GARCHでボラティリティ予測!
3つの要点
✔️ GARCHを用いたボラティリティ予測
✔️ インドの国立証券取引所(NSE)に上場している10銘柄のボラティリティー予測
✔️ 非対称GARCHモデルが対称GARCHモデルより高精度
Volatility Modeling of Stocks from Selected Sectors of the Indian Economy Using GARCH
written by Jaydip Sen, Sidra Mehtab, Abhishek Dutta
(Submitted on 28 May 2021)
Comments: Accepted at IEEE ASIANCON'2021.
Subjects: Computational Finance (q-fin.CP); Machine Learning (cs.LG); Statistical Finance (q-fin.ST)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめ
ボラティリティークラスターは、株式市場の挙動に大きな影響を与える重要な特性です。
本論文では、インドの国立証券取引所(NSE)に上場している10銘柄のボラティリティーをモデル化するために、一般化自己回帰条件付き異種共分散(GARCH)フレームワークに基づいたいくつかのボラティリティーモデルを提示します。
銘柄は、インド経済の自動車セクターと銀行セクターから選ばれており、NSEにおける各セクターのセクターインデックスに大きな影響を与えています。本論文では、一般化自己回帰条件付き異種共分散(GARCH)のアプローチに基づいた一連のボラティリティモデルを紹介します。
2010年1月1日から2021年4月30日までのNSEの過去の株価データを用いてインド経済の重要な2つのセクター、自動車セクターと銀行セクターからそれぞれ上位5銘柄を選びモデルを構築します。いくつかのGARCHモデルを構築し、微調整を行った後、アウトオブサンプルのデータでバックテストを行いました。
この研究には2つの特徴があります。
一つ目は、インド株式市場の様々なセクターの10年以上に渡る実世界の株価データを用いて、構築、微調整、バックテストを行った一連のGARCHモデルを提案しています。
二つ目に、本研究で研究されている2つのセクターのボラティリティーを比較するベンチマークを提供します。
2つのセクターのボラティリティーを正しく知ることで、潜在的な投資家はセクターの関連するリスクとリターンを理解することができます。
関連する研究
GARCH (1,1) フレームワークに基づいたかなりの数のモデルが提案されており、これらのモデルの残差の一般化された分布は、他の残差のモデルよりも系列のボラティリティを評価する上でより正確であることが観察されています 。いくつかの研究では、非対称GJR-GARCHモデルは、ボラティリティが高いときに条件付き分散に関するより正確な予測を生成することを発見しましたが、実世界ではほとんど、EGARCHモデルは、非対称ボラティリティの状況でより正確な予測を生成します。
GARCHベースのボラティリティモデルは、より安定したロバストな予測をもたらす一方で、エントロピーベースの予測のsensitiveはより高いことが観察されています。インド経済の15の重要なセクターのリターン分析は、ディープラーニングに基づくLSTMネットワークモデルの予測出力に基づいて行われています。
この研究では、FMCGセクターが最も収益性の高いセクターであることに変わりはありませんが、電力セクターの集約的なリターンが最も低いことが明らかになりました。また、複数の同時期の時系列のボラティリティを分析するために、多変量GARCHモデルが提案されています。
データと方法論
この研究で行った方法論は、10のステップで構成されています。以下では、それぞれのステップについて詳しく説明します。
データの抽出
panadasモジュールのDataReader APIを使用して、Yahoo Financeウェブサイトから株価データを抽出する。
例えば、NSEに上場しているマルチ・スズキの株価記録をYahoo Financeのウェブサイトから開始日から終了日まで、高値、安値、始値、終値、出来高、調整終値の属性で抽出する場合、必要なpythonコードは次の通りです。 maruti = web.DataReader ('MARUTI.NS', 'yahoo', start, end)[['High', 'Low', 'Open', 'Close', 'Adj Close']]. すべての銘柄について、開始日を2010年1月1日、終了日を2021年4月30日としています。
ハースト指数とボラティリティーの計算
株価の記録を抽出した後、終値の時系列のハースト指数を計算します。ハースト指数とは、時系列の長期的な挙動を示す指標です。これは、時系列の異なるラグの値の間の自己相関を測定し、ラグの値とともに自己相関が減少する割合を計算します。これらの計算に基づいてハースト指数は、時系列が平均値に強く回帰しているか、あるいは上昇から下降の方向に向かってクラスター化しているかを判断する指標を算出する。ここでは、最大100個のラグで自己相関を計算する関数を用いて、全銘柄のHurst指数を計算しています。
株価の終値指数に基づいて銘柄のハースト指数を計算した後、シリーズのボラティリティを計算します。
日次ボラティリティは、日次リターン値の標準偏差を計算することによって決定されます。月間ボラティリティーと年間ボラティリティーは、月に21日、年に252日の営業日があると仮定して、日々のボラティリティーにそれぞれ21の平方根と252の平方根の係数を乗じて計算されます。
return系列とlog return系列の統計的性質の検討
このステップでは、return系列とlog return系列を計算する。
return 系列の計算には、Python の pct_change 関数を使用する。log return series は、まず銘柄の終値に log 関数を適用して計算します。return系列、log return series、それらのQ-Q(Quantile-Quantile)プロット、自己相関関数(ACF)プロット、部分自己相関関数(PACF)プロットを行う。
一定の平均と正規分布の残差を持つGARCH(1,1)モデルのフィッティング
このステップでは、株価の時系列に対するボラティリティモデルを構築します。まず、平均値が一定で残差が正規分布しているGARCH(1,1)を構築します。このタイプのGARCHモデルは、(1)のように表すことができます。
第1項のωは長期平均ボラティリティに対応する一定の分散を表し、係数αはt-1時点での残差値の2乗の効果を表し、係数βはt-1時点での分散がt時点でのボラティリティに与える効果を表します。
![]()
GARCHモデルでは、残差をボラティリティ・ショック(急激な変化)として使用します。このステップでのGARCH (1,1) モデルでは、残差はゼロ平均の正規分布に従うと仮定します。時間tでの残差は、(2)で与えられます。
(2)では、時間的瞬間tにおけるリターンを表し、return系列の平均値である。
![]()
平均値が一定で残差が正規分布するGARCH(1,1)モデルをフィットさせました。GARCHモデルのパラメータω、α、βの値と、それぞれのp値を決定します。また、モデルの※赤池情報量規準(AIC)も判明します。
※赤池情報量規準...統計的モデルの予測性の良さを、観測値と理論値の差(残差)を用いて評価する統計量。値が小さいほど当てはまりが良いと言える。
平均値が一定で、残差が歪t分布しているGARCH(1,1)モデルのフィッティング
株式リターンとlog returnの値は通常、正規分布に従わないので、残差が正規分布ではなく、歪んだt分布に従うと仮定して、ステップ4で構築したGARCHモデルを微調整します。
また、GARCH(1,1)モデルの日次リターンに対する歪t誤差分布のボラティリティーをプロットして、GARCH(1,1)モデルがどれだけ正確であるかを検証しました。
log return系列に対する最適なARMAモデルの特定
このステップでは、株価の対数リターンシリーズに最もフィットする自己回帰移動平均(ARMA)モデルを見つけます。
ARMA残差のGARCH(1,1)へのフィッティング モデルを作成
最適なARMAモデルをlog returnシリーズにフィッティングし シリーズにフィッティングされ、ゼロ平均を持つGARCH (1,1) モデル(残差がゼロ平均を持つと仮定されるため)が、ARMAモデルの残差に適合されます。
このとき GARCHモデルの要約関数を使って、我々は パラメータω、α、βとそれらに対応するp値を求めます。また モデルのAICも記されています。p値の有意水準は、モデルの適合性を示しています。
return seriesに非対称ボラティリティモデルをフィッティングし、モデルの適合性を評価
前のステップで構築したGARCHモデルは、ポジティブなニュースとネガティブなニュースがボラティリティに同じような影響を与えると仮定しています。この仮定は現実世界では通用せず、リターンのボラティリティに対するネガティブなニュースの影響はポジティブなニュースの影響よりも大きくなります。
rerurn seriesのボラティリティを効果的にモデル化するためには、GARCHモデルは影響の非対称性を処理する機能を持っていなければなりません。
このために、(i)GJR-GARCHと(ii)EGARCHという2つの非対称モデルを構築します。
GJR-GARCH(1,1,1)モデルは、(3)で与えられる。(3)において、γは非対称なパラメータであり、d_(t-1)はダミー変数である。前時刻の残差が負であれば、ダミー変数の値は1となり、前時刻の残差が正であれば、ダミー変数の値は0となる。
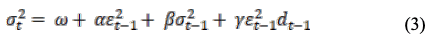
EGARCH(1,1,1)モデルは(4)のように与えられます
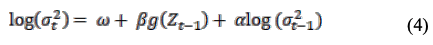
(4)では、関数の値を次のようにして評価します。
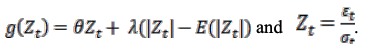
θ = 0の場合は、ショックが大きいほど条件付き分散は大きくなる。(Z_t - E[Z_t]>0)であれば、条件付き分散は減少する。
また、ショックが平均値よりも小さい場合、分散のショックは正となるGJR-GARCHとEGARCHモデルの予測ボラティリティー値とリターンシリーズをプロットし、予測ボラティリティー値がリターンシリーズの実際のボラティリティー値に対してどれだけ近いかを確認します。
EGARCH ボラティリティーの精度を検証する の予測
このステップでは、拡大窓法と固定窓法という2つの異なる予測法を使って、予測値を計算します。このステップでは、expanding window method とfixed window method という2つの異なる予測法を用いて 2021年1月1日から2021年4月30日までのアウトオブサンプルデータに対して、EGARCHモデルによる予測ボラティリティを算出します。
fixed window method では、過去5日間のボラティリティーに基づいて次の5日間のボラティリティーの値を予測します。expanding window method では、学習窓の大きさは、予測のラウンド数に応じてトレーニングウィンドウのサイズが大きくなります。最後に、予測されたボラティリティーの値と ボラティリティーの予測値と実際のボラティリティーをプロットします。
アウトオブサンプル・データでのEGARCHモデルのバックテスト
最後のステップでは、我々はリターンシリーズに対するEGARCHモデルのバックテストを行います。リターンシリーズに対するEGARCHモデルのバックテストを行い、平均絶対誤差(MAE)を計算します。
実験結果
GARCHに基づいた様々なボラティリティーモデルのパフォーマンスに関する広範な実験結果を示します。
自動車セクター
NSEに上場している自動車セクターの上位5銘柄 NSEに上場している自動車セクターの上位5銘柄は Maruti Suzuki India (MSZ)、Mahindra and Mahindra (MAH)、Tata Motors (TAM)、Mahindra and Mahindra (MAH)。and Mahindra (MAH), (iii) Tata Motors (TAM), (iv) Bajaj オート(BAJ)、ヒーロー・モトコープ(HMC)です。これら5社のそれぞれの 自動車セクター指数の計算に使用されたこれら5銘柄のそれぞれのウエイトの割合は以下のとおりです。MSU-18.72, mmh-15.72, tmo-11.50, baj-10.89, hmc-7.99 .
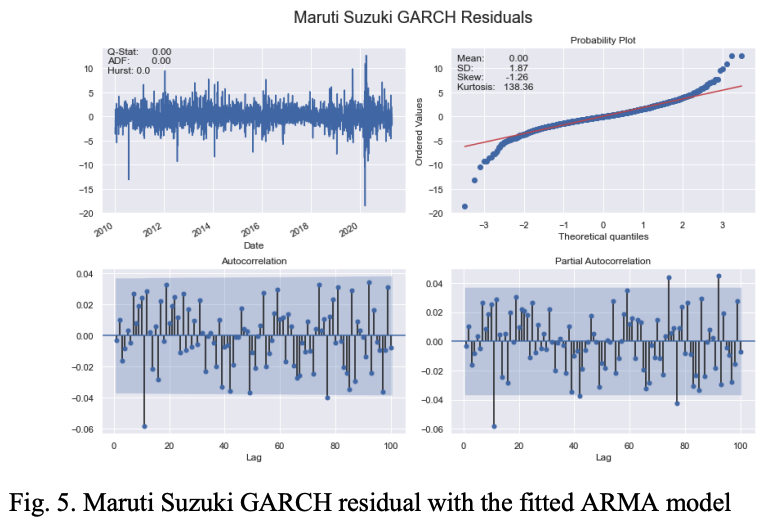
各セクターの最上位銘柄のビジュアルのみを表Iに示します。また図1は、マルチ・スズキ株のlogr returnシリーズの重要な特徴を示しています。
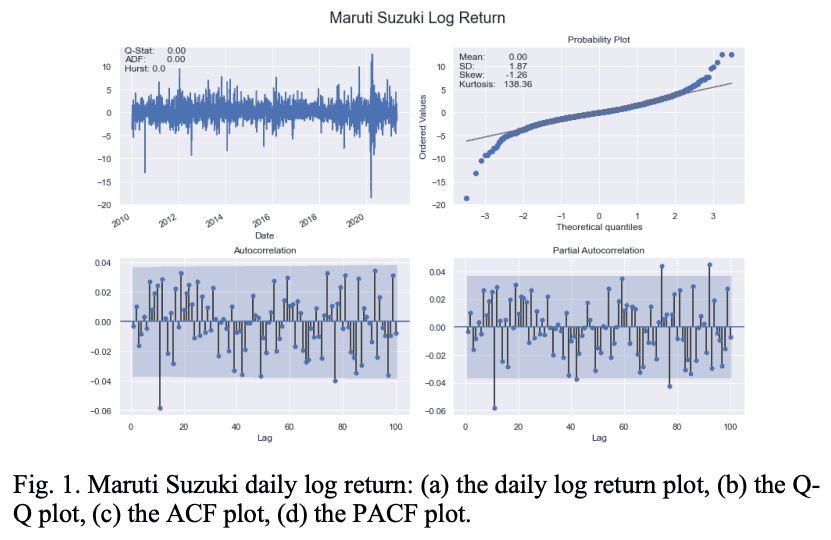
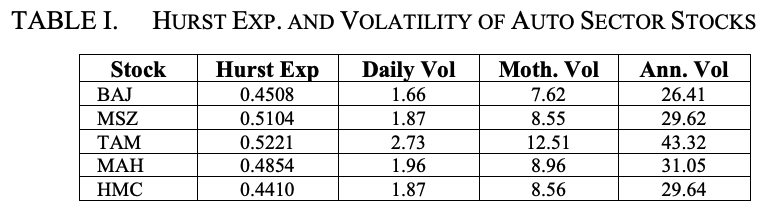
図2は、マルチ・スズキの日次ボラティリティー・シリーズの特性を示しています。
表Ⅰを見ると、BAJ、MAH、HMCの3銘柄は 表1から、BAJ、MAH、HMCの銘柄は平均回帰的な特性を示し、MSZとTAMのシリーズは 一方、MSZとTAMのシリーズは、ハースト指数から見て穏やかな平均回帰特性を示している。
表IIと表IIIは、自動車セクター銘柄のlog returnシリーズと、log returnシリーズの日次ボラティリティの重要な統計的特性を示している。表IIから、すべての銘柄のlog returnシリーズの平均値はゼロであるが、TAMの標準偏差、歪度、および尖度が最も高いことが明らかである。
同じ観察が表IIIにも記されている。
したがって、TAMは自動車セクターの中で最もボラティリティの高い銘柄であると結論づけられる。一方、BAJは、このセクターで最も低いボラティリティを示すことがわかった。
日次log return系列と日次ボラティリティ系列のACFとPACFプロットは、いずれもラグの値が大きいほど有意であることがわかった。ACFとPACFのグラフをラグの最大値である100に対してプロットしたところ、これらのプロットは大きなラグで有意であることがわかりました。
次に、平均値を一定とし、ボラティリティモデルをGARCHとし、誤差分布を正規分布として、returnシリーズにGARCH(1,1)モデルをフィットさせます。表Ⅳは、自動車セクターの5銘柄のリターン・シリーズに対するGARCH(1,1)モデルのフィッティングの結果を示しています。表Ⅳの列はそれぞれ、銘柄名(Stock)、リターンシリーズのデータにモデルを当てはめるのに必要な反復回数(#Iterations)、関数(=対数尤度関数)の評価回数(Func Eval)、勾配の更新回数(Grad Eval)、対数尤度関数の値(Log-Likelihood)を示しています。
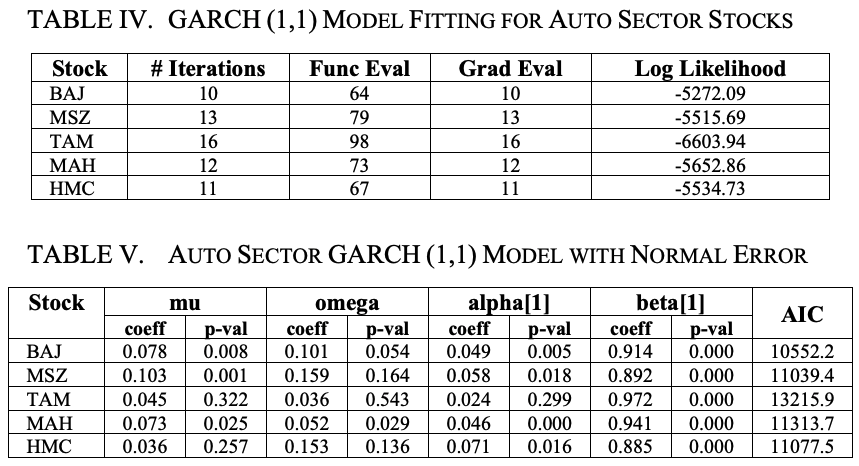
表Vは、平均値が一定で、誤差が正規分布しているGARCH(1,1)モデルの概要を示しています。
パラメータmuは一定の平均、omegaは長期平均ボラティリティに対応する一定の分散、alphaは前のラウンドでは得られなかった今回のラウンドでの新しい情報、betaは前期の予測ボラティリティを意味しています。
αの値が大きいほど、ショックの影響は大きくなります。一方、ベータ値が大きいほど、ショックの持続時間が長くなります。
表Vでは、MSZではアルファ値が最も高く、TAMでは最も低いことが観察されている。したがって、ショックの影響は、MSZで最も大きく、TAMの株式では最も小さい。一方、ベータ値に基づくと、ショックの継続時間はTAMが最も長く、HMCが最も短いことがわかった。
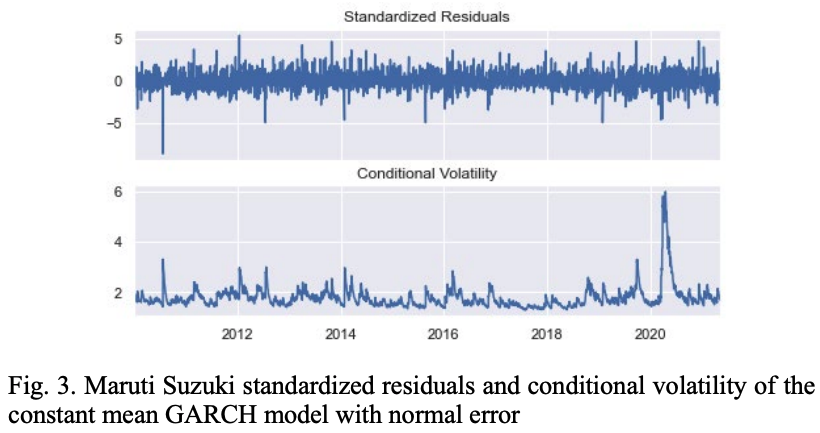
図3は一定の平均と正規分布の残差を仮定したGARCH(1,1)モデルで計算されたMSZ株の標準化残差と条件付ボラティリティのパターンを示しています。
次に、誤差モデルを正規から歪んだものに変更します。金融時系列では、残差はほとんどの場合、正規分布ではないため、残差が歪t分布に従うという仮定は 歪んだt分布に従うという仮定がより現実的です。
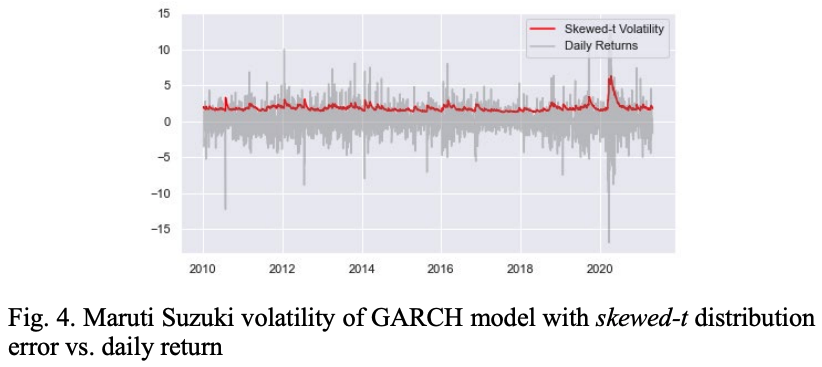
図4はskewed-t分布の残差を持つGARCHモデルのボラティリティとMSZ株の日次リターン値を比較したものです。
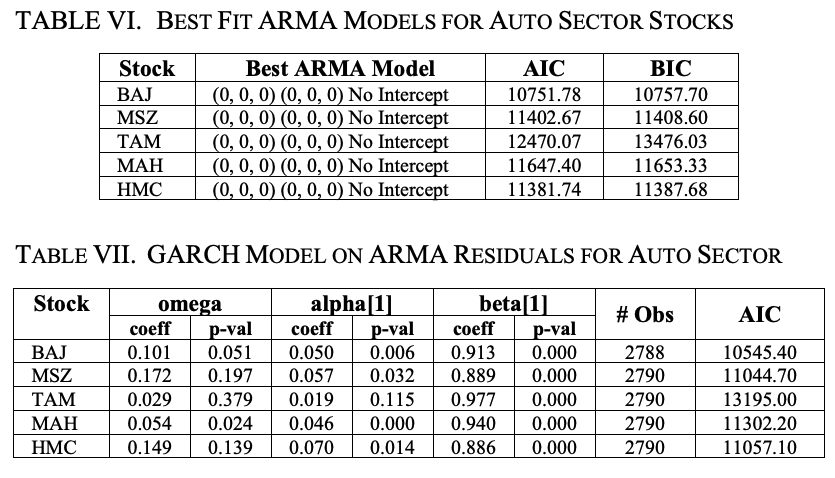
GARCH(1,1)モデルをさらに改良するために、株価の終値のlog returnをARMAモデルでモデル化し、ARMAモデルの残差をフィットさせて、log return系列のボラティリティを新しいGARCHモデルで推定します。
表Ⅵはその結果です。5銘柄とも、切片のないARMA (0,0,0) (0,0,0)が最もフィットしたモデルであることがわかります。このARMAの残差は、ゼロ平均のGARCH(1,1)モデルにフィッティングされます。
表Ⅶは、5銘柄の結果を示しています。
GARCHモデルの精度をさらに高めるために、GJR-GARCHとEGARCHの概念を用いて、2つの非対称モデルを構築しました。まず、自動車セクター銘柄のreturn系列にGJR-GARCHモデルを当てはめます。平均値は一定で、残差はt分布、ボラティリティは非対称GARCHパターンとなります。
このモデルで考慮されている非対称ショックは1ラグのものです。表Ⅷは、自動車セクターの5銘柄のモデルの概要を示しています。これはほとんどすべてのガンマ係数とベータ係数が有意であることがわかります。
自動車セクターのGJR-GARCHボラティリティーモデルにおいて最も重要な予測因子であることがわかった。
最後に、EGARCH(1,1,1)を用いてもう一つの非対称ボラティリティモデルを構築する。他のGARCHモデルとは異なり、EGARCHはアルファとベータのパラメータが非負であることを必要としません。そのため、EGARCH モデルの構築には、より少ない時間しか必要ありません。表IXは、自動車セクターの株式に対するEGARCHモデルの概要を示しています。アルファ、ガンマ、ベータの各係数がほぼすべて有意であることから、このモデルは株式のリターン値に非常によく適合していることがわかります。
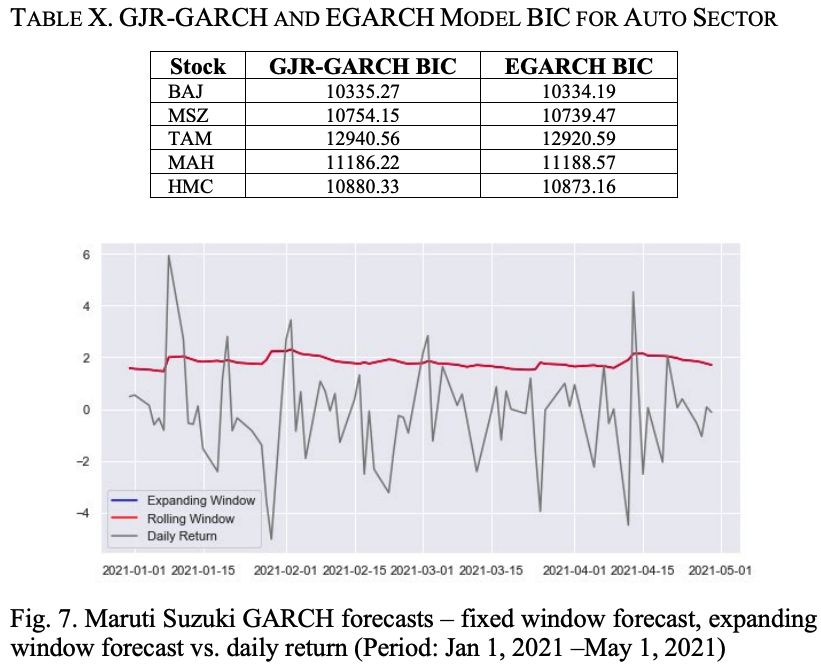
表 X は、自動車セクター銘柄の GJR-GARCH モデルと EGARCH モデルの BIC 値を示しています。MAHを除き、EGARCHモデルのBICは、対応するGJR-GARCHモデルのBICよりも低いことがわかります。図 6 は MSZ のリターンシリーズ、GJR-GARCH ボラティリティ、および EGARCH ボラティリティを示しています。両方のGARCHモデルの性能はほぼ同じであり、両方のモデルがMSZのリターンシリーズのボラティリティを正確に捉えていることがわかります。
拡大ローリングウィンドウ法と固定ローリングウィンドウ法を用いて、2021年1月1日からのMSZのリターンシリーズのボラティリティを80のデータポイントで予測しました。その結果が図7です。どちらの予測方法でも同じ予測結果が得られていることがわかります。
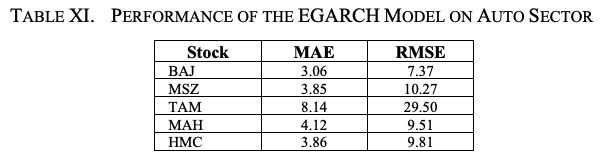
自動車セクター株のリターンシリーズに対するEGARCHモデルのパフォーマンスを評価するために、モデルのバックテストを行いました。
表XIは、5銘柄のモデルの平均絶対誤差(MAE)と二乗平均平方根誤差(RMSE)を示しています。このように TAMのMAEとRMSEの値が高いのは、株式のボラティリティが高いためです。
銀行セクター
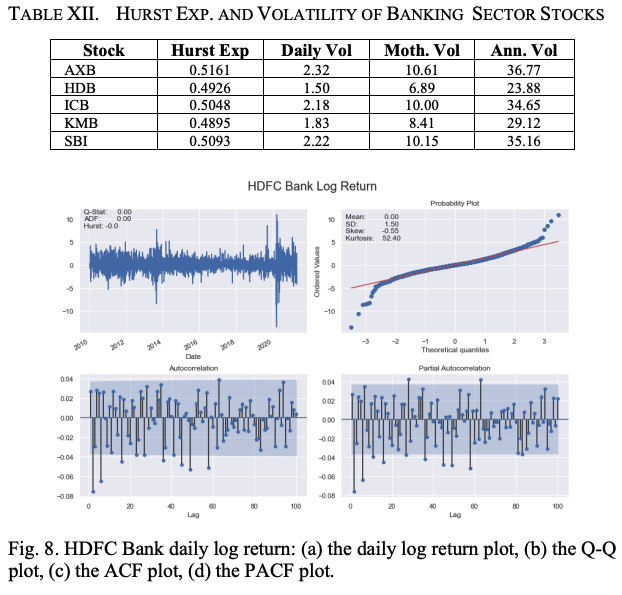
NSEの銀行セクター指数の計算に最も大きく寄与している5銘柄と、それぞれのウエイト(%)は以下の通りです。(i)HDFC銀行(HDB)-27.41、(ii)ICICI銀行(ICB)-21.09、Axis銀行(AXB)-14.30、Kotak Mahindra銀行(KMB)-13.02、State Bank of India(SBI)-11.74。表XIIは、銀行セクターの5銘柄のハースト指数、日次、月次、年次のボラティリティを示しています。AXB、ICB、SBIは非常に穏やかなトレンド性を示し、HDBとKMBは平均回帰型であることがわかります。AXBは最もボラティリティの高い銘柄ですが、HDBは5銘柄の中で最もボラティリティが低い銘柄です。
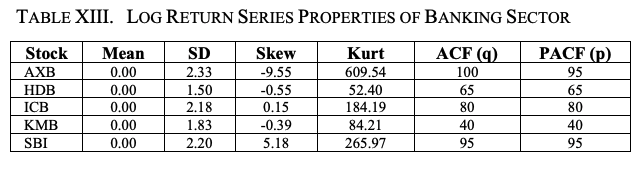
表XIIIと図8は、銀行セクター銘柄のlog returnシリーズの重要な統計的特性を示しています。すべてのreturnシリーズの平均値はゼロですが、AXBのSDが最も大きいことがわかります。また、AXBの歪度と尖度の大きさは、銀行セクターの5銘柄の中で最も高く、銀行セクターの中で最も変動が激しいことを示しています。
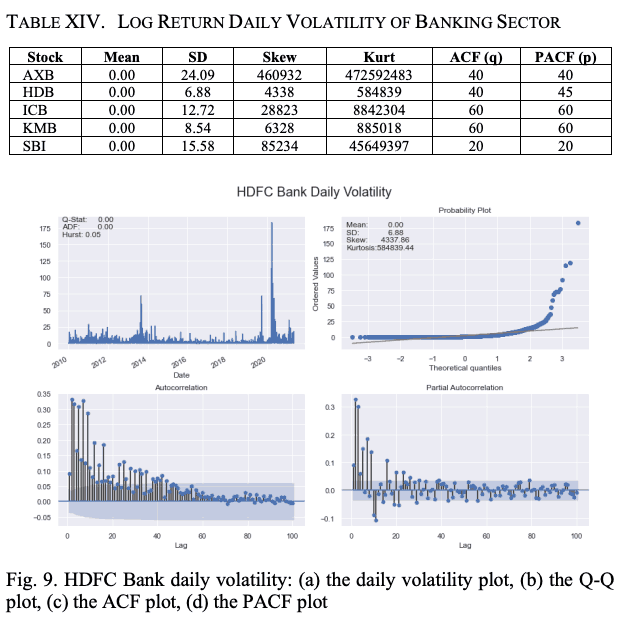
ACFとPACFのプロットには、最大ラグ値100を使用しています。表XIVと図9は、各銘柄のログ・リターン・シリーズのボラティリティーの特徴を示しています。ここでも、日次log returnのボラティリティーの平均値はすべてゼロであることがわかります。AXBはlog returnシリーズのボラティリティーのSD、歪度、および尖度の値が最も高くなっています。
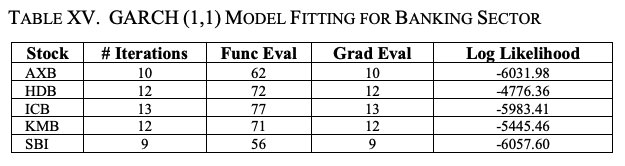
自動車セクター銘柄の場合と同様に、return系列にconstantmean GARCH(1,1)モデルを適合させ、残差を正規分布させました。
表XVは、銀行セクターの5銘柄に対するモデルフィッティングの結果を示しています。表XVの列名の意味は、先に説明した表IVの列名と同じです。
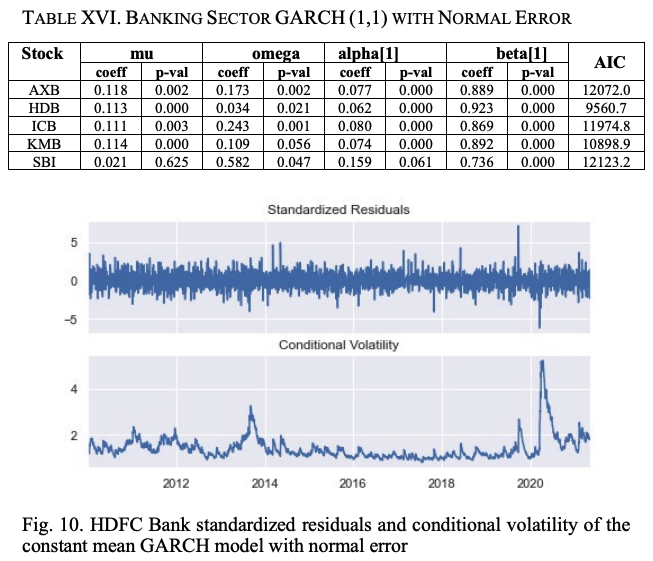
銀行セクター銘柄の正規分布残差を持つ定数平均GARCH(1,1)モデルの概要を表XVIに示します。先に説明したように、パラメータのmu、omega、alpha、betaは、一定平均、長期一定分散、最終ラウンドの残差値の二乗の係数、最終ラウンドのボラティリティ予測の分散の係数を意味しています。
α値が大きいほど、ショックがボラティリティに与える影響が大きくなり、β値が大きいほど、影響が長期間にわたって有効であることを示します。SBIはアルファ値が最も高く、HDBはパラメータ値が最も低いことが分かりました。HDBでは最も低くなっています。したがって、ショックの影響はSBIで最も大きく、HDBでは最も小さいということになる。ベータ値を見ると、HDBはショックの影響を受ける期間が最も長く、SBIは影響を受ける期間が最も短くなっています。
GARCH(1,1)モデルで計算したHDBの株式return系列の標準化残差と条件付ボラティリティを図10に示す。このGARCHモデルは2つの仮定に基づいて構築されている。
(i)return系列の平均値が一定であること
(ii)残差が正規分布していること
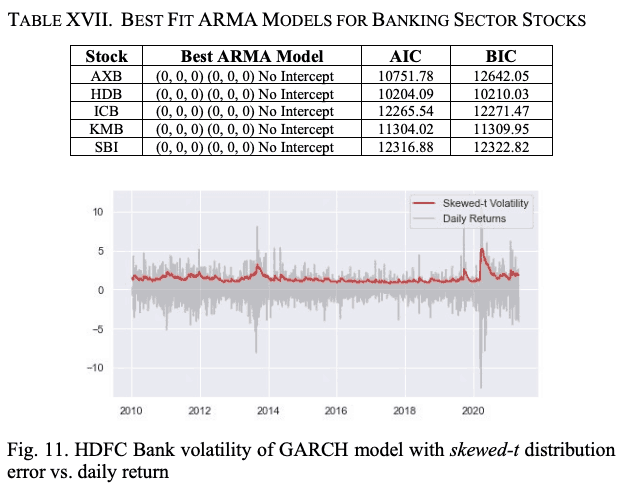
自動車セクター銘柄で行ったように、モデルをより現実的なものにするために、残差が正規分布ではなく、歪んだt分布に従うという仮定でGARCHモデルを構築します。図11は、歪んだt分布の残差を持つGARCHモデルのボラティリティと、HDB株の日次リターン値を示しています。
次に、GARCH(1,1)モデルを微調整します。
銘柄の終値の対数リターンを用いてARMAモデルを構築します。ARMAモデルの残差をGARCHモデルにフィットさせ、対数リターンシリーズの長期ボラティリティを推定します。ARMAモデルを、銘柄のlog return系列にフィットさせます。表XVIIはその結果を示しています。自動車セクターの銘柄と同様に、銀行セクターの5銘柄すべてにおいて、切片のないARMA (0,0,0) (0,0,0)が最もフィットするモデルであることがわかります。ARMAモデルの残差に、ゼロ平均のGARCH(1,1)モデルがフィットしています。
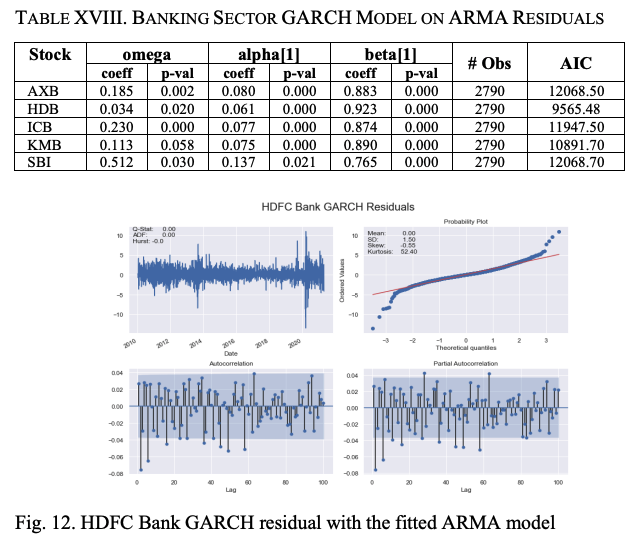
GARCHモデルの概要を表XVIIIに示します。ω、α、βの係数のほとんどが有意なp値を示しており、モデルの適合性が非常に高いことがわかります。自動車セクター株の場合と同様に、ボラティリティーモデルをより正確にするために、EJR-GARCHとEGARCHという2つの非対称モデルを構築します。
まず、GJR-GARCHモデルを構築します。一定平均のGJR-GARCHモデルが作成され、残差はt分布に従い、1ラグの非対称ショックが有意となります。
このモデルの概要は表XIXに示されています。
すべてのガンマ係数とベータ係数が有意であることから、1ラグの非対称ショックと1ラグの分散がモデルの主要な構成要素であることは明らかです。表XXのEGARCH(1,1)モデルの結果は、GJR-GARCH(1,1)に比べて、すべての係数が有意であるため、モデルの適合性が高いことを示しています。表XXIから、AXBを除くすべての銘柄において、EGARCHモデルのBICはGJR-GARCHのBICよりも小さく、株価データへの適合性が高いことが明らかになっています。
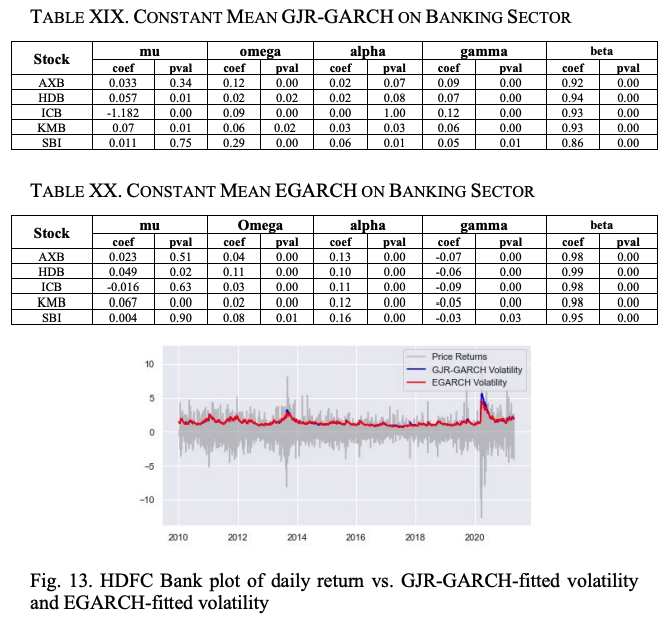
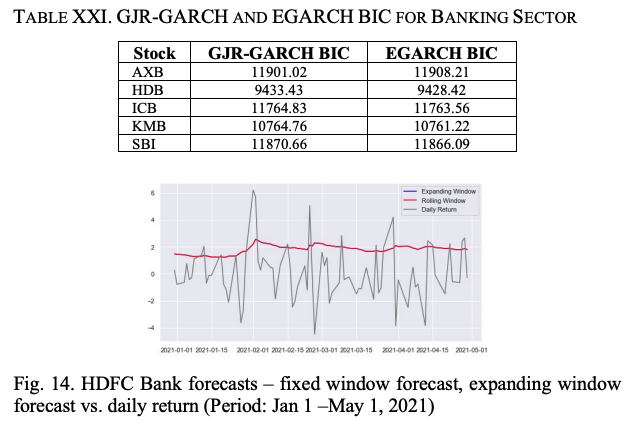
図14は、HDBのリターンシリーズと、GJR-GARCHとEGARCHのボラティリティを示しています。
表XXIIは、銀行セクターの全5銘柄に対するEGARHモデルの平均絶対誤差(MAE)と二乗平均平方根誤差(RMSE)を示しています。このモデルは、アウトオブサンプルのデータに対して非常に優れたパフォーマンスを発揮していることがわかります。
 最後に
最後に
本論文では、GARCHの様々なバリエーションに基づいたいくつかのボラティリティモデルを提案しました。これらのモデルは、2010年1月1日から2021年4月30日までの過去の株価データに基づいて構築されています。
2021. 銘柄はインドのNSEの自動車セクターと銀行セクターから選ばれました。モデルを微調整した後、サンプル外のデータでバックテストを行い、株式の将来のボラティリティーを予測する精度を評価しました。非対称GARCHモデルが対称モデルよりも優れていることが確認されましたが、EGARCHが最も正確な結果をもたらしていることがわかりました。



この記事に関するカテゴリー
.JPG)





