
季節性変動とトレンドが混在しても精度よく予測できる時系列モデルLaST
3つの要点
✔️ NeurIPS 2022採択論文です。季節性(周期的)変動とトレンドなど複数の変動傾向を含む時系列データの予測モデルLaSTを提案
✔️ 変分推論のロジックを用いて、複数の変動傾向を分離して、それぞれの変動を特定
✔️ 実世界データを用いて性能を検証したところ、従来の7つのモデルに対して優れた結果を確認
Learning Latent Seasonal-Trend Representations for Time Series Forecasting
written by Zhiyuan Wang, Xovee Xu, Weifeng Zhang, Goce Trajcevski, Ting Zhong, Fan Zhou
(Submitted on 30 Dec 2022)
Comments: NeurIPS 2022
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
概要
NeurIPS 2022採択論文です。時系列の予測について、最近では、様々な深層学習技術(RNNやTransformerなど)を逐次モデルに取り入れることで改善が試みられています。しかし、時系列はしばしば複雑に絡み合った複数の要素から構成されているため、明確なパターンを抽出することはまだ困難です。コンピュータビジョンや古典的な時系列分解における分離変分オートエンコーダの成功に刺激され、この論文では時系列の季節性成分(周期的変動)やトレンド成分を描写するいくつかの表現を推論することをもくろんでいます。この目標を達成するために、変分推論(変分ベイズ法)に基づき、潜在空間における季節性とトレンド表現を分離することを目的としたLaSTを提案します。さらに,LaSTは潜在空間における季節性とトレンド表現を,それ自身と入力再構成の観点から監督・分離し,一連の補助的な目的を導入します。広範な実験により、LaSTは時系列予測課題において、最先端の表現学習モデルやエンドツーエンド予測モデルに対して最先端の性能を達成することが証明できました。
注)変分ベイズ法については、PRML(パターン認識と機械学習)第10章などを参照のこと
はじめに
時系列データのユビキタス性と重要性のため、最近、研究者の努力を集め、時系列予測を改善する無数の深層学習予測モデルが開発されています。RNNやTransformerなどの高度な技術に基づくこれらの手法は、通常、信号のそれぞれの瞬間を表す潜在的な表現を学習し、予測器によって予測結果を導き出し、予測タスクで大きな進歩を達成しています。
しかし、これらのモデルは、特に表現に制約のない教師付きエンドツーエンドアーキテクチャにおいて、時間的パターン(例えば、季節性、トレンド、レベル)に関連する正確で明確な情報を抽出することが困難です。そのため、変分推論を時系列モデリングに適用する取り組みが行われ、確率的形式を持つ潜在的表現の改良されたガイダンスが下流の時系列タスクに有益であることが証明されています。しかし、時系列データ中に様々な構成要素が複雑に共進化している場合、単一の表現で解析すると、ニューラルネットワークの高度なもつれにより、表面的な変数やモデルの再利用性、解釈性の欠如につながります。このように、既存の高次元表現によるアプローチは、効率と有効性を提供する一方で、情報の活用と説明可能性を犠牲にし、さらにオーバーフィッティングや性能低下をもたらす可能性があるのです。
上記の制限に対処し、新しい分離型時系列学習フレームワークを模索するために、この論文では分解戦略のアイデアを活用して、時系列データをいくつかのコンポーネントに分割し、それぞれが基本的なパターンカテゴリを捕らえるようにします。分解は分析プロセスを支援し、人間の直感とより一致する基本的な洞察を明らかにします。この洞察に基づき、異なる時系列の特性(ここでは季節性とトレンド)に対応するいくつかの潜在的な表現を取ることし、そこから、シーケンスをこれらの特性の合計として定式化することによって結果を予測するようにしました。この潜在表現は、入力シーケンスに対する十分な情報を持ちながら、特徴のもつれを起こしやすいモデルを避けるために、可能な限り独立であるべきです。
そこで、この論文では時系列予測のための潜在的な季節性-トレンド表現を学習する新しいフレームワークLaSTを提案します。LaSTはエンコーダ・デコーダのアーキテクチャを利用し、変分推論理論に従って、時系列の季節性とトレンドを表現する2つの離散化された潜在的な表現を学習します。(1)入力再構成から、生の時系列と市販の測定方法から容易に得られる固有の季節・トレンドパターンを分離し、それに応じて一連の補助目標を設計する。(2)表現自体から、入力データとそれぞれの表現の間の整合性を保証する前提で、季節・トレンド表現間の相互情報(MI)を最小化する。
この論文の主な貢献は以下の3点です。
- 変分推論と情報理論に基づき、季節性-トレンド表現の学習と分離のメカニズムを設計し、その有効性と既存のベースラインに対する優位性を時系列予測タスクで実践的に実証する。
- 潜在的な季節-トレンド表現学習フレームワークであるLaSTを提案する。これは、入力を分離された季節性-トレンド表現として符号化し、季節とトレンドを別々に再構成する実用的なアプローチを提供し、カオスを回避する。
- MI項をペナルティとして導入し、その最適化について新しい扱いやすい下界と上界を提示する。下界は、従来のMINEアプローチにおける偏った勾配の問題を改善し、情報豊かな表現を保証する。上界は、季節-トレンド表現の重なりをさらに減らすための実現可能性を提供する。
潜在的な季節トレンドの表現学習のフレームワーク
LaSTでは季節性とトレンドの特徴を用いて解離学習を行いますが、このフレームワークは解離すべき成分が2つ以上ある状況に適応するようにも容易に拡張できます。
問題定義
X(i) 1:T = {x(i) 1 , x(i) 2 , - - , x(i) t , - - , x(i) T }と表されるN i.i.dシーケンスからなる時系列データセットDを考え、ここでi∈ {1, 2, ... ... }は、時刻の瞬間tの現在の観測値(例えば、価格や降水量)を表す単変量または多変量値であり、各x(i) tは時間瞬間tにおける現在の観測値(例えば、価格や降雨量)を表す単変量または多変量値です。将来のシーケンス Y = ˆ XT +1:T +τ を予測するのに適した表現 Z1:T を出力するモデルを導出することを目的とします。以下、曖昧さがない場合は上付き文字と下付き文字1:T を省略します。観測値 X と潜在表現 Z を持つ未来 Y との間の尤度を推論するモデルは、以下のように定式化できます。
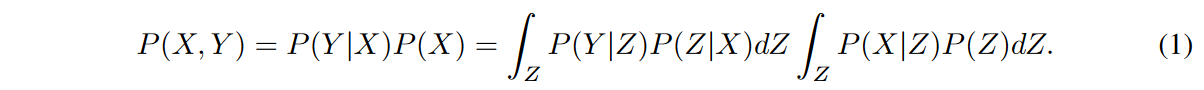
変分推論の観点から、尤度P(X|Z)は事後分布Qφ(Z|X)によって算出され、以下の証拠下限(ELBO : evidence lower bound)によって最大化されます。
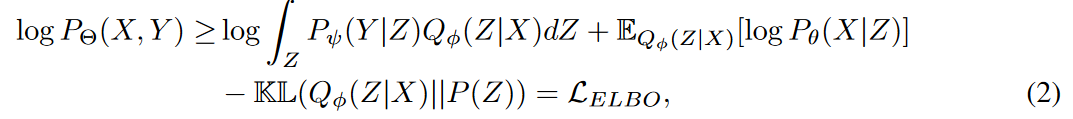
ここで、Θはψ、φ、θから構成され、学習されたパラメータを示します。
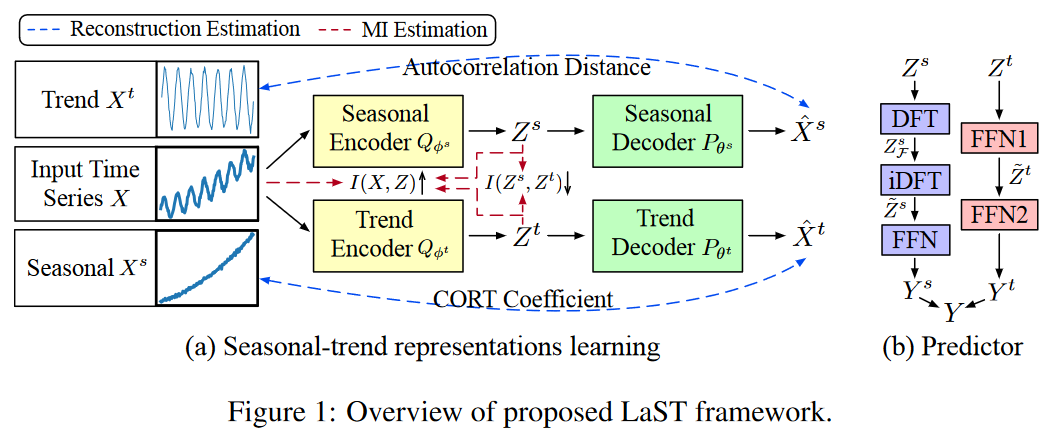
しかし、これはもつれの問題に直面し、複雑な時間パターンを明確に抽出することができません。そこで、この限界を改善するため、LaSTに分解戦略を組み込み、季節性とトレンドのダイナミクスを表現するための2つの分離された表現を学習させます。具体的には、時間信号XとYを季節性成分とトレンド成分の和、すなわち、X = Xs + Xtとして定式化します。したがって、潜在表現Zは、互いに独立であると仮定して、ZsとZtに分解され、すなわち、P (Z) = P (Zs)P (Zt)となります。Fig. 1はLaSTのフレームワークの2つの部分を示しています:(a)季節性-トレンド表現を分離するための表現学習(別々の再構成とMI制約)、および(b)学習した表現に基づく予測です。
・定理1
この分解戦略により、式(2)(すなわちELBO)は自然に次のような因数分解された形になります。
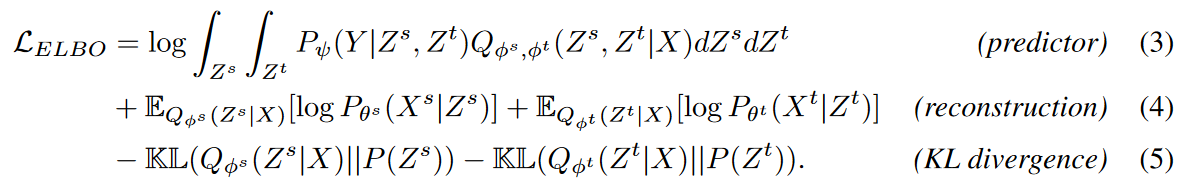
ELBOは、式(3)、(4)、(5)の3つの主要なユニットに分割されます。予測器は予測を行い、精度(例えば、L1またはL2損失)を測定し、再構成とKLダイバージェンスは学習された表現を改善することを目的とした正則化項として提供されます。以下、3つのユニットについて説明します。
・予測器
この予測変数は、![]() と
と ![]() という2つの独立した部分の合計とみなすことができます。ここでは、季節性-トレンド表現を利用するために、それぞれの特徴を組み合わせた2つの特化したアプローチを紹介します。季節潜在表現Zs∈RT ×dが与えられると、季節性予測器はまず季節性周波数を検出するために離散フーリエ変換(DFT)アルゴリズムを用います。すなわち、Zs F = DFT(Zs) ∈ CF ×d, ここでF = ⌊T +1 2⌋はナイキストの定理に起因します。 次に、周波数を時間領域に逆戻りして、未来部分まで表現を拡張する、すなわち、̃ Zs = iDFT(Zs F ) ∈ Rτ×d とします。Ztが与えられると、トレンド予測器はフィードフォワードネットワーク(FFN)f : T → τを提供して、予測可能な表現̃Zt∈Rτ×d を生成します。 Zsと̃ ZtをそれぞれY sとY tに写像し、それらの和によって予測結果Yを得るために、2つのFFNで予測器を終了します。
という2つの独立した部分の合計とみなすことができます。ここでは、季節性-トレンド表現を利用するために、それぞれの特徴を組み合わせた2つの特化したアプローチを紹介します。季節潜在表現Zs∈RT ×dが与えられると、季節性予測器はまず季節性周波数を検出するために離散フーリエ変換(DFT)アルゴリズムを用います。すなわち、Zs F = DFT(Zs) ∈ CF ×d, ここでF = ⌊T +1 2⌋はナイキストの定理に起因します。 次に、周波数を時間領域に逆戻りして、未来部分まで表現を拡張する、すなわち、̃ Zs = iDFT(Zs F ) ∈ Rτ×d とします。Ztが与えられると、トレンド予測器はフィードフォワードネットワーク(FFN)f : T → τを提供して、予測可能な表現̃Zt∈Rτ×d を生成します。 Zsと̃ ZtをそれぞれY sとY tに写像し、それらの和によって予測結果Yを得るために、2つのFFNで予測器を終了します。
・再構成とKLダイバージェンス
これら2つの項のうち、KLダイバージェンスは事前仮定を用いたモンテカルロ・サンプリングによって容易に推定することができます。ここでは,効率のために,両者の事前分布が N (0, I) に従うという,広く使われている設定を用います。再構成項については,Xs と Xt が未知であるため,直接測定することはできません。また、この2つの項を![]() に統合すると、デコーダがあらゆる表現から複雑な時系列を再構成しやすくなり、カオスになってしまいます。
に統合すると、デコーダがあらゆる表現から複雑な時系列を再構成しやすくなり、カオスになってしまいます。
・定理2
ガウス分布の仮定により、再構成損失LrecはXsとXtを活用することなく推定でき、式(4)は以下の式に置き換えることができます。
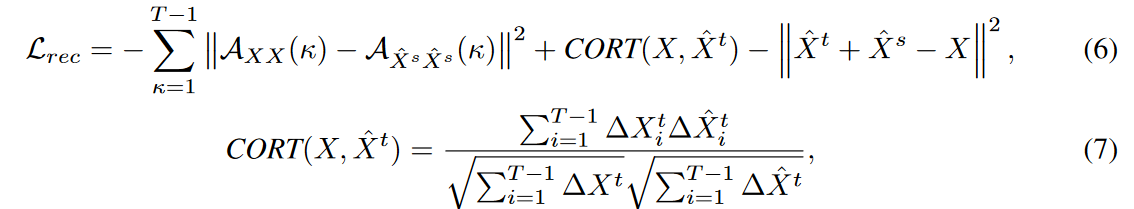
ここで、![]() は遅れ値κの自己相関係数,CORT(X, ˆ Xt) は時間相関係数,ΔXi = Xi - Xi-1 は第一階差です。
は遅れ値κの自己相関係数,CORT(X, ˆ Xt) は時間相関係数,ΔXi = Xi - Xi-1 は第一階差です。
式(6)によれば、再構成損失を推定することができ、逆に離散化表現学習を監督するために用いることができます。しかし、この枠組みにはまだいくつかの欠点があることがわかりました。
(1)KL発散は事後と事前との距離を縮める傾向がある。モデリング能力が十分でない場合、変分推論とデータ適合を犠牲にする傾向がある。また、事後推定は入力に対してほとんど情報を持たなくなり、観測と無関係な予測になる可能性がある。
(2)季節性-トレンド表現の非連接性は、分離再構成によって間接的に後押しされるが、そこでは表現自体に直接的な制約を課す必要がある。
相互情報正則化項を追加導入することで、これらの制約を緩和します。具体的には、Zs, Zt, X間の相互情報を増加させ、発散狭窄問題を緩和し、ZsとZt間の相互情報を減少させ、それらの表現をさらに分離させます。
LaSTの最大化目的は以下のようになります。
![]()
ここで、I(-, -)は2つの表現間の相互情報量を表します。しかし、この二つの相互情報項は追跡不可能です。
最適化のための相互情報量境界
ここで、式(8)のI(X,Zs)とI(X,Zt)を最大化し、I(Zs,Zt)を最小化する追跡可能な相互情報量を取り上げ、モデル最適化の下界と上界を示します。
・I(X, Zs)またはI(X, Zt)の下界
MIの下界を探索する先行アプローチのうち、例えばMINEは、ジョイント分布とマージナル間のKLダイバージェンスを用い、エネルギーベースの変分ファミリーを定義し、柔軟でスケーラブルな下界を達成するものです。これは、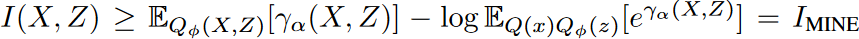 と定式化でき 、ここでγαはパラメータαの学習正規化クリティックとすることが出来るが、パラメトリック対数項により偏った勾配となります。対数関数をその正接族で置き換え、上記の偏った境界を改善します。
と定式化でき 、ここでγαはパラメータαの学習正規化クリティックとすることが出来るが、パラメトリック対数項により偏った勾配となります。対数関数をその正接族で置き換え、上記の偏った境界を改善します。
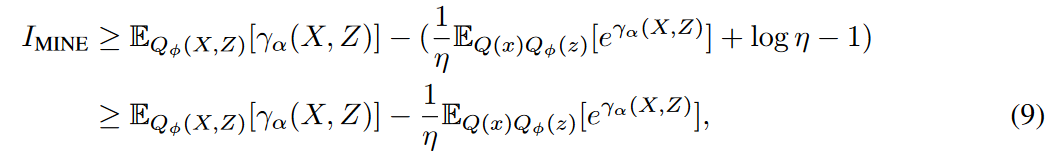
ここで、ηは異なる正接を表します。最初の不等式は、凹型の負対数関数に依存しています。曲線上の値は正接上の値に対する上界であり、接点が独立変数、すなわち ![]() の真の値と重なるとき、タイトとなります。正接と独立変数の距離が近いほど下界は大きくなります。そこで、できるだけ大きな下界を得るために独立変数を推定する変分項
の真の値と重なるとき、タイトとなります。正接と独立変数の距離が近いほど下界は大きくなります。そこで、できるだけ大きな下界を得るために独立変数を推定する変分項![]() をηとします。この不等式は
をηとします。この不等式は ![]() のときのみ成立し、γαは変数の組(X、Z)が結合分布からサンプリングされているかマージナルからサンプリングされているかを識別することができることを意味します。MINEと同様に、この整合性の問題は、ニューラルネットワークの普遍的な近似定理によって対処することができます。したがって、式(9)は、不偏勾配を持つI(X,Z)に対して柔軟でスケーラブルな下界を提供します。
のときのみ成立し、γαは変数の組(X、Z)が結合分布からサンプリングされているかマージナルからサンプリングされているかを識別することができることを意味します。MINEと同様に、この整合性の問題は、ニューラルネットワークの普遍的な近似定理によって対処することができます。したがって、式(9)は、不偏勾配を持つI(X,Z)に対して柔軟でスケーラブルな下界を提供します。
・I(Zs,Zt)の上界
相互情報量の追跡可能な上界を探索する努力は過去にあまり見られません。既存の上界は、既知の確率的密度を持つ結合分布または条件分布(ここではQ(Zs|Zt)、Q(Zt|Zs)またはQ(Zs、Zt))により追跡可能です。しかし, これらの分布は解釈可能性に欠け、 直接モデル化することが困難であるため,、上記の上界を追跡不可能に推定することになります。
未知の確率的密度を直接推定することを避けるため、Q(Zs, Zt)に対してエネルギーに基づく変分ファミリーを導入し、式(9)のような正規化したクリティックγβ(Zs, Zt)を用いて追跡可能な上界を設定します。具体的には、クリティックγβを上界ICLUB に組み込み、I(Zs, Zt)の追跡可能な季節性-トレンド上界(STUB)を得、次のように定義されます。
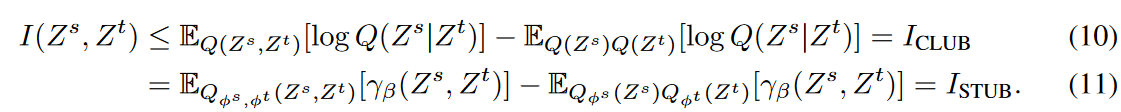
式(10)の不等式はZsとZtが独立変数の組である場合のみタイトです。これはまさにISTUBの十分条件であり、MIと式(11)はともに独立な状況においてゼロとなり、季節性-トレンドもつれほぐし最適目的であるからである。クリティックγβは、γαと同様に、識別の役割を持つが、逆のスコアを提供し、MIを最小に制約します。しかし、式(11)はパラメータβの学習中に負の値をとることがあり、その結果、MIの上限が不正になることがあります。この問題を緩和するため、モデル最適化を支援するために、ISTUBの負の部分をL2損失するペナルティ項 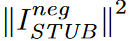 を追加で導入します。
を追加で導入します。
実験
以下、LaSTと最新のベースラインを比較した広範な実験評価の結果を示し、切り分け研究および季節性-トレンド表現の可視化とともに、一連の実証結果を示します。
設定
・データセットとベースライン
時系列予測アプリケーションの主流である以下の4つのカテゴリからなる7つの実世界ベンチマークデータセットに対して実験を行いました。
(1) ETT .Electricity Transformer Temperatureは、目標値「油温」と6つの「電力負荷」特徴量からなり、1時間ごと(すなわちETTh1とETTh2)、15分ごと(すなわちETTm1とETTm2)に2年間記録されている。
(2) Electricityは、UCI Machine Learning Repository から、前処理されたもので、2012年から2014年の321クライアントの1時間ごとの電力消費量をkWh単位で収録したものである。
(3) Exchange には、1990年から2016年までの8カ国の日次為替レートが格納されています。
(4) Weather は 21 の気象指標(気温や湿度など)を含み、2020 年に 10 分ごとに記録される。
2つのカテゴリーからなる時系列モデリングと予測タスクに関する最新の手法とLaSTを比較する:
(1)COST, TS2Vec, TNC を含む表現学習技術、
(2)VAE-GRU, Autoformer, Informer, TCN などエンドツーエンド予測モデル、などである。
・評価設定
先行研究に従い、単変量と多変量の両方の予測設定でモデルを実行しました。多変量予測では、LaSTはデータセット中のすべての変数を受け入れ、予測します。単変量予測では、LaSTは各データセットの特定の特徴のみを考慮します。すべてのデータセットについて、標準的な正規化を採用し、入力長T = 201とします。データセットの分割については、すべてのデータセットについて6:2:2の割合で時系列にトレーニングセット、検証セット、テストセットに分類する標準的なプロトコルに従います。
・実装詳細
LaSTのネットワーク構造としては、フィードフォワードネットワーク(FFN)として単層完全連結ネットワークを用い、これを事後、再構成、予測器のモデリングに適用します。また、MI境界推定における評論家γには2層MLPを採用しました。季節性表現とトレンド表現の次元は一致しています。単変量予測では32、他のデータセットでの多変量予測では128としました。MAE損失は予測器から得られる予測値を測定するために用いられます。学習戦略にはAdamオプティマイザーを使用し、学習プロセスは10エポック以内に早期停止されます。学習率は10-3で初期化し、エポック毎に0.95の重みで減衰させます。
性能比較とモデル解析
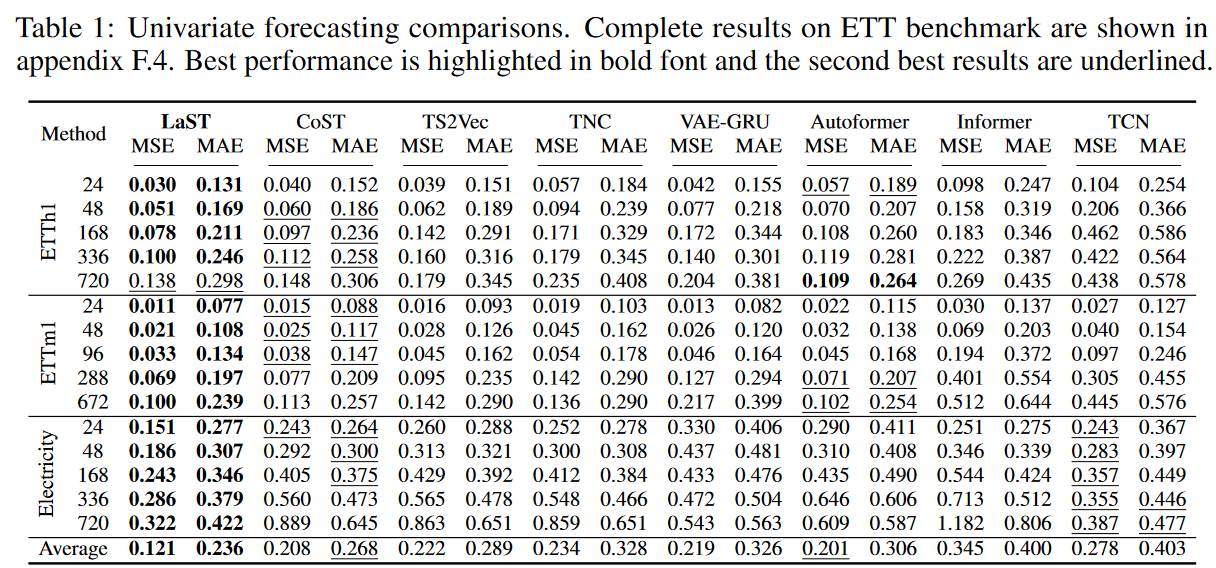
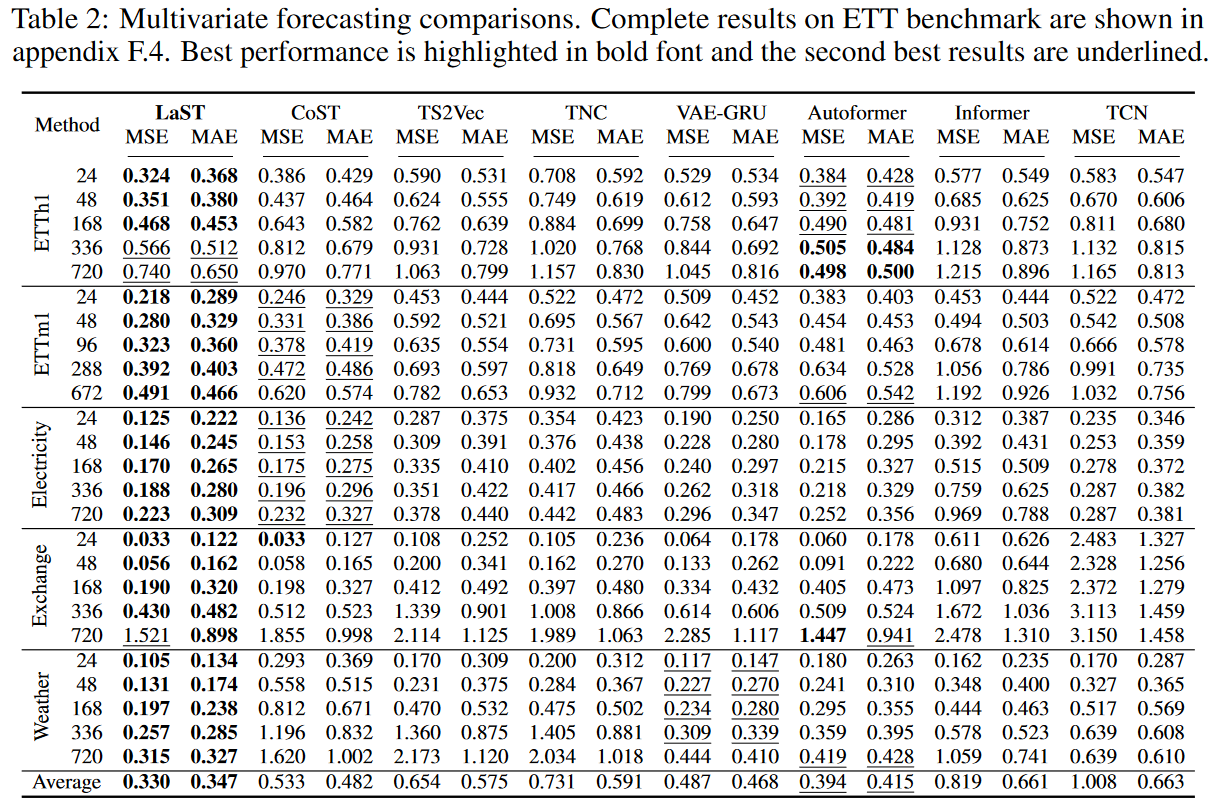
・効果
Table 1およびTable 2は、それぞれ単変量および多変量予測の結果をまとめたものです。LaSTは実世界の5つのデータセットにおいて、先進的な表現ベースラインに対して最先端の性能を達成しました。MSEとMAEの相対的な向上は、最良の表現学習法CoSTに対して25.6%と22.1%、最良のエンドツーエンドモデルAutoformerに対して22.0%と18.9%です。Autoformerが1時間毎のETTデータセットの長期予測においてより良いパフォーマンスを達成していることに注目し、その理由は2つあると考えています:
(1)Transformerベースのモデルは本質的に長距離依存性を確立し、それは長期シーケンス予測において重要な役割を果たす
(2)固定カーネルサイズでの平均プーリングによる単純分解を採用しており、それは時間毎にETTという周期性の強いデータセットに対してより適切である
この現象は長期予測には有益であるが、ローカルコンテキストへの感度が制限され、ボーナスは他のデータセットに大きな影響を与えません。ベースラインと比較して、LaSTは季節性とトレンドのパターンを解離した表現で適応的に抽出するので、入り組んだ時系列に適用できます。
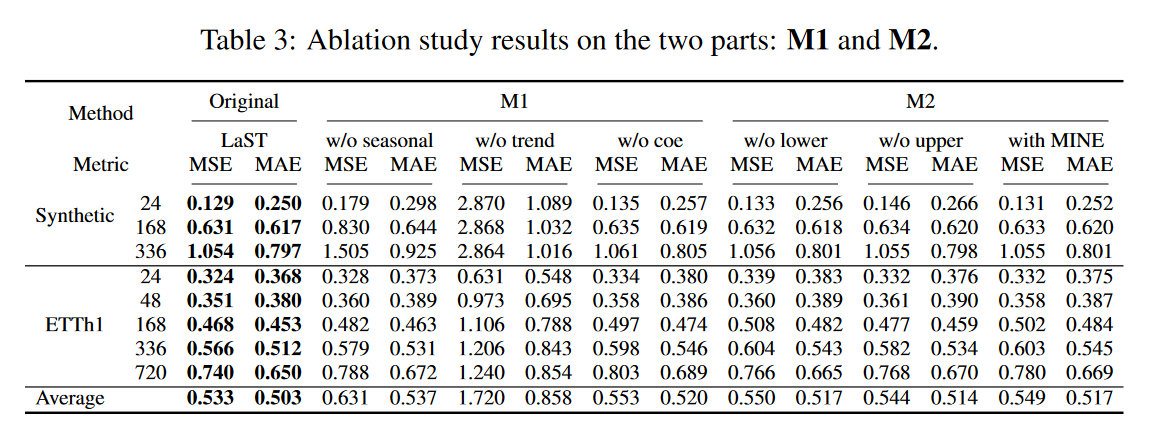
・切り分け
合成データセットとETTh1において、LaSTの各メカニズムがもたらす性能上の利点を調査しました。結果はTable 3に示す通りであり、2つのグループから構成されます。M1は、季節性-トレンド表現学習フレームワークのメカニズムを検証します。この中で、"w/o seasonal" と "w/o trend" はそれぞれ季節成分とトレンド成分を除いたLaSTを示し、"w/o coe" は再構成損失を推定する際に自己相関とCORT係数を除いたLaSTを示しています。M2はMIの導入と推定を判断し、"w/o lower" と "w/o upper" はそれぞれ正則化項におけるMIの下限と上限の削除を、"with MINE" は下限をMINEに置き換えることを表します。その結果、全てのメカニズムが予測タスクのパフォーマンスを向上させることがわかりました。トレンド成分を除去した場合、品質が大きく低下することがわかります。その理由は、季節予測はiDFTアルゴリズムに由来し、それは本質的に過去の観測を周期的に繰り返すものであるからです。しかし、季節パターンを捕らえ、完全なLaSTでトレンド成分をアシストすることで、特に長期設定と強い周期的合成データセットにおいて優位性をもたらすことができます。さらに、偏った正則化項MINEを用いた場合、性能は不安定になり、時にはMI下限を用いないLaSTよりも悪くなるが、非バイアス下限(式(9)参照)は継続的にLaSTを上回ることが確認されました。
・表現解きほぐし
Fig. 2は、tSNEの手法を用いた季節トレンドの表現を可視化したものです。また、比較としてAutoformerデコーダの最終層における埋め込みも可視化しました。同じ色の点は、LaSTではより明確で緊密なクラスタリングがなされているのに対し、分解機構なし("w/o dec "は2つの分解機構(自己相関とCORT係数、およびMIの上限)の除去を示す)には混在していることがわかります。
また、単純な移動平均ブロックを用いたAutofomerは、時系列の観点からは満足のいく分解を達成しているが、その表現はまだもつれやすいということが注目されます。これらの結果は、(1)季節性-トレンド表現を分離して学習することは容易ではないこと、(2)提案する分解機構は、潜在空間において、特定の時間パターンに注目した季節性-トレンド表現を分離することに成功していることを示唆しています。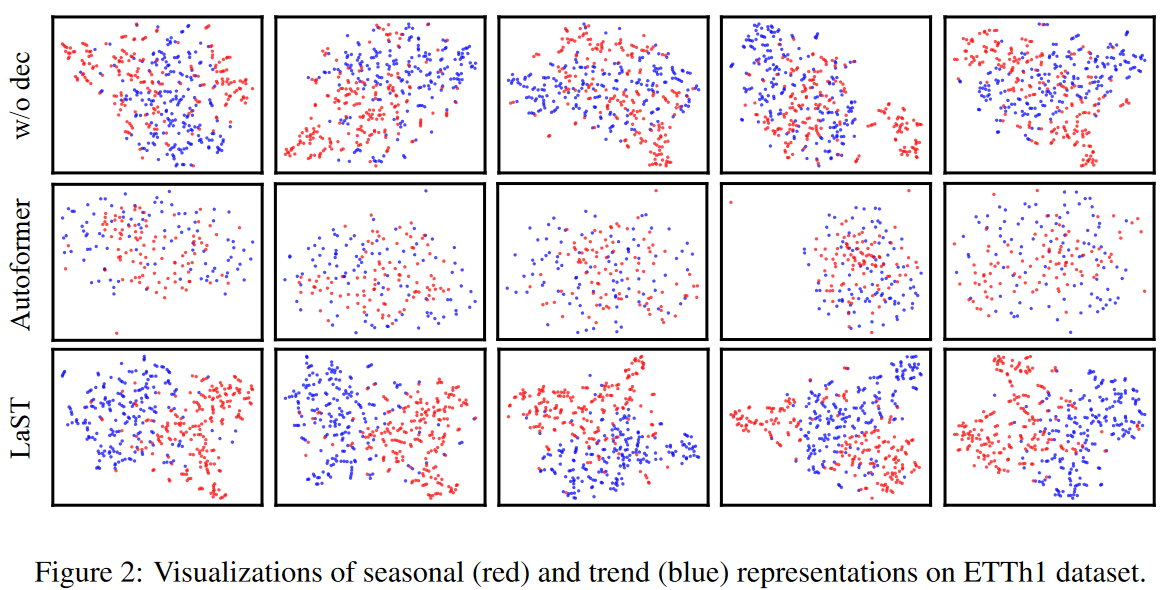
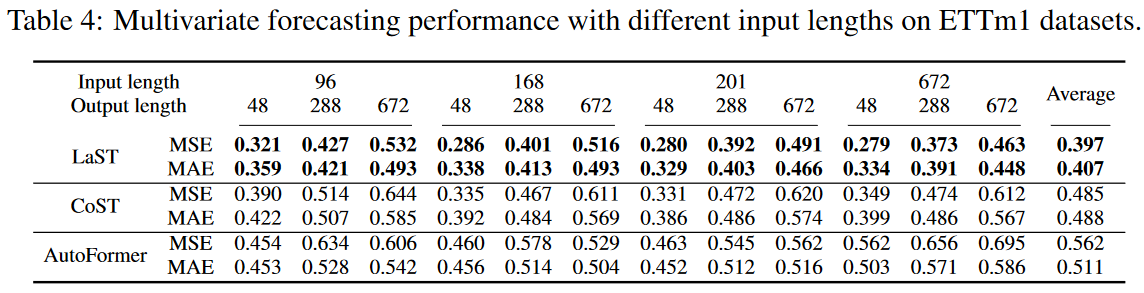
・入力設定
さらに、感度を検証するためにハイパーパラメータの入力長の影響を調べ、Table 4にその結果を示します。長いルックバックウィンドウは、特に長期予測において性能を向上させるが、他のものは性能低下さえあります。これは、LaSTが過去の情報を効果的に利用してパターンを理解し、予測を行うことができることを検証しています。
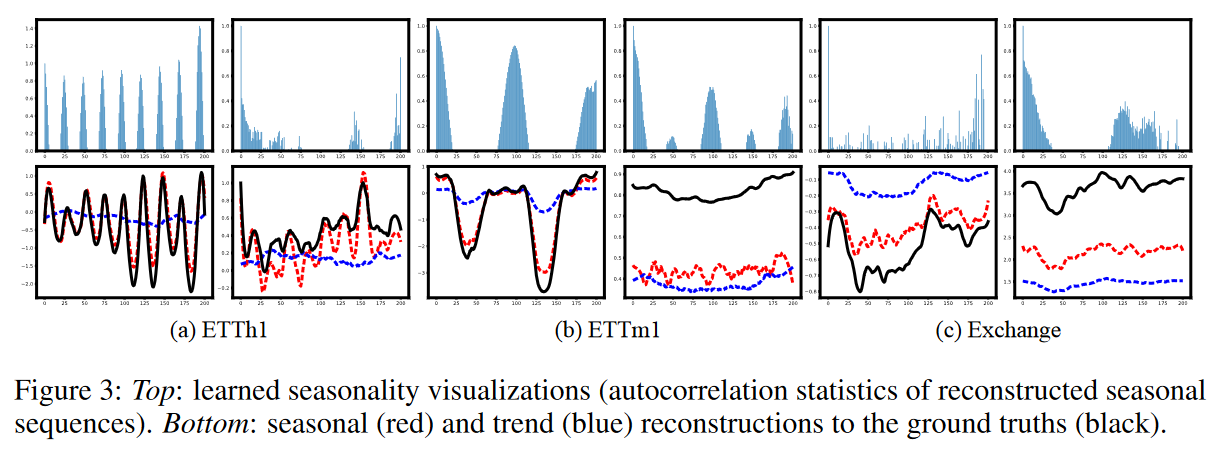
・ケーススタディから
さらに、抽出された季節性と傾向を具体的な事例で可視化することにより、LaSTの検証を行いました。Fig. 3に示すように、LaSTは実世界のデータセットにおいて季節パターンを捉えることができます。例えば、1時間足と15分足のETTデータセットでは、日中の強い周期が示されています。Exchangeデータセットでは周期が明確でないにもかかわらず、LaSTは日次データでいくつかの長期的な周期を提供しています。さらに、トレンド成分と季節成分は、それぞれの観点で正確に元の系列を復元しており、LaSTが複雑な時系列に対して実行可能な分離された表現を生成できることを裏付けています。
先行研究
時系列予測のための深層学習手法の多くは、エンドツーエンドのアーキテクチャとして設計されています。様々な基本的な技術(例えば、残差構造、自己回帰ネットワーク、畳み込み )が、時間依存性とパターンを反映する表現力のある非線形隠れ状態と埋め込みを生成するために利用されています。また、Transformer構造を時系列予測タスクに適用する研究群もあり、それらはシーケンス全体の関係を発見し、重要なタイムポイントに焦点を当てることを目的としています。ディープラーニングの手法は、ARIMAやVARなどの古典的なアルゴリズムと比較して優れたパフォーマンスを達成し、複数のアプリケーションで普及しています。
柔軟な表現を学習することは、多くの研究により、下流のタスクに有益であることが実証されています。時系列表現領域では、変分推論を用いた初期の手法が、生信号を再構成するエンコーダと対応するデコーダを共同で学習し、近似的な潜在的表現を学習します。最近の取り組みでは、コピュラや正規化フローなどの技術を用い、より複雑で柔軟な分布を確立することにより、これらの変分法を改良しています。別の研究グループは、拡張された時系列から不変の表現を得るために、急成長している対比学習を利用し、これは再構成プロセスを避け、追加の監視なしに表現を向上させるものです。
時系列分解は,複雑な時系列をいくつかの要素に分割し,時間的パターンと解釈可能性を得る古典的な手法です。最近の研究では、機械学習や深層学習のアプローチを適用して、大規模なデータセットに対して分解を頑健かつ効率的に実現しています。また、分解を援用した予測に取り組む研究成果もあります。例えば、Autoformer は、平均プーリングによって時系列を季節性・トレンドの部分に分解し、より良い関係発見のためにTransformer を強化する自己相関メカニズムを導入しています。CoST は信号を周波数領域と時間領域でそれぞれ季節性とトレンド表現に符号化し、それらの学習を監督するために対比学習を導入します。これらの手法は本論文とは異なり、単純な平均プーリング分解機構を利用しているため、互換性のない周期的仮定を提供したり、異なる領域での処理により直感的に表現を切り離したりすることができます。一方、LaSTは、潜在空間において、分離された表現が持つ季節性や傾向を適応的に抽出し、確率的な観点から分離を促進します。
まとめ
本論文は、時系列の効果的な予測のために、潜在空間における季節性-トレンド表現の混在を分離するための相互情報制約を持つ分離変分推論の枠組みであるLaSTを説明しました。広範な実験により、LaSTは季節性-トレンド表現の分離に成功し、最新の性能を達成することが実証されました。今後は、時系列の生成や代入補間など、時系列の下流にある他の困難なタスクに取り組むことに焦点を当てるとしています。さらに、確率的な要因を分解戦略において明示的にモデル化し、実世界の時系列をよりよく理解することを計画しているとします。






この記事に関するカテゴリー






