
複雑なチューニングなしに広い受容野で学習する時系列分類動的スパースネットワークDNS
3つの要点
✔️ NeurIPS 2022採択論文です。煩雑なハイパーパラメータチューニングを行うことなく、様々な受容野をカバーする学習が可能な時系列分類用のスパース接続を持つ動的スパースネットワーク(DSN)を提案します。
✔️ 各スパース層のカーネルはスパースであり、動的スパース学習により制約領域の下を探索することができるため、リソースコストを削減することが可能です。
✔️ 単変量および多変量のTSCデータセットにおいて、SOTAと比較して50%以下の計算コストで最先端の性能を達成できることが示されました。さらに、提案するDSN手法は他のDST手法と容易に組み合わせることができ、有効性を示しています。これは、将来の優秀な手法との融合を示唆するものです。
Dynamic Sparse Network for Time Series Classification: Learning What to "see''
written by Qiao Xiao, Boqian Wu, Yu Zhang, Shiwei Liu, Mykola Pechenizkiy, Elena Mocanu, Decebal Constantin Mocanu
(Submitted on 19 Dec 2022)
Comments: Accepted at Neural Information Processing Systems (NeurIPS 2022)
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
概要
この論文では、ハイパーパラメータの調整を必要とせずにさまざまな受容野(RF)サイズをカバーして学習できる時系列分類(TSC)用の動的スパースネットワーク(DSN)を提案します。DSN モデルは、単変量 TSC データセットと多変量 TSC データセットの両方で、最近のベースライン手法よりも少ない計算コストで最先端のパフォーマンスを実現します。
はじめに
時系列データを収集する際には、サンプリングレートやレコード長などのさまざまなばらつきが原因で、時系列に隠されたさまざまなスケーリングされた信号を発見して活用することが課題となります。 その主な理由は、サンプリングレートやレコード長など、時系列の収集時に自然に生じるいくつかの差異にあります。さらに、データ点の振幅オフセット、ワープ、オクルージョンも避けられません(Fig. 1参照)。そのため、特徴抽出に最適なスケールを決定することは困難ですが、TSCタスクでは重要です。主な解決策の1つは、時系列入力から有用な信号を無視しないように、できるだけ多くの受容野(RF)スケールをカバーすることです。
この論文では、より少ない接続数で密な相手と同等の性能を発揮できるスパースニューラルネットワークモデルに着想を得て、TSCタスクのために、大きくても動的なスパースカーネルを持つCNN層で構成され、様々なRFをカバーするという観点からスパース接続を自動学習できる動的スパースネットワーク(DSN)を提案しています。提案するDSNは、動的スパース学習(DST)戦略によって学習されるため、学習と推論にかかる計算コスト(例:浮動小数点演算(FLOPs))をも削減することが可能です。従来の動的スパース訓練法は、レイヤー単位で接続を探索するため、小さいRFをほとんどカバーできないが、ここではTSCのために、より細かいスパース訓練法を提案します。具体的には、各層のCNNカーネルはいくつかのグループに分割され、それぞれのカーネルはスパース訓練中に制約領域の下で探索することが可能です。
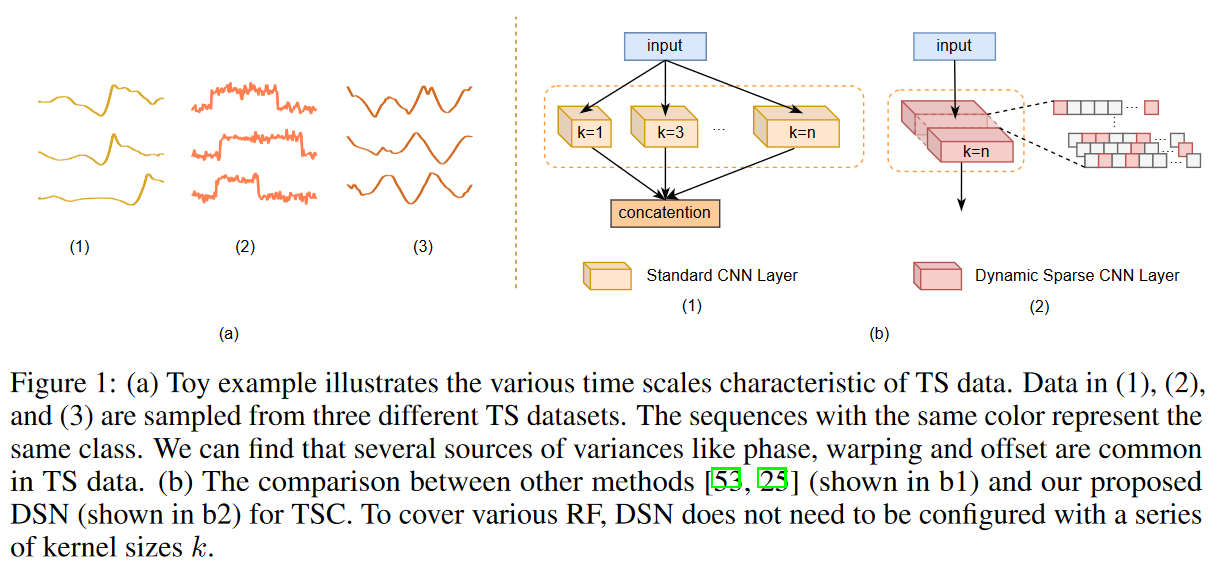
この論文の主な貢献は、ハイパーパラメータ調整を必要とせずにさまざまな受容野(RF)サイズをカバーすることを学習できる時系列分類(TSC)用の動的スパースネットワーク(DSN)の提案と、計算コストとメモリコストを削減するために動的スパーストレーニングによってトレーニングされるTSC用の新しいDSNモデルをネイティブに導入することです。提案された DSN モデルは、単変量 TSC データセットと多変量 TSC データセットの両方で、最近のベースライン手法よりも少ない計算コストで最先端のパフォーマンスを実現します。
関連研究
時系列分類
過去10年間の深層学習の成功は、研究者がTSCタスクへの応用を探求し、拡張することを奨励しています。単変量TSCでは、深層学習ベースのモデルは、畳み込みネットワークやリカレントネットワークを介して、生の時系列データを低次元特徴表現に直接変換しようとします。多変量TSCの場合、LSTMやアテンション層は、時系列データから補完的な特徴を抽出するために、しばしばCNN層と積層されます。近年、時系列データは様々なスケールの信号から構成されているため、よりスケーラブルな方法で特徴を抽出しようとする研究が多く行われています。主な解決策の一つは、適切なスケールを捕捉する確率を高めるように、様々なサイズの適切なカーネルを構成することです。ロケットベースの手法は、TSCの多様なRFをカバーするために、いくつかのサイズと拡張係数を持つランダムカーネルを使用することを目的としています。これらの研究とは異なり、ここで提案する動的スパースCNN層は、変形可能な拡張係数を用いて様々なRFを適応的に学習し、面倒なハイパーパラメータのチューニングなしに計算量とパフォーマンスの両方をトレードオフすることができます。
スパース訓練
近年、宝くじ仮説により、疎なサブネットワークを訓練することで、より少ない計算コストで密な対応ネットワークの性能に匹敵する性能を得ることが可能であることが示されました。最近の研究では、密なネットワークから繰り返しプルーニングを行うのではなく、学習中の勾配情報に基づく一発プルーニングする初期マスクを見つけようとします。プルーニングの後、ニューラルネットワークのトポロジーは訓練中に固定されることになります。しかし、この種のモデルは、高密度の対応するモデルが達成した精度にほとんど及びません。
宝くじ仮説の前に新しい学習パラダイムとして導入されたDSTは、疎なネットワークから出発し、学習中に固定数のパラメータで疎な接続性を動的に進化させることができます。現在、DSTは強化学習や継続学習などの他の研究分野からも注目を集めており、その可能性は高密度なニューラルネットワークの学習を凌駕するとされている。今回提案するDSNは、従来のDST手法とは異なり、TSCのより多様なRFを捉えるために、従来のレイヤーワイズ方式ではなく、きめ細かなスパース学習戦略で学習します。
適応受容野
学習中に適応的に変化させることができるRFは、多くの領域で有効であることが証明されています。適応的なRFは、通常、学習中に最適なカーネルサイズやカーネルのマスクを学習することで捉えることができます。しかし、カーネルもマスクもスパースではないため、より大きなRFが必要な場合には、計算量が膨大になる可能性があります。これらの方法とは異なり、DSNの動的スパースCNN層はDSTで学習することができ、変形可能な拡張係数を用いて可変のRFを捉えることを学習することができます。さらに、学習時および推論時のカーネルは常にスパースであるため、計算コストを削減することが可能です。
提案手法
問題定義
定義1. (Time Series Classification (TSC))
TSインスタンスX={X1,.Xn}∈Rn×mとし、ここでmは変量数、nは時間ステップ数を示します。TSCは、クラスラベルy∈{1、....c}をc個のクラスから正確に予測します。mが1に等しいとき、TSCは一変量であり、そうでないときは多変量です。
定義2. (Time Series (TS) Training Set)
訓練セットD={ (X(1), y(1)) , ...., (X(N), y(N))}とし、ここで、X(i)∈Rn×mは、ラベルy(i)∈{1, .... , c}に対応して単変量あるいは多変量のTSインスタンスです。
ここでは、すべてのインスタンスはTSデータセットにおいて同じ数の時間ステップを持つことに注意してください。一般性を失うことなく、訓練セットが与えられた場合、TSCタスクのために、低いリソースコスト(メモリや計算など)で、適応的で様々なRFを持つCNN分類器を訓練することを目的とします。
適応受容野付き動的スパースCNNレイヤー
様々なRFをカバーする簡単な戦略は、各CNN層でマルチサイズのカーネルを適用することですが、これにはいくつかの制限があります。第一に、異なるTSデータセットからのTSインスタンスは、ほとんどの場合、同じ長さとサイクルを持たないため、事前知識があっても、すべてのデータセットに対して固定カーネル構成を設定することは困難です。第二に、大きな受容野を得るためには、一般的に大きなカーネルやより多くのレイヤーを積み重ねる必要があり、より多くのパラメータが導入されるため、ストレージや計算コストが増加します。
これらの課題に対処するため、提案する動的スパースCNN層は、適応的なRFを獲得するために学習可能な、大きいがスパースなカーネルを有しています。具体的には、第l層の入力特徴マップxl∈Rcl-1×h×w(hは一変量TSCの時1、cl-1は入力チャンネル数)、カーネル重みΘl∈Rcl-1×cl×1×k(kはカーネルサイズ、clは出力チャンネル数)が与えられ、提案するダイナミックスパースCNN層のストライド1及びパディングによる畳み込みを、次式により定式化します。
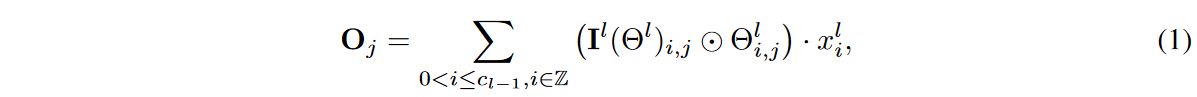
ここで、Oj∈Rh×wはj番目の出力チャネルにおける出力特徴表現を示し、Zは整数の集合を示し、Il(-).Rcl-1×cl×1×k → {0,1}cl-1×cl×1×kは指標関数、Il(Θl)i,jは(i,j)番目のチャンネルのカーネルである![]() の活性化重みを示し、
の活性化重みを示し、 は要素和積を示し、-は畳み込み演算子を示しています。提案DSNの学習時に学習される指標関数Il(-)は、
は要素和積を示し、-は畳み込み演算子を示しています。提案DSNの学習時に学習される指標関数Il(-)は、![]() を満足します。ここで0≦S<1は疎密比です。
を満足します。ここで0≦S<1は疎密比です。 ![]() はL0ノルム, Nl=cl-1×cl×1×kを表します。 S>0のとき、カーネルはスパースであり、動的スパースCNN層で大きなkを用いることで、計算量を減らして大きなRFが得られます。
はL0ノルム, Nl=cl-1×cl×1×kを表します。 S>0のとき、カーネルはスパースであり、動的スパースCNN層で大きなkを用いることで、計算量を減らして大きなRFが得られます。
Effective Neighbour Receptive Fieldサイズ
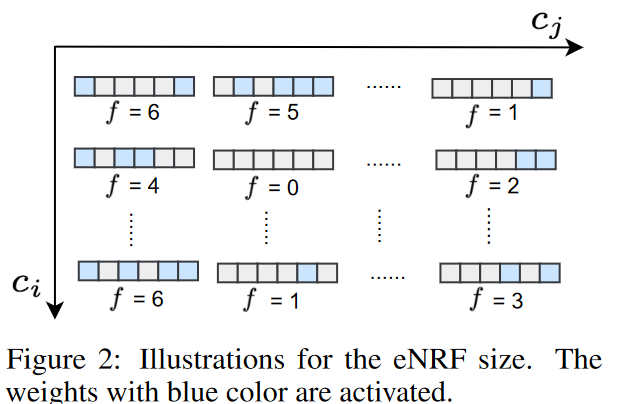
受容野は、CNNモデルの特徴が見ている入力中の領域として定義されます。連続する層の各特徴が見ている領域をNRF(Neighbour Receptive Field)と定義しています。具体的には、NRFのサイズは標準的なCNN層のカーネルサイズに相当します(dilationが1に等しい場合を考慮する)。ただし、カーネル内の最初または最後の重みが活性化されていない場合、提案された動的スパースCNN層のNRFサイズはカーネルサイズよりも小さくなります。例えば、∃i ∈ {1, .... cl-1}、j∈{1,.cl}、Il(Θl)i,j,1,1=0またはIl(Θl)i,j,1,k=0。Fig. 2に示すように、カーネル![]() のeNRFサイズ
のeNRFサイズ![]() を、l番目のCNN層における最初の活性化重みと最後の活性化重みの間の距離として、
を、l番目のCNN層における最初の活性化重みと最後の活性化重みの間の距離として、
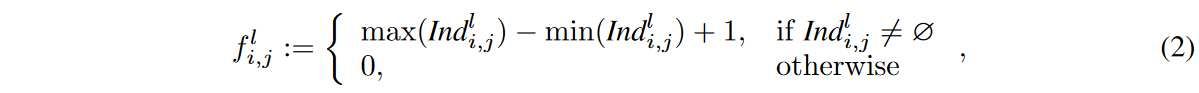
ここで![]() はカーネル
はカーネル![]() の非ゼロ重みに対応するインデックスの集合を表します。明らかに
の非ゼロ重みに対応するインデックスの集合を表します。明らかに![]() となります。
となります。
l番目の動的スパースCNN層のeNRFサイズセットはF(l)と表記され、0≦min(F(l))、max(F(l))≦kを満たします。Fig. 2のl番目の層の場合を簡単に例にすると、F(l)={0、1、2、3、4、5、6}とします。各ダイナミックスパースCNN層は1からkまでの様々なeNRFサイズに対応していると考えられます。グローバルな情報を期待する場合、Il(-)はより大きなeNRFを得るために重みを分散して活性化し、入力特徴を選択的に利用することが出来ます。一方、局所的な文脈を捉える場合は、eNRFが小さくなるため、活性化される重みは集中する傾向にあります。k = 5を例にとると、Il(Θl)i,jはグローバルコンテキストでは[1, 0, 1, 0, 1]、ローカルコンテキストでは[0, 0, 1, 1, 0]となる可能性があります。このように、eNRFを適応的に調整することができます。
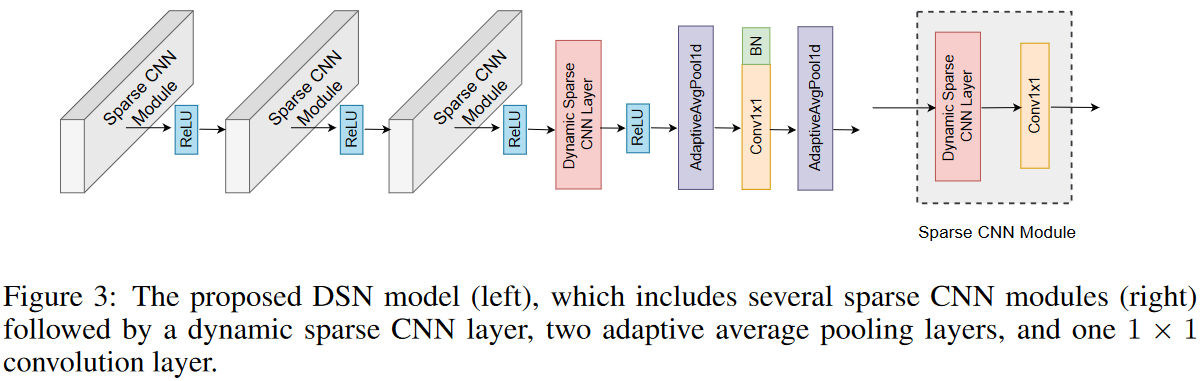
DSNのアーキテクチャ
提案するDSNモデルは、3つのスパースCNNモジュールで構成され、各モジュールは動的スパースCNN層と1×1 CNN層で構成されます。積層されたスパースCNNモジュールに続いて、追加の動的スパースCNN層、2つの適応的平均プーリング層、そしてDSNモデルの分類器として機能する1×1畳み込み層があります。全体的なアーキテクチャをFig. 3 に示します。
1×1畳み込みのeNRFサイズは常に1に等しいので、l番目のスパースCNNモジュールのeNRFサイズの集合S(l)は、動的スパースCNN層のそれと等しく、S(l)は、0≦min(S(l))、max(S(l))≦kを満たす。そして、連続的に積まれた3つのスパースCNNモジュールのeNRFサイズ集合はRFによって、次のように記述することができます。
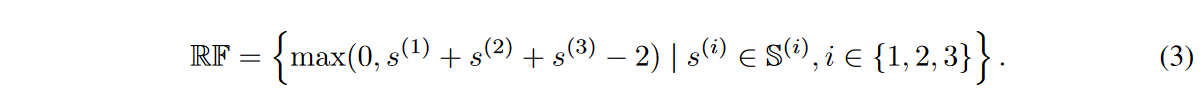
式(3)によると、複数のスパースCNNモジュールを積み重ねることで、RFのサイズを直線的に増加させることができ、l番目の動的スパースCNN層はS(l)のサイズだけ増加することがわかります。簡単のため、本研究では各ダイナミックスパースCNN層のカーネルサイズは一貫してkに設定されています。そして、RFはmax(RF) ≦ 3k - 2、0 ≦ min(RF)を満たします。したがって、スパースCNNモジュールのkを大きくすることで、スタックしたスパースCNNモジュールのeNRFサイズの幅を広げることができます。
DSNモデル用の動的スパース訓練
本節では、性能の良いRFを確保するために活性化させる必要がある重みを発見するための学習戦略を示します。つまり、提案するDSNの学習中に指標関数Il(-)をどのように更新するかを検討する必要があります。
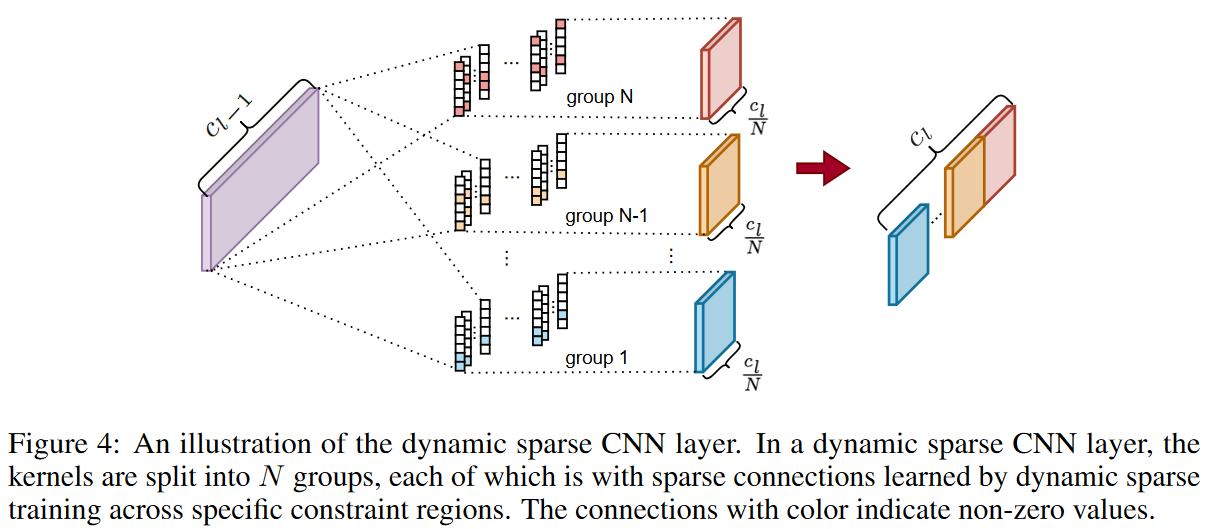
DST法の主要な考え方に従って、カーネルをスパースに保つために、提案するDSNモデルをゼロからスパースに訓練する。設計上、訓練段階では、活性化された重みの総数がNl(1 - S)を超えないようにしなければなりません。しかし、ここでは、特にスパース比Sが小さい場合、活性化された重みをレイヤーごとに発見するレイヤーワイズ探索方式のDST法では、小さなeNRFを捕らえることが難しいことを観察しました。この観察に基づき、各ダイナミックスパースCNN層のカーネルは、Fig. 4に示すように、異なるグループに分けられ、その対応する探索領域は異なる大きさです。DST法とは逆に、DSNでは、活性化された重みの探索は異なるカーネルグループで別々に行われ、これはよりきめ細かな戦略です。具体的には、第l層のカーネル重みΘl∈Rcl-1×cl×1×kを出力チャネルに沿ってN個のグループに分割します。すなわち、![]() と、対応する探索領域
と、対応する探索領域![]() 。第l層の第iグループの探索領域
。第l層の第iグループの探索領域![]() は、このグループ内の各カーネルの最初の
は、このグループ内の各カーネルの最初の![]() 個の位置と定義されます。k=6、N=3を例にとると、最初のグループの活性化された重みは
個の位置と定義されます。k=6、N=3を例にとると、最初のグループの活性化された重みは![]() の各カーネルの最初の2つの位置の中にしかないが、最後のグループではカーネル全体の中にあります(Fig. 4に示すように)。このようにして、様々なeNRFをカバーし、探索空間を縮小することができ、探索効率を向上させることができます。
の各カーネルの最初の2つの位置の中にしかないが、最後のグループではカーネル全体の中にあります(Fig. 4に示すように)。このようにして、様々なeNRFをカバーし、探索空間を縮小することができ、探索効率を向上させることができます。
重み探索領域![]() とスパース比Sが与えられたら、アルゴリズム1(原論文参照)に示すように、提案するDSNモデルを訓練します。活性化された重みは探索領域内で探索され、∆t反復ごとに更新されます。更新された重みの割合は、コサインアニーリングの関数fdecay (t; α, T)に従って時間と共に減衰し、以下のようになります。
とスパース比Sが与えられたら、アルゴリズム1(原論文参照)に示すように、提案するDSNモデルを訓練します。活性化された重みは探索領域内で探索され、∆t反復ごとに更新されます。更新された重みの割合は、コサインアニーリングの関数fdecay (t; α, T)に従って時間と共に減衰し、以下のようになります。
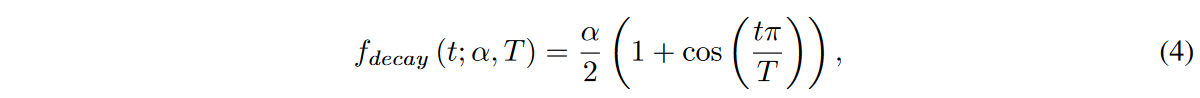
ここで、αは更新された活性化重みの初期割合、tは現在の学習反復、Tは学習反復の回数です。したがって、t回目の反復の間、l番目の層のi番目のグループにおける更新された活性化された重みの数は、![]() nであり、
nであり、![]() は領域
は領域![]() において探索できる重みの数です。活性化された重みの更新中、 まず,
において探索できる重みの数です。活性化された重みの更新中、 まず,![]() で決められた活性化された重みを刈り取り、続いて
で決められた活性化された重みを刈り取り、続いて![]() でランダムに新しい活性化重みを生成します。ここでArgTopK(v,u)はベクトルvのうち値の大きい上位u個の要素のインデックスを与え、RandomK(v,u)は、ベクトルvにおいてランダムなu要素のインデックスを出力し、
でランダムに新しい活性化重みを生成します。ここでArgTopK(v,u)はベクトルvのうち値の大きい上位u個の要素のインデックスを与え、RandomK(v,u)は、ベクトルvにおいてランダムなu要素のインデックスを出力し、![]() は、
は、![]() を除く
を除く![]() 内の重みを示します。
内の重みを示します。
活性化された重みの探索は簡単です。まず、大きさの小さい重みを刈り込むことは直感的です。なぜなら、大きさの小さい重みの寄与は重要でないか、あるいは無視できるからです。また、刈り込みの回復性を考慮し、刈り込まれた重みと同じ数の新しい重みをランダムに再生することで、より良い活性化重みの探索を実現します。このように、学習前後に重みを刈り込む方法と比較して、重みの探索は動的で可塑的です。
実験
データセット
各データセットの詳細は以下の通りです。
- UCR 85アーカイブの単変量TSデータセット: このアーカイブは、様々なドメイン(例:ヘルスモニタリングやリモートセンシング)から収集され、特徴的な特性を持ち、様々なレベルの複雑さを持つ85個の一変量TSデータセットで構成されています。トレーニングセットのインスタンス数は16から8926、時間ステップ分解能は24から2709の範囲です。
- UCIからの3つの多変量TSデータセット: EEG2データセットには、2つのカテゴリと64の変量からなる1200のインスタンスが含まれています。Human Activity Recognition (HAR)データセットは、6カテゴリ、10,299インスタンスからなり、変量数は9、Daily Sportデータセットは、19カテゴリ、9,120インスタンスからなり、変量数は45です。
実験設定と実装の詳細
最適化にはAdam optimizerを用い、初期学習率は3×10-4、コサイン減衰は10-4としました。16のミニバッチサイズで1,000エポック学習しています。カーネルグループの数Nは、小、中、大のeNRFをカバーするのに役立つ3つに設定されています。各設定を5回繰り返し、その平均結果を報告します。
結果と分析
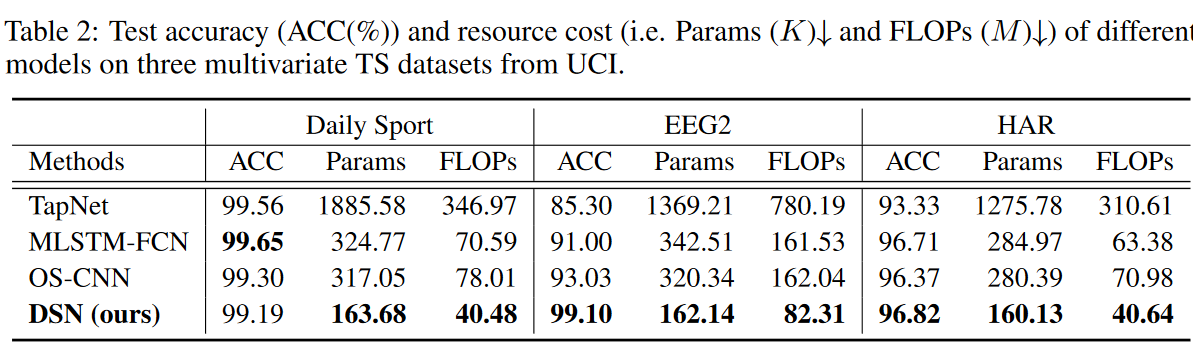
単変量および多変量のTSCベンチマークにおける性能をTable 1-2に示します。単変量TSCでは、UCR 85アーカイブデータセットにおいて、より少ないパラメータ数(例えばParams 3)と少ない計算コスト(例えばFLOPs)で、ほとんどのケースで提案する手法がベースライン手法を上回っていることが分かります。多変量TSCでは、提案するDSN法はEEG2とHARデータセットでより良い性能を達成し、Daily SportではMLSTM-FCNが0.46%高精度でした。提案するDSNのリソースコスト(ParamsとFLOPs)は、ベースライン手法のリソースコストよりもはるかに小さいです。

感度分析
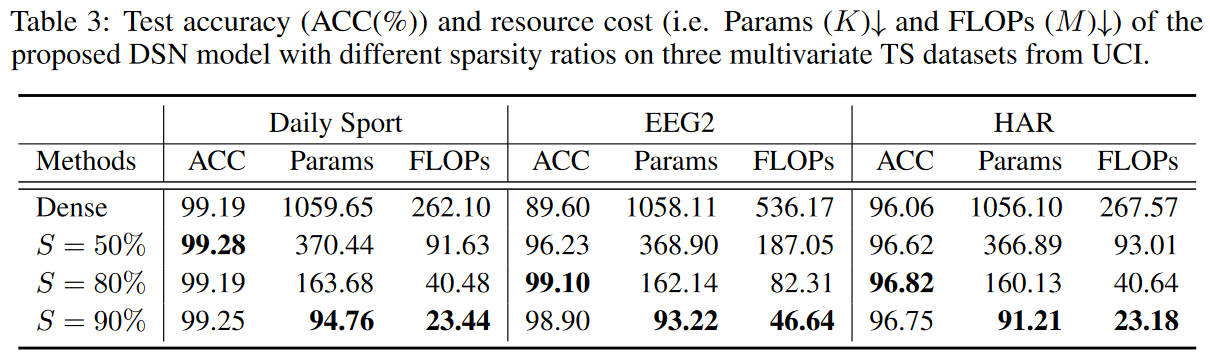
スパース比の効果
Table 3から、多変量TSデータセットにおいて、動的スパースCNN層のスパース比が最終的なテスト精度とリソースコストにどのように影響するかを知ることができます。ここでは、様々なスパース比(S∈[50%, 80%, 90%])と密なDSNモデルの下でテスト精度とリソースコストのトレードオフを分析します。なお、密なモデルとは、カーネル全体が密に接続されたDSNモデルと全く同じように定義されています。モデルのパラメータが多ければ多いほど性能が向上するわけではないことがわかります。これは主に、パラメータを増やすとオーバーフィッティングにつながるためで、適切なスパース比であれば、目的の受容野を容易にカバーすることができます。EEG2データセットを例にとると、スパース率の減少に伴い、その性能は急激に低下していまする。このデータセットは、小さな受容野からの特徴量に期待するところが大きいと考えられます。実験によると、80%のスパース率は精度とリソースコストの間の良いトレードオフを反映しており、これはここでのDSNモデルの動的スパースCNN層のデフォルト設定です。
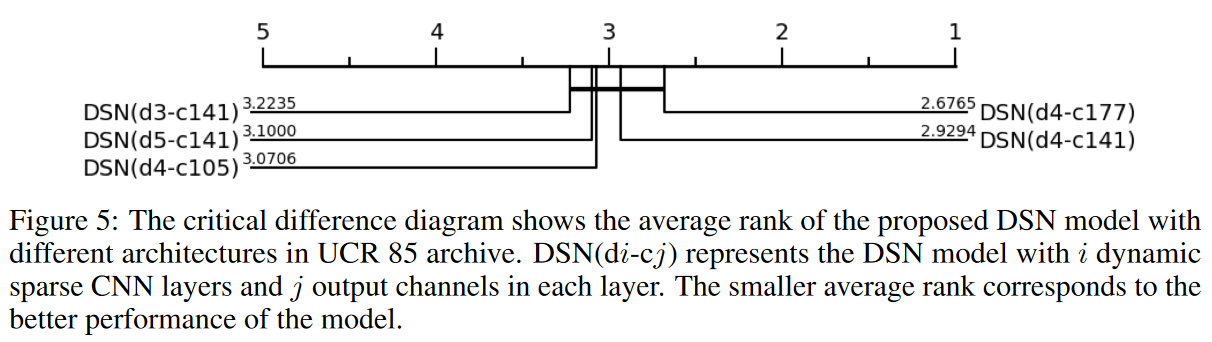
アーキテクチャーの効果
DSNのアーキテクチャが最終的な性能にどのように影響するかを示すために、TSCの評価に通常用いられる臨界差分図を採用して詳細に比較します。Fig.5から、4つの動的スパースCNN層と各層に177の出力チャンネルを持つDSNモデルは、他の構造よりも一貫して優れた性能を発揮していることがわかります。出力チャンネルを増やした提案モデルは、ネットワークの容量を維持するために重要であるようですが、他のモデルと比較して、より多くのパラメータとFLOPsを必要とします。このことは、精度と計算効率の間の興味深いトレードオフを浮き彫りにしています。実験によると、4つの動的スパースCNN層と各層の141の出力チャンネルを持つDSNモデルは、性能とリソースコストの間のトレードオフであり、これはここでのDSNモデルのデフォルト設定です。
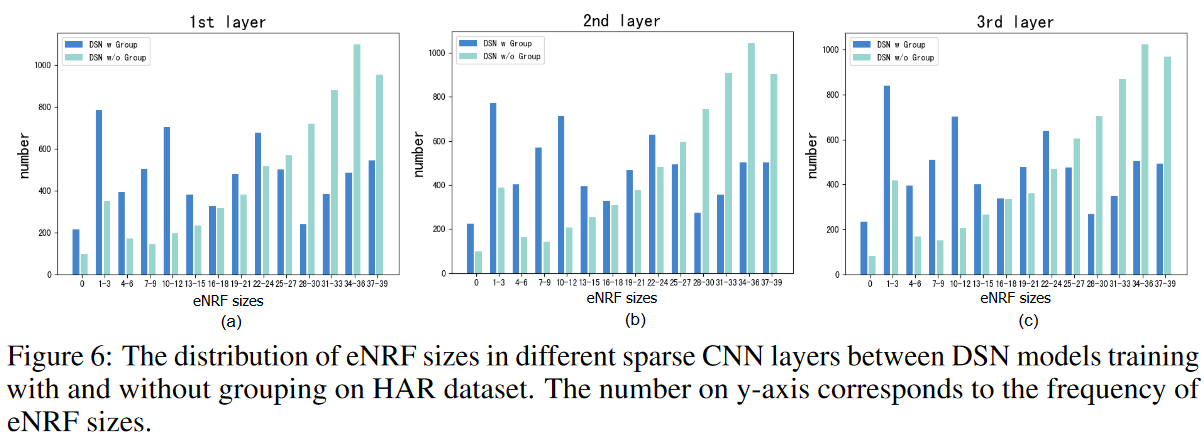
カーネルグループの効果
Fig. 6に示すように、カーネル群を用いないDSNの学習は、小さなeNRFの捕捉に支障をきたし、EEG2のように局所的な情報を期待するデータセットにおいて満足な性能を保証することができません。また、スパース比Sを小さくすると、大きなRFが大部分を占める現象がより深刻になり、Table 4に示すように、グループありの訓練とグループなしの訓練の性能差が大きくなっています。カーネルをグループ化することで、すべてのデータセットで様々なRFカバー率や広告の精度を実現できます。

切り分け研究
動的スパース訓練の効果
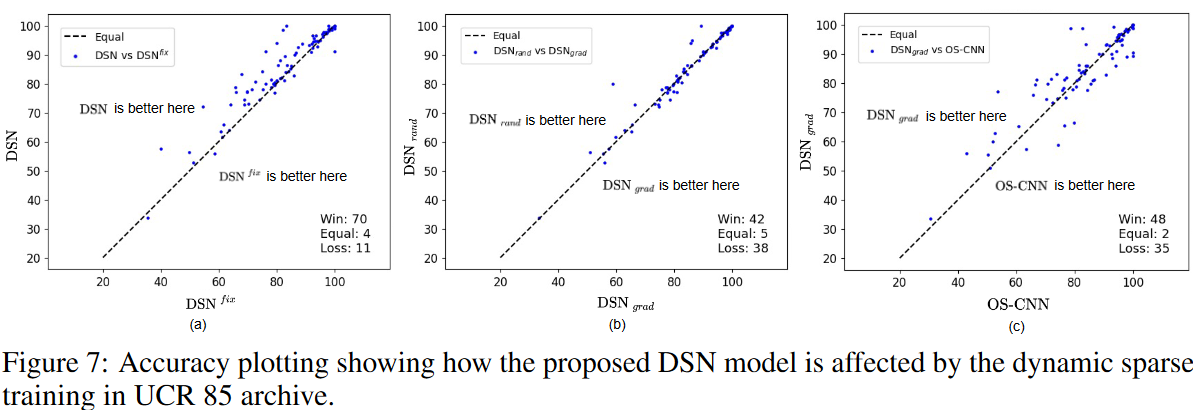
さらに、DSN法における動的スパース訓練の効果についても研究しています。DSNを、活性化された重みの初期化後に訓練中にトポロジーを固定する静的な変形(すなわちDSNfix)と比較するためにアブレーション研究を実施しました。つまり、式(1)の指標関数Il(-)は、学習中に更新されません。Fig. 7(a)に示す結果によれば、UCR 85アーカイブにおいてDSNモデルはDSNfixをほとんど上回っており、動的スパース学習によって学習されるのは、適切な活性化重みとその値であることが分かります。
他のDST手法でのケーススタディ
同様に、RigL のような他のDST手法の存在下でも、提案するDSN手法の有効性を分析しました。RigLはランダムに重みを成長させるのではなく、最も大きい勾配で重みを成長させます。Fig. 7(c)から、勾配に従って重みを成長させること(すなわちDSNgrad)は、UCR 85アーカイブのほとんどのケースで、OS-CNN法を上回ることができることがわかります。さらに,Fig. 7 (b) に示すように,DSNgrad はランダムに重みを成長させる方法 (DSNrand) と同等の性能を持つことが分かります.なお、DSNrandは、任意のタイミングで完全な勾配を計算する必要がないという理由で、本論文で提案する方法の主な設定です。まとめると、きめ細かいスパース戦略を持つ提案DSNは、既存のDST手法と容易に組み合わせることができ、将来的に他の先進的なDST手法と融合することでさらなる改善の可能性を示しています。
活性化重みの可視化
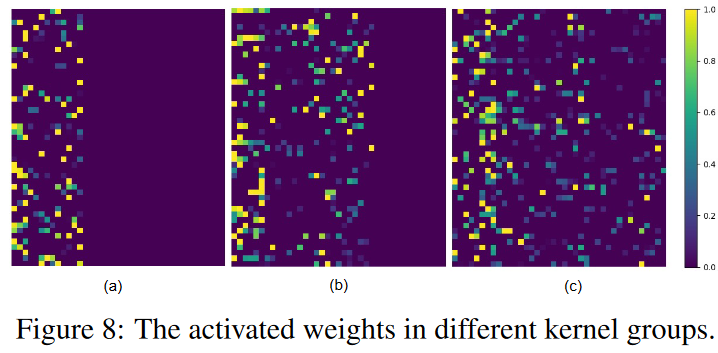
Fig. 8は、HARデータセットでスパース学習を行った後のDSNモデルの正規化活性化重みを示します。(a)、(b)、(c)は最初の動的スパースCNN層の3つのカーネル群の活性化した重みに対応し、図の各行は1つのカーネルを表します。各カーネルの重みはスパースであり、前に定義した制約領域内で活性化できることがわかります。
まとめ
この論文では、ハイパーパラメータの調整を必要とせずにさまざまな受容野(RF)サイズに対応できるよう学習できる時系列分類(TSC)用の動的スパースネットワーク(DSN)を提案しています。DSN モデルは、単変量 TSC データセットと多変量 TSC データセットの両方で、最近のベースライン手法よりも少ない計算コストで最先端のパフォーマンスを実現します。提案されたDSNモデルは、資源認識とTSCのさまざまな効果的な隣接受容野カバレッジとの間のギャップを埋めるための実行可能なソリューションを提供し、さまざまな分野の他の研究者に刺激を与える可能性を秘めています。





この記事に関するカテゴリー






