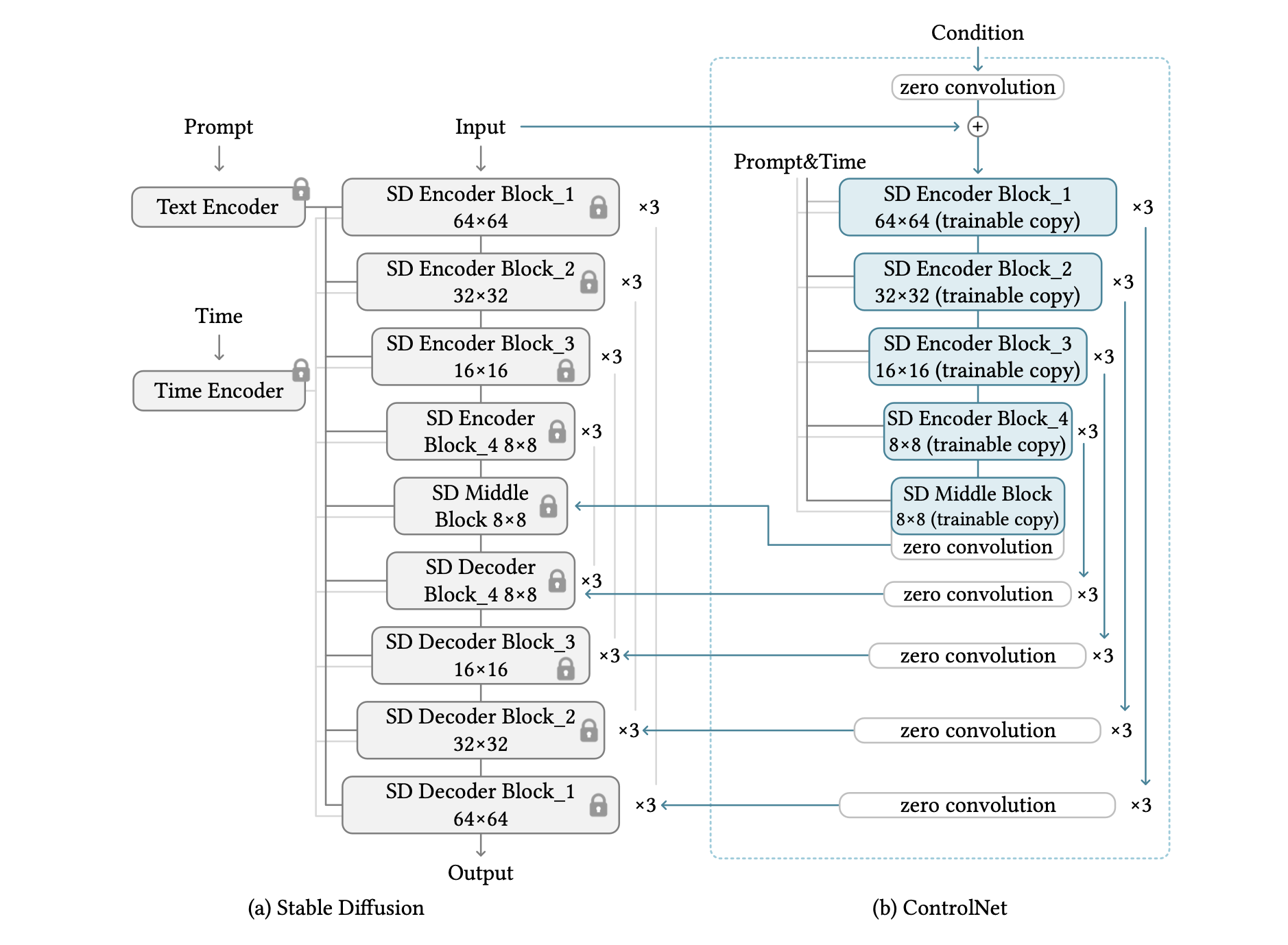
上の図はControlNet を用いて U-net の各レベルを制御しています。このアーキテクチャは計算効率がよく、GPUメモリを節約でき、他の拡散モデルでも使える可能性が高いです。なぜなら、元の重みは ロックされているため、学習の過程で元のエンコーダの勾配計算が必要ありません。これにより、元のモデルの勾配計算の半分を回避できるため、学習を高速化し、GPUメモリを節約することがで きます。ControlNetでStable Diffusionを学習させると、GPUメモリを約23%節約でき、学習の各イテレーションで通常の34%の時間しか必要としません(Nvidia A100 PCIE 40Gでテスト済み)。
3.モデルの学習について
画像拡散モデルは、画素または潜像空間にノイズを加えることで画像を徐々にノイズ化します。Stable Diffusion は、学習に潜在的な画像を使用します。これらのモデルは、時間ステップ、テキストプロンプト、タスク固有の条件などの条件に基づいて画像に追加されるノイズを予測するように学習します。
training中、Cannyエッジマップや人間の走り書きなどの入力制御マップから意味内容を認識するモデルの能力を向上させるため、テキストプロンプトの50%がランダムに空文字列に置き換えられます。これは、プロンプトが表示されていないときの代替としてモデルのエンコーダーが入力制御マップからより多くの意味内容を学習するためです。
実験結果
実験設定
この実験では、すべての結果がCFGスケールを9.0で設定したもので得られています。サンプラーはDDIMを使用しています。デフォルトでは20ステップを使用しています。モデルをテストするために、3つのタイプのプロンプトを使用します。
- プロンプトなし: プロンプトに空の文字列""を使用します。
- デフォルトのプロンプト: Stable diffusionは本質的にプロンプトでトレーニングされているため、空の文字列はモデルにとって予期しない入力であり、プロンプトが提供されない場合、SDはランダムなテクスチャマップを生成する傾向があります。より良い設定は、"an image"、"a nice image"、"a professional image"などの意味のないプロンプトを使用することです。この実験では、"a professional, detailed, high-quality image"をデフォルトのプロンプトとして使用しています。
- 自動プロンプト: 完全に自動化されたパイプラインの最大の品質をテストするために、自動的な画像キャプション手法(例:BLIP [34])を使用して、「デフォルトのプロンプト」モードで得られた結果を使用してプロンプトを生成します。生成されたプロンプトを再度拡散させます。
- ユーザープロンプト: ユーザーがプロンプトを与えます。
定性的結果
本論文では、図4~15で定性的な結果を示しています。ここではいくつか結果をピックアップします。



因果推論
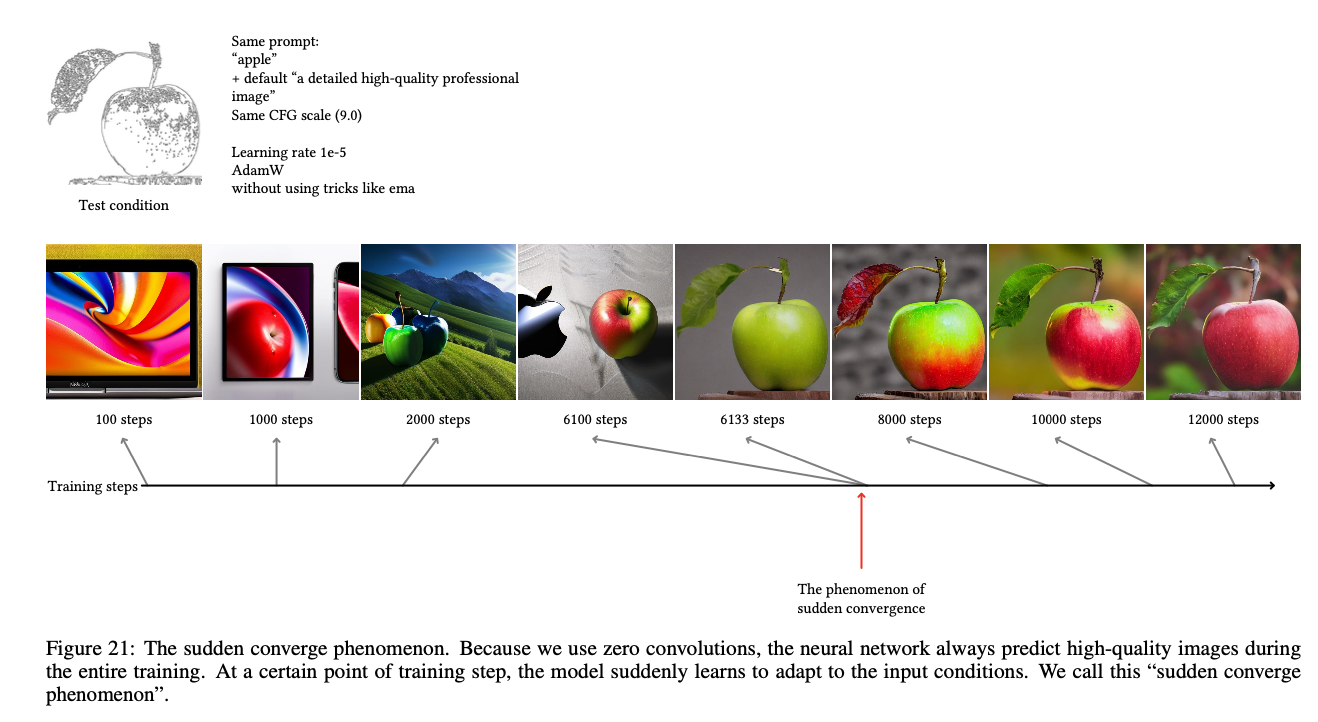
図21ではモデルが突然入力現象に従う「突然の収束現象」が指摘されています。
課題はある?
入力画像の意味がモデルに誤って認識されると、強いプロンプトが提供されてもその悪影響を排除することは困難であるように思われます。下の画像では”俯瞰から見た農園の風景”とプロンプトで指示していますが、AIモデルが線画を”コップに入った水”と間違って認識してしまっています。

まとめ
この論文は、拡散モデルを制御するためのニューラルネットワークアーキテクチャ、ControlNetを提案していました。ControlNetは、拡散モデルに対する追加の条件をサポートし、小さな学習データセットでもロバストに学習することができます。ControlNetの学習速度は拡散モデルのfine-tuningと同程度であり、個人用デバイスでも学習させることが可能です。また、ControlNetを用いることで、大規模な拡散モデルを制御するための手法が充実し、関連する応用がより容易になる可能性があります。






この記事に関するカテゴリー

