
生成モデルを用いた時系列予測D3VAE
3つの要点
✔️ NeurIPS 2022採択論文です。D3VAEと呼ばれる生成モデルを用いた時系列予測の新しい方法を提案しています。拡散、ノイズ除去、およびもつれ解除の手法と双方向変分オートエンコーダーを組み合わせたものです。
✔️ 限定的でノイズの多いデータによる時系列予測の問題に対処し、より安定していて解釈しやすい予測を提供することを目的としています。
✔️ 提案された方法の有効性を実証するために、合成データと現実世界のデータに関する広範な実験を紹介しています。
Generative Time Series Forecasting with Diffusion, Denoise, and Disentanglement
written by Yan Li, Xinjiang Lu, Yaqing Wang, Dejing Dou
(Submitted on 8 Jan 2023)
Comments: NeurIPS 2022 Accept
Subjects: Machine Learning (cs.LG)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
AI-SCHOLARイベント
AI技術は日進月歩で進み、皆さんもAI技術に関して多くのブームから衰退までを見ていると思います.そんな中,昨今のブームといえば,GPTからの大規模言語モデルだと思います.そこで,今回はAI-SCHOLARのメンバーを集めて,GPTの総論から話題にも上がるセキュリティ周りなどの技術者・研究者目線でのイベントを実施いたします.

概要
NeurIPS 2022採択論文です。テーマは時系列予測です。この論文では、D3VAEと呼ばれる生成モデリングを用いた時系列予測の新しい方法を提案しています。この手法は、拡散、ノイズ除去、デエンタングルメント(もつれ解除)の手法と双方向変分オートエンコーダー(BVAE)を組み合わせたものです。提案手法は、限定的でノイズの多いデータによる時系列予測の問題に対処し、より安定していて解釈しやすい予測を提供することを目的としています。具体的には、偶然の不確実性を増加させることなく時系列データを補強し、BVAEでより扱いやすい推論プロセスを実装するために、連成拡散確率モデルを提案します。さらに、生成された時系列が真の目標に向かうようにするため、マルチスケールノイズ除去スコアマッチングを時系列予測のための拡散プロセスに適応し統合することを提案します。さらに、予測の解釈可能性と安定性を高めるために、潜在変数を多変量に扱い、全相関を最小化した上で、それらを切り離します。
はじめに
時系列予測は、リスク回避や意思決定において非常に重要です。従来のRNNベースの手法は、時系列の時間的依存性を捉えて将来を予測します。長期短期記憶(LSTM)とゲート型リカレントユニット(GRU)は、セル構造にゲート関数を導入して長期依存性を効果的に処理します。畳み込みニューラルネットワーク(CNN)に基づくモデルは、畳み込み演算によって時系列の複雑な内部パターンを捉えます。最近、トランスフォーマーに基づくモデルは、マルチヘッドの自己アテンションの機能を発揮して、時系列予測で素晴らしい性能を示しています。しかし、時系列予測におけるニューラルネットワークの大きな問題の一つは、深層構造の特性に起因する不確実性です。ベクトル自己回帰(VAR)に基づくモデルは、隠れた状態から時系列の分布をモデル化しようとするもので、予測により信頼性を与えることができますが、その性能は満足できるものではありません。
また、解釈可能な表現学習は、時系列予測のもう一つのメリットです。変分オートエンコーダ(VAE)は、データの潜在分布をモデル化し、勾配ノイズを低減することに優れているだけでなく、時系列予測の解釈可能性も示しています。しかし、VAEは潜在変数が絡み合うため、解釈可能性が劣る可能性があります。
表現異同を学習する取り組みが行われており、良好にもつれ解除された表現がアルゴリズムの性能と頑健性を向上させることができることが示されています。
さらに、実世界の時系列はノイズが多く、短時間で記録されることが多いため、オーバーフィットや一般化の問題が生じることがあります。このため、この論文では、時系列予測問題を生成的モデリングで解決します。具体的には、拡散、ノイズ、もつれ解除を備えた双方向変分オートエンコーダ(BVAE)、すなわちD3VAEを提案します。具体的には、まず、拡散モデルの前進過程から着想を得て、入力時系列と出力時系列を増強することにより、時系列データの制限を改善する結合拡散確率的モデルを提案します。また、Nouveau VAEを時系列予測タスクに適応させ、拡散モデルの逆プロセスの代用としてBVAEを開発します。このように、拡散モデルの表現力とVAEの扱いやすさを合わせて、生成的な時系列予測に活用することができます。しかし、一般化できる利点がある反面、拡散されたサンプルが破損する可能性があり、その結果、生成モデルがノイズの多い目標に向かって進んでしまいます。そこでこの論文では、拡散した時系列をクリーニングするために、スケールされたノイズ除去スコアマッチングネットワークをさらに開発します。さらに、潜在変数の異なる次元が異なる時間的パターン(トレンド、季節性など)に対応すると仮定することで、時系列の潜在変数を分離しています。
ここでの貢献は以下のように要約されます。
- 我々は、時系列のアレータ的不確実性を低減し、生成モデルの汎化能力を向上させることを目的とした連成拡散確率論的モデルを提案する。
- また、生成結果の精度を向上させるために、マルチスケールノイズ除去スコアマッチングを連成拡散プロセスに統合する。
- 生成モデルの潜在変数を分離し、時系列予測における解釈可能性を向上させる。
- 合成データセットと実世界データセットを用いた広範な実験により、D3VAEが競合するベースラインを満足なマージンで上回ることが実証された。
手法
生成時系列予測
問題の定式化
入力データは n 個のデータ点で構成される多変量時系列 X で、各データ点 xi は D 次元のベクトルです。対応するターゲット時系列 Y は m 個のデータ点で構成され、各データ点 yj は d' 次元のベクトル (d' ≤ d) です。目標は、ガウス分布 Z ~ p (Z|X) から抽出された潜在変数 Z からターゲット時系列 Y を生成することです。潜在変数の分布は、pφ (Z|X) = gφ (X) として定式化されます。ここで、gφ は非線形関数です。ターゲット系列のデータ密度は式 (1) で求められます。ここで、pσ (Y) はターゲット系列の確率密度関数、fσ はパラメーター化関数、Z は潜在変数空間 ΩZ で積分されます。対象となる時系列は、pθ (Y) からサンプリングすることで取得できます。
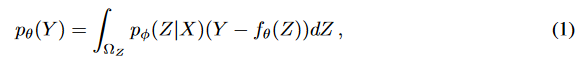
ここで問題設定している時系列予測は、Xの有用な信号を捉える表現Zを学習し、低次元のXを高い表現力で潜在空間に写像することです。D3VAEのフレームワークの概要はFig. 1の通りです。詳細な技術に入る前に、まず、予備的な命題を紹介します。
命題 1
時系列 X は Xr と X に分解できます。ここで Xr はノイズのない理想的な時系列データです。根拠となる真実と予測の誤差は、ランダム的な不確実性と認識論的な不確実性の組み合わせと見なすことができます。
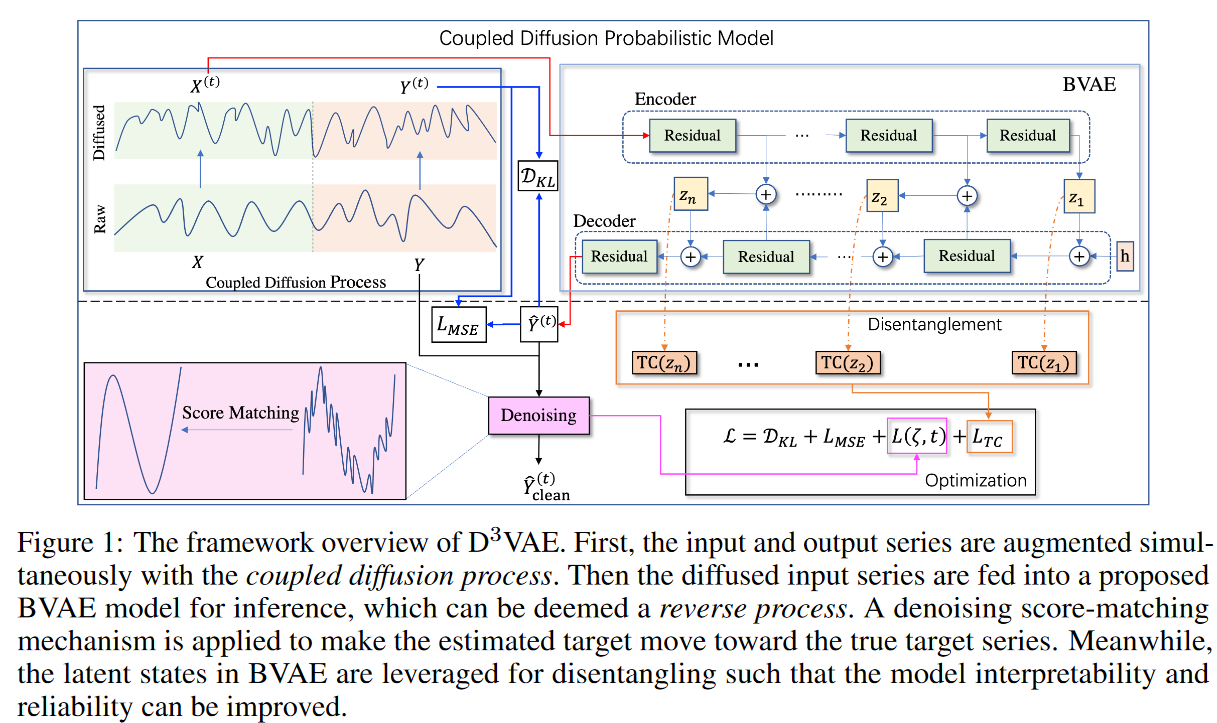
結合拡散確率モデル
拡散確率モデル(略称:拡散モデル)は、高品質なサンプルの生成を目的とした潜在変数モデル群です。生成時系列予測モデルに高い表現力を持たせるために、入力系列と目標系列を同期的に増強する結合順プロセスが開発されています。また、予測タスクでは、より扱いやすく正確な予測が期待されます。そのために、拡散モデルの逆行列の代わりに双方向変分オートエンコーダ(BVAE)を提案します。
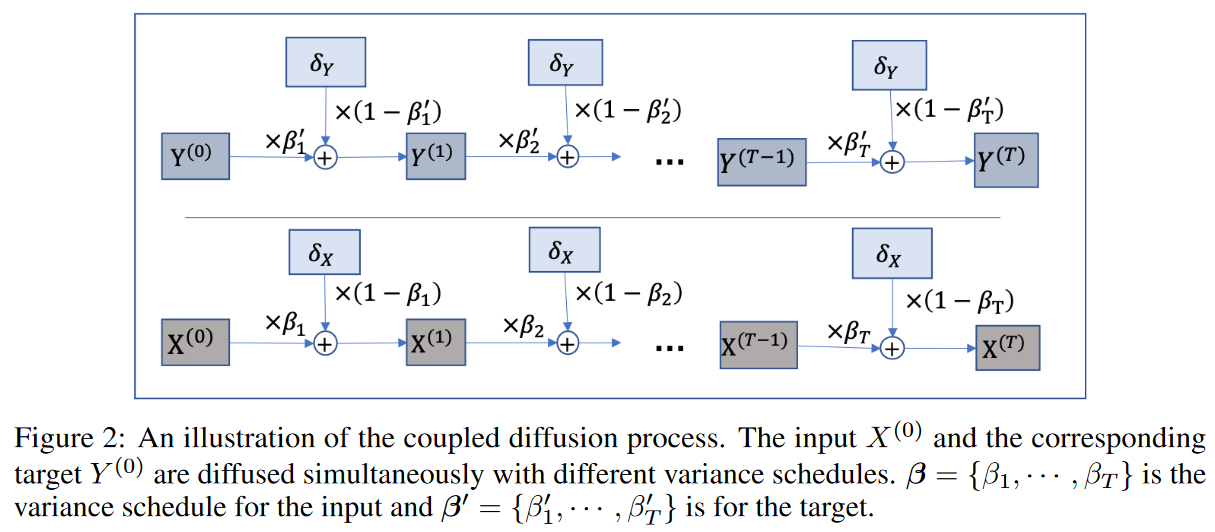
結合拡散プロセス
前方拡散過程は、データにガウスノイズを徐々に加えるマルコフ連鎖に固定されています。入力と出力の系列を拡散させるために、Fig. 2に示すような連成拡散過程を提案します。具体的には、入力X = X(0) ∼ q(X(0))が与えられると、近似事後q(X(1:T )|X(0)) は以下のように求められます。
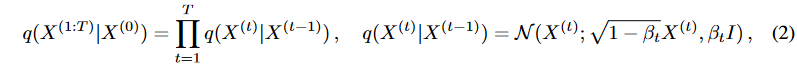
ここで、付加するノイズのレベルを制御するために、一様増加分散スケジュールβ={β1,-,βT|βt∈[0,1]}が採用されます。そして、αt=1〜βt、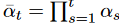 とすると、次のようになります。
とすると、次のようになります。
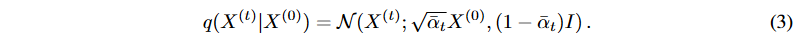
さらに、命題1により、 X(0) を X(0) = Xr , ϵX のように分解することができます。そして、式(3)を用いて、拡散されたX(t) を以下のように分解することができます。
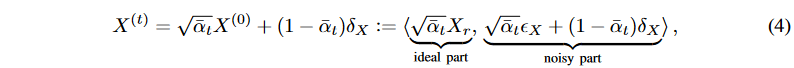
ここで、δXはXの標準ガウスノイズを示します。αは分散予定βが分かれば決定できるので、拡散過程で理想部分も決定されます。ここで、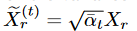 、
、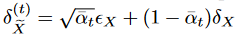 とすると命題1および式(4)により、次のようになります。
とすると命題1および式(4)により、次のようになります。
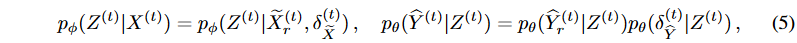
ここで、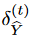 は
は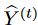 の生成ノイズを表します。時系列データに起因する偶発の不確実性の影響を緩和するために、さらに、対象系列
の生成ノイズを表します。時系列データに起因する偶発の不確実性の影響を緩和するために、さらに、対象系列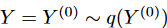 に対して拡散プロセスを適用します。具体的には、
に対して拡散プロセスを適用します。具体的には、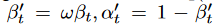 、
、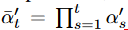 となるようなスケールパラメータ ω∈(0, 1)を採用し、命題1に従って、以下の分解(式(4)と同様)を得ることができます:
となるようなスケールパラメータ ω∈(0, 1)を採用し、命題1に従って、以下の分解(式(4)と同様)を得ることができます:
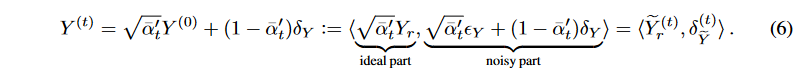
その結果、q(Y (t)) = q( ̃ Y (t) r )q(δ(t) ̃ Y ) となります。その後、命題1と式(5)、(6)を用いて以下の結論を導くことができます。
レンマ1 ∀ε > 0,について、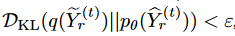 を保証する確率モデル fφ,θ := (pφ, pθ) が存在する. ここで
を保証する確率モデル fφ,θ := (pφ, pθ) が存在する. ここで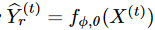 とする。
とする。
レンマ2 拡散過程の連成により、拡散ノイズと生成ノイズの差が小さくなる。すなわち、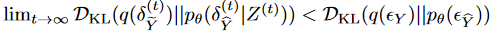
したがって、生成モデルやデータ固有のノイズによって生じる不確実性は、連成拡散プロセスによって低減することができます。さらに、拡散過程は入力系列と目標系列を同時に増強するため、(特に短い)時系列予測の汎化能力を向上させることができます。
双方向変分オートエンコーダ
従来、拡散モデルでは、高品質なサンプルを生成するために逆プロセスが採用されています。しかし、生成的な時系列予測問題では、表現力だけでなく、基底真理の監視も考慮する必要があります。本研究では、より効率的な生成モデル、すなわち双方向変分オートエンコーダ(BVAE)を採用し、拡散モデルの逆過程を代行させます。BVAEのアーキテクチャはFig. 1に示すように、Zを多変量に扱う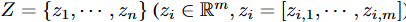 と
と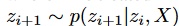 です。そして、nはエンコーダだけでなく、デコーダでも残差ブロックの数に応じて決定されます。BVAEのもう一つの利点は、モデルの解釈可能性を向上させるために、離散化を統合するインターフェイスを開くことです。
です。そして、nはエンコーダだけでなく、デコーダでも残差ブロックの数に応じて決定されます。BVAEのもう一つの利点は、モデルの解釈可能性を向上させるために、離散化を統合するインターフェイスを開くことです。
拡散時系列クリーニングのためのスケールドノイズ除去スコアマッチング
時系列データは前述の連成拡散確率モデルで補強することができますが、生成分布pθ( ̂ Y (t))は破損した拡散ターゲット系列Y (t)に向かう傾向があります。 生成されたターゲット系列をさらに「きれいに」するために、モデルの柔軟性を犠牲にすることなく、不確実性の除去プロセスを加速するために、Denoising Score Matching (DSM)を採用します。DSM は、Denoising Auto-Encoder (DAE) とScore Matching (SM) を結びつけるために提案されました。生成された対象系列を̂Yとすると、目的関数は次のようになります。
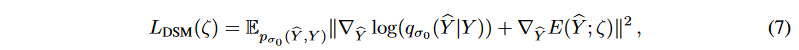
ここで、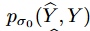 は破損サンプルとクリーンサンプルのペア ( ̂ Y , Y ) の結合密度、
は破損サンプルとクリーンサンプルのペア ( ̂ Y , Y ) の結合密度、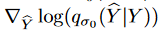 は単一のノイズカーネルのログ密度の導関数で、これは Parzen密度推定器:
は単一のノイズカーネルのログ密度の導関数で、これは Parzen密度推定器: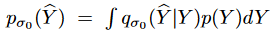 をスコアマッチで置き換えるためのもので、
をスコアマッチで置き換えるためのもので、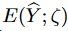 はエネルギー関数です。ガウスノイズの特殊な場合、
はエネルギー関数です。ガウスノイズの特殊な場合、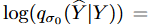
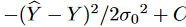 、 したがって、次のようになります。
、 したがって、次のようになります。
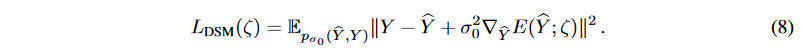
そして、ステップtにおける拡散対象系列について、次のように求めることができます。
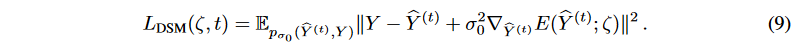
異なるレベルのノイズをスケーリングするために、単調に減少する一連の固定σ値{σ1, - - , σT | σt = 1 - ̄αt}が採用されます。従って、マルチスケールドDSMの目的関数は
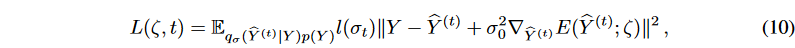
ここで、σ∈{σ1, - - , σT }、l(σt)=σtとします。式(10)では、σ0を設定することで、勾配が正しい大きさを持つことを保証することができます。生成時系列予測の設定では、生成されたサンプルは拡散プロセスを適用せずにテストされることになる。生成されたターゲット系列̂Yをさらにノイズ除去するために、シングルステップの勾配ノイズ除去ジャンプを適用します:
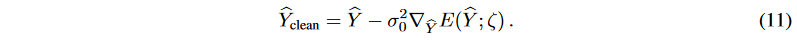
生成された結果は、真のターゲットよりも大きな分布空間を持つ傾向があり、式(11)のノイズ項は、生成されたターゲット系列と「クリーニング」されたターゲット系列との間のノイズを近似するものです。したがって、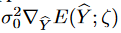 は、予測の推定不確かさとして扱うことができます。
は、予測の推定不確かさとして扱うことができます。
解釈のための潜在変数の切り離し
時系列予測モデルの解釈可能性は、多くの下流タスクにとって非常に重要です。生成モデルの潜在的な変数を分離することによって、解釈可能性だけでなく、予測の信頼性もさらに高めることができます 。
潜在変数Z = z1 , , zn を分離するために、複数の確率変数の間の依存関係を測定するための一般的なメトリックであるTotal Correlation (TC) を最小化することを試みます。
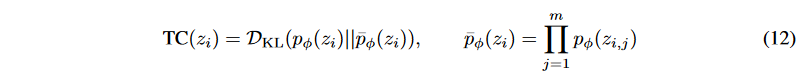
ここで、mは離散化する必要があるzi の因子の数を表します。潜在変数が有用な情報を保持している場合、一般にTCが低いほど、より良い離散化を意味します。しかし、潜在変数が意味のある信号を持たない場合、非常に低いTCを得ることもあります。BVAEの双方向構造により、このような問題にも無理なく対処することができます。Fig. 1に示すように、エンコーダとデコーダの両方で信号が拡散され、潜在変数に豊富なセマンティクスが集約されます。さらに、潜在的な不規則値の影響を緩和するために、 z1:n の相関の合計を平均化すると、BVAEのTCスコアに対する損失が求められるようになります:
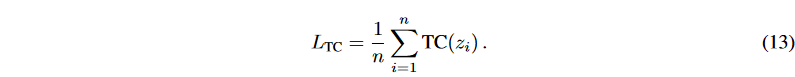
学習と予測
訓練の目的
不確実性の影響を低減するために、一般性を犠牲にすることなく、ノイズ除去ネットワークを備えた連成拡散を提案します。そして、潜在変数のTCを最小化することにより、生成モデルの潜在変数を切り離します。最後に、 いくつかのトレードオフ・パラメータを用いて損失を再構成します。式(10)、(11)、(13)を用いると、次のようになります。
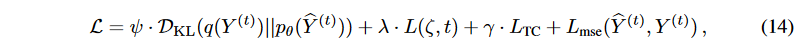
ここで、Lmse は、Y(t) と Y(t) の間の平均二乗誤差 (MSE) を計算します。上記の目的を最小化することで、生成モデルを適宜学習します。
アルゴリズム
アルゴリズム1は、式(14)の損失関数を用いた D3VAE の完全な学習手順を示しています。推論については、アルゴリズム2に記述されているように、入力系列Xが与えられた場合、ターゲット系列は、分布pθ から直接生成することができ、分布pφ から描かれた潜在状態を条件とします。

実験
設定
データセット
2つの合成データセットを生成します。
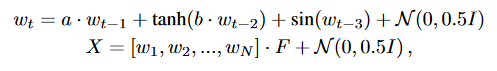
ここで、wt R2 と 0 wt,1 , wt,2 1 (t = 1, 2, 3), F R2×k [ 1, 1 ], k は次元数、N は時間点の数、a, b は2つの定数であることを示しています。D1 の生成には a = 0.9, b= 0.2, k = 20、D2 の生成には a = 0.5, b = 0.5, k = 40、D1 と D2 の両方には N = 800 と設定しました。
時空間ダイナミクスが多様な実世界のデータセットとして、交通量、電力を含む6 つのデータセットを選択しました。天気予報, 風 ( 風力発電) およびETT(ETTm1およびETTh1)。短い時系列シナリオの不確実性を強調するため、各データセットについて、開始点からサブセットをスライスし、スライスした各データセットが最大1000個の時間点を含むことを確認します。5%-Traffic、3%-Electricity、2%-Weather、2%-Wind、1%-ETTm1、5%-ETTh1 を得ました。すべてのデータセットは時系列に分割され、同じ訓練/検証/テストの比率、すなわち7:1:2が採用されている。
ベースライン
D3 VAEをGP(ガウスプロセス)ベースの手法1つ(GP-copula)、自動回帰手法2つ(DeepAR と TimeGrad )、VAEベースの手法4つ(vanilla VAE, NVAE, factor-VAE (f-VAE for short と β-TCVAE) と比較しました。
実装の詳細
input-lx -predict-ly ウィンドウを適用し、訓練セット、検証セット、テストセットをそれぞれ1タイムステップのストライドでロールし、この設定をすべてのデータセットで採用します。以下、デフォルトで多変量時系列の最後の次元がターゲット変数として選択されます。
Adam optimizerを使用し、初期学習率は5e-4です。バッチサイズは16、学習は最大20エポックに設定され、早期停止を備えます。もつれ解除係数の数は{4、8}から選択し、βt βは0.01から0.1の範囲に設定し、異なる拡散ステップT [100, 1000]を設定し、その後ωは0.1に設定されます。トレードオフのハイパーパラメータは、ETTについてはψ =0.05, λ = 0.1, γ = 0.001、その他についてはψ = 0.5, λ = 1.0, γ = 0.01 と設定されています。評価指標として、Continuous Ranked Probability Score (CRPS) とMean Squared Error (MSE)を使用しています。どちらの評価指標も、低いほど良いです。特にCRPSは2つの分布の類似性を評価するために用いられ、2つの分布が離散的である場合にはMean Absolute Error(MAE)と同等です。
主な結果
2つの異なる予測長、すなわち、ly 8, 16 (lx = ly ) を評価しました。
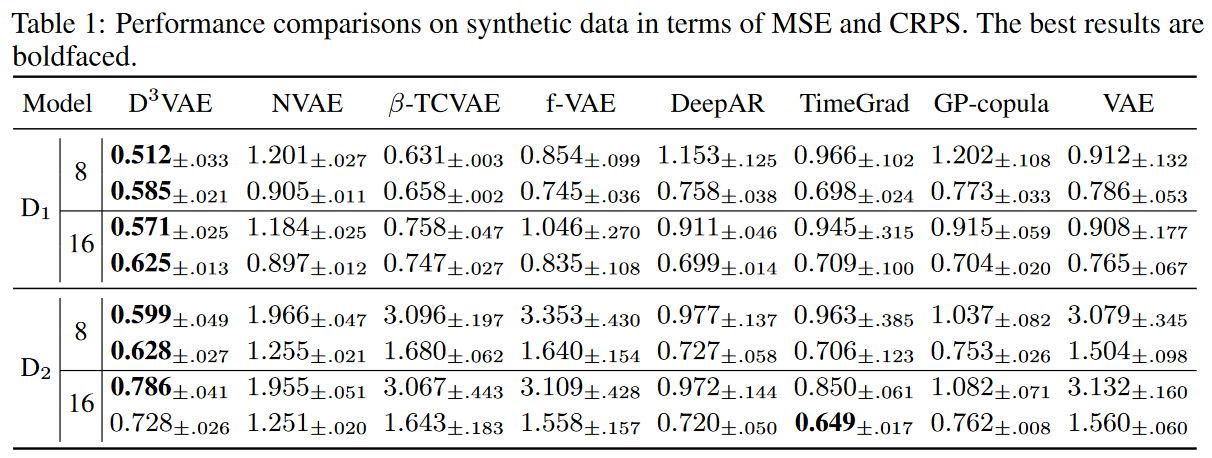
トイ・データセット
Table 1では、D3 VAEはほとんどの時間でSOTA性能を達成し、D2 では予測長16で競合CRPSを達成していることがわかります。また、D1 では VAE が VARと GP を上回りますが、D2 では VAR がより良い性能を達成しており、複雑な時間依存性の学習における VAR の優位性を示しています。
実世界のデータセット
実世界データに対する実験では、D3VAEは、Windデータセットにおいて予測長16を除き、一貫したSOTA性能を達成しました(Table 2)。特に、入力8-予測8の設定において、D3VAEは、交通量、電力、風力、ETTm1、ETTh1、天気のMSE削減率(90%, 71%, 48%, 43%, 40%, 28%)に顕著な改善をもたらすことができました。CRPS 削減については,D3VAE は input-8-predict-8 設定で 交通量 73%,風力 31%,電力 27%, input-16-predict-16 設定で 交通量 70%,電力 18%,天気 7%の削減を達成しました。
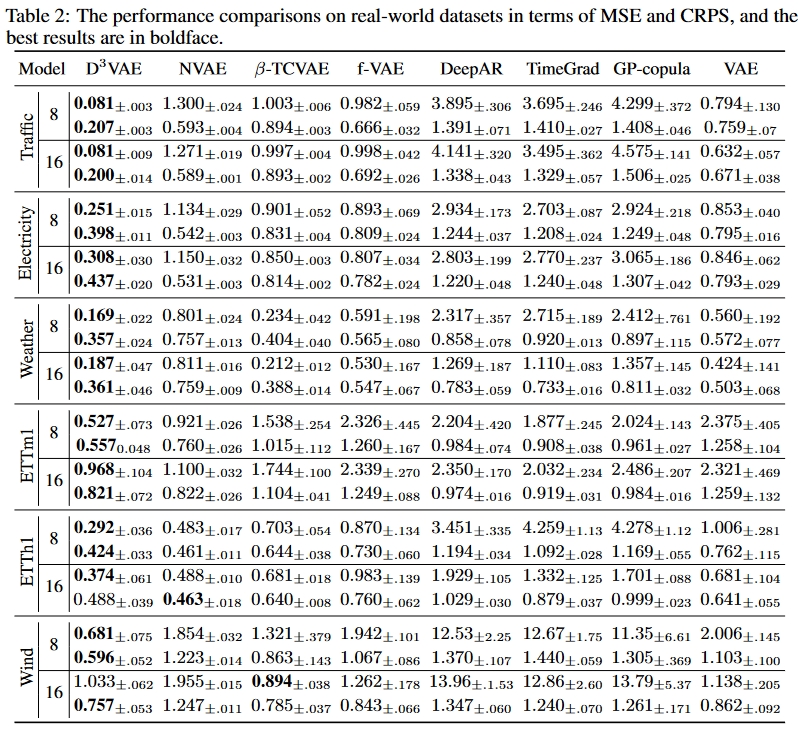
全体として、D3VAEは、上記の設定の中で平均して43%のMSE削減と23%のCRPS削減を獲得しています。
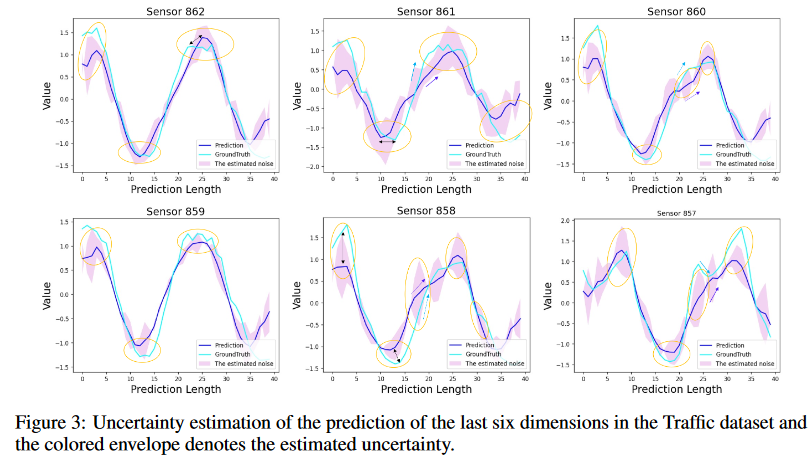
不確実性の推定
不確実性は,予測を行う際に結果系列のノイズを推定することで評価できます。スケールパラメータωによって、生成された分布空間を適宜調整することができます。
Fig. 3のショーケースは、最後の6次元がターゲット変数として扱われるTrafficデータセットにおいて、生成された系列の不確実性推定を実証しています。ノイズ推定が不確実性を効果的に定量化できることがわかります。例えば、極端な値に遭遇すると、推定される不確実性は急速に増大します。
もつれ解除の評価
時系列予測では、分離された要因を手作業でラベル付けすることは困難であるため、分離される要因としてZの異なる次元を取る: zi = [zi,1 , , zi,m ] (zi Z).インスタンスzi,j がクラスjに属するかどうかを識別する分類器を構築し、分類性能を評価することで分離の品質を評価することができる。また、相互情報量(MIG)を指標として採用し、より分かりやすくもつれ解除を評価します。
モデル解析
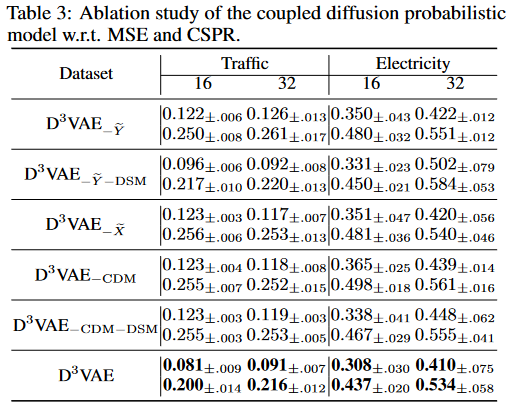
拡散とノイズ除去の結合ネットワークのアブレーション研究
拡散結合モデル(CDM)の有効性を評価するため、フルバージョンのD3VAEとその3つのバリエーション
i)D3VAE- ̃ Y、すなわちYを拡散しないD3VAE、
ii)D3VAE- ̃ X、すなわちXを拡散しないD3VAE、
iii)D3VAE-CDM(拡散しないD3VAE)
の比較を行います。また,D3VAE-⑰ Y -DSM,D3VAE-CDM-DSMと表記し,対象系列が拡散していない場合のDSM(Denoising score matching)の性能も報告します。切り分け研究は、input-16-predict-16とinput-32-predict-32のもと、TrafficとElectricityのデータセットで実施されています。Table 3から、拡散処理によって、入力またはターゲットを効果的に増強できることがわかります。また、ターゲットが拡散されない場合、ターゲットのノイズレベルが推定できないため、ノイズ除去ネットワークは欠陥があることがわかります。
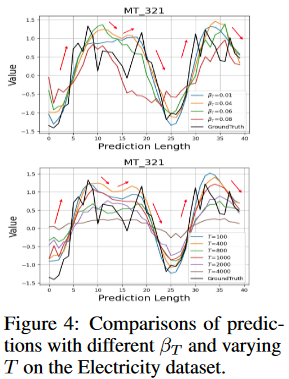
分散スケジュールβと拡散ステップの数T
情報量の多い時間的パターンを維持しながら不確実性の影響を軽減するためには、拡散の程度を適切に設定する必要があります。分散スケジュールが小さすぎたり、拡散ステップが不十分だったりすると、意味のない拡散処理になってしまいます。そうでない場合は、拡散が制御不能になる可能性があります。ここでは、分散スケジュールβと拡散ステップ数Tの影響を分析します。β1=0とし、βtの値を[0.01, 0.1]の範囲で変化させ、Tは100から4000の範囲とした。Fig. 4に示すように、適切なβとTを採用することで、予測性能が向上することが確認できます。
議論
生成時系列予報のためのサンプリング
ランジュバン力学は、エネルギーベースモデル(EBM)のサンプリングに広く応用されています。
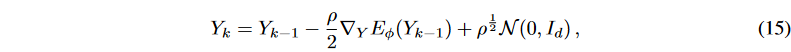
ここで、k∈{0, - - , K}、Kはサンプリングステップ数を表し、ρは定数です。Kとρを適切に設定することで、高品質のサンプルを生成することができます。ランジュバン力学は、コンピュータビジョンや自然言語処理のアプリケーションにうまく適用されています。
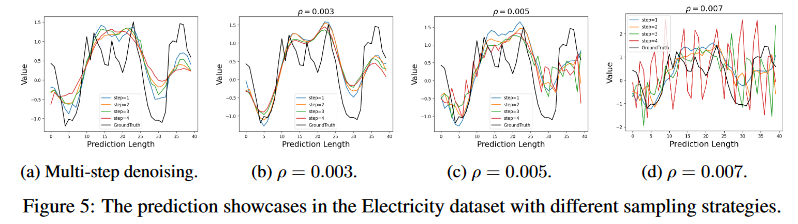
本研究では、ターゲット系列を生成するために、シングルステップの勾配ノイズ除去ジャンプを採用します。実施した実験により、このようなシングルステップサンプリングの有効性が実証されました。時系列予測のさらなる性能向上のために、より多くのサンプリングステップを取る価値があるかどうかを調査するために、追加の実証研究を実施します。Fig. 5では、異なるサンプリング戦略の下での予測結果を示しています。ランジュビンダイナミクスにおける加法性ノイズを省くために、D3VAEの多段階ノイズ除去を採用して対象系列を生成し、生成結果をFig. 5aにプロットします。次に、標準的なランジュバンダイナミクスで、ノイズ除去の代わりに生成手順を実装し、生成されたターゲット系列を異なるρで比較します(Fig. 5b~5d参照)。生成的時系列予測において、より多くのサンプリングステップが予測性能の向上に役立たない可能性があることが観察できます(Fig. 5a)。さらに、サンプリングステップを増やすと、計算量が多くなることが予想されます。一方、ランジュバンダイナミクスの異なる構成(ρを変化させる)は、時系列予測に不可欠な利点をもたらしません(Fig. 5b〜5d)。
限界
連成拡散確率モデルでは、時系列のアレアトール的な不確実性は低減できるものの、入力とターゲットの分布を模倣するために、時系列に新たなバイアスが導入されることになります。しかし、入力に偏りが生じると生成される出力にも偏りが生じるというVAEに共通する問題があるため[、このモデルが異なる時系列タスクにスムーズに適用できるように、拡散ステップと分散スケジュールを慎重に選択する必要があります。提案されたモデルは一般的な時系列予測のために考案されたものであり、不正な応用など社会的に負の影響を与える可能性を避けるために、適切に使用する必要があります。
時系列予測分析において、潜在変数のもつれ解除は、より信頼性の高い予測を解釈するために非常に重要です。生成的時系列予測では、もつれた要因の事前知識がないため、教師なし離散化学習のみが可能であり、これは時系列に対して理論的に実現可能であることが証明されているにもかかわらず、もつれ解除のボーダーレスな応用とより良いパフォーマンスのために、今後、時系列の因子をどのようにラベル付けするのかを探求する価値があります。さらに、時系列データは一意であるため、時系列生成タスクに対して、より生成的でサンプリング的な方法を探求することも有望な方向性です。
まとめ
本研究では、双方向のVAEをバックボーンとする生成モデルを提案しています。さらに一般性を高めるために、時系列予測のための連成拡散確率モデルを考案します。そして、予測精度を保証するために、スケーリングされたノイズ除去ネットワークを開発しました。その後、モデルの解釈性を高めるために、潜在的な変数をさらに分離しました。合成データと実世界のデータを用いた広範な実験により、提案する生成モデルが、既存の競合生成モデルと比較してSOTA性能を達成することを検証しました。






この記事に関するカテゴリー






