機械と人間を区別できるか?テキスト生成モデルと自動生成テキスト検出技術の現状について徹底解説!
3つの要点
✔️ テキスト生成モデル・自動生成テキスト検出器とはなにか?
✔️ テキスト生成モデルの具体例・技術について解説
✔️ 自動生成テキスト検出器の具体例・技術について解説
Automatic Detection of Machine Generated Text: A Critical Survey
written by Ganesh Jawahar, Muhammad Abdul-Mageed, Laks V.S. Lakshmanan
(Submitted on 12 Nov 2020)
Comments: Accepted at The 28th International Conference on Computational Linguistics (COLING), 2020
Subjects: Computation and Language (cs.CL); Artificial Intelligence (cs.AI)


はじめに
テキスト生成モデル(TGM)の著しい発展は、その悪用の危険性を高めることにも繋がっています。
例えばGPT-2では、当初フェイクニュースの生成などに悪用される可能性から、モデルの公開がなされませんでした。こうした悪用を抑止するためには、機械的に生成された文章と、人間により書かれた文章とを区別できる技術が重要となります。
本記事では、テキスト生成モデル並びに自動生成文(または文章)の検出について、包括的な解説を行います。
目次
1.テキスト生成モデル(TGM)とは
1.1.TGMの学習
1.2.TGMによるテキスト生成
1.2.1.決定論的デコーディング
・貪欲探索
・ビームサーチ
1.2.2.確率論的デコーディング
・無制限サンプリング
・top-kサンプリング
・核サンプリング
1.3.TGMの社会的影響
2.テキスト生成モデル(TGM)の具体例
2.1.主なTGM
2.2.制御可能TGM(生成される文を制御する)
2.2.1.制御トークン
2.2.2.属性分類器を利用
3.自動生成文検出器
3.1.Classifiers trained from scratch
3.1.1.Bag-of-words classifier
3.1.2.Detecting machine configuration
3.2.Zero-shot classifier
3.2.1.Total log probability
3.2.2.Giant Language model Test Room (GLTR) tool
3.3.Fine-tuning NLM
3.3.1.GROVER detector
3.3.2.RoBERTa detector
3.4.Human-machine collaboration
3.4.1.Differences in human and machine detector
3.4.2.Supporting untrained humans
3.4.3.Real or Fake Text (RoFT) tool
4.最先端の検出器の課題
1.テキスト生成モデル(TGM)とは
1.1.TGMの学習
典型的なTGMは、以前のテキストが与えられたとき、次のトークンの確率をモデル化するように訓練されたニューラル言語モデル(NLM)です。
例えば"I","play"が入力として与えられたとき、その後に続く単語("baseball","soccer"など)の確率を予測します。これは$p_\theta(x_t|x_1,...,x_i,...,x_{t_1})$と表されます。このときトークンの語彙$V$について、$x_i∈V$となります。テキストを$x=(x_1,...,x_{|x|})$とすると、$p_\theta$は通常、$p_\theta(x)=\prod^{|x|}_{t=1}p_\theta(x_t|x_1,...,x_{t-1})$の形式となります。
このとき$p_\theta$は、以下の損失関数を最小化するように学習されます。$L(p_\theta,D)=-\sum^{|D|}_{j=1}\sum^{|x^{(j)}|}_{t=1}logp_\theta(x^{(j)}_t|x^{(j)}_1,...,x^{(j)}_i,...,x^{(j)}_{t-1})$このとき$D$は、参照分布を示す$p_*(x)$からのテキストの有限集合を表します。
1.2.TGMによるテキスト生成
テキストの最初の一部$x_{1:k} ~ p*$が与えられたとき、テキスト生成タスクは$p_\theta$により、与えられたテキストの続き$\hat{x}_{k+1} ~ p_\theta(.|x_{1:k})$を予測します。このとき得られたテキスト$(x_1,...,x_k,\hat{x}_{k+1},...,\hat{x}_N)$が、$p_*$からのサンプルとの類似度を高めることが目標となります。
例えばニュース記事の生成タスクでは、見出しが与えられたとき、記事の本文を生成させるように学習を行うことができます。物語生成タスクでは、冒頭から物語の続きを生成することもできます。
このとき、テキストの続き$\hat{x}_{k+1}$を生成するために、近似的な決定論的(deterministic)または確率論的(stochastic)デコーディングが用いられます。
1.2.1.決定論的デコーディング
・貪欲探索
貪欲探索では、各時間ステップで最も予測された確率が高いトークンを選択します。つまり、$x_t=arg max p_\theta(x_t|x_1,...,x_{t-1})$となります。このときの時間計算量は$O((N-k)|V|)$です。
・ビームサーチ
ビームサーチでは貪欲探索と異なり、確率の高い上位$b$個を候補として保存します。これらの候補をもとに次の時間ステップのトークンを予測し、再び上位$b$個の候補を保存します。このときの時間計算量は$O((N-k)b|V|)$です。
決定論的デコーディングでは、繰り返し同じ単語が生成されたり、一般的な(さまざまな文脈で許容されうるような)テキストが生成されるといった問題が発生する傾向があります。
1.2.2.確率論的デコーディング
確率論的デコーディングでは、各時間ステップで予測された確率分布からサンプリングを行います。
・無制限サンプリング
無制限サンプリングでは、予測された確率分布からそのままトークンをサンプリングします。最も単純な手法ですが、予測された確率が低い(不適切な可能性の高い)トークンをサンプリングしてしまう可能性が高くなります。
・top-kサンプリング
無制限サンプリングで発生する問題を回避するため、サンプリングされるトークンを上位k個に限定します。このときのkの適切な値は文脈によって異なり、例えば名詞(語彙が多い)を予測するならば大きく、前置詞(語彙が少ない)を予測する場合は小さく設定されるべきであるかもしれません。
・核(top-p)サンプリング
出力すべき単語の、確信度を高い順に並べて、閾値$k$になるまでの集合の中からサンプリングする。つまり、$p_\theta(x|x_1,...,x_{t-1})≧p$となるような$x$のみがサンプリングの対象となります。確率論的デコーディングには、非現実的な(大きな矛盾を含むような)文を生成する傾向があります。
1.3.TGMの社会的影響
TGMは、フェイクニュース、製品レビュー、スパム/フィッシングなどの生成に悪用される可能性があります。こうした偽のニュース記事やレビュー・コメントなどを、ユーザーが必ずしも適切に見極められるとは限りません。そのため、TGMの悪用を防ぐには、人間の書いた文と自動生成文を識別できるモデルを作成する必要があるのです。
2.テキスト生成モデル(TGM)の具体例
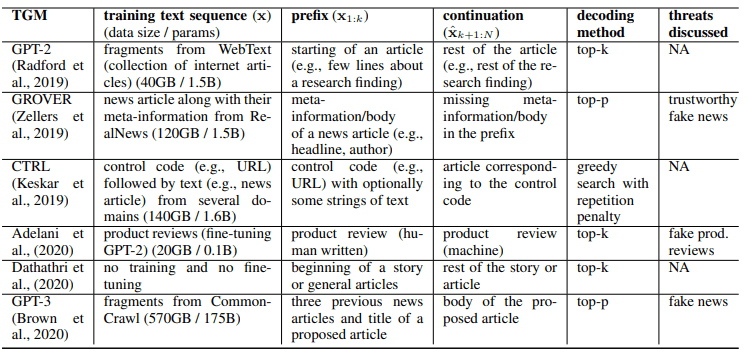
2.1.主なTGM
主なTGMは以下の通りです。
2.2.制御可能TGM
TGMの中には、記事のトピックや感情(肯定的なレビューか否定的なレビューか)などを制御することのできるものがあります。GPT-2やGPT-3など、与えられるテキストでそうした情報を制御する場合もありますが、生成される文章を細かく制御することは困難かもしれません。そのため、明示的に生成文を制御する方法として、以下のような手法が考案されています。
2.2.1.制御トークン
TGMを学習させる段階で、例えばニュース記事の著者や作成日、ソースドメインといったメタ情報をトークンとして入力します。一度学習が完了すれば、こうしたメタ情報を指定して入力することで、生成される文章を制御することができます。
例えばGROVERでは、人間が書いたフェイクニュースと識別が困難なニュース記事を生成することが可能です。またCTRLでも、制御トークンによる生成されるテキストの特定の属性を明示的に制御することが可能です。(生成される記事のトピックを指定するなど)
制御トークンを利用する場合、学習時点でそうしたメカニズムを導入する必要があります。そのため、一般に公開されている事前学習モデル(GPT-2など)を利用することは困難となります(高い学習コストのため)。
2.2.2.属性分類器を利用
それに対し、例えばGPT-2のようなTGMが生成した文章を、何らかの属性分類器(感情分類、トピック分類など)と組み合わせることにより、特定の属性を含むテキストを生成するようにモデルを調整することができます。この手法の場合、事前学習モデルを再び学習させる必要がないため、低コストで生成文を制御することができます。
3.自動生成文検出器
TGMにより生成された文章を、人間が書いた文章と区別できるようにするため、様々な検出器が考案されています。こうした検出器についての主な研究事例を紹介します。
3.1.Classifiers trained from scratch
ここでは、scratchから(≒ゼロから)訓練された分類器について取り上げます。
3.1.1.Bag-of-words classifier
ロジスティック回帰モデルとtf-idfを利用した単純なモデルにより、WebTextのテキストと、GPT-2により生成されたテキストを区別します。検出器の中でも特にシンプルな手法といえます。この研究では、異なるパラメータ数(117M、345M、762M、1542M)とサンプリング技術(純粋サンプリング、top-kサンプリング、top-pサンプリング)について、検出精度がどう変化するかが検証されました。
結果として、パラメータ数が大きいほど検出が困難になること、top-kサンプリングより核サンプリングのほうが検出が困難であることがわかりました。(top-kサンプリングでは一般的な単語が多く生成されてしまい、単語頻度の分布が人間のそれと大きく異なることに起因しているとみられます。)
また、GPT-2のfine-tuningを行うことで、より検出が困難となることがわかりました。
3.2.2.Detecting machine configuration
こちらの研究では、人間の書いたテキストと自動生成文をバイナリで分類するのではなく、どのようなモデルが生成した文章であるか(デコーディング手法、モデルのパラメータ数など)を識別します。
結果、モデル構成を(ランダムの場合と比べて)高い確率で予測可能であることが示されました。(このタスクは、人間の文と自動生成文の識別ほどは困難ではないことも示されました。)このことから、自動生成文はモデルの構成に強く依存していることがわかります。
加えて、Bag-of-words(文章の中の単語の出現回数を示すもの)を用いた検出器が、複雑な検出器(Transformerなど)と同等の性能を発揮したことから、単語の順序は分類にあまり関与しませんでした。
また別の研究では、古典的な機械学習モデルや単純なニューラルネットワークは、以下の三つの設定である程度機能することが示されました。
(1)二つの記事が同じTGMにより生成されたかの分類
(2)記事がどのTGMから生成されたかの分類
(3)人間が書いたテキストと自動生成文の分類(目標となるタスク)
ただし(3)について、いくつかのTGM(CTRL, GPT-1, GPT-2, GROVER, XLM, XLNet, PPLM, FAIR)をもとに検証した結果、GPT-2の生成文は検出が困難であったことがわかりました。
3.2.Zero-shot classifier
ここでは事前学習済みモデル(GPT-2、GLOVERなど)を利用してゼロショットで分類を行う事例について取り上げます。このとき、テキストの生成に用いるモデルと自動生成文検出に用いるモデルは、同じ場合もあれば異なる場合もあります。この設定では、自動生成文検出のための教師付きデータは不要となります。
3.2.1.Total log probability
単純な例として、TGMを利用して対数尤度を評価します。このとき、与えられたテキストの対数尤度を、人間が書いたテキスト・TGMにより生成されたテキストの対数尤度の平均と比較し、どちらに近いかに従って予測を行います。この分類器は、前述したシンプルなロジスティック回帰モデルと比べて低い性能となります。
3.2.2.Giant Language model Test Room (GLTR) tool
GLTRツールと呼ばれる手法では、GPT-2により生成されたテキストと、人間が書いたテキストの分布の違いを利用して分類を行います。TGMを用いてテキストを生成する場合、top-kサンプリングや核サンプリングなどを元に、順次次の時間ステップのトークンを生成していきます。ここで、テキストが与えられたとき、何らかのTGMを利用して、テキストの最初のk個のトークンを元に次のトークンの確率分布を予測してみます。そのテキストがTGMによる生成された文であれば、予測された次トークンの分布と、実際に与えられたテキストの次トークンの関連性が高まることが期待されます。また、top-kや核サンプリングにより生成されたテキストでは、珍しい単語の登場頻度が低くなる傾向があります。
これらの発想から、単語の出現率、予測分布における単語の順位、エントロピー等をもとに分類を行います。
イメージは以下の図の通りです。

この図では、予測された次トークンの確率分布に対する実際の次トークンの順位を色で示しています。上は人間が書いたテキスト、下はGPT-2 large(temperature=0.7)による生成文です。自動生成文では、予測分布のなかで高い順位にあたるトークンが多く登場しており、二つのテキストの違いが強調されていることがわかります。
3.3.Fine-tuning NLM
ここでは、事前学習済みモデルをfine-tuningし、自動生成文検出を行います。ゼロショットと同じく、テキストの生成に用いるモデルと自動生成文検出に用いるモデルは、同じ場合もあれば異なる場合もあります。
3.3.1.GROVER detector
この研究では、TGMであるGROVERモデルの上に線形分類器を付け加えてファインチューニングし、自動生成文検出を行いました。
このとき、テキストの生成に用いるモデルと自動生成文検出に用いるモデルが同じ場合のほうが、検出精度が高まることが実験で発見されました。ただし、実験で検証されたモデルが偶然そのような傾向を示しただけの可能性があります。
3.3.2.RoBERTa detector
この研究ではRoBERTaのファインチューニングを行い、パラメータ数最大のGPT-2により生成されたウェブページを、およそ95%もの精度で識別することに成功し、最先端の性能を発揮しました。
このとき、コアサンプリングにより生成された例をもとに訓練すると、その他のデコーディング手法(top-kや無制限サンプリング)でも効果を発揮しました。また、大規模なGPT-2で訓練された検出器は、小規模なGPT-2による生成文も適切に検出できることが示されました。(ただし逆の場合、大規模なGPT-2による生成文の検出精度は低下します。)
加えて上述のGROVERの研究と異なり、GPT-2モデルを微調整した場合よりも、RoBERTaモデルを微調整した場合のほうが高い精度を発揮しました。(これはRoBERTaの双方向性に起因すると考えられます。)
別の研究では、人間が書いたツイートと自動生成ツイートの分類において最先端の性能を発揮し、古典的な機械学習モデルやニューラルネットワーク(RNNやCNN)等を大差で上回りました。RoBERTaの事前学習にツイッターのデータは含まれていませんが、こうした事前学習時に見られなかったデータに対しても優れた性能を発揮できる可能性が示されたといえます。
3.4.Human-machine collaboration
全自動的な検出器を用いるのではなく、人間による判断と機械的な判断とを組み合わせることも考えられます。このような試みに基づいた研究について、以下にいくつか紹介します。
3.4.1.Differences in human and machine detector
この研究では、人間の判断と機械的な検出器について、以下のような能力の違いがあることが示されました。
(1)人間の評価は、自動生成文の矛盾や意味の誤り(支離滅裂であるなど)に気づくことに長けています。自動検出器は意味の理解力が人間に比べ劣るため、こうした判断は苦手です。
(2)自動生成文に単語の偏りがある場合(top-kサンプリングにみられる傾向です)、自動検出器は適切に判断することができますが、人間の評価ではこうした問題に気づくことが困難です。
人間と機械を組み合わせた自動生成文検出を行うならば、こうした能力の違いを把握することが重要でしょう。
3.4.2.Supporting untrained humans
先ほどにも取り上げたGLTRツールにより、テキストの特性を可視化することで、人間の判断を支援することが可能です。こうした支援により、特別な訓練を受けていない人間の判断の精度を向上させることができます。(54%→72%)ただしGLTRは、「自動生成文である」という判断に偏る傾向があり、「自動生成文ではない」と確信的に判断することが困難です。
こうした偏りは、人間の評価者が機械的な判断に引きずられる危険性にもつながるため、人間と機械とが「連携する」ことの必要性に繋がります。
3.4.2.Real or Fake Text (RoFT) tool(論文、Webサイト)
RoFTツールは、人間の自動生成文検出の判断能力を評価するための手法です。人間の評価者は、人間が書いた文と自動生成文の境界線を検出することが求められます。
具体的には、はじめは人間が書いた文章で、途中から自動生成された文章からなる一連の文章が順次与えられます。まだ自動生成された文章に切り替わっていないとユーザーが判断した場合、次の一文が与えられます。自動生成文に切り替わったと判断した場合、ユーザーはその根拠を提示する必要があります。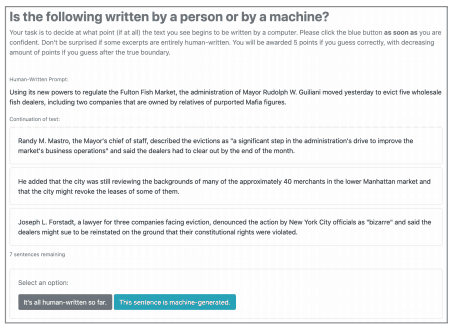
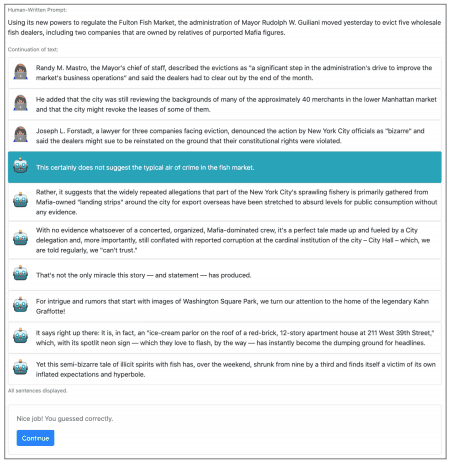
このような手順を繰り返し、人間が書いた文と自動生成文の境界線を評価者が判別できるかが評価されます。このRoFTツールはこのページで実際に利用することができます。
注意点として、自動生成文よりも人間が書いたテキストのほうがユーザーに多く提示されるといった偏りが生じる可能性があります。
4.最先端の検出器の課題
ここでは、RoBERTaモデルによる最先端の検出器の課題について述べます。この研究では、人間が書いたAmazon商品レビューと、GPT-2により生成されたテキストの検出タスクについて調査しています。このとき、検出器が適切に判断できなかった偽陽性の事例(自動生成文を人間が書いたと判定した場合)をランダムに100件調査した結果、以下のようなものが含まれていました。
- 流暢である(人間にも判別困難なほど流暢な事例もまれに含まれていました)
- 短い
- 事実と異なる(映画のレビューで出演者の名前が異なる等)
- 無関係な内容(音楽のレビューで音楽と無関係な単語が登場する等)
- 矛盾を含む(AはBを好きだが好きではない、等)
- 繰り返しを含む(Aは素晴らしい、そしてAは素晴らしい、等)
- 常識的にありえない事象を含む
- 誤字脱字・文法ミス
- 支離滅裂な内容
このように、人間ならばある程度判別可能な事柄を判断できない等、最先端の検出器にも未だ課題が残されていることがわかりました。
まとめ
本記事ではテキスト生成モデル(TGM)並びに自動生成テキスト検出技術の現状について紹介しました。GPT-2やGPT-3などのテキスト生成技術の大きな発展により、TGMの悪用の危険性はどんどん高まっています。そのため、こうした高度なTGMの悪用を防ぐための検出技術は今後非常に重要となっていくでしょう。
この研究領域に興味を持たれる方々にとって、本記事が有用な知識を提供できれば幸いです。




この記事に関するカテゴリー





