
時系列データ系列間の時点ずれを高精度かつ高速にアライメントするBILCO
3つの要点
✔️ NeurIPS 2022採択論文です。BILCOは時系列データの系列間で時点ずれが発生している場合のアライメントを行う
✔️ 従来のジョイントアライメント手法は精度は高いが、計算負荷が高く、普及が進まない
✔️ 初期化を工夫し、また双方向プッシング戦略により、元の問題を2つの小さな部分問題に変換することにより、平均で20倍の速度向上を達成
BILCO: An Efficient Algorithm for Joint Alignment of Time Series
written by Xuelong Mi, Mengfan Wang, Alex Bo-Yuan Chen, Jing-Xuan Lim, Yizhi Wang, Misha Ahrens, Guoqiang Yu
(Submitted on 01 Nov 2022)
Comments: NeurIPS 2022 Accept
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
概要
NeurIPS 2022採択論文です。時系列データを取り扱う場合、複数の時系列データ間で、時点ずれが発生し、アライメントを行うことが、データ解析の基本的な前処理ステップの一つになっています。従来のペアワイズアライメント手法が使用されていましたが、これらの時系列データは相互に依存していることが多く,アライメントタスクに余分な情報を与えるため、この情報をうまく利用することができません。最近、ジョイントアライメントはマックスフロー問題としてモデル化され、アライメントされた時系列間のプロファイル類似度と隣接するワーピング関数間の距離の両方が共同で最適化されるようになりました。しかし、この新しいモデルは、エレガントな数学的定式化と優れたアライメント精度を有するにもかかわらず、既存の汎用マックスフローアルゴリズムを用いるため、計算時間とメモリ使用量が大きく、その普及上、大きな制約となっています。本論文では、ジョイントアライメントマックスフロー問題を効率的かつ正確に解く新しいアルゴリズムであるBIdirectional pushing with Linear Component Operations (BILCO)を紹介します。ここでは、動的計画法とプッシュ-ラベルアプローチを統合した線形成分操作の戦略を開発しました。この戦略は、ジョイントアライメントマックスフロー問題がダイナミックタイムワーピング(DTW)の一般化であり、多数の個々のDTW問題が埋め込まれているという事実によって動機づけられています。さらに、良い初期化がジョイントアライメントマックスフロー問題に対して容易に計算できるという別の事実を活用し、事前知識を導入し、不必要な計算を減らすために、双方向プッシング戦略を提案しています。
BILCOの実証性の検証は、合成実験と実実験の両方を用いて行い、様々なシミュレーションシナリオと3つの異なるアプリケーションカテゴリにおいて数千のデータセットでテストした結果、BILCOは既存の最良のマックスフロー手法と比較して、少なくとも10倍、平均で20倍の速度向上と、最大1/8、平均1/10のメモリ使用量を一貫して達成しています。
はじめに
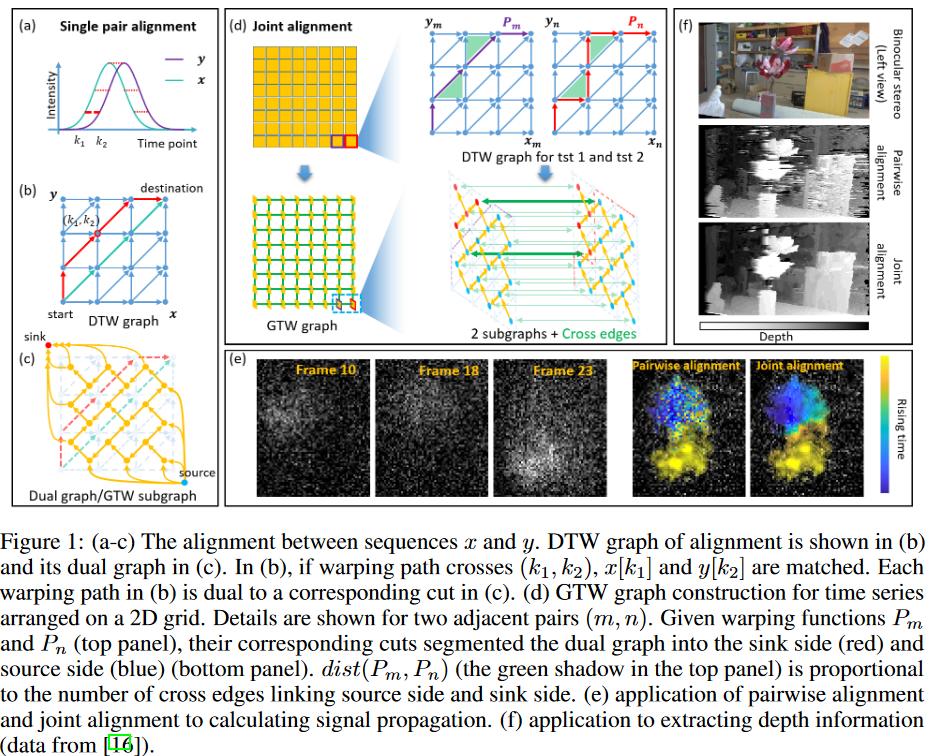
時系列データは、モーションキャプチャ、音声認識、バイオインフォマティクスなど、様々な分野で自然に現れるものです。通常、時系列データは遅延や歪みの可能性があるため、データ系列間、時点間を単純には直接比較することはできず、データ間のアライメントは要不可欠な前処理です。最も一般的なアライメント手法である動的時間歪み法(DTW)は、動的計画法(DP)を用いて線形時間で2つのシーケンス間の最適なマッチングを見つけるものです。しかし、DTWとその亜種は単一の時系列の組を比較するだけであり、実データに含まれる構造情報が活用されません。例えば、タイムラプス顕微鏡のデータでは、画素強度が2次元格子状に経時的に記録され、隣接する画素は類似した時間パターンを持つ傾向があります。したがって、単一ペア以上のジョイントアライメントは、構造からの依存性を利用することで、より良い性能を達成することが期待されます。
長い間、構造情報を原理的にどのように取り込むかは明確でありませんでしたが、最近様々な発見的トリックが開発されました。最近の理論的ブレークスルーとして,ジョイントアライメント問題は,時系列ペアワイズ類似度とワープ関数間距離の両方を最適化することにより,グラフィカルタイムワーピング(GTW)グラフのマックスフロー問題としてエレガントにモデル化されました。GTWは、脳活動解析や液体クロマトグラフィー質量分析(LC-MS)プロテオミクスなどの多くのアプリケーションにおいて、優れたアライメント精度を持つことが示されており、ワープ関数は参照時系列に対する各時点の実信号の遅延を表し、隣接時系列は同様に伝播すべきであるとされています。ワープ関数の非類似度にペナルティを加えることで、GTWは構造情報を利用し、Fig. 1(e)(f)に示すように、より良いアライメント性能を得ることができます。しかし、GTWは既存の汎用的なmax-flowアルゴリズムで解かれているため、計算時間が長く、メモリ使用量も多いという問題があり、幅広い応用が制限されています。実際、5000組の時系列からなる典型的なデータセットにおいて、各時系列が200時点を含む場合、incremental breadth-first search (IBFS) , Hochbaum's pseudoflow (HPF) , Boykov-Kolmogorov (BK) max-flow, highest-label push-relabel (HIPR) など、すべての一般的手法では数時間と100Gバイト以上のメモリを消費することになります。
本論文では、ジョイントアライメント・マックスフロー問題の2つの重要な性質を明らかにし、それらを活用することで、速度とメモリ効率の両方が改善された新しいアルゴリズムを設計できることを示します。具体的には、まず、ジョイントアライメントはペアワイズアライメントの一般化であり、Fig. 1(a)〜(d)に示すように、多数の個別DTW問題が埋め込まれています。依存関係を無視すれば、複数の独立したDTW問題に還元され、DPにより線形時間で解くことができます。依存関係があるため問題は複雑になるが、DTW問題の特性は生かすことができます。第二に、ジョイントアライメントの粗い近似解は、多くのアプリケーションで容易に推定することができます。このような事前知識は、マックスフローアルゴリズムを加速するために取り入れることができます。
この2つの性質を利用して、本論文では、ジョイントアライメントマックスフロー問題を正確かつより効率的に解く新しいアルゴリズムであるBIdirectional pushing with Linear Component Operations (BILCO)を開発しました。このアルゴリズムは2つの主要な戦略からなります:
(a)最初の特性を利用し、DPとプッシュ-リラベルlアプローチを統合するExcess pushing with Linear Component Operations (ELCO)を提案する。
各コンポーネントは、接続ノードとそれらに関連するエッジを含む小さなサブグラフとして定義される。コンポーネントは自動的かつ適応的に決定される。DPとサブグラフの特性を組み合わせることで、各成分に対する全ての演算が線形時間で達成できることを示す。線形成分操作により、ELCOは一般的なプッシュ-リラベルアプローチよりも高い効率を達成することができる。
(b) 2番目の性質を利用し、事前知識を初期化として利用する双方向プッシュ戦略を設計する。
この戦略は、元の問題を、プッシュ方向が逆である2つの小さなサブ問題に単純化する。各問題ではELCOが適用されるが、2つのプッシング方向が分離されているため、不要な計算が劇的に削減される。
BILCOは、HIPRのような最高の一般的な手法と同じ理論的な時間複雑性を持つが、ジョイントアライメントのタスクにおいて精度を犠牲にすることなく、経験的に大幅な効率アップを実現するものです。その有効性は、合成実験と実実験の両方を通じて証明されています。IBFS、HPF、BK、HIPRと、様々なシミュレーションシナリオの数千のデータセットと、異なるカテゴリーの3つの実アプリケーションで比較した結果、BILCOは、最良の同種の手法に比べて、10〜50倍の速度向上と平均10分の1のメモリコストで済むことが分かりました。
問題定義
時系列節のアライメント問題は、次のように定式化できます。
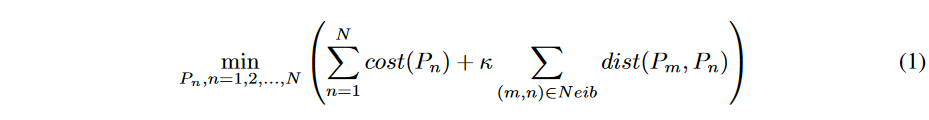
ここで、Pnはn番目の時系列ペアのワーピングパスを示し、Nは共同整列される時系列ペアの総数、cost(Pn)はn番目の時系列ペアの整列コスト、dist(Pm,Pn)はPmとPnで囲まれた領域の面積で定義されるワーピングパス距離です。Neibは隣接する時系列を表すペアインデックス(m、n)の集合、κはアライメントコスト項と距離項のバランスをとるためのハイパーパラメータです。例えば、2次元グリッド時系列データの場合、Neibは隣接するピクセルのペアを含み、κはピクセル間の事前類似度を表します。
Fig.1 に示すように、式(1)をフローネットワークに変換し、その min-cut を求めることで解くことができます。構築されたグラフ、動的時間歪み法GTWグラフは、N個のGTW部分グラフ{Gn = (V n, En)|n = 1, 2, ..., N }と容量κ2の交差辺Ecrossからなります(Fig. 1(d))。GTW部分グラフ内のエッジをEwithinと呼ぶ。以下の内容では、便宜上、「GTW subgraph」を「subgraph」と表記します。各サブグラフGnは、一対の時系列間のワーピングを表すDTWグラフと双対です。サブグラフ内のカットは時系列ペアのワーピングパスと双対であるため(Fig. 1(b)〜(c))、動的計画法(DP)により最短経路を求めることで1つのDTWグラフのミニカットを線形時間内に解くことができます。クロスエッジは隣接する部分グラフのカットの差を拘束し、式(1)の距離の項に相当します(Fig. 1(d))。ワーピングパスの単調性と連続性を保証するため、各サブグラフの逆辺の容量は無限大に設定されます。
GTWのフレームワークは柔軟で広く適用可能であり、構造情報を活用しながら多くの問題を解決するためのビルディングブロックとして利用できることは特筆に値します。想定される近傍構造と類似性の強さは、アプリケーションに特化することも、ユーザーが設計することも可能です。例えば、異なるワーピング関数の組に対して、GTWは異なるハイパーパラメータκを設定することができます。簡単のために、本論文では、以下、すべてのワーピング関数の組に対して同じハイパーパラメータκを用います。
手法
BILCOは、前述のように、それぞれELCOと双方向プッシングという二つの主要な部分を含んでいます。ワーピング関数の初期化に基づいて、双方向プッシング戦略は最大フロー問題を2つのサブ問題に変換し、それぞれをELCOで解きます。この統合によりBILCOが導かれ、その後時間複雑性とメモリ使用量の分析が行われます。
Excess pushing with linear component operations (ELCO)
GTWグラフはDTWグラフと双対をなす部分グラフを多く含み、各DTWグラフはDPによって線形に解くことができるため、本論文のアプローチではDTWグラフとDPアルゴリズムが利用できることを期待しています。グラフ間のクロスエッジによりDPの直接利用はできませんが、定義したコンポーネントがDPの利用を可能にする最大の部分グラフであることを見いだしました。新たに考案したグラフ変換戦略(Fig. 3)とDPを組み合わせることで、定義したコンポーネントに対する操作「Drain」「Discharge」は、実際に線形に実装可能であることを確立しました。大域的な最適性を保証するために、3.1.4節に示すような新しいラベリング関数を設計し、それを使ってコンポーネントの操作をガイドする。
・操作の基本単位はノードやサブグラフではなく、コンポーネント
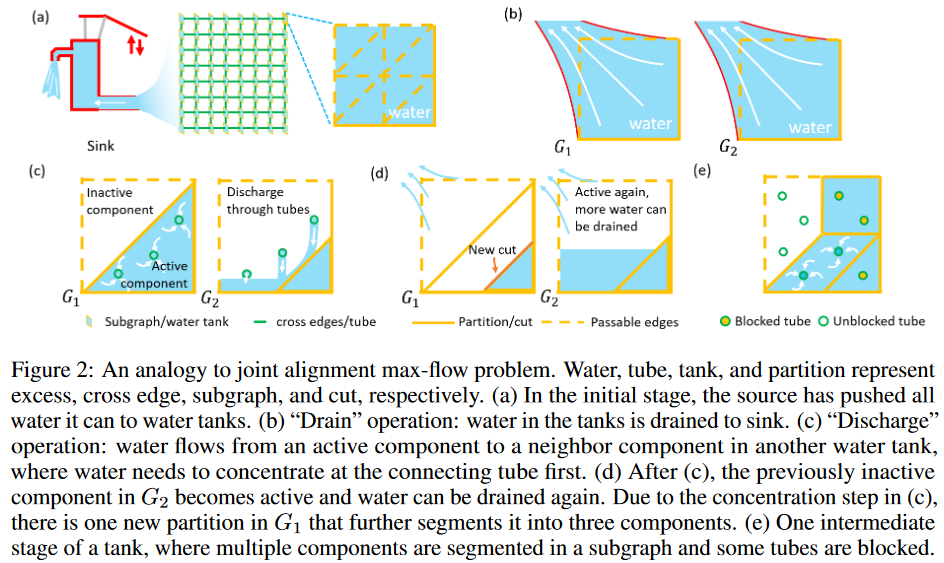
各サブグラフの特性を利用するために、ELCOは、操作が局所化されている一般的なプッシュ・ラベル・アルゴリズムのアイデアを借用している。ELCOは、1つのノードの流入フローと流出フローの間の余剰である余剰の存在を許容する。余剰を持つノードは「アクティブ」とみなされる。フローの交換場所に基づいて、"Drain "と "Discharge "という2つのオペレーションを定義する。「Drain "はEwithinを通して余剰分をシンクに押し出す操作であり、サブグラフ内の操作である。一方、DischargeはEcrossを通して隣接するサブグラフに余剰分を押し出すクロスサブグラフ操作である。この2つの操作を交互に行うことで、より多くの余剰分をシンクに送ることができます(Fig.2)。余剰分が広がると、多くの辺が飽和状態になり、同じサブグラフに複数のカットが発生します。これらの切り口は、サブグラフを異なる構成要素に分割します(Fig.2(e))。ここで、1つのコンポーネントを、隣接する2つのカットに囲まれたGTWサブグラフの部分集合と定義します。ELCOでは、ノードやサブグラフの代わりにコンポーネントを基本演算単位として用いています。これは、DPを用いてフローをプッシュする際に、コンポーネントが最も大きな単位となるためです。
・補題1
2つのノードが同じコンポーネントにある場合、それらを結ぶパスが少なくとも1つ存在する。
補題 1により、あるコンポーネント内の1つのノードがアクティブであれば、その余剰分は同じコンポーネント内のどこにでも広がることができます。したがって、コンポーネント全体を1つの単位として見ることができます。逆に、カットは同じサブグラフ内のコンポーネントをまたぐ流れを遮断するため、サブグラフ全体を1つのユニットと見なすことはできません。
コンポーネントを基本演算単位として、ELCOは以下のように記述されます。初期状態では、各サブグラフは1つのアクティブなコンポーネントです。「Drain」操作は、Ewithinを通して、最大の余剰を直接シンクに送ります。新しいカットが生成され、ソースに近い分割されたコンポーネントの余剰分がブロックされます。次に、「Drain」を実行できるコンポーネントに向かって、余剰分をサブグラフ全体に移動させる機会を探す「Discharge」の番が来ます。この2つのコンポーネントの操作を交互に実行することで、グローバルな最大フローを達成することができます。
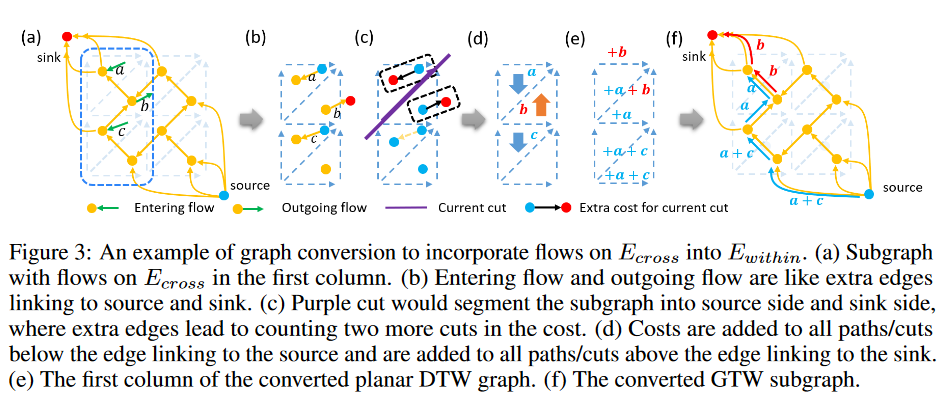
・ドレイン "部品動作の線形時間実装
「ドレイン」操作については、シンクにリンクする1つの活性成分のmin-cutを計算するだけで、新しいカットより上の余剰分はすべてドレインされ、新しいカットより下の部分が新しい活性成分として特定されます(Fig. 2(b)(c))。前述のように、min-cutはその双対グラフ上のDPによって高速に解くことができます。しかし、Ecross上のフローでは、DPを直接適用することはできません。グラフは平面でなくなり(Fig. 3(a)(b))、その双対グラフも存在しません。そこで、Fig. 3に示すような線形時間グラフ変換戦略(補足のアルゴリズム参照)を設計し、Ecross上の既知のフローをEwithinに取り込み、DPがまだ適用可能な等価平面グラフを得ることができるようにします。線形変換戦略とDPを組み合わせることで、「Drain」成分の演算を線形時間で実現することができます。
・補題2
グラフ変換前と後の対応するカット値/パスコストは同じ
・「放電」コンポーネント動作の線形時間実装
1つのコンポーネントを排出するために、各ノードで余剰分を可能な限り押し出し、コンポーネントが余剰分を全て送ったことを確認します。余剰分は同じコンポーネント内のどこにでも流れる可能性があるからです。
・補題3
ノードvの最大可能超過量は、vをシンクとした場合の残差グラフのmin-cut値である
修正DTWグラフで作業しても、DPはv以下の最短経路とグラフ全体の最短経路の差を求めることで、このような超過分を計算することができます。この差は、補題 3で述べたmin-cutの値を表すことができます。線形複雑度成分の「放電」操作を実装するために、ここでは、最短距離を再帰的に保存する保存された動的行列を再利用するDPの別のレイヤーを使用しています。
・シンクに近づく余分なものを部品間で誘導する新しいラベリング機能
本論文は、高ラベルから低ラベルへの成分間の過剰な接近tを導くために、新しいラベリング関数を設計しました。一般的なpush-relabelのものとは異なり、ここでのラベリング関数は、ノードからではなく、あるコンポーネントからシンクまでの距離を意味するものです。カットは同じ部分グラフの成分間の接続を遮断するので、Ecrossのみがカウントされます。このような距離から派生して、ラベリング関数 d : V → N は、すべての残差エッジに対して、以下の場合に有効であると定義します。
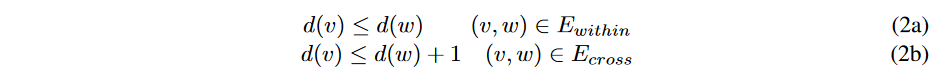
・補題4
同じコンポーネントのノードはすべて同じラベルを持つ
・補題5
新しいラベリング関数(2)は、各コンポーネントを1つのユニットとして扱えば、一般的なプッシュリラベルラベリング関数と整合する
補題4は、1つのコンポーネントとその中のすべてのノードに同じラベルを設定できることを示唆しています。また、補題5は、ELCOがコンポーネントを演算単位とする代替プッシュ・ラベル・アプローチとみなすことができ、一般的なプッシュ・ラベル・アプローチ のすべての記述がコンポーネントレベルでも成立することを示唆しています。ELCOではラベリング関数の妥当性が保たれているため、最適解は多項式成分操作で達成できます。
ELCOの概要はAlgo.1、Algo.2です。Rはコンポーネントの記号です。R1 → R2 は v∈R1 と w∈R2 に対して (v, w) が正の残差容量を持つ場合、最高ラベル選択規則を適用し、グローバルリラベルヒューリスティックとギャップリラベルヒューリスティックの両方を加速のために利用します。


双方向プッシュ型戦略
一般的なプッシュ・ラベル方式やELCOは、余分なものをできるだけシンクに押し込もうとします。もし、余剰分の一部がエッジの容量制限によりシンクに到達できない場合、ソースに吸収される必要があるが、これには長い時間と高い計算コストがかかる可能性があります。このような余剰分は、最大流量に影響を与えることも、最終的なカットを変更することもできないため、このような計算は冗長です。ELCOは、線形成分演算により各成分内の冗長性の一部を低減するが、特にκが大きい(Ecrossの容量が大きい)場合、成分間の問題を解決することができません。κが大きい場合、Ewithinは飽和しやすく、コンポーネントは小さく分割されやすくなります。このように、各成分だけに着目すると冗長性を低減することは困難です。
極端な例として、全てのノードがカットに従ってソース側VTに分割される場合を考えます。この場合、すべての余剰はシンクに到達することができ、すべてのプッシュ操作は冗長になりません。もう一つの極端なケースでは、全てのノードがソース側VSに属します。ほとんどの余剰はシンクに到達できないが、それでもプッシュされるため、冗長な計算が発生します。逆に、ソースから余分なものをプッシュするよりも、シンクから不足分をプッシュする方が良い戦略です。赤字とは、入力の流量が出力の流量より少ないことを意味します。赤字を押し出すことは、計算のあるグラフでは、過剰を押し出すことに他なりません。もし、ワーピングパスの初期化を見つけるための予備知識があれば、シンク側で過剰を、ソース側で不足を押し出すだけでよいです。その後は、ほとんど計算の無駄はない。このような考えから、ソースとシンクを入れ替えた双方向プッシング戦略(Fig.4)を設計することにしました。すべてのノードがVSに分割されているので、赤字を逆方向に押し出す操作はすべて冗長になりません。結論として、シンク側VTで過剰を押しても、ソース側VSで不足を押しても、グラフが無効になることはありません。
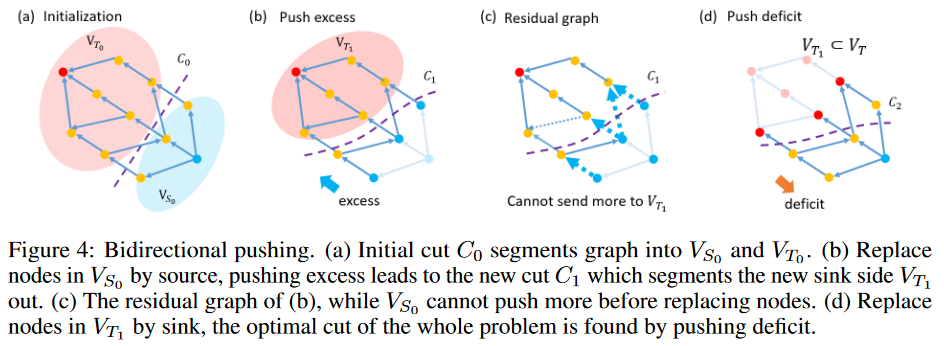
初期化:GTWグラフの初期カットC0 を推定する。対応するソース側とシンク側をそれぞれ VS0, VT0 とする.
超過分を押し出す:VS0 のすべてのノードをソースに置き換え、余剰分を押し出すことによってマックスフロー問題を解く。新しいミニカットC1 によって分割された新しいシンク側をVT1 とする。
赤字を押す:VT1 のノードをすべてシンクに置き換え、max-flow 問題を赤字のプッシュで解く。得られたミニカットC2は、元のGTWグラフのミニカットである。
この戦略は、以下の記述により最適解を達成することが保証されています。
・補題6
ミニカットがノードVをソース側VSとシンク側VTに分割すると仮定すると、VSまたはVTのノードをソースまたはシンクに置き換えても、ミニカットに影響を与えない。
・補題7
VTが,元のGTWグラフの実ミニカットが分割したシンク側のノードを表すとすると,VT1⊆VT.
・定理1
双方向戦略で得られるミニカットは、元のグラフのミニカットである。
ジョイントアライメント問題では、κが大きいと類似性ペナルティが大きくなるため、最終的なカットが類似する傾向があるので、良い初期化が見つかりやすいです。
線形成分演算による双方向プッシュ
小さいκの下では、成分は通常大きく、ELCOは効率的に働くことができます。一方、κが大きい場合は、異なる部分グラフのカットが類似しており、初期解を容易に推定することができます。したがって、双方向プッシング戦略がうまく機能します。各サブグラフの初期化を、平均化されたサブグラフの最適ワーピングパス(無限κのジョイントアライメントの解でもある)とすることで、BILCOは両方の利点を取ることができ、どのκにおいても良い性能を持つようになりました。本手法は実験においてこのような初期化を用い、良好な性能を得ました。したがって、少なくとも類似のアプリケーションでは、BILCOの初期設定としてこれを推奨します。
複雑性
双方向プッシング戦略は、元の問題を2つの小さな部分問題に変換することができ、あらゆるマックスフロー法を加速するのに役立つ可能性があります。例えば、最良のケースでは、初期化が正確で、問題を2つの半分の大きさの部分問題に分割することができます。その場合、O(|V |2p|E|) 法の速度は、VとEが半分になるため、3倍近く加速されます。初期化が悪い場合でも、この戦略は複雑さの限界に影響を与えることなく、演算数を増加させるだけです。
ELCOはDTW(複雑度Θ(|V |))とHIPR(複雑度O(|V |2p|E|) )の統合のようなものです。一方、EcrossはELCOをDTWより複雑にするため、下限Ω(|V |)を持ちます。一方、過剰なプッシュを行うために線形成分演算を使用することで、ELCOはHIPRよりも演算単位が少なく、複雑さが軽減されます。各コンポーネントが1つのノードしか含まない最悪のケースでも、ELCOはHIPRと同じ上界を持ち同等です。したがって、BILCOの最悪の複雑度はO(|V |2p|E|)です。
メモリー使用度
また、BILCOはGTWグラフの構造を利用することで、メモリ効率を向上させることができます。一般的なマックスフロー法では、メモリの大部分をノードとエッジの関係を記録するために使用します。BILCOでは、グラフ構造が既知であるため、ノードとエッジを座標順に格納し、その位置関係から関係を導き出すことが可能です。実際のアプリケーションでは、成分数は大きな|V|と|E|に比べれば無視できるほど少ないので、成分の保存にかかる費用は重要ではありません。Table 1はBILCOとピアメソッドのメモリ使用量をその実装に基づいて比較したものです。

実験
ここでは、合成シミュレーションと実アプリケーションのもとで、BILCOの効率性をIBFS、HPF、BK、HIPRの4つのピアメソッドと比較します。すべての実験は、Intel(R) Xeon(R) Gold 6140@2.30Hz、128GBメモリ、Windows 10 64ビット、Microsoft VC++コンパイラーを使用し、MATLABで実施されました。GPUは使用していません。すべてのメソッドは、MATLABのラッパーを使用したC/C++で実装されています。
合成データ
画素(N )とフレーム(T )を変化させた画像信号伝搬データセットをシミュレートしました。4-コネクテッドネイバーを使用したため、GTWグラフは|V|=2N T 2ノード、|E|=7N T 2エッジ程度となります。画像の中心から境界までベル型の信号が伝搬します。ガウスノイズはS/N比が10dBになるように加え、実際のシナリオを模倣しました。ハイパーパラメータκを比較可能にするため、ノイズの標準偏差を割ることで合成データを正規化しました。N、T、κの各組み合わせについて、20インスタンスのテストを行いました。
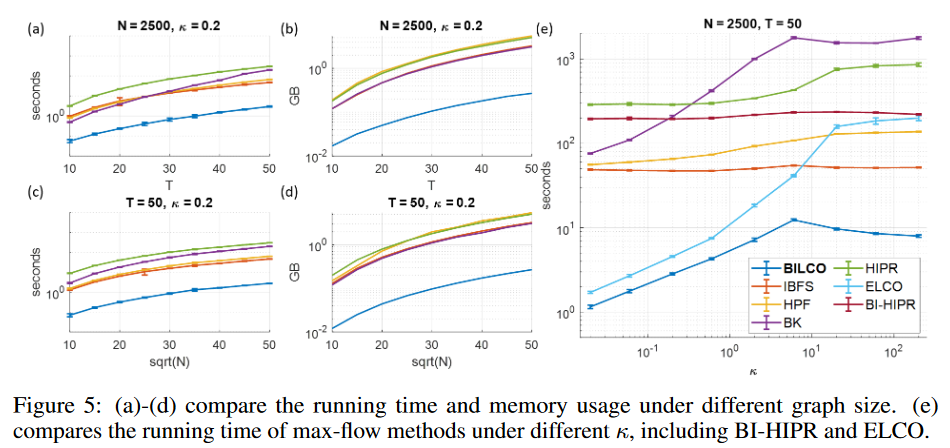
Fig. 5(a-d)はグラフサイズを変えてBILCO法とピア法を比較したもので、BILCO法はどのピア法よりも10倍以上速く、メモリコストも1/10で済むことがわかります。Fig. 5(e)はハイパーパラメータκの影響を示しており、HIPRと本手法の双方向プッシング戦略(BI-HIPR)およびELCO法を比較したものです。このように、Ecrossの容量が大きくなると、交換フローの自由度が増し、グラフが複雑になるため、κが大きくなると、ほとんどの手法の実行時間が長くなることがわかります。すべての手法の中で、BILCOはいかなるκの下でも最高の効率を示します。ELCOとBILCO、またはHIPRとBI-HIPRを比較すると、双方向プッシング戦略により、特に大きなκの下で両手法が高速化されることがわかります。これは、デフォルトの初期化が、κが大きくなると最適解に近づき、不要な計算が効果的に取り除かれるためです。また、Fig.5(e)は、ELCOと双方向プッシュの2つの戦略が補完的で相乗効果があることを示している。κが小さいときは、ELCOが加速を支配しています。κが大きい場合は、双方向プッシュがより大きな影響を与えます。興味深いことに、この2つの戦略は、κが大きい場合に相乗的に速度を向上させます。例えば、最大のκの下では、BI-HIPRとELCOは共にHIPRの4倍近く高速化し、独立効果の16倍の高速化を示唆し、BILCOはHIPRと比較して約100倍の高速化を示しています。
実データ
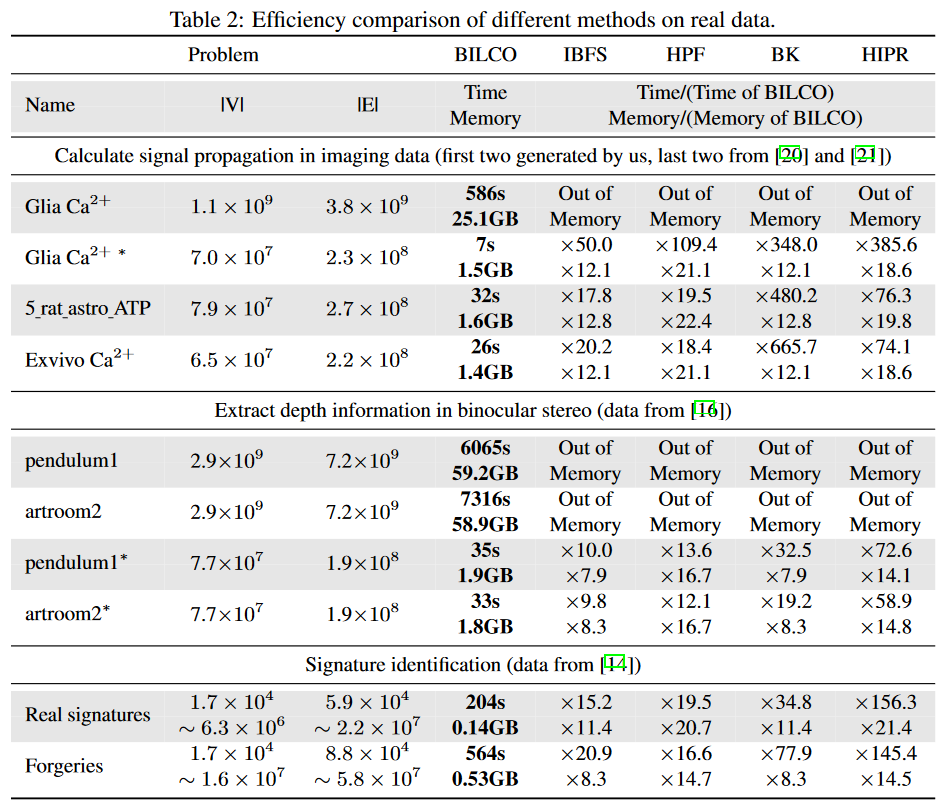
ここでは、信号伝播の計算、深さ情報の抽出、署名識別という3つの異なるアプリケーションカテゴリにおいて、本手法のBILCOと4つのピアメソッドを比較します。これらのmax-flow法はすべて同じ結果を与えるので、ここでは、Table 2に示すように、実行時間とメモリ使用量のみを比較します。名称の*は空間的にダウンサンプリングされたデータを表します。BILCOをベースラインとし、他が何倍コストがかかるかを示しています。2番目の応用例は2つの画像間の同じ行の位置ずれから深さを導き出すことができるが、隣接する行の深さ分布は類似していると仮定しています。本実験では、比較的大きな視差を許容しつつ、不要な計算を避けるため、ウィンドウサイズを配列長の1/5としました。3番目の応用例として、20人の署名を識別し、500人の本物の署名と500人の贋物の署名を参照署名と比較します。表には、2つの署名カテゴリに対する実行時間の合計と最大メモリ使用量が示されています。このように、BILCOはこれら全てのジョイントアライメントアプリケーションで常に最高のパフォーマンスを発揮します。BILCOは、最良のピアメソッドと比較して、約10~50倍の速度向上を示し、ほぼ1/10のメモリコストで済みます。特に、信号の伝搬を推定するアプリケーションでは、BILCOは他の手法に比べて平均29倍(18から50の範囲)高速に実行されます。これらのアプリケーションは多様であり、依存関係構造も深さ方向の2隣接、伝播方向の4隣接、署名方向の全隣接と様々であることを考慮すると、BILCOの優位性と幅広い応用性が力強く証明されたことになります。
結論
ジョイントアライメントはDTWと比較して、データの依存関係を利用するため、より良い性能を得ることができるが、速度とメモリを犠牲にしています。本論文では、この問題の特殊性を利用し、このような犠牲を最小限に抑えるBILCOアルゴリズムを開発しました。このアルゴリズムは、ジョイントアライメントマックスフロー問題を効率的に解くことができ、精度を犠牲にすることなく、正確に大域的最適解を得ることができます。理論的な解析に加えて、合成実験と実応用を通じてBILCOの効率性を実証しました。BILCOは、IBFS、HPF、BK、HIPRの中で最も優れた手法と比較して、約10〜50倍の速度向上と平均で1/10のメモリコストしか必要としないことを明らかにしました。また、様々なシナリオで検証を行った結果、BILCOの適用範囲の広さが示唆されました。本研究により、ジョイントアライメントの応用が促進され、様々な分野でより良い性能を得ることができると期待されます。
双方向プッシュ戦略は、一般的なプッシュ・ラベル高速化手法と見なせるだけでなく、BILCOの線形成分演算と相乗的に作用することが確認されました。双方向プッシュ戦略により、グラフは不要な過不足が少なくなるように分離され、飽和エッジやカットが少なくなり、より大きなコンポーネントが得られるようになる。成分が大きいと演算回数が大幅に削減できるため、前述したHIPRと比較した場合、BI-HIPR(4×)、ELCO(4×)の乗算よりもBILCOはさらに高速(100×)であることがわかります。
BILCOアルゴリズムは、特定のマックスフロー問題に対する特別なアプローチです。max-flowアルゴリズムの発明には長い歴史があるが、既存の方法は、経路の拡張に基づくもの、pushrelabelのような局所的操作、両者の組み合わせ、グラフ分解の統合のいずれでも、問題を効率よく解くことはできません。知る限り、DPと一般的なpush-relabel法を統合してmax-flow問題を解いたのはこの論文が最初です。この分野では、初期化はmax-flowアルゴリズムにあまり役立たないという一般的な感覚がありますが、ここでは双方向プッシュが初期化を活用する良い戦略であり、線形成分演算と組み合わせた場合に特に強力であることを示しました。ここでの取り組みが、ジョイント・アライメントの応用に役立つだけでなく、特定のネットワークフロー問題の方法論開発への刺激となることを期待しています。古典的な問題に対してより良い汎用アルゴリズムを発明することは難しいですが、より特殊な問題に対しては多くの機会があり、最近の問題の超大規模化により実際に大きな需要があることを感じているとしています。




この記事に関するカテゴリー






