
時系列分析に新たな潮流 : 増分近傍法による頑強な時系列「連鎖」抽出 TSC22
3つの要点
✔️ 時系列データから特徴的な「連鎖」を探すという比較的新しい手法が強力にアップデートされました
✔️ データが変化していく中で、正確に「連鎖」を見つけ、ノイズにも強い頑強なアルゴリズムになっています
✔️ 実世界のデータで定性評価、合成データで定量評価し、優れた性能を確認しています
Robust Time Series Chain Discovery with Incremental Nearest Neighbors
written by Li Zhang, Yan Zhu, Yifeng Gao, Jessica Lin
(Submitted on 3 Nov 2022)
Comments: ICDM 2022
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
概要
時系列データの分析、モデル化には多くのアプローチがあり、今回紹介する「時系列連鎖(Time Series Chain: TSC))」は、それらの中でも比較的新しい手法です。
時系列モチーフの発見は、時系列データ中の意味のある繰り返しパターンを同定するための基本的な課題でした。近年、時系列データ中の連続的に進化するパターンを識別するために、時系列モチーフの拡張として時系列連鎖が導入されました。非公式には、時系列連鎖(TSC)は時系列部分文の時間的順序集合であり、すべての部分文はその前の部分文と類似しているが、最後と最初が任意に非類似であることができるものです。TSCは、時系列に潜在する連続的な発展傾向を明らかにし、複雑なシステムにおける異常現象の前兆を識別することができることが示されています。しかし、残念ながら、既存のTSCの定義では、時系列の進化する部分を正確にカバーすることができません。発見された連鎖はノイズによって容易に切断され、進化していないパターンを含むことがあり、実世界のアプリケーションでは実用的でないことが分かっています。時系列部分配列の最近傍が時間とともにどのように変化するかを追跡する最近の研究に触発され、非進化パターンを除外しながら進化するパターンをよりよく見つけることができるという意味で、データ中のノイズに対してより頑健な新しいTSCの定義を導入します。さらに、発見された連鎖をランク付けするための2つの新しい品質指標を提案します。広範な実証評価により、提案するTSCの定義が従来の技術よりもノイズに強く、発見された上位の連鎖が実世界の様々なデータセットにおいて意味のある規則性を明らかにできることを実証します。
はじめに
過去20年間、モチーフ発見として知られる時系列データ中の繰り返しパターンを見つけるタスクは、多くの異なる領域にわたる幅広いアプリケーションのため、研究コミュニティで多くの注目を集めてきました。近年、時系列データの進化するパターンを捉える新しいツールとして、時系列連鎖(TSC)と呼ばれるプリミティブが導入されました。時系列鎖とは、時系列から抽出された部分文の順序集合であり、鎖の中の隣接する部分文は類似しているが、最初と最後が任意に非類似であるようなものです。モチーフ発見、 不和発見、 時系列クラスタリングなどの他の時系列データマイニングとは異なり、時系列連鎖は多くの複雑系、自然現象、社会の変化に広く存在する、時間と共に蓄積された潜在的ドリフトを捉えることができます。
時系列連鎖の機能をよりよく理解するために、アメリカの小売チェーン「Costco」の12年間の検索ワードに対応するFig. 1のGoogle Trendのデータを考えてみよう。図中、発見された時系列連鎖がハイライトされています。この連鎖の最初のパターンは、クリスマス前後に急激なピークを示します。これは、ホリデーシーズン前後にオンラインショッピングのニーズが高まるため、通常のパターンです。その後、そのピークが年々滑らかになるにつれて、7月頃に小さな段差が現れ、それが徐々に成長して、もう一つの大きなピークになるパターンです。この連鎖のパターンの変遷は、コストコの7月4日(独立記念日)のオンライン販売イベントに対する人々の関心の高まりを明確に示しており、マーケティングに有用な知見を提供しています。
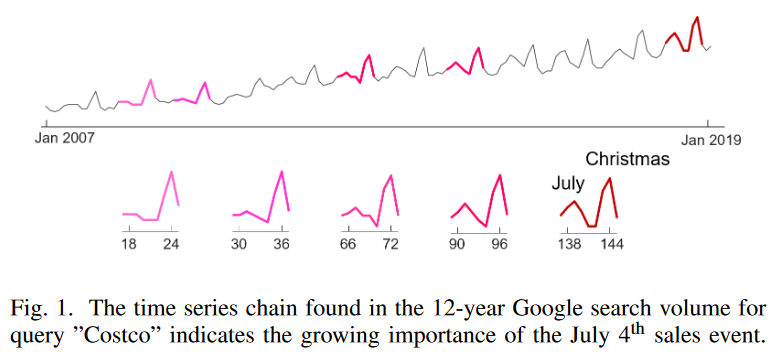
時系列連鎖のもう一つの典型的な応用は予後予測です。先行研究で指摘されているように、"ほとんどの機器の故障は、そのような故障が発生しそうな特定の兆候、条件、または徴候に先行されます"。時系列チェーンは、単一の前兆だけでなく、システムの連続的かつ漸進的な変化を明らかにする一連のパターンを識別することができ、分析者が早期に原因を発見し、致命的な故障を防ぐのに役立ちます。時系列連鎖を発見する方法としては、今のところ2つの方法があります。連鎖の概念は双方向の定義に基づいて初めて紹介され、その後頑健性を高めるために幾何学的な定義が提案されました。オリジナルの時系列チェーンの定義をTSC17と呼び、後の幾何学的チェーンの定義をTSC20と呼ぶことにします。
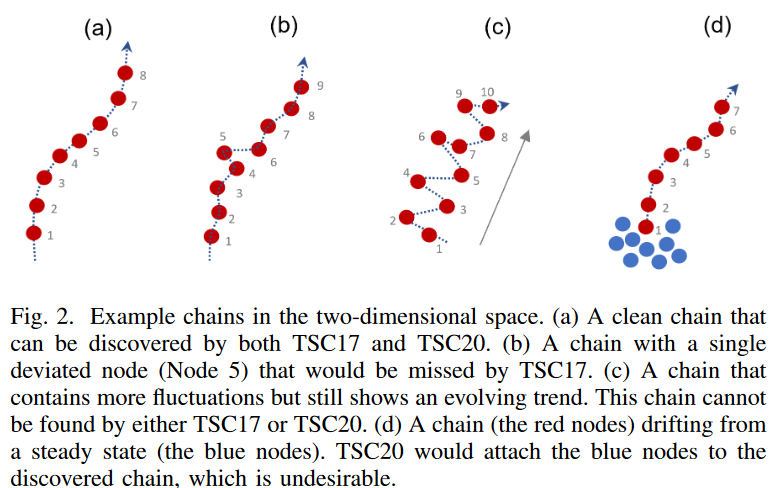
時系列連鎖の優れた解釈性にもかかわらず、残念ながら、既存の連鎖発見法は、データがクリーンで、パターンが小さな準線形ステップで展開する(Fig. 2.aに示すように)比較的理想的な状況でのみうまく機能することが観察されています。実際には、連続的なデータ収集プロセスは、環境変化、ヒューマンエラー、センサー信号の中断などの影響を受けることが多いです。 その結果、データはノイズを含み、いくつかのパターンは一般的な傾向から外れたり(Fig. 2.bのノード5など)、連続したパターンが反転したり、データの変動によりチェーンがジグザグに発展したりします(Fig. 2.c)。また、パターンがドリフトし始める前に、比較的安定した状態を保つこともあります(Fig. 2.dに示すように、予後予測では典型的である)。既存の連鎖発見法は実世界のデータにおけるこのようなシナリオを扱うには十分なロバスト性を持っていません。
具体的には、既存の時系列連鎖の定義に以下のような制約があることがわかりました。
- TSC17で導入された制約条件は厳しすぎるため、小さな揺らぎで簡単に連鎖が「切れて」しまう。Fig. 2.bはその制約を満たさない例である。
- TSC20で導入された方向角の閾値は、ノイズに非常に敏感である。データに揺らぎが含まれる場合、50度の閾値(推奨閾値は40度)でも見かけ上の鎖を見落とすことがある(例:Fig. 2.c)。しかし、さらに閾値を上げると、発見された連鎖には進化するトレンドとは関係のないノイズの多いパターンが多く含まれることになる。
- また、方向角が非常に小さい場合でも、TSC20で発見された連鎖には、進化するトレンドとは無関係なパターンが含まれることがある。例えば、最初は安定(パターンが非常に似ている)していたデータがドリフトし始めた場合(Fig. 2.dなど)、TSC20は安定(青)パターンを進化するチェーンに付加してしまう。その結果、いつドリフトし始めたのかがわからなくなってしまう。
これらの制限に対処するため、本研究では、連鎖発見の頑健性を向上させるために、パターンの最近接が時間とともにどのように変化するかを追跡するアイデアを利用した、新しい時系列連鎖定義TSC22を提案します。TSC17と同様に、TSC22は双方向の定義であるが、制約がかなり緩和されており、TSC20のような角度制約に依存しません。さらに、この手法によって発見された鎖をランク付けするために、新しい品質評価指標を提案します。実証的な評価により、提案手法は従来の手法よりもノイズに強く、発見された上位の鎖は実世界の様々なデータセットにおいて意味のある規則性を明らかにすることができることを実証します。
関連研究
時系列連鎖は比較的新しいトピックです。最も密接に関連する研究は、Zhuらと今村らによるものです。Zhuらは最初に時系列連鎖の概念を導入しました。この研究では,鎖の中のすべての隣接する部分配列のペアは,互いに左右の最近傍であることを強制し,最も長い鎖を時系列のトップチェーンとして報告します。この概念は単純かつ直感的ですが,現実世界の多くのアプリケーションでは,データの揺らぎやノイズによって鎖が簡単に切れてしまうため,双方向の最近接の要件は厳しすぎることが示されています。今村らは、単一方向の左最近傍条件のみを強制することで双方向条件を緩和し、発見された連鎖の方向性を保証するためにあらかじめ定義された角度制約を追加しています。この概念はいくつかの条件下ではより頑健であることが示されたが、新たに角度パラメータが導入され、いくつかの実世界のシナリオではこのパラメータをどのように設定しても意味のある鎖が発見できないことが観察されました。
時系列連鎖に関する他の研究は、異なる問題設定をしています。Wangらは、既存の時系列連鎖定義を用いて、ストリーミングデータにおける連鎖発見を高速化する方法を探求しています。Zhangらは、2つの時系列にまたがるジョイント時系列チェーンを検出する方法を提案しています。
ここでは単一の時系列におけるチェーン定義の改良に焦点を当てます。
定義
まず必要な時系列表記を確認し、次に時系列連鎖の正式な定義について考察します。
A. 時系列表記
時系列に関連する基本的な定義です。
定義1. 時系列
T = [t1, t2, ... , tn] はデータポイントの順序付きリストであり、ti は有限の実数、nは時系列Tの長さです。
定義2. 時系列部分列
ST i= [ti, ti+1, ... , ti+l-1] は,時系列 T の位置 i から始まる点の連続した集合で,長さ l. 通常 l ≫n,そして 1 ≤ i ≤ n - l + 1 です。
時系列 T からは、固定長 l のウィンドウを時系列間でスライドさせることで部分列を抽出することができます。クエリの部分配列が与えられると,時系列 T のすべての部分配列との距離を計算することができます。これは距離プロファイルと呼ばれます。
定義 3. 距離プロファイル
DQ,T は,クエリ部分配列 Q と時系列 T の同じ長さの部分配列との間の距離を含むベクトルです。形式的には,DQ,T = [d(Q, S1), d(Q, S2), ... , d(Q, Sn-l+1)], ここで d(., .) は距離関数を表してます。Qが位置iから始まる時系列Tの部分列である特別な場合、距離プロファイルをDiと表記します。
Matrix Profile の原著作に従い,ここでは,スケールとオフセットの不変性を達成するために,ユークリッド距離の代わりに z 正規化ユークリッド距離を使用します。
さらに、距離プロファイルを左距離プロファイルと右距離プロファイルに分割することができます。
定義4. 時系列Tの左距離プロファイル
時系列 T の DLi は,与えられた部分配列 Si∈T と,Si の左側にあるすべての部分配列との間のユークリッド距離を含むベクトルです。形式的には、DLi = [d(Si, S1), d(Si, S2), ... , d(Si, Si-l/2)] です。
定義5.右距離プロファイル
DRiは、DRi = [d(Si, Si+l/2), ... , d(Si, Sn-l+1)] であるベクトルです。
左側と右側の距離プロファイルの最小値をそれぞれ調べることで,ある部分配列の左側最近傍(LNN)と右側最近傍(RNN)を容易に見つけることができます。左行列プロファイルと右行列プロファイルという2つのベクトルを用いて、全ての部分配列とそれに対応する左/右最近傍間の距離、および、それらの最近傍の位置を格納します。
定義6. 左行列プロファイル
MPL は,サイズ 2 × (n - l + 1) の 2 次元ベクトルで,MPL(1, i) = min(DLi) および MPL(2, i) = arg min(DLi) です。
ここで,MPL(1, i) は Si と i より前の最も類似した部分配列(すなわち,その LNN)との間の距離を格納し,M PL(2, i) は LN N の位置を格納します。
定義7.右行列プロファイル
MPR はサイズ 2 × (n - l + 1) の 2 次元ベクトルで,MPR(1, i) = min(DRi) と MPR(2, i) = arg min(DRi) です。
B.既存の時系列連鎖の定義
既存の時系列連鎖の定義はいずれも後方時系列連鎖をもとに発展したものであり、左行列プロファイルが与えられれば容易に求めることができます。
定義8. 時系列Tの後方連鎖
時系列 T の TSCBWD は、時系列部分列の有限順序集合です。TSCBWD = [SC1 , SC2 , SC3 , ... , SCm ], ここで、C1 > C2 > ... 。C1 > C2 > ... > Cm は時系列 T のインデックスで、1 ≤ i < m に対して、LNN (SCi ) = SCi+1 となるようなものです。
ここで、わかりやすくするために、時系列連鎖の一部をノードと呼ぶことにします。後方鎖の最初のノードを開始ノード、最後のノードを終了ノードと呼ぶことにします。ここで、TSCBWD では、SC1 が開始ノードで、SCm が終了ノードです。
同様に、右の行列プロファイルから前方時系列連鎖を得ることができます。
定義 9. 前方鎖
TSCFWD は,時系列 T の部分列の有限個の順序集合です。TSCFWD = [SC1 , SC2 , SC3 , ... , SCm ] ここで、C1 < C2 < ... < Cm は時系列 T のインデックスです。任意の 1 ≤ i < m に対して, RN N (SCi ) = SCi+1 をちます。
既存の研究は、後方鎖に異なる制約を課して鎖を定義しています。TSC17では、後方鎖と前方鎖の交点に基づいて時系列鎖が定義されています。これを双方向時系列連鎖と呼びます。
定義10. 双方向時系列連鎖
双方向時系列連鎖(TSC17) は、時系列 T の部分列の有限個の順序付き集合です。TSC = [SC1 , SC2 , SC3 , ... , SCm ] ここで,C1 > C2 > .... C1 > C2 > ... > Cm であり,任意の 1 ≤ i < m に対して, LNN (SCi ) = SCi+1 と RN N (SCi+1 ) = SCi を持ちます。ここで、集合の大きさ m を鎖の長さとして表します。
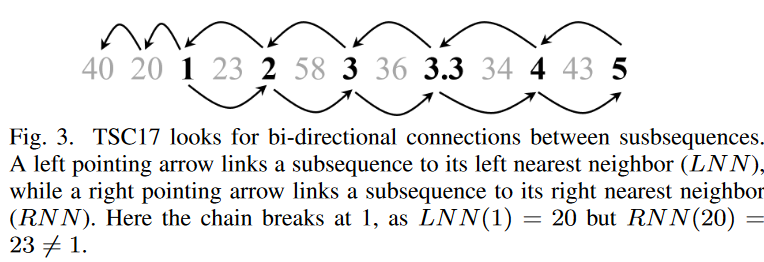
TSC17 の仕組みを理解するために、Fig. 3 の時系列を考えてみましょう。
40, 20, 1, 23, 2, 58, 3, 36, 3.3, 34, 4, 43, 5
部分列の長さを1とし、数値の差の絶対値で距離を測ります。後方連鎖5→4→3.3→2→1→20→40をたどり、各ノードのLNNとRNNがループを形成できるかどうかを確認します。
LNN (5) = 4、RNN (4) = 5となる。
LNN (4) = 3.3 と RN N (3.3) = 4。
LNN (3.3) = 3 と RNN (3) = 3.3;
LNN (3) = 2およびRNN (2) = 3。
LNN (2)=1、RNN (1)=2です。
LNN (1)=20だが、RN N (20)=23 6=1なので、鎖は1で切れます。Fig.3のように、抽出された鎖(逆行)は
5 ↔ 4 ↔ 3.3 ↔ 3 ↔ 2 ↔ 1
Fig.3をよく見てみると、この疑問に対する良い答えが見つかります。もし、単純に5→4→3.3→3→2→1→20→40の連鎖を何の制約もなくたどると、連鎖はその「方向性」を失います。ノイズの多い大きな数字(20、40)は単にゆっくり減少するトレンドに適合しないのです。TSC17の双方向性制約は、これらのノイズの多い信号を連鎖から除去します。
TSC20では、後方鎖に角度制約をかけることで時系列鎖を定義しています。これを幾何学的時系列連鎖と呼びます。
定義 11. 時系列Tの幾何学的時系列連鎖
時系列Tの幾何学的時系列連鎖(TSC20) は,時系列 T の部分列の有限順序集合です。TSC = [SC1 , SC2 , SC3 , ... , SCm ] (C1 > C2 > .... > Cm )であり、任意の 1 ≤ i < m に対して、LNN(SCi )= SCi+1 を持ち、任意の 2 ≤ i < m に対して、i番目の角度 θi ≤ θ を持つようなものです。ここで、
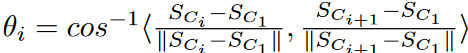
θはあらかじめ定義された閾値です。
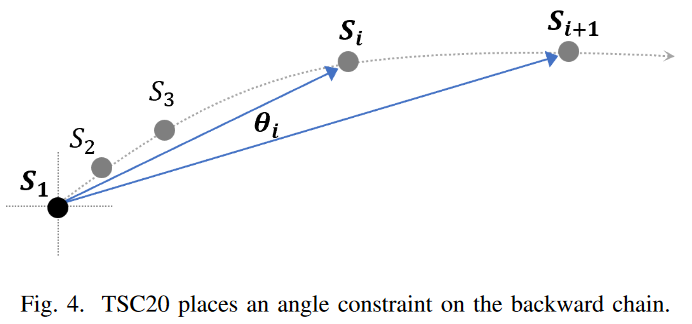
Fig. 4は、TSC20の定義が2次元空間においてどのように機能するかを示しています。方向角θiは、アンカーノードS1を基準としたSiからSi+1への方向変化を測定します。連鎖の連続する2つの部分列の間に小さな角度閾値を設けることで、部分列が類似した方向に進化することを保証しています。
TSC17とTSC20の限界
TSC17とTSC20はどちらも直感的に使えるが、データのノイズや揺らぎの影響を受けやすいことが分かります。
A. TSC17の弱点
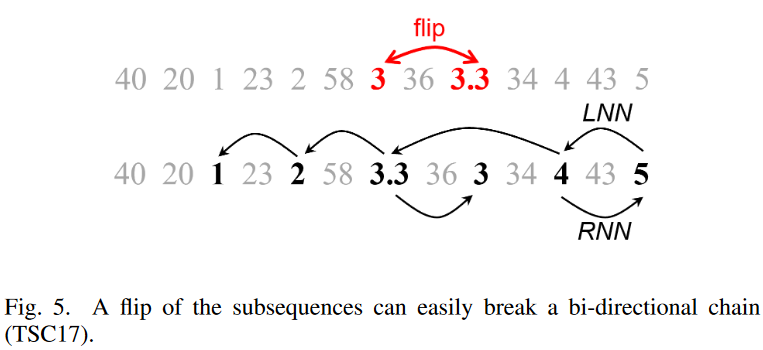
Fig. 3の例をもう一度見てみましょう。Fig. 5.上のように、3、3.3という数字を反転させるとします。これで時系列は次のようになります。
40, 20, 1, 23, 2, 58, 3.3, 36, 3, 34, 4, 43, 5
Fig. 5.下のように、ノード5から後方に鎖を伸ばしていくことを考えます。LNN (5) = 4, LNN (4) = 5 であることがわかるので、連鎖に4を追加することができます。続けて、LNN (4) = 3.3 となるが、RNN (3.3) = 3 6= 4 なので、3.3 を加えることができず、連鎖は途切れます。しかし、Fig.5.下より、反転しても5→4→3.3→2→1という順序で、徐々に減少する合理的な連鎖を作ることができることが分かります。双方向の制約がきつすぎて、連鎖が成立していないだけです。
B. TSC20の弱点
TSC20で使用されている幾何学的な鎖の定義では、TSC17の双方向l制約を取り除き、後方鎖のみを使用しています。これにより、Fig. 3に示すように、鎖が長くなる一方で、無関係なノイズパターンが鎖に含まれる可能性があります。これを解決するために、TSC20では後方鎖の上に角度制約を追加しました。しかし、この角度制約が新たな問題を引き起こし、TSC20はある状況では明らかな連鎖を見逃し、またある状況では発見された連鎖に不要なパターンが付加されてしまうことがわかりました。
1) 明らかな連鎖の見落とし
Fig. 6.上の2次元の例を考えてみましょう。部分配列は時間的に次の順序で現れると仮定します。
s9, s8, s7, s6, s5, s4, s3, s2, s1
部分配列はジグザグに進化しているが、左から右へゆっくりと移動している傾向がはっきりとわかります。しかし、TSC20はこの連鎖を検出することができません。
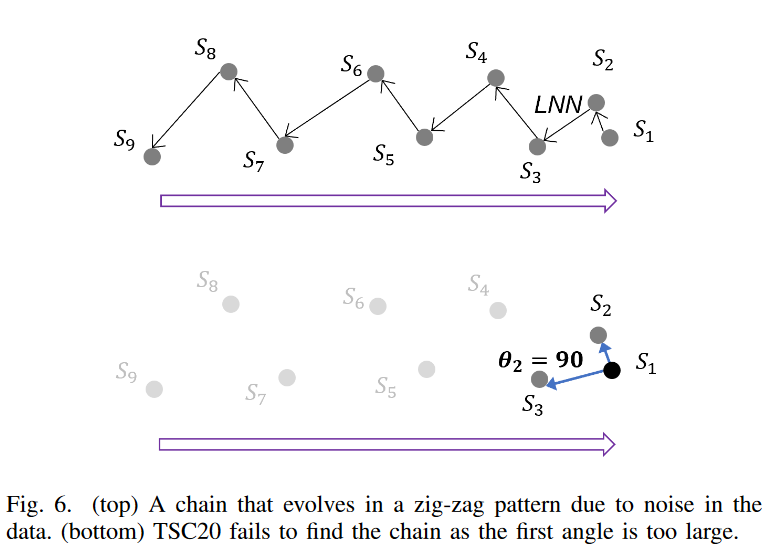
TSC20 の定義に従い、Fig.6.上 では、まず S1 から始まる後方鎖を見つけ(矢印はすべての部分列を 2 次元空間上の LNN に指している)、次にアンカー部分列 S1 を基点に連続する部分列間の角度を確認します。Fig. 6.下に示すように、最初の角度θ1 = 90度であり、TSC20で提案された閾値40度よりはるかに大きく、鎖は即座に切断されます。アンカーを次の部分鎖に再設定することで、全ての部分後方鎖について確認できるが、残念ながら制約を満たす部分鎖はありません。
Fig. 6は、2次元空間において揺らぎがTSC20を破綻させることを示しているにすぎないことに注意してください。実際には、高次元空間では、ノイズやゆらぎが部分列を異なる方向にドリフトさせるため、このような進化をするパターンが非常に一般的です。
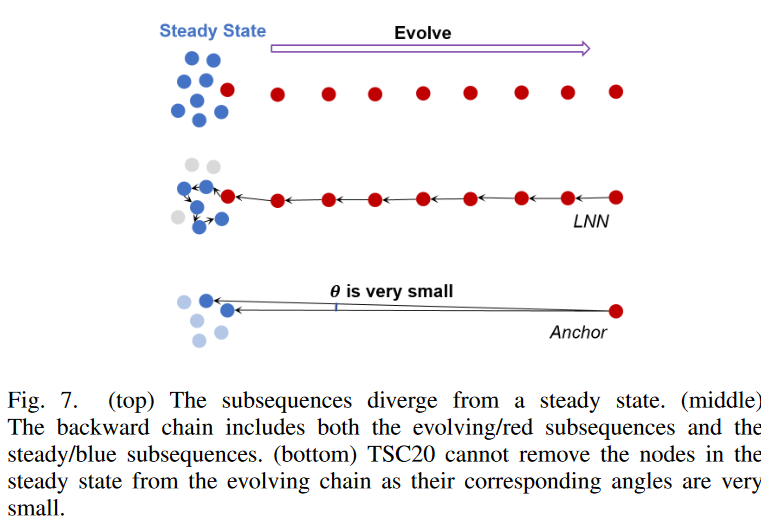
2) 連鎖への望ましくないパターンの付加
また、TSC20の問題点として、チェーンに無関係なパターンが付くことがあり、チェーンの品質が劣化することがあります。Fig. 7.上にその例を示します。ここでは、部分配列は最初定常状態にあり(青で示す)、その後ずっと右へドリフトし始めます(赤で示す)。理想的には、連鎖発見アルゴリズムが、定常状態(青)の部分配列ではなく、進化する(赤)部分配列をすべて見つけ、連鎖の終端ノード(左の最初の赤いノード)が、システムがいつドリフトし始めるか(すなわち変化点)を正確に教えてくれるようにすることです。この時間情報は、ドリフトの根本的な原因を特定するのに役立つため、予後予測の用途では非常に重要です。しかし,Fig. 7.中に示す後方チェーンをたどると,このチェーンに沿ったすべての連続したノードが TSC20 の角度制約を満たしていることがわかります。赤い節点は準線形で進化しているので、方向角はゼロに近いです。また、連続する青いノード(Fig. 7.下)に対応する角度も、これらのノードはアンカーから遠く離れていながら非常に接近しているため、非常に小さくなっています。その結果、TSC20の角度制約では、青いノードを鎖から除外することができず、変化点を検出することができません。
提案手法
既存の時系列連鎖の定義における前述の限界に対処するため、本論文ではTSC22と名付けた新しい時系列連鎖発見法を提案します。TSC20で述べたように、連鎖発見法は2つの部分から構成されるべきです。データ中の全ての連鎖を発見するアルゴリズムと、発見された連鎖をランク付けするために使用される品質メトリックです。
A. 増分近傍
我々の連鎖発見法はY. Zhuらのアイデアを活用し、時系列部分配列の最近傍が時間とともにどのように変化するかを追跡します。Fig. 8 では、前節の 1 次元の実行例を用いて、これがどのように機能するかを示しています。右から順に部分配列 2 まで走査すると、その絶対値の差に基づいて、これまでの最近傍部分配列(または増分近傍配列)が格納されます。この集合は、ある部分配列の最近傍の位置が、時系列の最後から辿っていったときにどのように変化するかを示しているため、集合 {3, 4, 5} を増分近傍集合 (IN N S) と呼ぶことにします。

定義 12. ある部分配列Siの増分近傍集合(INNS)とは,部分配列Sj(i<j≦n - l+1)の集合です。
{Sj|d(Si, Sj) < d(Si, Sk)∀k : j < k ≤ n - l + 1}
なお,ある部分配列の右近傍は,必ずその部分配列の IN N S に含まれます。
B. 増分近傍ですべての連鎖を見つける
増分近傍に基づき、我々の連鎖の定義における重要な要素であるクリティカル・ノードを導入します。
定義 13. 時系列 T の時系列部分配列 Si は、Si ∈ IN N S(LNN (Si)) のとき、クリティカル・ノード (CN) となります。
クリティカルノードは,定義10(TSC17)と比較して,より緩やかな制約に基づくことができることに注意してください。RNN は常にインクリメンタルな最近傍集合に属するので、TSC17 チェーンのノードも本定義ではクリティカル・ノードとなります。時系列 T のすべての臨界ノードを見つけることができます。これをクリティカル・ノード集合と呼び、CN T と表記します。これにより、TSC22(relaxed-bi-directional time series chain)を正式に定義することができます。
定義 14. 時系列 T の緩和双方向時系列連鎖(TSC22)とは,時系列部分列の有限順序集合です。
T SC = [SC1 , SC2 , SC3 , ... , SCm ] (C1 > C2 > ... > Cm), such that:
1) 任意の 1 6 i < m に対して,LN N (SCi ) = SCi+1,
2) SC1 ∈ CN T,
3) 任意の 1 < i 6 m に対して,SCj ∈ IN N S(i), j = arg min i<j≤m SCj ∈ CN T を有する。
条件(1)から、TSC17とTSC20と同様に、我々の新しい鎖の定義TSC22も後方鎖の上に構築されていることがわかります。TSC17ほど前方鎖の制約が厳しくないため、"relaxed" bi-directional chainと呼びます。
Fig. 9に一次元の時系列を例として示します。
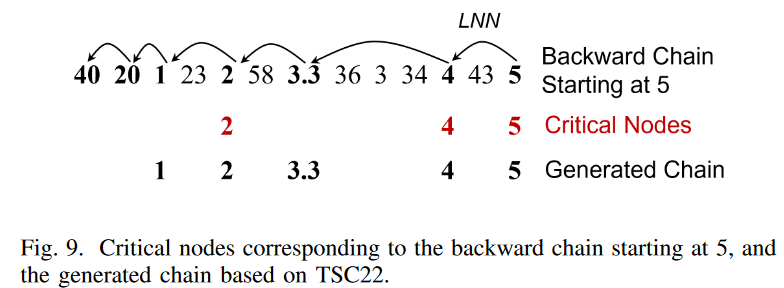
(1)と(2)から、TSC22は臨界ノードから始まる後方鎖であることがわかります。ここで、ノード "5 "から連鎖を展開してみます。Fig. 9に示すように、LNN(5)=4、5∈IN N S(4)={5}であることが判ります。つまり、5はクリティカルノードであり、TSC22の有効な始点ノードであることがわかります。次に、後方連鎖の次のノードの確認に移ります。LN N (4) = 3.3 であり、4∈IN N S(3.3) = {3, 4, 5}なので、4はクリティカルノード、LN N (3.3) = 2だが、3.3 6∈IN N S(2) = {3, 4, 5}なので3.3はクリティカルノードではない等々です。処理を続けると、この後方鎖上のクリティカルノードは5、4、2であることがわかります。条件(3)は、連鎖の各ノードSCi (開始ノードを除く)に対して、SCi の後に現れる連鎖の最も近いクリティカル・ノードがIN N S(SCi )の要素でなければならないことを要求しています。後方鎖5→4→3.3→2→1→20→40の各ノードについて確認すると、部分鎖5, 4, 3.3, 2, 1はこの条件を満たすが、部分鎖20は1 6∈IN N C(20) = {23, 34, 5}となり、この位置で鎖は切れないことが分かります。そのため、生成される連鎖は5→4→3.3→2→1です。本来、条件(3)は生成される鎖の「方向性」を保証するものです。Fig. 9 に示すように、元の時系列と生成された鎖の両方において、2の右側にあるすべての部分 列と比較して、部分列 2 は部分列 1 に近く、元の時系列と生成された鎖の両方において、部分列 4 の右側にあるすべての部分列と比較して、4 は 2 と 3.3 に近いことが確認されました。
Fig. 9とFig. 5を比較すると、TSC22では、ノイズにより鎖のパターンの一部が反転していても、意味のある鎖を抽出できることが分かる。また、Fig. 6のジグザグ連鎖も我々の定義で発見できることがわかります。このことは、TSC22がTSC17やTSC20よりもノイズに強いことを示しています。
C. ランキング
TSC22で発見された全てのチェーンが揃ったので、それらの品質を測定し、効果的にランク付けするメカニズムが必要です。TSC17は発見された鎖をその長さでランク付けするが、これは特に時系列に大量のノイズが存在する場合、必ずしも効果的とは言えません。TSC20で述べたように、TSC17は、進化的な傾向を示さない定常データでも長い鎖を発見することがあり、上位の鎖の長さだけでは、データ中に意味のある鎖があるかどうかを判断することはできません。質の高い連鎖は次のような性質を持つことが理想的です。
- High Divergence 連鎖の最初と最後のノードが十分に非類似であること。
- 漸進的変化(Gradual Change) 連鎖の連続するノードが互いに非常に類似していること。
- Purity 連鎖には無関係なパターンが含まれていてはならない。
- 長さ 漂流パターンを十分にカバーするために、鎖は長い方が良い。
これらの品質観は必ずしも一致しないことに注意してください。ある鎖は非常に速く進化し、高い発散性を示すが漸進性は低く、長さも短いです。一方、別の長い鎖は、互いにほとんど同じパターンからなるが、進化する傾向を示さないこともあり得ます。これを解決するために、我々は全ての特性を考慮した2つの品質指標を開発し、これらの品質指標に基づく2段階のランキングアルゴリズムを設計し、高品質の鎖が目立つようにします。
・有効長
TSC20に触発されて、発散性と漸進性を同時に測定する「有効長」 メトリック Leff を計算します。
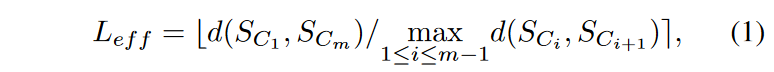
ここで b.e は最も近い整数に丸めることを表します。分子は鎖の最初のノードと最後のノード間の距離で、分母は鎖の連続するノードのすべての組の間の最大距離である。鎖が一様な速度で線形トレースで進化する場合、Leffが鎖の長さになることが想像できます。この指標は本質的に、線形トレースで動いている場合、開始ノードから終了ノードに到達するために必要なおおよそのステップ数を示しており、1ステップあたりの距離は鎖のノード間の最大連続距離に等しいとされています。発散が大きく、かつ漸進性の高い連鎖はLeffが高く、ノイズを含む連鎖はLeff ≈ 1となるはずです。Leffは整数であるため、同値のものが存在します。まずLeffのスコアで鎖をランク付けし、次にLeffのスコアが最も高い鎖に対して、相関の二乗和に基づく細かいランク付けを行います。
・相関長
本論文でのメトリックを相関長と呼び、以下のように計算されます。
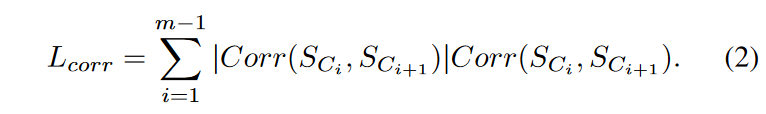
ここで、Corr(.)はz正規化された部分配列のピアソン相関係数であり、値は[-1, 1]の範囲です。2つの部分配列が非常に似ている場合、そのピアソン相関係数は1に近く、ノイズを含む場合、通常0.5より小さくなります。ここでは、類似ペアと非類似ペアの差を拡大するために、ピアソン相関係数にその絶対値を掛けています。この指標を相関「長さ」と呼ぶのは、鎖の連続するノードが互いに非常に似ている場合、Lcorrは鎖の実際の長さに非常に近くなるためです。その結果、細粒度のランキング段階では、高度に類似した部分列を持つ長い鎖が優先されることになります。鎖の長さのみを考慮するTSC17のランキング手法や、発散度と漸進度のみを考慮するTSC20のランキング手法と比較すると、このランキング手法は、鎖の全ての品質観点に対してより良い網羅性を持っています。新しいランキング手法と、より頑健な鎖の定義により、TSC22は、データに大量のノイズが存在する場合でも、様々な実世界や合成データセットから意味のある鎖を効果的に発見することが可能です。
実験評価
提案手法が現在の最新時系列連鎖発見手法であるTSC17 (ICDM'17) とTSC20 (KDD'20) よりも堅牢であることを実世界と合成データの両方において実証します。公正な比較を行うため、TSC17とTSC20の両方のMatlabのオリジナルソースコードを使用し、TSC20の方向角はデフォルトを使用します。
まず、実世界のデータを用いたいくつかのケーススタディにより、3つの連鎖発見手法の性能を定性的に分析し、次に、絶対的なグランドトゥルースに基づく性能指標を計算できる大規模合成データセットで定量的な比較を行います。
A. ケーススタディ: ペンギン活動データの頑強分析
1) クリーンなデータ
ここでは、Y. Zhuらのペンギンの活動時系列を用います。これは、鳥が移動する際のx軸の加速度を示しています。部分配列の長さは25です。Fig. 10 はペンギンが水中に飛び込むときの 22.5 秒間のデータ(40Hz で記録)です。鳥が水面に到達するのは約2秒後(80個目のデータポイント)であり、その後、深度の値が増加し始めます。Fig. 10に示すように、TSC22は、最初のピークが2番目のピークより少し低く、時間とともに1番目のピークが高くなり、2番目のピークが弱くなるという、明らかに発展的な傾向を示す高品質の連鎖を見いだしました。この連鎖は、ペンギンが浮力と水圧の増加のバランスをとるために羽ばたきを調整する様子を示しています。TSC22で得られた鎖は潜水範囲全体をカバーしていますが、TSC20で得られた鎖は末端の数ノード、TSC17で得られた鎖は両側の数ノードが欠落しています。TSC20とTSC17の連鎖は、パターンの進化傾向を示すことができるが、進化手順の開始/終了時刻を示すことができていません。
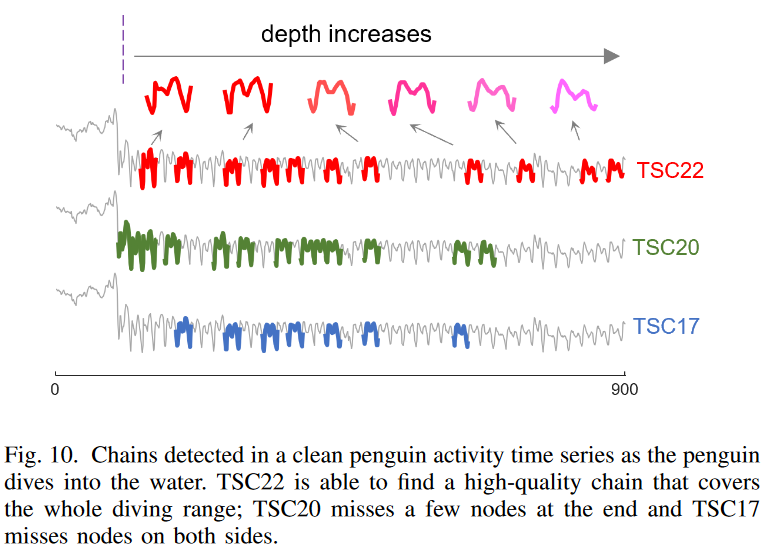
TSC17とTSC20がFig. 10のTSC22の鎖を見つけられないのは、TSC17とTSC20の制約によるものか、それともTSC22の鎖より他の鎖を好むランキングメカニズムによるものか、不思議に思うかもしれません。よく観察すると、TSC22チェーンはTSC17とTSC20のどちらの定義も満たしていないことがわかります。Fig. 5と同様に、データの自然な揺らぎ(例えば、ペンギンが他の動物を避けるために移動方向を変えた可能性)により、鎖上の連続したノードのほとんどがTSC17の双方向最近傍制約を満たしていません。そして、TSC22の連鎖を逆に辿っていくと、この連鎖の最初の3つのノードが形成する方向角(Fig. 6を参照)は114度で、TSC20の角度閾値(40度)を大きく上回るため、連鎖は瞬時に切断されることが分かります。この例は、自然な揺らぎを持つ高次元実世界データにおけるTSC17とTSC20の弱点を検証し、そのようなデータにおけるTSC22の頑健性を実証するものです。
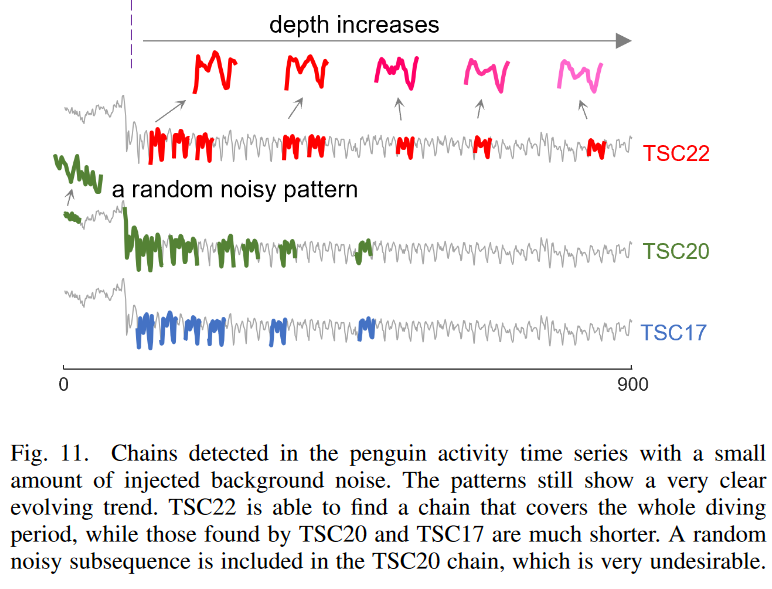
2) ライダム背景ノイズを持ったデータ
Fig. 11では、3つの手法の頑健性をさらに検証するために、ペンギンのデータに少量(±0.08等級)のランダムノイズを加え、センサーからの追加バックグラウンドノイズをシミュレートしています。この場合、TSC22は依然として潜水手順全体に渡る高品質な鎖を発見することができ、発見されたパターンは追加ノイズがある場合でも非常に明確な進化傾向を示していることがわかります。しかし、TSC20とTSC17はこの連鎖を捉えることができず、彼らのトップチェーンは進化する範囲の半分しかカバーできなくなりました。さらに、TSC20はランダムなノイズパターンをトップチェーンに付加しています。これは、後方チェーンが長くなるにつれて方向角制約のフィルタリング能力が弱まっていることを表しています。
B. ケーススタディ: 散るとテーブルデータでの変化点の検出
ここでは、Y. Zhuらのチルトテーブルデータを用いて、システムが定常状態からドリフト状態に遷移する際に、検討中の3つの方法がどのように機能するかを比較します。Fig. 12は、チルトテーブルに横たわる患者の動脈血圧(ABP)信号です。ここで、部分配列の長さを180とし、ほぼ心周期に相当する長さとしました。このようなデータは、他の多くの領域、特に予後予測では、システムが最初は安定した状態で動作し、その後、悪化し始めるという典型的なものであることがわかります。そのため、変化点(ドリフトの始まり)を正しく特定することが重要であり、その情報をもとにドリフトを引き起こした暗黙のメカニズムを特定し、システム障害を早期に防止することができます。
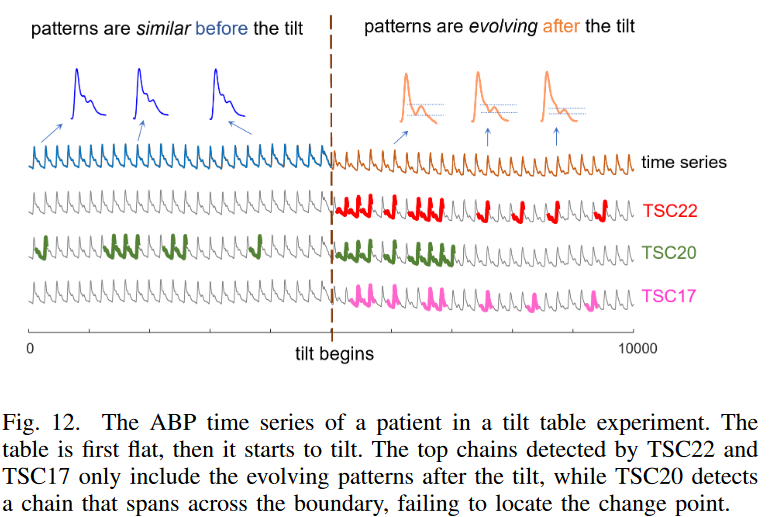
Fig. 12を見ると、TSC22とTSC17は、傾き後のデータの右側部分のみを対象とした連鎖の発見に成功しているが、TSC20は、傾き部分と定常部分にまたがる連鎖を検出していることがわかります。この場合、TSC20が純粋な鎖を生成できない理由は理解できなくはありません(Fig. 7を参照)。アンカーポイントを基準とした傾き前の部分配列のどのペアもほぼ同一であるため、それらの間に形成される方向角はゼロに近くなってしまうのです。TSC20の単一方向性では、データの安定区間に到達したときに後方鎖の成長を単純に止めることができません。一方、TSC22とTSC17の両方における双方向の制限は、それらの鎖が定常セクションに成長するのを効果的に阻止します。この例は、TSC22の有用性をさらに示しています。TSC22は、システムがドリフトし始めるタイミングを正確に特定できるため、解析者はその前後に起きているイベントを調べることで、ドリフトの暗黙の原因を容易に見つけ出すことができます。
C. ケーススタディ: 人間の歩行力データでの複数の訓練ステージでの連鎖発見
人間の歩行力時系列を用いて、連鎖発見法を評価しました。Fig. 13に示すように、この時系列は、4つの異なる走行速度で動作するスプリットベルト式トレッドミル上でセンサが検出した後前方向の力を表しています。Fig. 13から、TSC22で検出されたチェーンは、すべての異なる速度帯にまたがっていることがわかります。また、連鎖のパターンが鋭くくぼんでいるのは、速度が上がるにつれて力の変化が速くなり、被験者の足が糸車床上にいる時間が短くなることを示しています。また、ディップからピークまでの時間が短いことは、走行速度が速くなったことを示しています。しかし、TSC20とTSC17は、時系列全体でパターンが進化しているにもかかわらず、データの一部でしかチェーンを検出できず、全範囲をカバーすることができません。
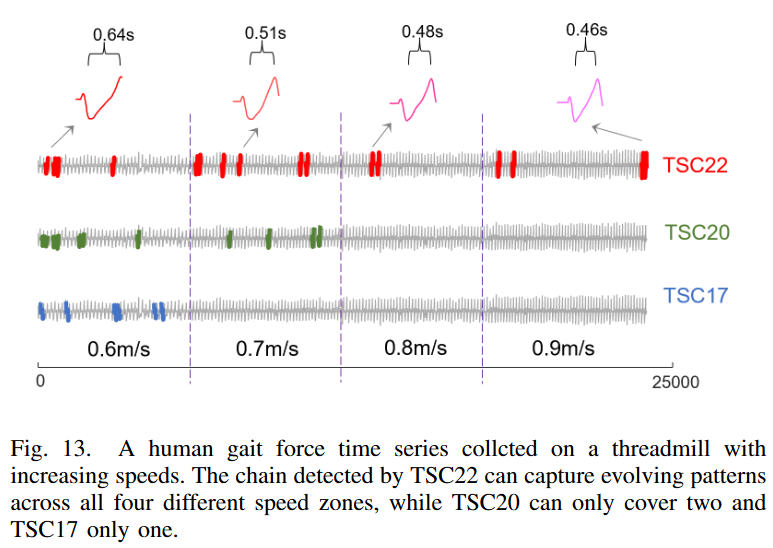
この場合、なぜTSC20とTSC17は失敗するのでしょうか?速度が断片的に一定に増加しているため、同じ速度帯内のパターンは互いに比較的類似しており、かなり小さなペースで進化していることに注意してください。参加者の動きには当然ゆらぎがあるため、同じスピードゾーン内で多くのパターンが反転し(Fig. 5を参照)、全体の進化形はFig. 2.aのものではなくFig. 2.cやFig. 6のようなジグザグチェーンに近くなります。健全性チェックとして、Fig. 13のTSC22鎖上のノードはいずれもTSC20の双方向最近傍制約を満たしておらず、鎖上の最後の3ノード(すなわち後方鎖の最初の3ノード)が形成する方向角は86度で、TSC20の角度制限40度をはるかに超えていることが分かります。この例は、当然ながら多くの揺らぎやノイズを伴う実世界の時系列データに対するTSC22の優れた頑健性をさらに実証しています。
D. 定量的頑強性分析
上記評価では、絶対的なグランドトゥルースラベル(すなわち、時系列におけるチェーンの各パターンの正確な位置)がなく、これらのラベルの潜在的な曖昧さは、実世界のデータに基づく合理的な定量分析を行うことを困難にしています。そこで、精度や再現率などの定量的な性能指標を計算するために、大規模な合成データセットを作成し、そこに手動で連鎖パターンを埋め込み、当該3手法がこれらのパターンを正確に位置づけることができるかどうかをテストしました。
Fig. 14は作成した時系列の例です。ここでは、グランドトゥルース鎖の最初のノード(Fig. 14.上)はUCR時系列分類アーカイブ1内のデータセットからランダムにサンプリングされ、最後のノードはランダムウォークパターンです。鎖は10個のノードからなり、最初のノードから最後のノードまで線形に進化します。この鎖のノードをランダムノイズの時系列に順序を保ったままランダムな位置に埋め込みます。課題の難易度を上げるため、データの上にランダムなノイズを加えてパターンを歪ませ、さらに、最初のノードに似ているが(同じデータセットからサンプリング)進化するトレンドとは無関係な10個のパターン(Fig. 14.下に示す)を時系列に埋め込むことにしました。生成された時系列の最初と最後に2つのランダムなノイズセクションを追加し、連鎖が時系列全体に及ばないという現実世界のシナリオをシミュレートしました。合成時系列を構築するために、UCR時系列アーカイブにある17のデータセットを使用し、50から500のインスタンス長で全てのセンサー、ECG、シミュレーション形状データをカバーし、生成されたチェーンの視覚的解釈が困難になる高周波パターンを含むデータセットは省略しました。各データセットについて、5つの異なる時系列を生成し、これらの時系列に対する各鎖発見手法の平均性能を測定しました。

検出された連鎖のノード(すなわち、部分配列)が50%以上グランドトゥルースと重なる場合、ヒットと定義します。
すべてのTSC手法は、連鎖の検出とランキングの2つのステップから構成されているため、ランキングのステップを含む場合と含まない場合の性能を比較する実験を行いました。
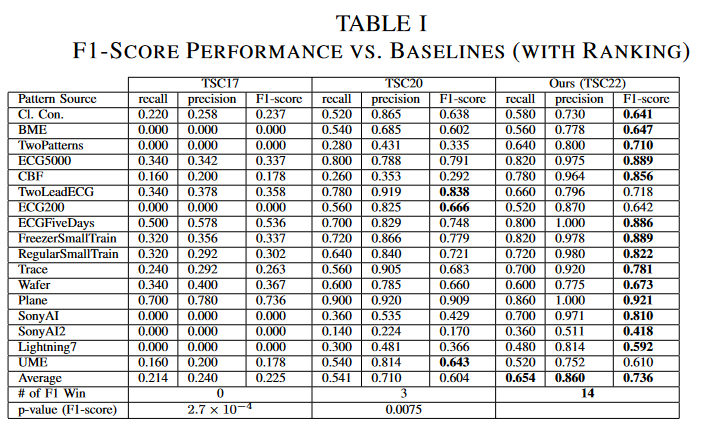
1) ランキングを用いた場合の総合性能
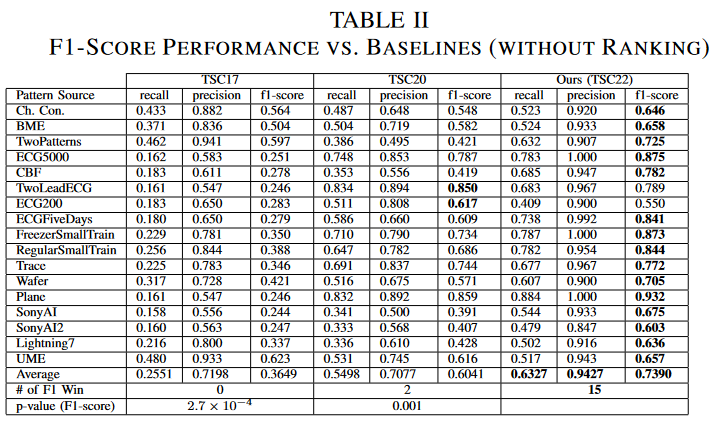
Table Iは、3つの方法によって検出されたトップ1チェーンの性能を示しています。TSC22は17データセット中14データセットで両ベースラインよりF1スコアが高く、平均値(0.736)はTSC17(0.225)、TSC20(0.604)よりはるかに良好です。TSC22とTSC17の間のWilcoxon signed-rank検定のp値は2.7 × 10-4、TSC22とTSC20の間のp値は0.0075でした。いずれのp値も0.05未満であることから、TSC22がベースラインよりも統計的に有意に優れていることがわかります。
2) ランキングを用いない場合の性能
ランキングの影響を排除した定義で3つのTSC手法を公平に比較するために、チェーンの開始ノードを固定し、発見されたチェーンのパフォーマンスを評価しました。各時系列において、グランドトゥルース鎖の最後の5ノードから独立して鎖を「成長」させ、これら5つの異なる鎖の中で得られた最大のF1スコアを報告しました。Table IIより、TSC22は17データセット中15データセットで両ベースラインよりF1スコアで優れていることがわかります。また、Wilcoxon検定のp値が0.05未満であることから、TSC22の定義は既存のTSCの定義よりも有意に優れていると結論づけられます。
まとめ
本研究では、パターンの最近傍が時間とともにどのように変化するかを追跡するアイデアを利用し、ノイズに対する連鎖の頑健性を向上させる新しい時系列連鎖定義TSC22を提案しています。さらに、検出された連鎖を効果的にランク付けするために、2つの新しい品質メトリクスを提案しました。実世界と合成データの両方に対する広範な実験により、この新しい定義が最先端のTSC定義よりもはるかに頑健であることが示されました。また、実世界の時系列に対して行ったケーススタディにより、この手法により発見されたトップランクの連鎖が、異なるノイズ条件下での様々なアプリケーションにおいて、意味のある規則性を明らかにできることが示されました。
(記事筆者)幅広い応用分野を持つ時系列データ分析において、強力なツールが新しく提案されました。読者の皆様ご自身のデータで評価されてみてはいかがでしょうか?




この記事に関するカテゴリー






